



 本文是针对初学者的Python爬虫基础教程,涵盖爬虫介绍、HTTP协议、URL解析、使用requests模块发送请求、响应对象处理、正则表达式以及数据存储到MySQL数据库的方法。讲解了HTTP请求与响应、网络抓包、Cookie与User-Agent的使用,帮助读者快速入门网络爬虫开发。
本文是针对初学者的Python爬虫基础教程,涵盖爬虫介绍、HTTP协议、URL解析、使用requests模块发送请求、响应对象处理、正则表达式以及数据存储到MySQL数据库的方法。讲解了HTTP请求与响应、网络抓包、Cookie与User-Agent的使用,帮助读者快速入门网络爬虫开发。
前言
彦祖们啊,博主们啊,还有“君子们”啊,我们又见面了,对于前面的那些文章大部分都因某些原因都 鸽了吧~ 鸽了吧~ 。(后期会整体慢慢补充)

一、爬虫介绍
爬虫又称网络蜘蛛、网络机器人,主要的功能就是抓取网络数据的程序。本质就是用程序模拟人使用浏览器访问网站,并将所需要的数据抓取下来。通过对抓取的数据进行处理,从而提取出有价值的信息。
爬虫可分为两大类:通用网络爬虫、聚焦网络爬虫
-
通用网络爬虫 :是搜索引擎的重要组成部分,百度搜索引擎,其实可以更形象地称之为百度蜘蛛(Baiduspider),它每天会在海量的互联网信息中爬取信息,并进行收录。当用户通过百度检索关键词时,百度首先会对用户输入的关键词进行分析,然后从收录的网页中找出相关的网页,并按照排名规则对网页进行排序,最后将排序后的结果呈现给用户。通用网络爬虫需要遵守robots协议,网站通过此协议告诉搜索引擎哪些页面可以抓取,哪些页面不允许抓取。
-
聚焦网络爬虫 :是面向特定需求的一种网络爬虫程序。聚焦爬虫在实施网页抓取的时候会对网页内容进行筛选,尽量保证只抓取与需求相关的网页信息。这也很好地满足一些特定人群对特定领域信息的需求。
-
robots协议 :是一种“约定俗称”的协议,并不具备法律效力,它体现了互联网人的“契约精神”。行业从业者会自觉遵守该协议,因此它又被称为“君子协议”,当然具体的就是四个大D(四个大D:懂得都懂)
-
查看详情点击
二、网页获取流程
- 浏览器会根据URL发送HTTP请求给服务端
- 服务端接收到HTTP请求后进行解析
- 服务端处理请求内容,组织响应内容
- 服务端将响应内容以HTTP响应格式发送给浏览器
- 浏览器接收到响应内容,解析展示
import re
import requests
class MaoYanSpider:
def __init__(self):
self.url = 'https://maoyan.com/board/4?offset=0'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
def get_html(self, url):
"""请求的功能函数"""
response = requests.get(url=url, headers=self.headers)
return response.text
def parse_html(self, html):
