






B站的评论是通过动态加载出来的,使用常规的静态爬取无法正常爬取,但使用常规动态爬取需要解密,此方法非常复杂,且错误率较高,多次试错后可能还会被封IP,但使用DrissionPage完全不用担心上述问题。以下是全部代码。
from DrissionPage import ChromiumPage # pip install DrissionPage
import time
URL = input("请输入B站视频链接:")
num = int(input("请输入要爬取的页面次数:"))
page = ChromiumPage()
page.set.load_mode.none()
# 监听特定的网络流
page.listen.start('https://api.bilibili.com/x/v2/reply/wbi/main?')
# 访问B站页面
page.get(f'{URL}')
time.sleep(3)
for _ in range(num+1):
page.scroll.to_bottom()
time.sleep(2)
# 用于存储所有捕获的响应数据
responses = []
try:
# 循环监听直到达到所需数量或超时
for _ in range(num):
# 等待网络请求包到达
packet = page.listen.wait()
# 停止加载页面(这步可以根据需求调整)
page.stop_loading()
# 接收 HTTP 响应内容
response_body = packet.response.body
# 将响应内容存储到列表中
responses.append(response_body)
time.sleep(1)
except Exception as e:
print(f"解析出现错误: {e}")
# 处理和打印捕获到的所有响应
total_comments = 0
for response in responses:
try:
if 'data' in response:
datas = response['data']['replies']
total_comments += len(datas)
for data in datas:
comments = data['content']['message']
uname = data['member']['uname']
sex = data['member']['sex']
IP = data['reply_control']['location']
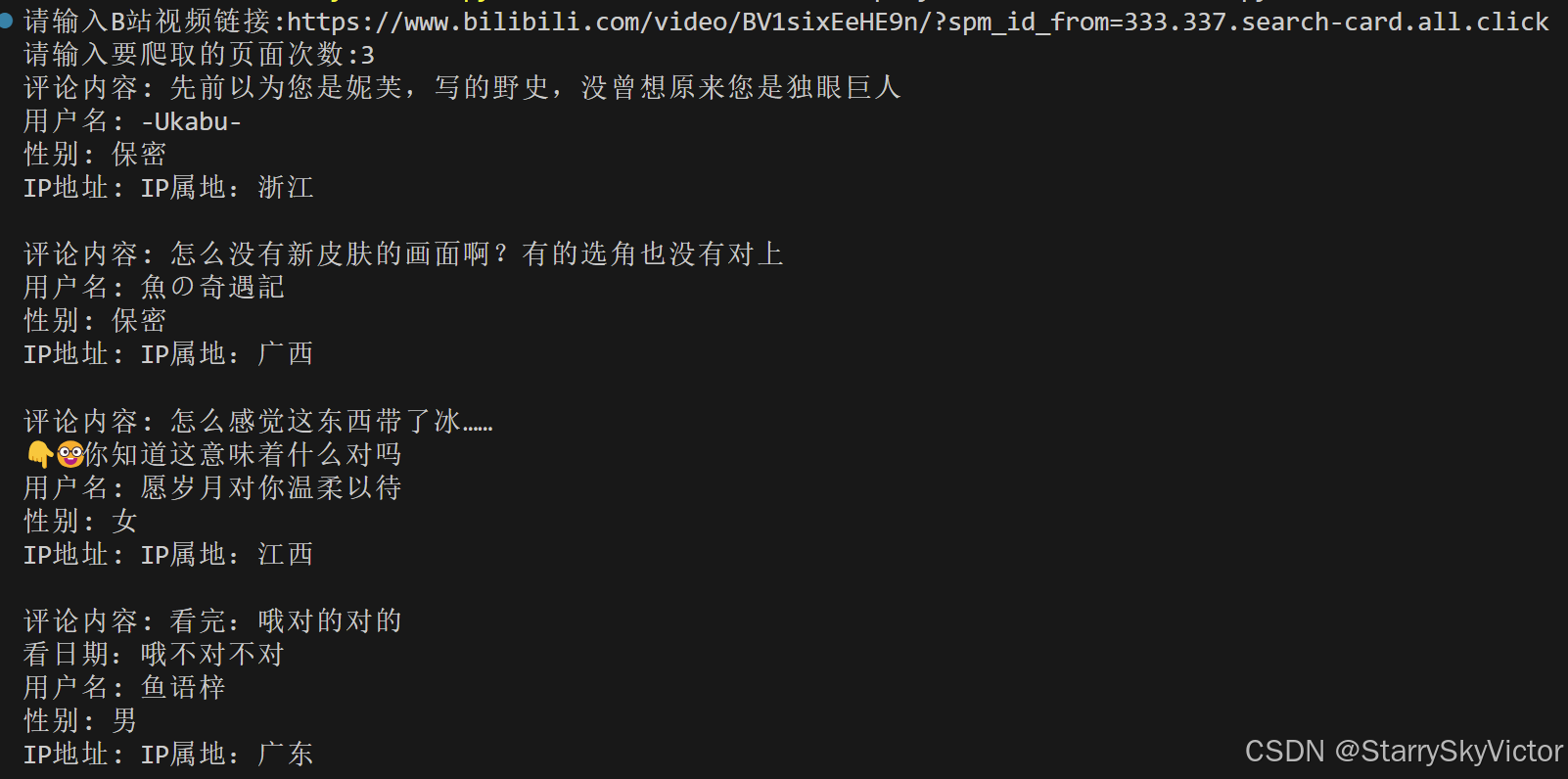
print(f"评论内容: {comments}\n用户名: {uname}\n性别: {sex}\nIP地址: {IP}\n")
except KeyError as e:
print(f"处理响应时出现错误: {e}")
page.close()
# 最后打印总评论数量
print(f"总评论数量: {total_comments}")
加上一些空余行和注释行外才65行代码。不需要一些用户信息,如'user-agent','cookie'之内的信息。只需要输入B站视频的网址,以及要爬取的视频页面次数。总评论量是要爬取的页面次数乘以20(因为B站视频每次回加载出新的20条评论)。而代码中的网络流是大评论的所在的url。因此,此代码只能爬取大评论,若要爬取大评论下的小评论需要更改网络流。如果只爬取大评论,无需更改任何一处代码。
运行代码后,下拉条回自动下拉,无需手动下拉。当然也可以手动下拉网页右边的下拉条。使用此代码,电脑中应有谷歌浏览器,且B站已经登录。此代码会爬取评论内容,用户名,性别,IP地址。也可以自行添加代码,增加爬取内容。
DrissonPage这个第三方库需要手动下载,cmd里pip install DrissionPage即可,无需像selenium配置浏览器环境。默认的浏览器为谷歌浏览器。
以下是运行结果部分截图。
DrissionPage这个第三方库非常好用。开发者在B站上也有账号。希望大家大家为这位开发者点点赞,点点星。
如果代码运行中有什么疑惑,可以看看我在B站上发的视频,视频里有更详细地解释。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









