




文章预览:
1.Hive中参数设置的几种方式
- 在hive-site.xml中修改,这种方式是永久生效。
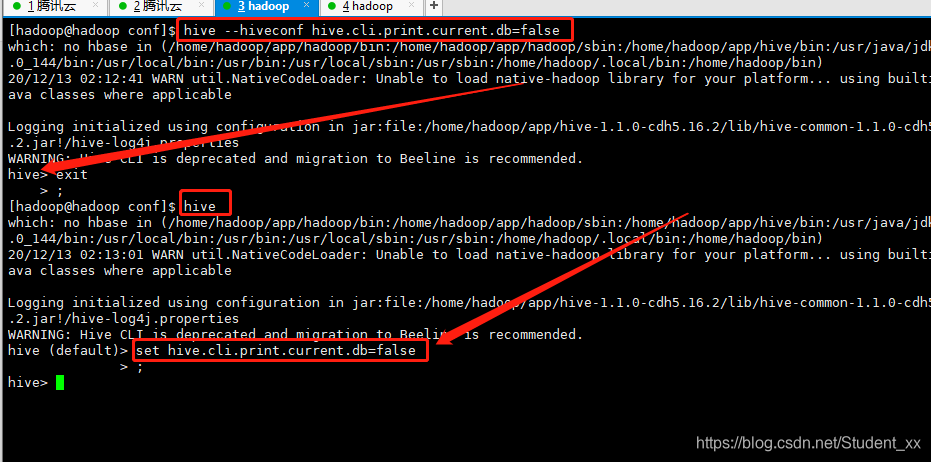
- 在Hive启动的时候通过在后面添加–hiveconf hive.cli.print.current.db=false的方式,这种方式仅在本次会话有效。
- 在hive>客户端上直接修改,这种方式也是仅本次会话有效。
以上三种修改方式的操作如下图所示:
2.Hive命令行
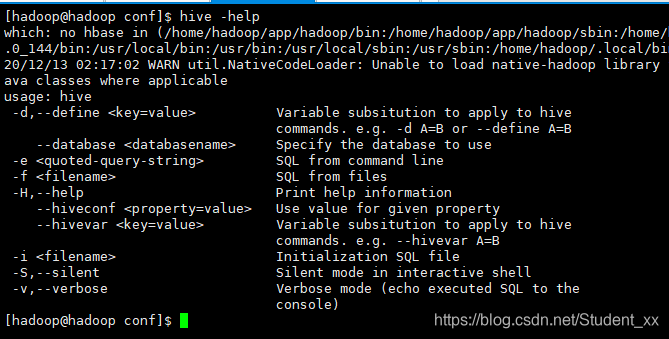
如上图hive -help所示的结果,下面说几种常用的:
-e:后边跟SQL语句
-f:SQL语句的文件
–hiveconf:设置参数
-i:定义UDF函数
3.DDL(Database)
参考官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
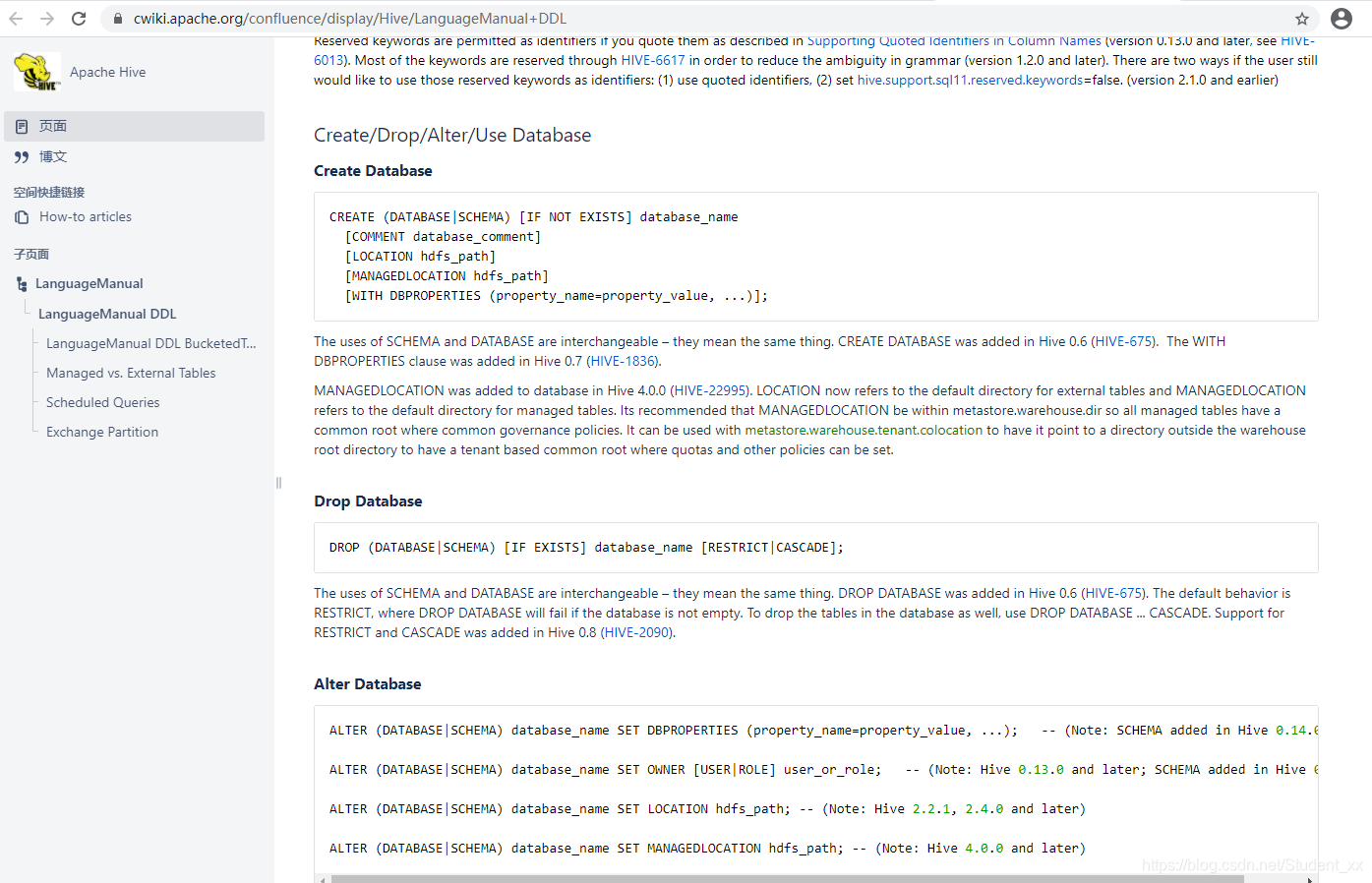
Database的DDL:
1.创建
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[MANAGEDLOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, …)];