"""提取数据"""
regex = '<div class="movie-item-info">.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>'
r_list = re.findall(regex, html, re.S)
self.save(r_list)
def save(self, datas):
for data in datas:
li = [
data[0].strip(),
data[1].strip(),
data[2].strip()
]
print(li)
def crawl(self):
"""程序的入口函数"""
html = self.get_html(url=self.url)
self.parse_html(html)
spider = MaoYanSpider()
spider.crawl()三、URL
-
URL即统一资源定位符`Uniform Resource Locator`,每一个URL指向一个资源。可以是一个`HTML`页面,一个`CSS`文档,一个`js`文件、一个图片等等(详情点击)
-
绝对URL :URL(Uniform Resource Locator)就是统一资源定位符,简单地讲就是网络上的一个站点、网页的完整路径。
-
相对URL :如将自己网页上的某一段文字或某标题链接到同一网站的其他网页上面去;还有一种称为同一网页的超链接,这种超链接又叫做书签。
-
我们上面看到的是一个绝对的URL,还有一个叫相对URL。如果URL的路径部分以“/”字符开头,则浏览器将从服务器的顶部根目录获取该资源。常出现在网页的超链接中
语法格式
`protocol://hostname[:port]/path[?query][#fragment]`解析:
- protocol:是指网络传输协议
- hostname:是指存放资源的服务器的域名或IP地址。
- port:是一个可选的整数,它的取值范围 是 0-65535。如果port被省略时就使用默认端口,各种传输协议都有默认的端口号,如http的默认端口为80,https的端口是 443。
- path:路由地址,由零个或多个`/`符号隔开的字符串,路由地址决定了服务端如何处理这个请求。
- query:从?开始到#为止,它们之间的部分就是参数,又称搜索部分或者查询字符串。这个部分允许有多个参数,参数与参数之间用&作为分隔符。
四 HTTP协议
-
HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写。HTTP协议主要的作用就是要服务器和客户端之间进行数据交互(相互传输数据)。`HTTPS` (Secure Hypertext Transfer Protocol)安全超文本传输协议,`HTTPS`是HTTP协议的安全版。对传输数据进行加密。(详情点击)
-
HTTP特点
无连接: 无连接意味着每次连接处理一个请求,服务器返回之后断开连接,节省传输时间和服务器压力。
HTTP协议是一个无状态的协议,同一个客户端的这次请求和上次请求是没有对应关系。
