




 本文总结了在使用PyTorch过程中遇到的TensorBoard安装和使用的问题,以及pycocotools在Windows环境下的安装方法。对于TensorBoard,重点讨论了安装检查和使用时可能出现的错误及解决方案;对于pycocotools,提供了Windows系统的安装指南链接。
本文总结了在使用PyTorch过程中遇到的TensorBoard安装和使用的问题,以及pycocotools在Windows环境下的安装方法。对于TensorBoard,重点讨论了安装检查和使用时可能出现的错误及解决方案;对于pycocotools,提供了Windows系统的安装指南链接。
一、TensorBoard
1、安装
在PyTotch中使用TensorBoard是,首先要确保安装了以下包:
pip install tb-nightly
pip install future
输入from torch.utils.tensorboard import SummaryWriter后不会出错,则表明环境安装正确
- 若没有安装
tb-nightly,则输入from torch.utils.tensorboard import SummaryWriter后,会出现如下错误:

2.若没有安装future,则输入from torch.utils.tensorboard import SummaryWriter后,会出现如下错误:

2、使用
1.tensorboard --logdir=runs
使用上述命令时,可能会出现如下错误:
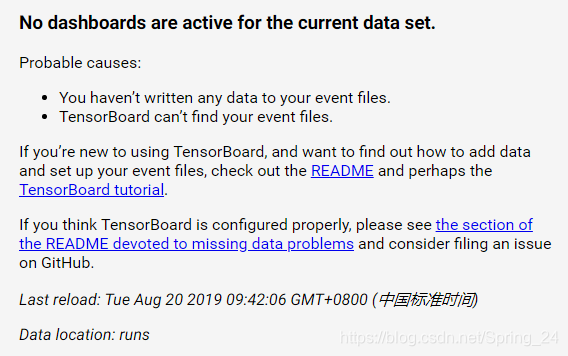
这时,只需将runs修改为具体的文件路径即可,即使用tens
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2069
2069





 到【灌水乐园】发言
到【灌水乐园】发言