例:
CREATE DATABASE IF NOT EXISTS ruozedata_hive;
CREATE DATABASE IF NOT EXISTS ruozedata_hive2
LOCATION '/dw_directory/ruozedata_hive2';
CREATE DATABASE IF NOT EXISTS ruozedata_hive3 COMMENT 'it is ruozedata hive database'
WITH DBPROPERTIES('creator'='pk','date'='2088-10-05');
以上的创建方式中如果没用LOCATION关键字指定存储的位置的话:会默认存储到默认的数据库中,对应在HDFS上的路径是:/user/hive/warehouse/database_name.db
2.修改:
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...); -- (Note: SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role; -- (Note: Hive 0.13.0 and later; SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path; -- (Note: Hive 2.2.1, 2.4.0 and later)
ALTER (DATABASE|SCHEMA) database_name SET MANAGEDLOCATION hdfs_path; -- (Note: Hive 4.0.0 and later)
例:
ALTER DATABASE ruozedata_hive3 SET DBPROPERTIES('year'='2088');
3.删除:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
例:
DROP DATABASE IF EXISTS ruozedata_hive3;
4.DDL(table)
Copy一份官网(https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-Create/Drop/Alter/UseDatabase)的:具体的参考官网
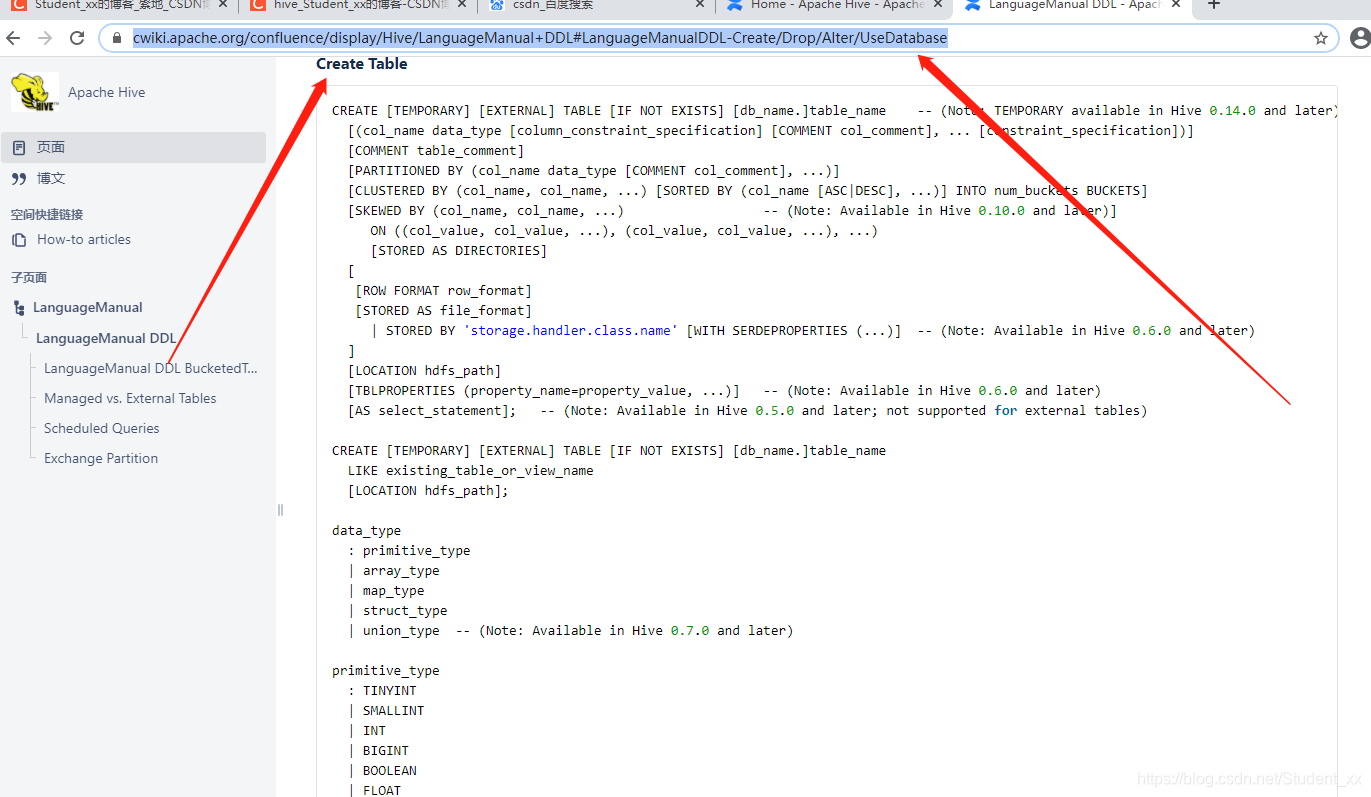
