



Mysql
数据库的三大范式
第一范式(1NF): 保证字段不可再分,保证原子性。
第二范式(2NF): 满足1NF前提下,表的每一列都必须和主键有关系。消除部分依赖关系。
第三范式(3NF): 满足2NF前提下,表的每一列比必须和主键有直接关系,不能是间接关系。消除传递依赖。
sql的执行顺序
select distinct
查询列表(要查的字段)
from
左边的表们s
连接类型(left|inner) join
右边的表们s
on
连接条件
where
筛选条件
group by
分组的列表(按什么字段分组)
having
having_condition
order by
排序的字段(asc/desc)
limit
limit number;
解释“
1 from 左边的表们s:从左边的表开始选择数据
2 连接类型(left|inner) join 右边的表们s on 连接条件:按照连接条件和右边的表
进行连接,形成结果集
3 where 筛选条件:在形成的结果集中根据筛选条件过滤数据
4 group by 分组列表(按什么字段分组):在过滤后的数据集中根据分组字段进行分组
5 having having_condition:对分组后的数据集应用条件进行过滤
6 select:选择结果集中需要的列,计算结果
7 distinct 查询列表(要查询的字段):对结果集去除重复行
8 order by 排序的字段:对结果集进行排序
9 limit limit_number:对结果集进行限制行数
Case表达式
CASE when sex='1' then '男'
when sex='2' then '女'
else '其他' end
在发现为真的 WHEN 子句时, CASE 表达式的真假值判断就会中止,而剩余的 WHEN 子句会被忽略。
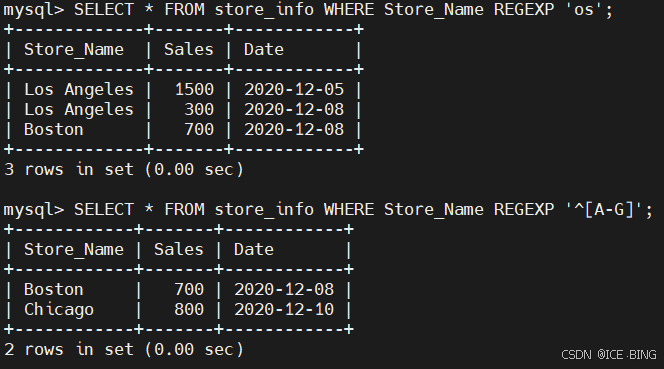
正则表达式
| 匹配模式 | 描述 | 实例 |
|---|---|---|
^ | 匹配文本的开始字符 | ^bd 匹配以 bd 开头的字符串 |
$ | 匹配文本的结束字符 | qn$ 匹配以 qn 结尾的字符串 |
. | 匹配任何单个字符 | s.t 匹配任何 s 和 t 之间有一个字符的字符串 |
* | 匹配零个或多个在它前面的字符 | fo*t 匹配 t 前面有任意个 o |
+ | 匹配前面的字符 1 次或多次 | hom+ 匹配以 ho 开头,后面至少一个 m 的字符串 |
字符串 | 匹配包含指定的字符串 | clo 匹配含有 clo 的字符串 |
p1|p2 | 匹配 p1 或 p2 | bg|fg 匹配 bg 或者 fg |
[...] | 匹配字符集合中的任意一个字符 | [abc] 匹配 a 或者 b 或者 c |
[^...] | 匹配不在括号中的任何字符 | [^ab] 匹配不包含 a 或者 b 的字符串 |
{n} | 匹配前面的字符串 n 次 | g{2} 匹配含有 2 个 g 的字符串 |
{n,m} | 匹配前面的字符串至少 n 次,至多 m 次 | f{1,3} 匹配 f 最少 1 次,最多 3 次 |
语法:SELECT “字段” FROM “表名” WHERE “字段” REGEXP {模式};
Redis
Redis内存淘汰策略
Redis是基于内存的key-value数据库,因为系统的内存大小有限,所以我们在使用Redis的时候可以配置Redis能使用的最大的内存大小。
1.通过配置文件配置
//设置Redis最大占用内存大小为100M
maxmemory 100mb
2.通过命令修改
Redis支持运行时通过命令的动态修改内存大小
//设置Redis最大占用内存大小为100M
127.0.0.1:6379> config set maxmemory 100mb
//获取设置的Redis能使用的最大内存大小
127.0.0.1:6379> config get maxmemory
如果不设置最大内存大小或者设置最大内存大小为0,在64位操作系统下不限制内存大小,在32位操作系统下最多使用3GB内存
redis的淘汰策略一共有8种
