




Trino(之前称 PrestoSQL)项目最初由 Meta 开发,旨在让数据分析师能够在广泛的 Apache Hadoop 数据仓库上执行交互式查询。其高效处理大型数据集和复杂查询的能力,以及多数据源连接的灵活性,使其迅速成为大规模组织的首选数据分析工具。随着时间的推移,用户对数据分析的需求不断演变。移动互联网和 SaaS 应用的兴起,实时分析变得至关重要。因此,企业需要更高性能、更高并发、低延迟的数据分析引擎来满足不断增长的数据分析需求。在这种情况下,越来越多的用户开始寻找替代方案。
StarRocks 作为一种新兴的数据分析引擎,在业界已受到广泛的关注。它在性能、高并发和低延迟方面展现出了明显的优势,吸引了包括微信、小红书、携程、贝壳等大型企业的注意。那么,StarRocks 究竟如何构建其优势?与 Trino 相比,它有何异同之处?接下来,我们将围绕这些问题展开深入分析。
StarRocks 与 Trino 相似之处
Massively Parallel Processing (MPP)
两个引擎都采用 MPP 作为其分布式执行框架,在这个框架中,一个查询请求被拆分为众多的逻辑和物理执行单元,并在多个节点上同时运行。与许多其他数据分析产品在其分布式计算框架中使用的 scatter-gather 模式不同,MPP 可以利用更多的资源来处理查询请求。得益于这个框架,两个引擎都可以在 PB 级的数据上使用,数百个大型用户已经在其生产环境中使用了这些引擎。
Cost-based Optimizer (CBO)
两个引擎都内置了高效的基于成本的优化器(CBO),这在处理多表 Join 查询时尤为关键。得益于 CBO,这两个引擎都能够处理包括复杂查询、Join 和聚合在内的多种 SQL 特性。此外,Trino 和 StarRocks 都通过了 TPC-H 和更难的 TPC-DS 基准测试,证明了两者都有极为出色的性能。
Pipeline 执行框架
两个引擎都有 Pipeline 执行框架。Pipeline 执行框架的主要目标是增强查询引擎在单机上利用多核资源的效率,其主要功能包括三个方面:
-