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
column_constraint_specification:
: [ PRIMARY KEY|UNIQUE|NOT NULL|DEFAULT [default_value]|CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
default_value:
: [ LITERAL|CURRENT_USER()|CURRENT_DATE()|CURRENT_TIMESTAMP()|NULL ]
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
[, CONSTRAINT constraint_name UNIQUE (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
1.Hive常用的数据类型
int、bigint(对应java中的long)、double:、float、string
2.Hive的分隔符
默认是\001也就是^A,在工作中常用的分隔符是:\t和空格或者逗号
3.建表语句含义的解释
CREATE TABLE:指定要创建的表的名字
col_name data_type:列名以及对应的数据类型,多个列之间使用逗号分隔
PARTITIONED BY:指定分区
CLUSTERED BY: 排序、分桶
ROW FORMAT:指定数据的分隔符等信息
STORED AS:指定表存储的数据格式:textfile rc orc parquet
LOCATION:指定表在文件系统上的存储路径
AS select_statement: 通过select的sql语句的结果来创建表
例:
create table emp_managed(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
4.加载数据方式(DML)
生产上使用最多的就是LOAD和inert…select这两种方式,export/import在迁移的时候用的较多
1. LOAD
官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DML#LanguageManualDML-Loadingfilesintotables
LOAD DATA [LOCAL] INPATH ‘filepath’ [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 …)]