1.noeviction(默认策略): 不会删除任何数据,拒绝所有写入操作并返回客户端错误消息(error)OOM command not allowed when used memory,此时 Redis 只响应删和读操作;
2.allkeys-lru: 从所有 key 中使用 LRU 算法进行淘汰(LRU 算法:最近最少使用算法);
3.allkeys-lfu: 从所有 key 中使用 LFU 算法进行淘汰(LFU 算法:最不常用算法,根据使用频率计算,4.0 版本新增);
4.volatile-lru: 从设置了过期时间的 key 中使用 LRU 算法进行淘汰;
5.volatile-lfu: 从设置了过期时间的 key 中使用 LFU 算法进行淘汰;
6.allkeys-random: 从所有 key 中随机淘汰数据;
7.volatile-random: 从设置了过期时间的 key 中随机淘汰数据;
8.volatile-ttl: 在设置了过期时间的key中,淘汰过期时间剩余最短的。
注意: 当使用 volatile-lru、volatile-lfu、volatile-random、volatile-ttl 这四种淘汰策略时,如果没有 key 可以淘汰,则和 neoviction 一样返回错误。
Git
Springboot
依赖注入的方式
将Bean对象更加简单地从Spring中取出来,有三种方式,分别为 属性注入, setter注入,构造方法注入
@Autowired
构造函数注入@RequiredArgsConstructor
JAVA八股
范围查询推荐使用什么树(B/B+树)?B和B+树的区别?
范围查询推荐使用B+树,存储数据的叶子节点也相互连接,方便查找相邻的数据。
归并排序和快速排序各个优势选择?不足?
归并排序(Merge Sort)
优势:
- 稳定性:归并排序是一个稳定的排序算法,能保持相同元素在排序前后的相对顺序。
- 时间复杂度:无论输入数据如何,归并排序的时间复杂度都是 (O(n \log n)),最坏情况也保持这个复杂度,适合处理需要保证最坏时间复杂度的场景。
- 适合处理大规模数据:归并排序通过分治思想,将大问题拆分成小问题递归处理,尤其适合对链表等结构的排序,且能够很好地利用外部存储器进行排序(如外部排序)。
不足:
- 空间复杂度较高:归并排序需要额外的 (O(n)) 空间来存储临时数组,这在内存较为紧张的场景下可能成为瓶颈。
- 局部性差:归并排序在处理数据时的内存访问是分散的,缓存命中率较低,可能导致性能在实际运行中不如其他算法。
快速排序(Quick Sort)
优势:
- 平均时间复杂度更低:快速排序的平均时间复杂度为 (O(n \log n)),且由于其常数因子较小,在实际应用中通常比归并排序快。
- 原地排序:快速排序是一个原地排序算法,仅需要 (O(\log n)) 的辅助空间,用到的额外空间很少,因此在内存使用上非常高效。
- 适合多种数据结构:快速排序可以很好地处理数组等需要高效就地排序的数据结构,并且可以通过选择不同的“枢轴”策略来优化性能。
不足:
- 最坏情况时间复杂度高:如果数据本身已经有序或接近有序,且选择了不合适的枢轴,快速排序的最坏情况时间复杂度可能退化为 (O(n^2))。
- 不稳定:快速排序不是稳定的排序算法,相同的元素在排序后可能会改变其相对顺序。
- 对小规模数据表现不佳:在处理小规模数据时,快速排序的递归开销可能超过其性能优势。
选择依据:
- 归并排序适合在对稳定性有要求、处理链表或大规模数据、最坏情况性能必须控制的场景中使用。
- 快速排序适合在内存有限、追求速度、数据规模较小或不需要保证稳定性的场景中使用。
信号量和读写锁的概念 实际应用
1. 信号量(Semaphore)
-
概念:
信号量是一种计数器机制,用于控制多个线程或进程对共享资源的访问。信号量可以限制同时访问资源的线程或进程数量。-
类型:
- 二值信号量:值为0或1,类似互斥锁,一次只允许一个线程访问共享资源。
- 计数信号量:信号量值为非负整数,表示允许多少个线程同时访问资源。
-
操作:
- P操作(wait/down):将信号量的值减1,若值小于0,则阻塞调用线程。
- V操作(signal/up):将信号量的值加1,若有线程阻塞,则唤醒。
-
-
实际应用:
- 限制资源访问数量:用于控制同时访问数据库连接、文件等资源的线程数量。