-
HTTP请求
-
请求行 : 具体的请求类别和请求内容
| GET | 请求类别 |
| / | 请求内容 |
| HTTP/1.1 | 协议版本 |
-
请求类别:每个请求类别表示要做不同的事情
在HTTP协议中,定义了八种请求方法。我们主要了解两种常用的请求方法,分别是get请求和post请求。
-
get请求:从服务器获取数据下来,并不会对服务器资源产生任何影响的时候会使用get请求。
-
post请求:向服务器发送数据(登录)、上传文件等,会对服务器资源产生影响的时候会使用post请求。
-
请求头:对请求的进一步解释和描述
Referer:表明当前这个请求是从哪个url过来的。这个一般也可以用来做反爬虫技术。如果不是从指定页面过来的,那么就不做相关的响应。
User-Agent:请求载体的身份标识,这个在网络爬虫中经常会被使用到。请求一个网页的时候,服务器通过这个参数就可以知道这个请求是由哪种浏览器发送的。如果我们是通过爬虫发送请求,那么我们的User-Agent就是Python,这对于那些有反爬虫机制的网站来说,可以轻易的判断你这个请求是爬虫。因此我们要经常设置这个值为一些浏览器的值,来伪装我们的爬虫。
Cookie:对应的是一个用户的信息,http协议是无状态的。也就是同一个人发送了两次请求,服务器没有能力知道这两个请求是否来自同一个人。因此这时候就用cookie来做标识。
-
请求体: 提交的内容
五 HTTP响应
-
响应行 : 反馈基本的响应情况
| HTTP/1.1 | 版本信息 |
| 200 | 响应码 |
| OK | 附加信息 |
常见的响应状态码
200:请求正常,服务器正常的返回数据。
301:永久重定向。
302:临时重定向。比如在访问一个需要登录的页面的时候,而此时没有登录,那么就会重定向到登录页面。
400:请求的url在服务器上找不到。换句话说就是请求url错误。
403:服务器拒绝访问,权限不够。
500:服务器内部错误
-
响应头:对响应内容的描述
Content-Length: 服务器通过这个头,告诉浏览器回送数据的长度
Content-Type:服务器通过这个头,告诉浏览器回送数据的类型
-
响应体:响应的主体内容信息
六 编写爬虫流程
"""
1. 确定需要爬取的URL地址。
2. 由请求模块向URL地址发出请求,并得到网站的响应。
3. 从响应内容中提取所需数据。
4. 存储
"""
import requests
class MaoYanSpider(object):
def __init__(self):
pass
def get_html(self, url):
"""发送请求功能"""
pass
def parse_html(self, html):
"""提取数据"""
pass
def save(self):
"""存储数据"""
pass
def crawl(self):
"""程序的入口"""
pass
spider = MaoYanSpider()
spider.crawl()七 控制台抓包