LOAD DATA:加载数据
LOCAL:可有可无
有:从本地[Hive客户端]加载数据到Hive表
无:从文件系统加载数据到Hive表
INPATH:加载数据的路径
OVERWRITE:可有可无
有:覆盖已有的数据 overwrite
无:追加 append
INTO TABLE:加载数据到哪个表中
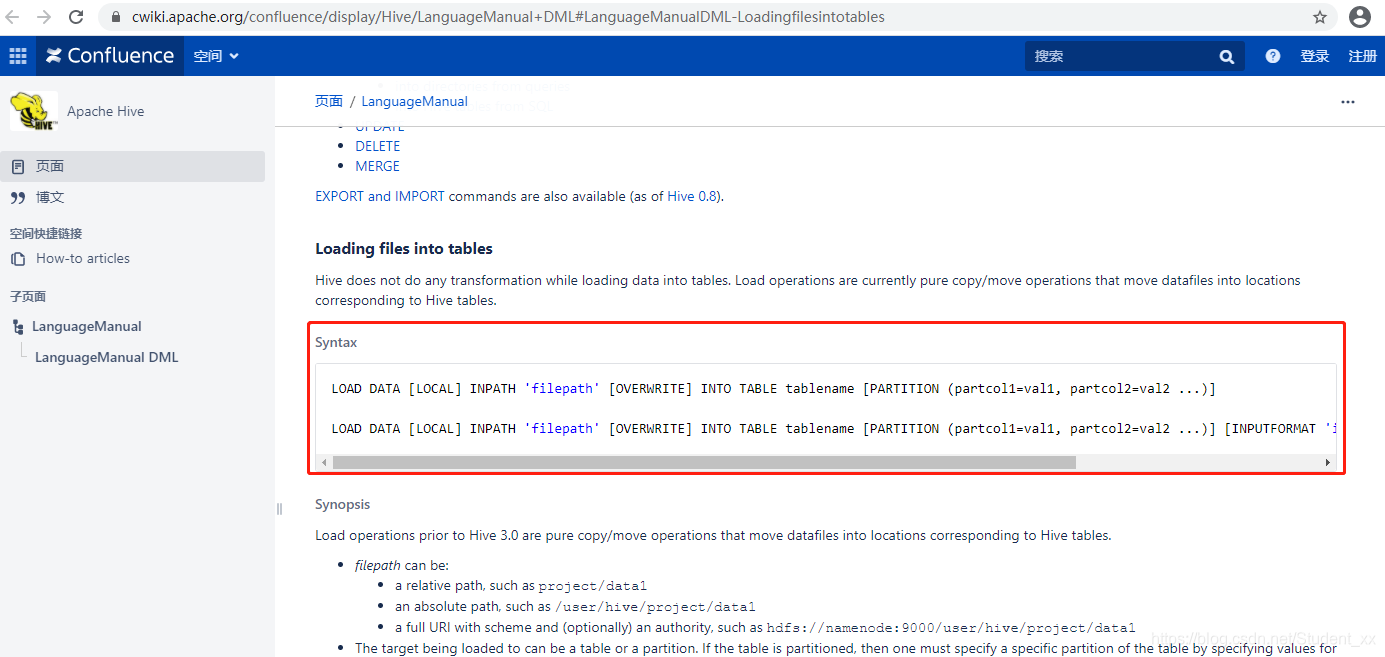
例:
load data local inpath '/home/hadoop/data/emp.txt' overwrite into table emp_managed;
2. insert … select的方式
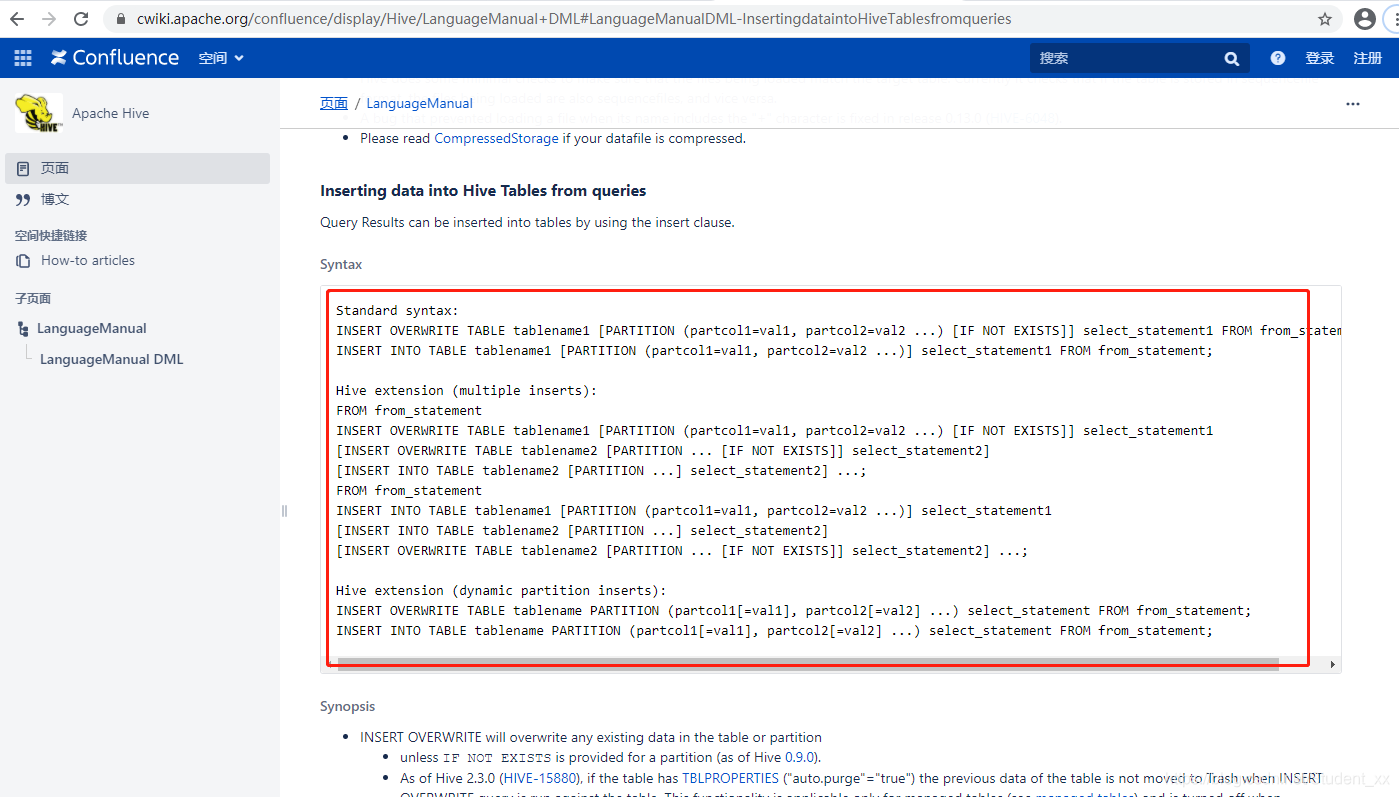
INSERT OVERWRITE/INTO TABLE emp2 select empno,job ,ename,mgr,hiredate,sal ,comm,deptno from emp;
3. INSERT INTO TABLE table_name VALUES()方式:
例:
