




 本文主要探讨了epoll在io多路复用中的作用,回顾其出现背景以解决select的局限,并重点分析了如何选择数据结构以适应高并发、频繁连接操作及高效事件检测的需求,特别强调了树型数据结构在这些场景中的优势。
本文主要探讨了epoll在io多路复用中的作用,回顾其出现背景以解决select的局限,并重点分析了如何选择数据结构以适应高并发、频繁连接操作及高效事件检测的需求,特别强调了树型数据结构在这些场景中的优势。
如果大家面试或者学习的时候,应该都或多或少听说过io多路复用,里面的概念、逻辑、和实现能讲的内容很多,但是本文不深究这些,而是专注于epoll要解决的问题和使用的数据结构
我们先简单回顾下epoll的实现
epoll实现
io多路复用是很久之前就提出的了,select是第一个实现,但是select的实现过于简陋,性能低下,当然20年前也不会预料到互联网的发展对网络的性能提出了这么高的要求
所以epoll应运而生,为了解决select架构下的几个问题:
- 监听的fd有限
- 每次都会涉及到fd位图的用户内核内存的互相拷贝
- 需要便利才能知道哪些fd有读写事件
然后再联想下互联网应用的特点:
- 并发用户多(连接数大)
- 用户会频繁上线下线(频繁增删)
- 用户请求的不均衡性,并不是所有用户都同时发送请求(并不是所有连接都有数据,需要找到有数据的连接)
所以为了解决上述的场景,应该要用什么数据结构来保存连接呢?能支持应用程序频繁地添加 监控连接,删除已监控连接,同时高效地找到有读写事件的连接
大家在学习的时候也听说过,不同数据结构的增删改查的效率,综合来看的话,还是树各个方面都比较平衡
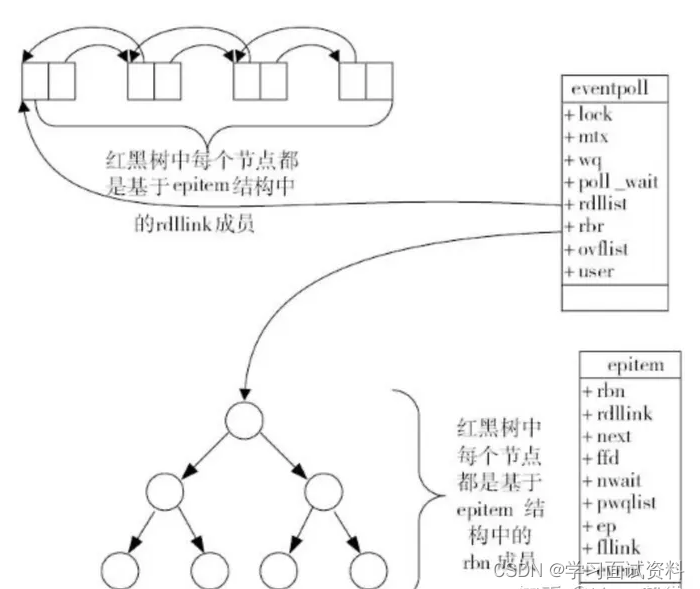
具体数据结构

















 1382
1382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