- 生产者-消费者问题:用于协调生产者和消费者对缓冲区的访问。
2. 读写锁(Read-Write Lock)
-
概念:
读写锁允许多个线程同时读取共享资源,但写操作必须互斥,并且在写操作期间不允许任何线程读取资源。- 读锁:允许多个线程同时获取,适用于并发读操作。
- 写锁:写操作必须独占锁,不能同时有其他线程进行读或写操作。
-
实际应用:
- 读多写少的场景:适用于缓存、配置文件等读多写少的数据结构的并发访问。
- 数据库的读写分离:允许多个线程并发读取数据,写操作时需要互斥。
- 缓存更新:多个线程并发读取缓存数据时,使用读写锁可以提高性能,写入时保证数据一致性。
3. 信号量与读写锁的区别与应用场景
- 信号量:用于控制并发访问的数量,适合生产者-消费者模型等场景。
- 读写锁:适合读多写少的场景,提升并发性能,常用于缓存和数据库读写分离。
线程池的相关类及其开发应用
1. Executor 接口
-
概念:
Executor是一个顶层接口,定义了执行线程的基础方法,所有线程池相关类都继承自这个接口。
-
主要方法:
execute(Runnable command):提交一个任务以供线程执行。
2. ExecutorService 接口
-
概念:
ExecutorService继承自Executor接口,提供了管理线程池的功能,可以提交任务、关闭线程池以及控制任务的执行。
-
主要方法:
submit(Callable<V> task):提交一个任务并返回Future对象,允许获取任务结果。shutdown():关闭线程池,已提交的任务继续执行,但不接受新的任务。shutdownNow():尝试停止所有正在执行的任务,并返回等待执行的任务列表。
3. ThreadPoolExecutor 类
-
概念:
ThreadPoolExecutor是 Java 中线程池的核心实现类,提供了非常灵活的线程池管理机制。可以根据任务的数量动态调整线程数。
-
构造方法参数:
corePoolSize:线程池中核心线程的数量。maximumPoolSize:线程池允许的最大线程数量。keepAliveTime:线程空闲后保持存活的时间。workQueue:用于存放待执行任务的队列(如ArrayBlockingQueue、LinkedBlockingQueue等)。handler:拒绝策略(如AbortPolicy、CallerRunsPolicy等),处理当任务无法被执行时的行为。
4. 开发应用
-
场景:
- 适用于需要高并发处理的任务,如网络请求、数据处理等。
- 通过复用线程,减少线程创建和销毁的开销,提高程序的性能和响应速度。
-
常用实现:
- 使用
Executors工具类快速创建线程池,如Executors.newFixedThreadPool(int nThreads)和Executors.newCachedThreadPool()。
- 使用
为什么重写equals必须重写hashcode
如果重写了 equals() 但没有重写 hashCode(),可能会发生以下问题:
插入到集合中无法找到对象:假设你在 HashSet 中插入一个对象,集合会根据该对象的 hashCode() 确定它的位置。后来,如果你再创建一个与其 equals() 相等的新对象,因为 hashCode() 没有被重写,这两个对象可能有不同的哈希值,导致集合无法正确找到这个对象。
重复对象无法去重:在 HashSet 或 HashMap 中,去重是基于 hashCode() 和 equals() 的配合。如果两个对象的 hashCode() 不同,即使 equals() 返回 true,集合也可能认为它们是不同的对象,导致无法去重。
Git 工具
1. 概念
Git 是一个分布式版本控制系统,用于跟踪计算机文件的变化,尤其是源代码文件。它允许多个开发者在项目中并行工作,跟踪历史版本,进行协作和管理代码。
2. 主要特性
- 分支管理:Git 允许创建、合并和删除分支,便于并行开发和特性实验。
- 快速操作:大多数操作在本地执行,速度较快。
- 数据完整性:使用 SHA-1 哈希算法确保数据的完整性,任何修改都会导致哈希值变化,易于检测。
- 支持离线工作:用户可以在离线状态下进行提交和其他操作。
3. 常用命令
3.1 仓库操作