打开浏览器,`F12`打开控制台,找到Network选项卡
控制台常用选项
- Network: 抓取网络数据包
- ALL: 抓取所有的网络数据包
- `XHR`:抓取异步加载的网络数据包
- `JS` : 抓取所有的`JS`文件
3. Sources: 格式化输出并打断点调试JavaScript代码,助于分析爬虫中一些参数
4. 抓取具体网络数据包后:单击左侧网络数据包地址,进入数据包详情,查看右侧
八 request模块的安装
这里注意一定要设置环境变量!!!!! 详细点击:梁同学
# 在`CMD`命令行中执行如下命令进行在线安装
pip install requests
#由于网络的不稳定性有时会导致下载失败,在下载的时候我们可以加上第三方源进行下载
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
#在py里面安装
pip install requests -i http://pypi.douban.com/simple/九 requests.get()
# 该方法用于 GET 请求,表示向网站发起请求,获取页面响应对象。语法如下:
response = requests.get(url,headers=headers,params,timeout)
- `url`:要抓取的`url` 地址。
- headers:用于包装请求头信息。
- `params`:请求时携带的查询字符串参数。
- timeout:超时时间,超过时间会抛出异常。十 `HttpResponse`响应对象
Requests 模块向一个URL发起请求后会返回一个 `HttpResponse`响应对象
响应对象属性
- text:获取响应内容字符串类型
- content:获取到响应内容bytes类型(抓取图片、音频、视频文件)
- encoding:查看或者指定响应字符编码
- request.headers:查看响应对应的请求头
- cookies:获取响应的cookie,经过了set-cookie动作;返回`cookieJar`类型
- `json()`:将`json`字符串类型的响应内容转换为python对象
十一 发送带header的请求
# 请求头(headers)中的 User-Agent
# 测试案例: 向测试网站http://httpbin.org/get发请求,查看请求头(User-Agent)
import requests
url = 'http://httpbin.org/get'
html = requests.get(url=url,headers=headers).text
print(html)
"""
请求头中:User-Agent为python-requests那第一个被网站干掉的是谁???我们是不是需要发送请求时重构一下User-Agent???添加 headers 参数!!!
"""
import requests
url = 'http://httpbin.org/get'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
