




 本文介绍了Python Selenium中针对HTML元素定位的三种方法:id、name和class_name,并通过实例展示了如何在百度搜索框输入文字并点击搜索。文章还分享了如何查看和定位浏览器中的元素,以及模拟输入和点击操作的基本语法。
本文介绍了Python Selenium中针对HTML元素定位的三种方法:id、name和class_name,并通过实例展示了如何在百度搜索框输入文字并点击搜索。文章还分享了如何查看和定位浏览器中的元素,以及模拟输入和点击操作的基本语法。
在学习元素定位前,要了解一些HTML的基础知识,知道HTML的构成是由很多的标签构成的,而这些标签下会存在很多的元素,有些元素是无功能含义的,这些元素常常是在我们在项目启动后,与开发商量,协助后期做自动化而写上去的,主要是为了在相同的标签里做区分,让我们能准确的定位到想要的元素,从而对元素进行操作。
点击HTML了解简单的基础知识。
selenium中支持的元素定位方法有8种:
1.id 2. name 3.class_name 4. link_text 5. partial_link_text 6. tag_name 7. xpath 8. css
运用格式: 对象名.find_element_by_id(元素定位方式8种)
通过元素定位方法写一个脚本实现通过模拟输入【slenium教程】在百度输入框后,点击【百度一下】。
首先要先找到元素,再通过元素去进行定位操作
如何查看浏览器中的元素?
通过谷歌浏览器打开百度首页来举个例子:
先定位到输入框的元素:
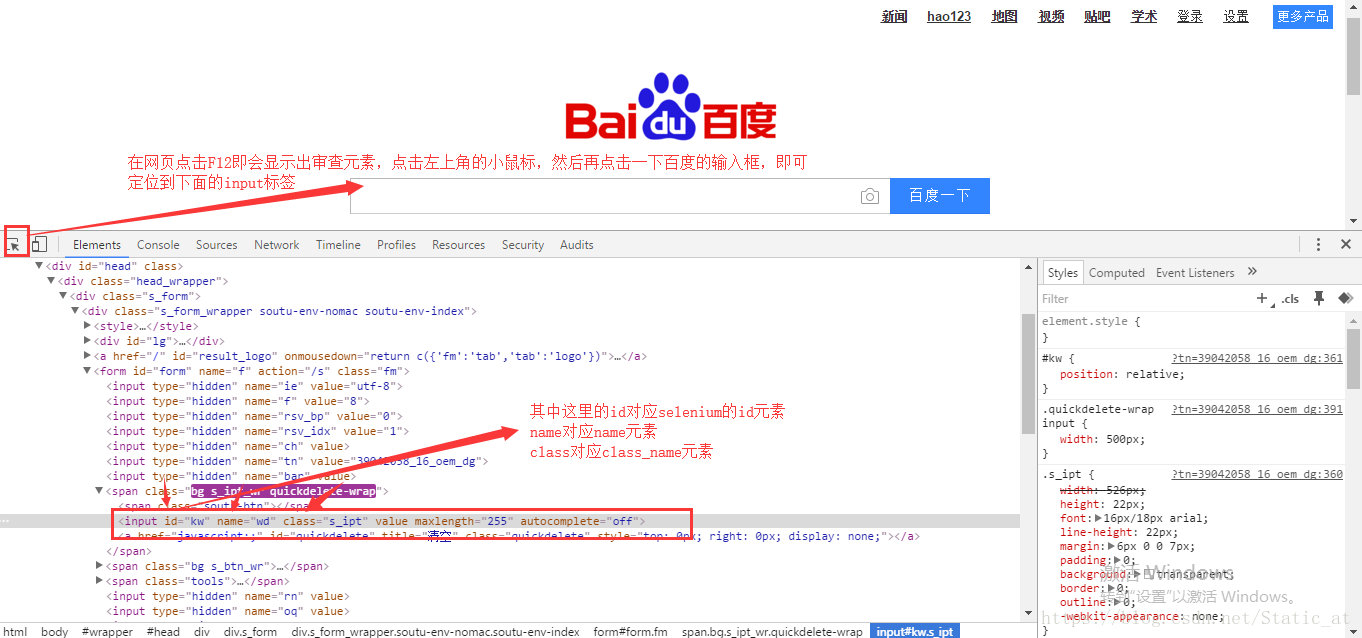
再定位到百度一下按钮的位置:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







