




 本文探讨了机器学习中过度拟合的问题,解释了过度拟合的原因,即模型在训练集上表现过好,导致泛化能力下降。文章分析了特征变量过多、数据量不足等情况,并提出了解决方案,包括减少特征值、正则化代价函数等。
本文探讨了机器学习中过度拟合的问题,解释了过度拟合的原因,即模型在训练集上表现过好,导致泛化能力下降。文章分析了特征变量过多、数据量不足等情况,并提出了解决方案,包括减少特征值、正则化代价函数等。
所有的机器学习需要的能力都不是针对标签已知的样本进行判别决策的能力,而是正对未知样本能够正确预测的能力,但是在我们的模型学习过程中,会出现一些过犹不及的现象。
什么是过度拟合
过度拟合(overfitting), 实际上是为了尽可能的减小训练集的误差,从而导致模型过度复杂,泛化能力下降的情况。所谓泛化能力,指的就是对未知样本的预测能力。
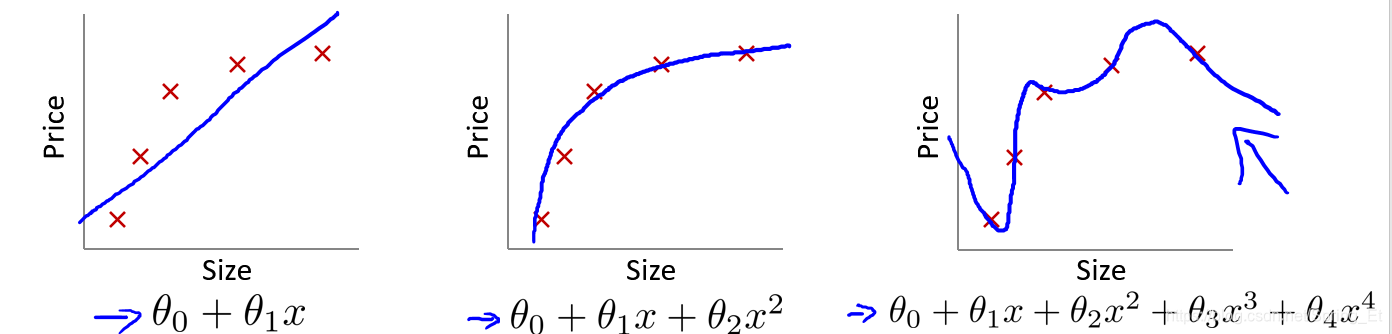
如图所示,在预测面积和房价的案例中。如果我们使用线性图一,过于简单的模型,会使得样本偏离变大,这个叫做欠拟合。而使用第三个曲线,虽然训练样本的方差很小,但是其的泛化能力反而不如图二,原因是引入的方差过大,这就是过度拟合。我们希望选择图二这种平滑而有效的模型
为什么会过度拟合
- 因为特征变量过多,而数据量不足。
- 对影响小的特征变量没有坐有效的限制,使得拟合的模型诡谲多变。
如果解决过度拟合问题
- 减少特征值
可以手动人为的根据经验的减少特质值
也可以在模型中自动的减少特征值 - 正则化代价函数
选择尽可能小的参数,这样一般有两个好处:
- 使得模型更加简单
- 减小过度拟合的可能性
在线性拟合和逻辑拟合的代价函数是:
J(θ)=12m[∑i=1m(hθ(x(i)−y(i)))]
J(\theta)=\frac{1}{2m}[\sum_{i=1}^{m}(h_\theta( x^{(i)}-y^{(i)}))]
J(θ)=2m1[i=1∑m(hθ(x(i)−y(i)))]
在这个过程中,为了获得尽可能小的参数我们在代价函数中加入如下的项:
J(θ)=12m[∑i=1m(hθ(x(i)−y(i)))+λ∑j=1mθj2]
J(\theta)=\frac{1}{2m}[\sum_{i=1}^{m}(h_\theta( x^{(i)}-y^{(i)}))+\lambda \sum_{j=1}^{m}\theta_j^2]
J(θ)=2m1[i=1∑m(hθ(x(i)−y(i)))+λj=1∑mθj2]
我们通过选择合适的θ\thetaθ 值来优化上面的代价函数。
值得注意得是,λ\lambdaλ相当于对θ\thetaθ大小的代价因子,不宜选择过大。否则我们会趋于将所有的θ\thetaθ都取为0,这个时候我们的模型就接近一个常数模型了(除了第一个参数以外,所有的参数都为0的情况)
正则化问题求解
我们对回归正则化以后,
J(θ)=12m[∑i=1m(hθ(x(i)−y(i)))+λ∑j=1mθj2]
J(\theta)=\frac{1}{2m}[\sum_{i=1}^{m}(h_\theta( x^{(i)}-y^{(i)}))+\lambda \sum_{j=1}^{m}\theta_j^2]
J(θ)=2m1[i=1∑m(hθ(x(i)−y(i)))+λj=1∑mθj2]
也就是说需要求解参数使得J最小
minθJ(θ)
\min_{\theta} J(\theta)
θminJ(θ)
我们依然使用梯度下降,也就是对正则因子进行求偏导:
θj:=θj−α∂∂θjJ(θ)
\theta_j :=\theta_j-\alpha \frac{\partial}{\partial \theta_j}J(\theta)
θj:=θj−α∂θj∂J(θ)
也就是,
θj:=θj−α[1m∑i=1m(hθ(xi)−yi)xji+λmθj]
\theta_j :=\theta_j-\alpha [\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^i)-y^i)x_j^i+\frac{\lambda}{m}\theta_j]
θj:=θj−α[m1i=1∑m(hθ(xi)−yi)xji+mλθj]
也就是
θj:=(1−αλm)θj−α1m∑i=1m(hθ(xi)−yi)xji
\theta_j :=(1-\alpha\frac{\lambda}{m})\theta_j-\alpha \frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^i)-y^i)x_j^i
θj:=(1−αmλ)θj−αm1i=1∑m(hθ(xi)−yi)xji


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