INSERT INTO TABLE dept VALUES (95271, 'DEV', 'BJ'),(95281, 'QA', 'SZ'); #这种方式慎用,因为一个MapReduce会产生一个文件,即它会产生很多小文件,上面的一次插入两行数据会走一个MapReduce
4. Export/Import
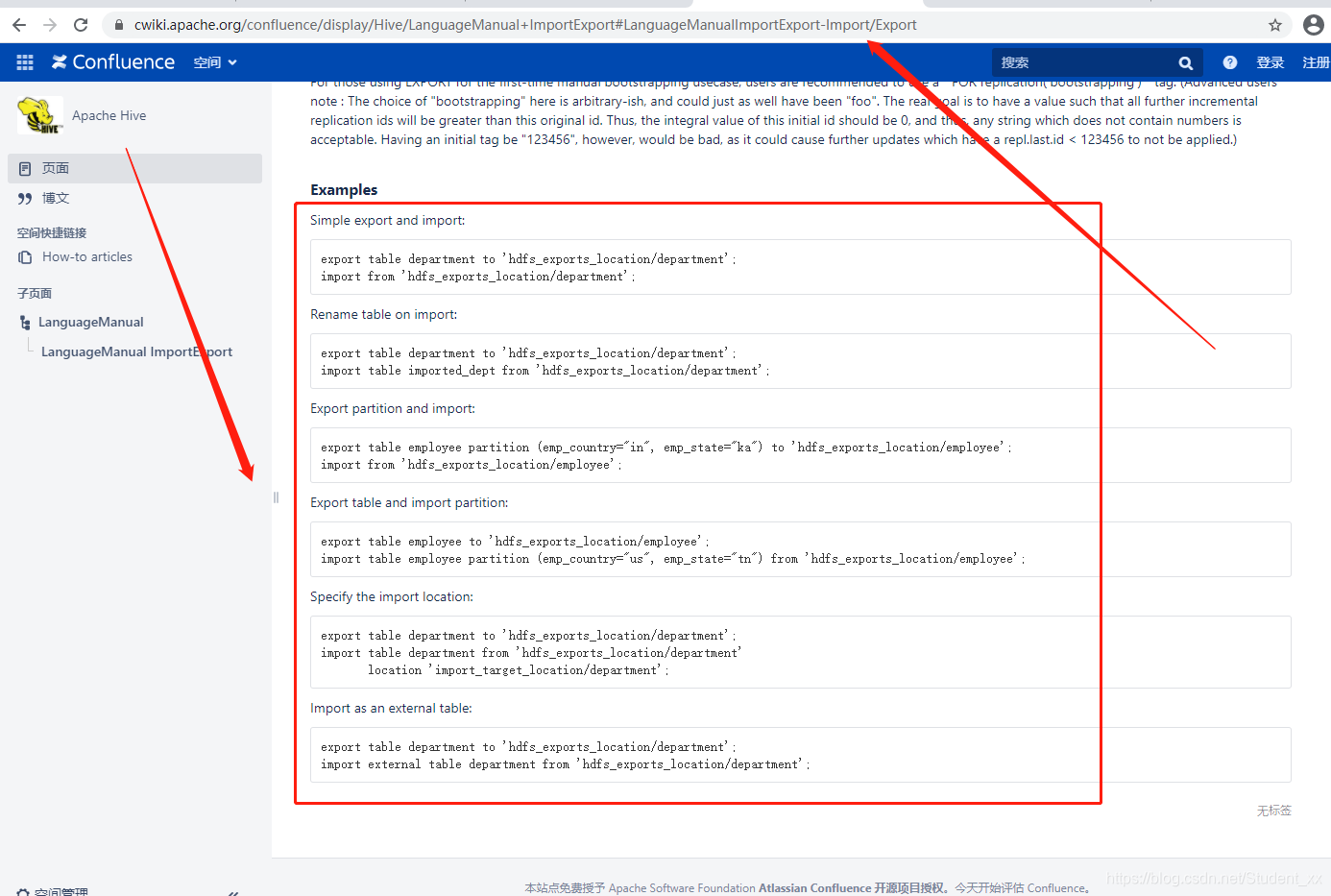
export table emp_managed to '/123';
import table import_emp from '/123'; #此方式是在导入的时候改名
5. 数据导出
注意:在导出的时候指定一下列分隔符 不然在文件系统上查看很乱没什么实际应用的意义
例:
INSERT OVERWRITE local DIRECTORY '/home/hadoop/tmp/emp'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
SELECT * FROM emp;
5.内部表和外部表
1.转换
内部表和外部表之间的转换
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL Managed vs external:https://cwiki.apache.org/confluence/display/Hive/Managed+vs.+External+Tables如下图:
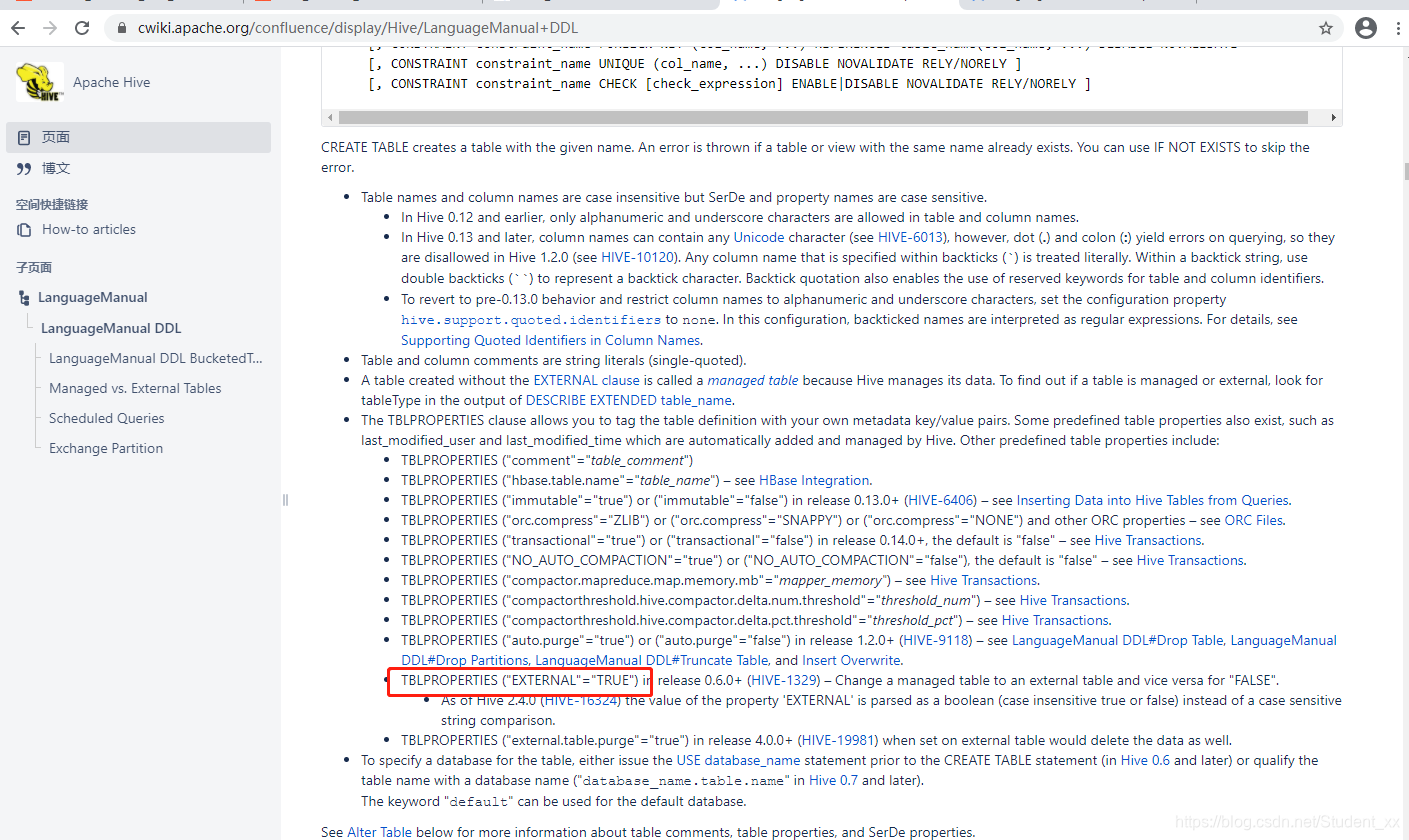
例:
ALTER TABLE emp_external SET TBLPROPERTIES ('EXTERNAL' = 'false'); #转为内部表
ALTER TABLE emp_external SET TBLPROPERTIES ('EXTERNAL' = 'true'); #转为外部表
2.区别
1.创建语法
内部表语法create table xxx;
外部表创建语法:create EXTERNAL table xxx;
2.drop table
内部表删除表之后:HDFS和MySQL的数据都被删除了
外部表删除表之后:MySQL的数据都被删除了,但是HDFS的数据是还存在的
6.truncate
- 有回收站会直接到回收站不会删除元数据 drop会删除元数据和数据
- truncate不能作用到外部表 只能作用内部表
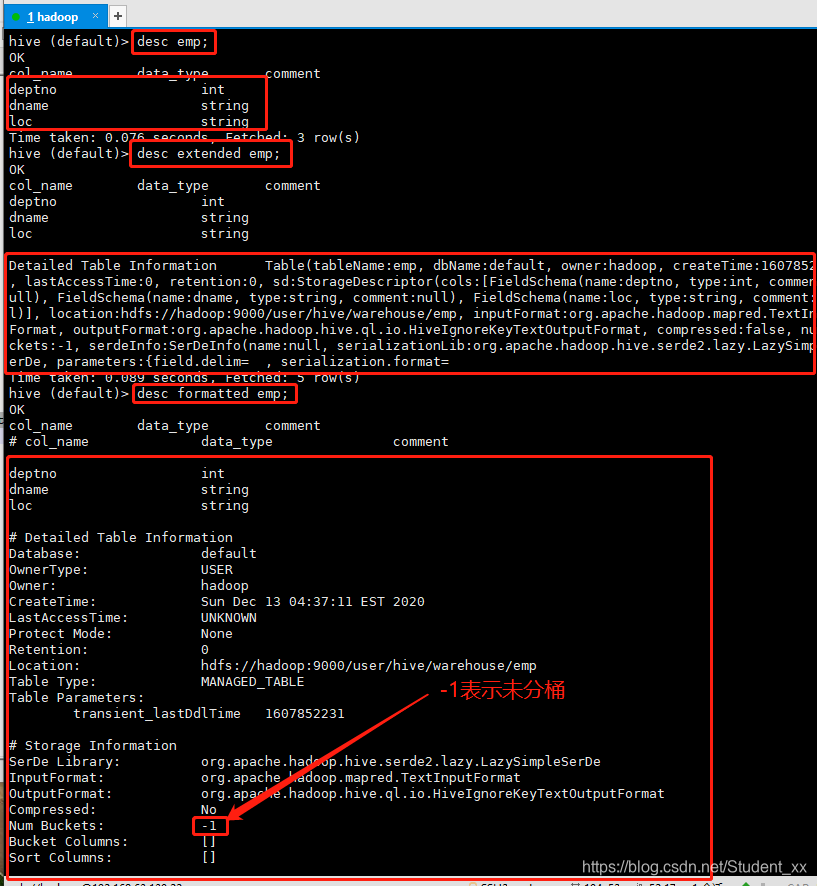
7.查看表的命令
如下图所示

















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