html = requests.get(url=url,headers=headers).text
# 在html中确认User-Agent
print(html)十二 发送带参数的请求
# 直接对含有参数的URL发起请求
url = 'https://maoyan.com/board/4?offset=0'
通过`params`携带参数字典
- 构建请求参数字典
- 向接口发送请求的时候带上参数字典,参数字典设置给`params`十三 处理cookie相关的请求
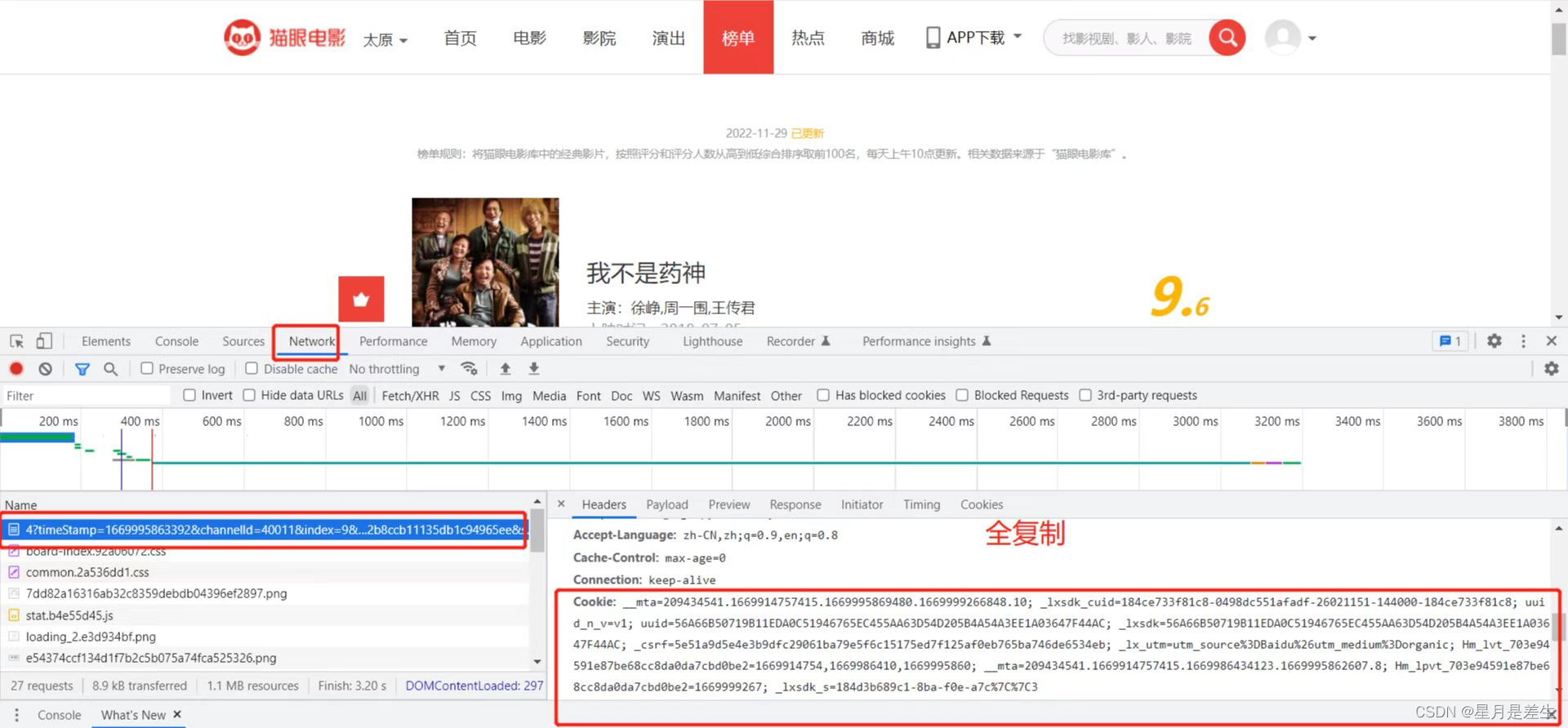
Cookie是一个记录了用户登录状态以及用户属性的字符串。当你第一次登陆网站时,服务端会在返回的Response Headers中添加Cookie, 浏览器接收到响应信息后,会将Cookie 保存至浏览器本地存储中,当你再次向该网站发送请求时,请求头中就会携带Cookie,这样服务器通过读取 Cookie 就能识别登陆用户了。
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Cookie":"__utma=32101439.446453095.1567515939.1567855225.1596027512.4; __utmc=32101439; __utmz=32101439.1596027512.4.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmt=1; __utmb=32101439.1.10.1596027512"
}
#requests.post():适用场景 : Post类型请求的网站
cookie_dict = {"cookie的key:“cookie的value"}
requests.get(url, headers=headers, cookies=cookie_dict)
requests.post(url=url,data=data,headers=headers)
"""
requests提供了一个叫做session类,来实现客户端和服务端的会话保持。会话能让我们在请求时候保持某些参数,比如在同一个 Session 实例发出的所有请求之间保持 cookie 。
"""
User-Agent查找方法
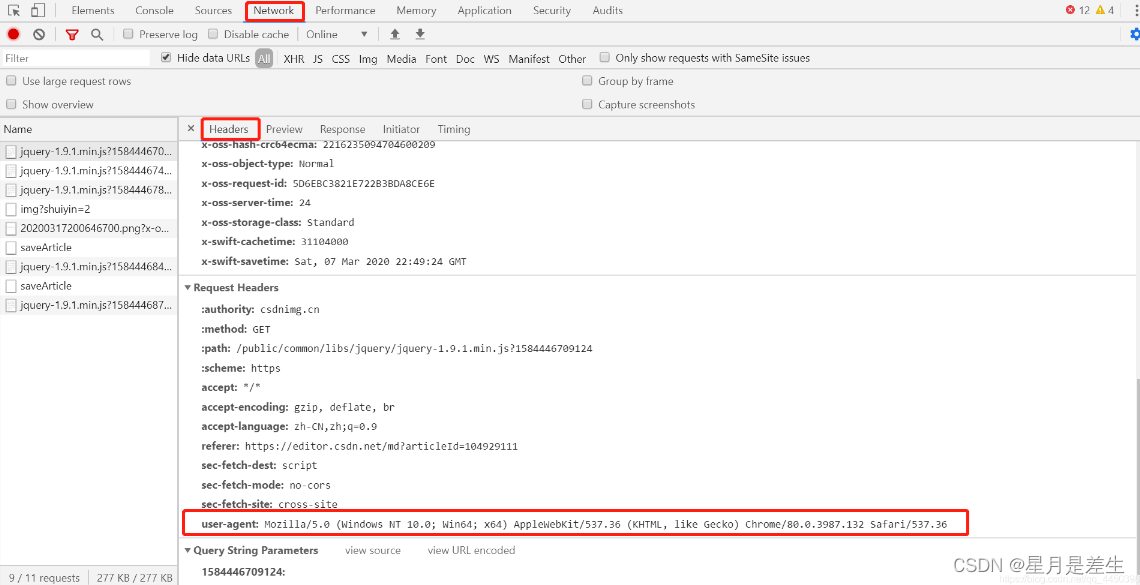
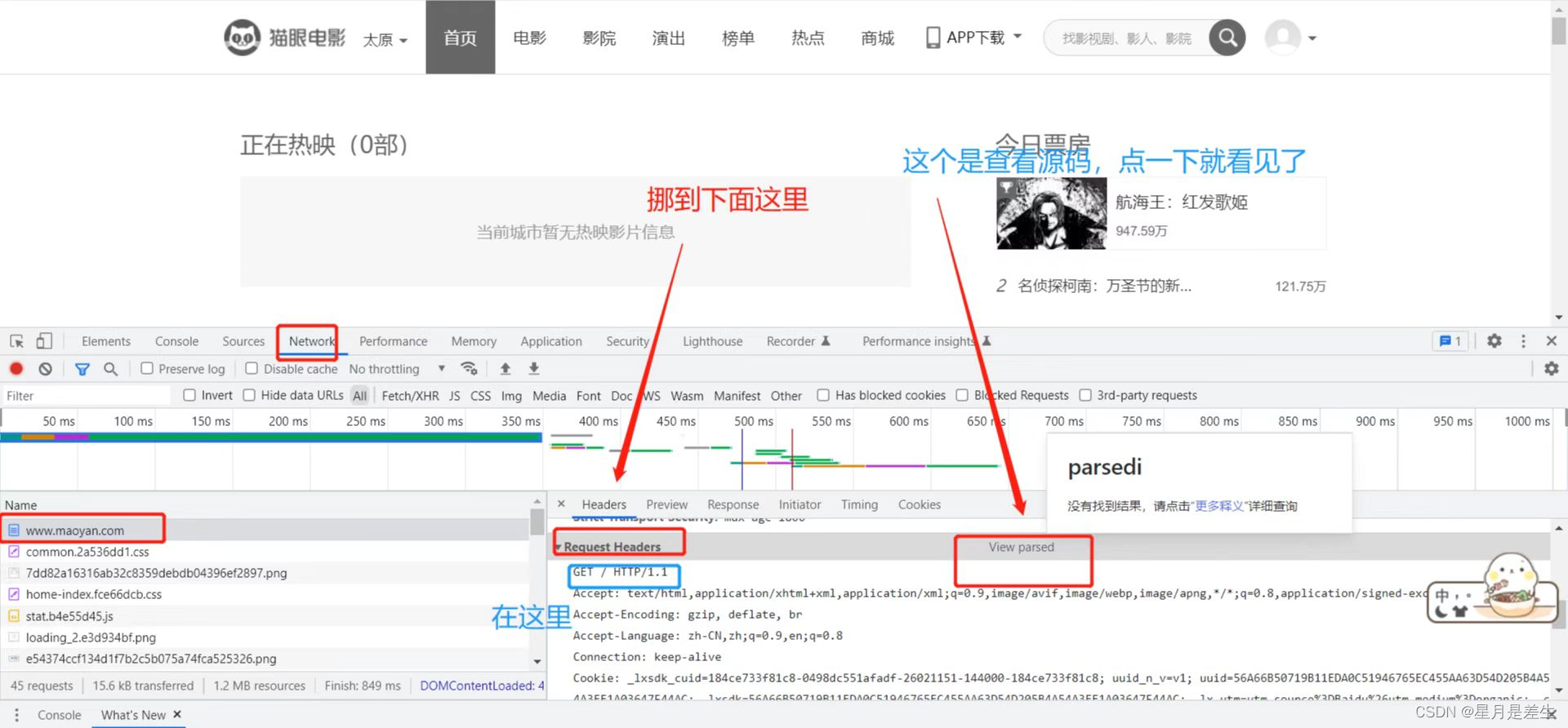
版本查找方法
Cookie查找方法
十四 正则表达式
`r_list=re.findall('正则表达式',html,re.S)`
-
正则表达式分组:将每个圆括号中子模式匹配出来的结果提取出来
- - 先按整体正则匹配,然后再提取分组()中的内容
- - 在网页中,想要什么内容,就加()
- - 如果有2个及以上分组(),则结果中以元组形式显示 [(),(),()]
正则表达式元字符
元字符 含义 .
任意一个字符(不包括\n) \d 一个数字 \s 空白字符 \S 非空白字符 [] 包含[]内容 * 出现0次或多次 + 出现1次或多次