降低查询引擎中各种计算节点的任务调度成本。
-
提高 CPU 利用率,同时处理查询请求。
-
自动调整查询执行的并行度,充分利用多核系统的计算能力,从而提升查询性能。
ANSI SQL 支持
两个引擎都符合 ANSI SQL,分析师可以在日常工作中使用他们最熟悉的查询语言,而无需额外的学习成本。企业经常使用的 BI 工具也将非常容易地与 StarRocks 或 Trino 集成。
StarRocks 与 Trino 区别
向量化查询引擎
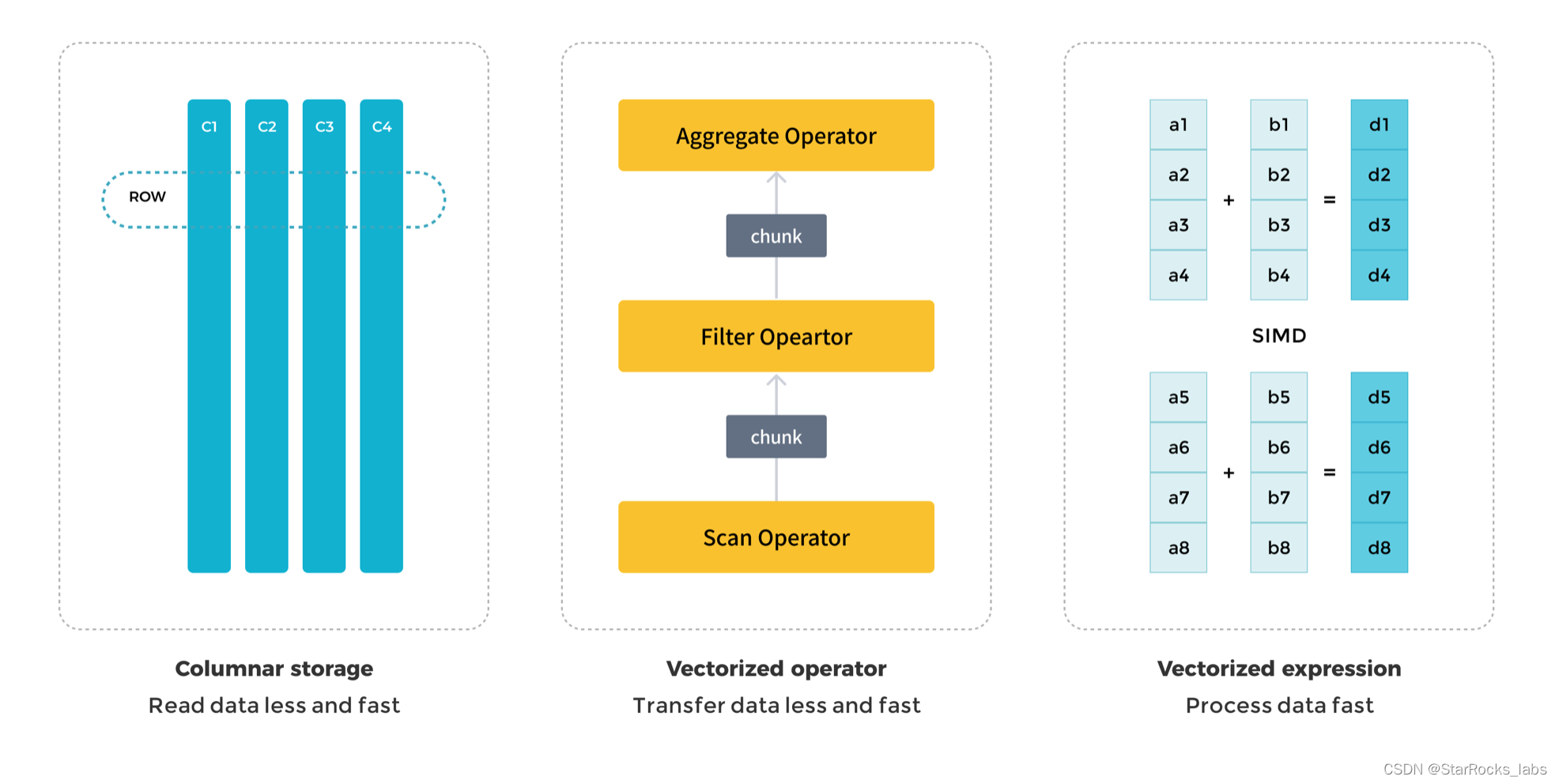
StarRocks 是 C++ 实现的 Native 向量化引擎,而 Trino 是 Java 实现的,使用了有限的向量化技术。向量化技术帮助 StarRocks 更高效地利用 CPU 处理能力。StarRocks 具有以下特点:
-
可以充分利用列式数据管理的效率。StarRocks 从列式存储中读取数据,在内存中管理数据的方式,以及算子处理数据的方式都是列式的,从而可以更有效地利用 CPU 缓存,提高 CPU 执行效率。
-
可以充分利用 CPU 支持的 SIMD 指令。这使得 CPU 可以在更少的时钟周期内完成更多的数据计算,StarRocks 使用向量化指令可以将整体性能提高 3-10 倍。
-
可以更有效地压缩数据,从而大大减少内存占用。这使得这种类型的查询引擎更有能力处理大数据量的查询请求。
事实上,Trino 也在探索向量化技术。Trino 包含 SIMD 代码,但与 StarRocks 相比,在深度和覆盖率方面落后。Meta 的 Velox 项目旨在使用向量化技术来加速 Trino 查询。然而,到目前为止,很少有公司在生产环境中正式使用 Velox。
物化视图
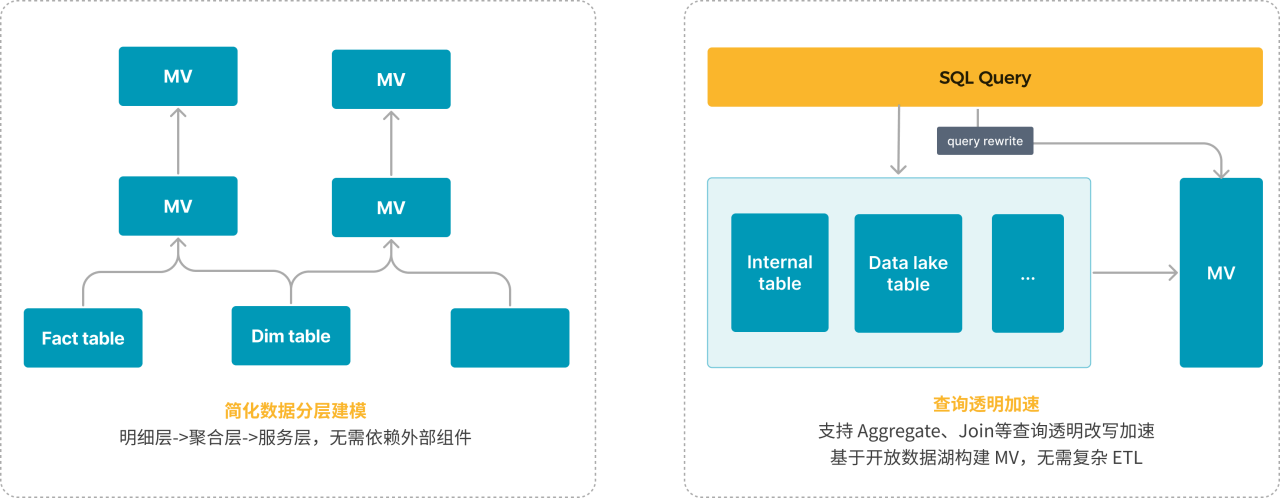
StarRocks 具有几个 Trino 没有的物化视图功能。物化视图是加速查询的常见优化手段,StarRo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