git init:初始化一个新的 Git 仓库。git clone <repository>:克隆远程仓库到本地。
3.2 状态查看
git status:查看当前工作区和暂存区的状态。git log:查看提交历史。
3.3 文件操作
git add <file>:将文件添加到暂存区。git commit -m "message":提交暂存区的更改到本地仓库。git rm <file>:删除文件,并将删除操作添加到暂存区。
3.4 分支管理
git branch:列出所有分支。git branch <branch_name>:创建新分支。git checkout <branch_name>:切换到指定分支。git merge <branch_name>:将指定分支的更改合并到当前分支。
3.5 远程操作
git remote add <name> <url>:添加远程仓库。git fetch <remote>:从远程仓库获取最新更新。git pull <remote> <branch>:从远程仓库拉取并合并到当前分支。git push <remote> <branch>:将本地分支推送到远程仓库。
3.6 其他命令
git stash:临时保存当前的修改,方便切换分支。git diff:查看当前工作区和暂存区的差异。
4. 开发中的应用
- 版本控制:管理源代码版本,便于回滚到先前状态。
- 团队协作:多个开发者可以在不同分支上独立工作,合并时处理冲突。
- 备份与恢复:通过远程仓库备份代码,防止数据丢失。
- 持续集成:与 CI/CD 工具结合,自动化构建和测试流程。
5. 图形化工具
除了命令行,Git 还有许多图形化工具,例如:
- GitHub Desktop:适用于 GitHub 的桌面客户端。
- Sourcetree:Atlassian 提供的图形化 Git 客户端。
- GitKraken:跨平台的 Git 客户端,界面友好。
Nacos 微服务
主要功能
-
服务发现:
- 服务注册:微服务在启动时可以将自己注册到 Nacos,保存服务的元数据(如服务名、地址、端口等)。
- 服务发现:其他微服务可以通过 Nacos 查询已注册的服务信息,从而找到所需的服务。
-
配置管理:
- 动态配置:允许集中管理应用程序的配置,并可以在运行时动态更新,避免重启服务。
- 多环境支持:支持对不同环境(如开发、测试、生产)的配置管理。
-
负载均衡:
- 根据服务实例信息,实现负载均衡,将请求均匀分配到不同的服务实例上,提高系统可用性和性能。
mysql索引?应用场景?数据修改有什么帮助?
MySQL 索引
1. 概念
索引是数据库中用于快速查询数据的结构,它通过创建一个数据表的关键字和数据地址的映射,来加速数据的检索。MySQL 支持多种类型的索引,包括:
- B-TREE 索引:默认的索引类型,适用于范围查询和等值查询。
- HASH 索引:适用于等值查询,查询速度快,但不支持范围查询。
- FULLTEXT 索引:用于对文本字段进行全文搜索。
- SPATIAL 索引:用于空间数据类型的索引,支持地理数据的快速查询。
2. 应用场景
- 快速查询:当数据表中有大量记录时,通过索引可以显著提高查询性能。
- 排序操作:索引可以加速 ORDER BY 和 GROUP BY 操作的性能。
- 唯一性约束:使用唯一索引可以确保某列的值唯一,如主键索引。
- 联接查询:在多表联接时,索引可以加速数据的匹配,提高联接查询的效率。
3. 对数据修改的帮助
虽然索引能提高查询性能,但在数据修改时(如 INSERT、UPDATE、DELETE)会带来一些开销:
- INSERT 操作:每次插入数据时,索引需要更新,因此索引数量越多,插入速度可能越慢。
- UPDATE 操作:更新涉及索引的列时,需要更新索引,可能会导致性能下降。
- DELETE 操作:删除记录时,也需要同步更新索引,影响性能。
4. 总结
索引是提高 MySQL 查询性能的有效工具,但在数据修改时也会带来一定的性能开销。因此,合理设计索引(包括选择合适的索引类型和索引列)是数据库性能优化的重要部分。


















 86万+
86万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









