




 本文介绍了MapReduce的工作流程,从文件在HDFS中的存储,InputFormat读取数据,split切片,map任务处理,到shuffle阶段的分区、排序,再到reduce任务的执行,最后生成最终结果。MapReduce的核心在于shuffle阶段,确保数据的正确处理和传输。
本文介绍了MapReduce的工作流程,从文件在HDFS中的存储,InputFormat读取数据,split切片,map任务处理,到shuffle阶段的分区、排序,再到reduce任务的执行,最后生成最终结果。MapReduce的核心在于shuffle阶段,确保数据的正确处理和传输。
最近几天一直在学习关于大数据方面的相关技术,今天学习了MapReduce的工作流程,让我对数据地处理有了新的认识,接下来我分享一下关于MapReduce2.0的工作流程
Mapreduce简介
Hadoop MapReduce 源于Google发表的 MapReduce论文。Hadoop MapReduce 其实就是Google MapReduce的一个克隆版本。Hadoop 2.0即第二代Hadoop系统,其框架最核心的设计是HDFS、MapReduce和YARN。其中,HDFS为海量数据提供存储,MapReduce用于分布式计算,YARN用于进行资源管理。
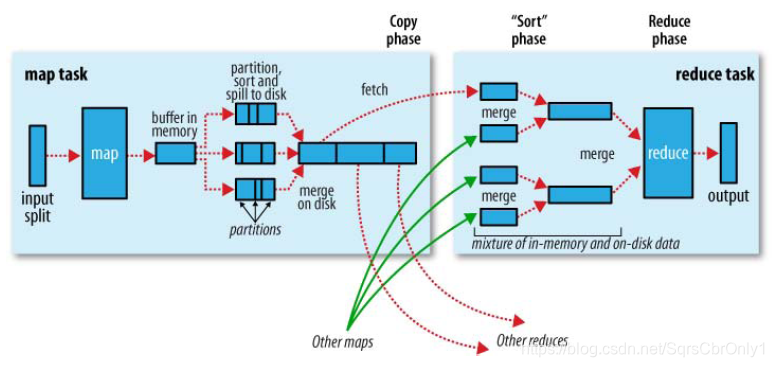
MapReduce的工作流程图
中文版
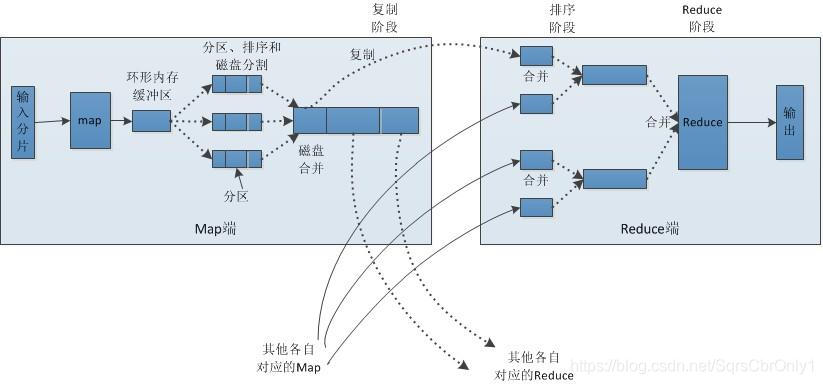 根据图片不难看出mapre的工作流程
根据图片不难看出mapre的工作流程
1.文件要存储在HDFS中,每个文件被切分成多个一定大小的块也就是Block,(Hadoop1.0默认为64M,Hadoop2.0默认为128M),并且默认3个备份存储在多个的节点中。
- MR通过Inputformat将数据文件从HDFS中读入取,读取完后会对数据进行split切片,切片的数量根据Block的大小所决定,然后每一个split的个数又决定map的个数,即一个split会分配一个maptask并行实例处理。说到切片下面讲一下切片的小细节:
1.获取文件大小 fs.sizeOf(ss.txt);
2.计算切片大小 computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=block
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