贪婪匹配和非贪婪匹配
-
- 贪婪匹配:匹配重复的元字符总是尽可能多的向后匹配内容。
-
- 非贪婪匹配:让匹配重复的元字符尽可能少的向后匹配内容。
十五 数据存储 MYSQL
"""
- 建立数据库连接db = `pymysql.connect(...)`
- 参数host:连接的mysql主机,如果本机是'127.0.0.1'
- 参数port:连接的mysql主机的端口,默认是3306
- 参数database:数据库的名称
- 参数user:连接的用户名
- 参数password:连接的密码
- 参数charset:通信采用的编码方式,推荐使用utf8
- 创建游标对象cur = db.cursor()
- 游标方法: cur.execute("insert ....")
- 提交到数据库或者获取数据 : db.commit()
- 关闭游标对象 :cur.close()
- 断开数据库连接 :db.close()
"""
import re
import requests
class MaoYanSpider:
def __init__(self):
self.url = 'https://maoyan.com/board/4?offset=0'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
def get_html(self, url):
"""请求的功能函数"""
response = requests.get(url=url, headers=self.headers)
return response.text
def parse_html(self, html):
"""提取数据"""
regex = '<div class="movie-item-info">.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>'
r_list = re.findall(regex, html, re.S)
self.save(r_list)
def save(self, datas):
for data in datas:
li = [
data[0].strip(),
data[1].strip(),
data[2].strip()
]
print(li)
def crawl(self):
"""程序的入口函数"""
html = self.get_html(url=self.url)
self.parse_html(html)
spider = MaoYanSpider()
spider.crawl()后记
为了这个博客笔记,将近写了4个小时,前四次电脑网络原因根本发不出来,预计是下午3:00发布的,因此很抱歉,拖了这么就,快给我写麻了,写崩溃了。不过还好在今天赶出来。晚点就晚点吧。


















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









