 RPA项目:网站文章超链接获取实现
RPA项目:网站文章超链接获取实现





一、需求概述
在网站中指定页面中,获取指定时间范围内的文章的超链接,其中时间范围可通过输入框更改。
二、思路概述
可将实现思路分为几个部分
1、运行组件前的检查
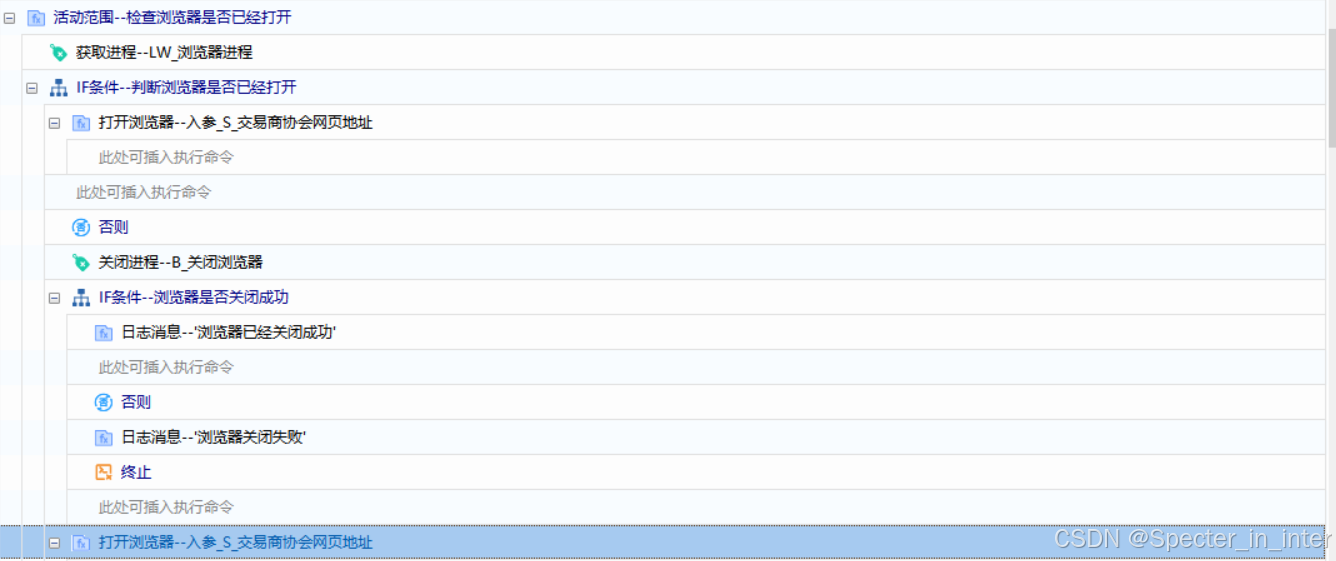
(1)判断浏览器是否已经打开
实现思路:
先获取浏览器进程判断浏览器是否已经打开,如果没打开就打开浏览器,如果已经打开就先关闭进程,判断是否已经关闭成功,如果关闭浏览器成功再打开浏览器,关闭失败就直接终止组件并报错。
实现模板:
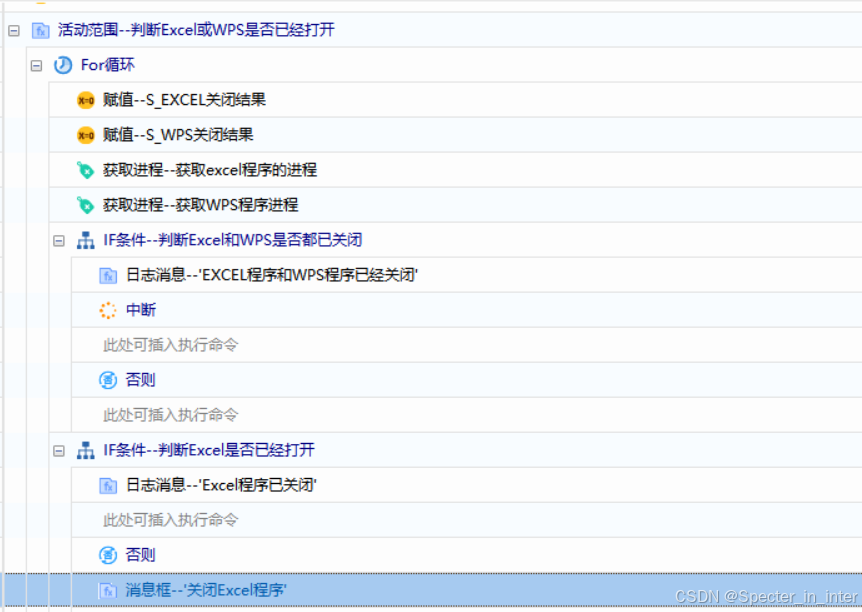
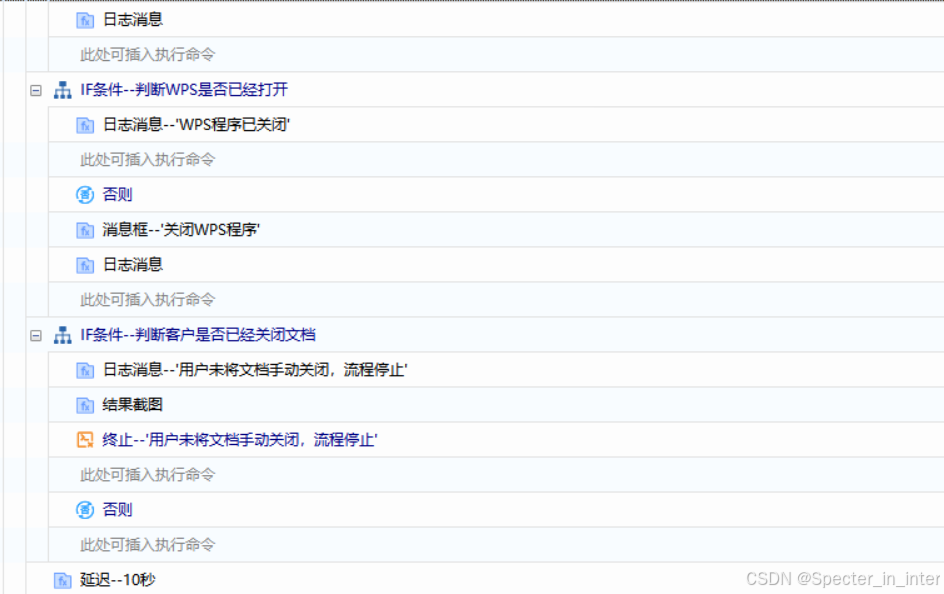
(2)判断文件是否已经打开,如果打开该怎么关闭
实现思路模板:
循环判断n次(n自定义),设S_EXCEL关闭结果、S_WPS关闭结果(消息框返回值)的默认值为“Yes”,然后获取EXCEL与WPS的进程,判断是否都已经关闭;如果没关闭就分别判断谁没关闭,并通过消息框提示用户手动关闭程序,当客户点击的按钮不为【是】或循环提示的次数超过n次时就直接终止组件运行。
注意:每次循环后需要延迟10秒后再进行是因为手动关闭程序时,程序会过几秒后才能完全关闭,如果手动关闭马上进行获取进程就会造成程序还存在的现象。
2、网页跳转实现
实现思路因网站而异,不存在绝对的实现思路,但是还是存在几个需要注意的要点:
(1)每次跳转时,需要通过【存在元素】去判断是否跳转网页成功,并且无论跳转成功与否都需要用【日志消息】输出一下跳转结果。除非在同一网站切换菜单栏跳转页面,并无网址的改变就可不用【存在元素】判断跳转成功与否,但还是得输出跳转到哪个页面的日志。
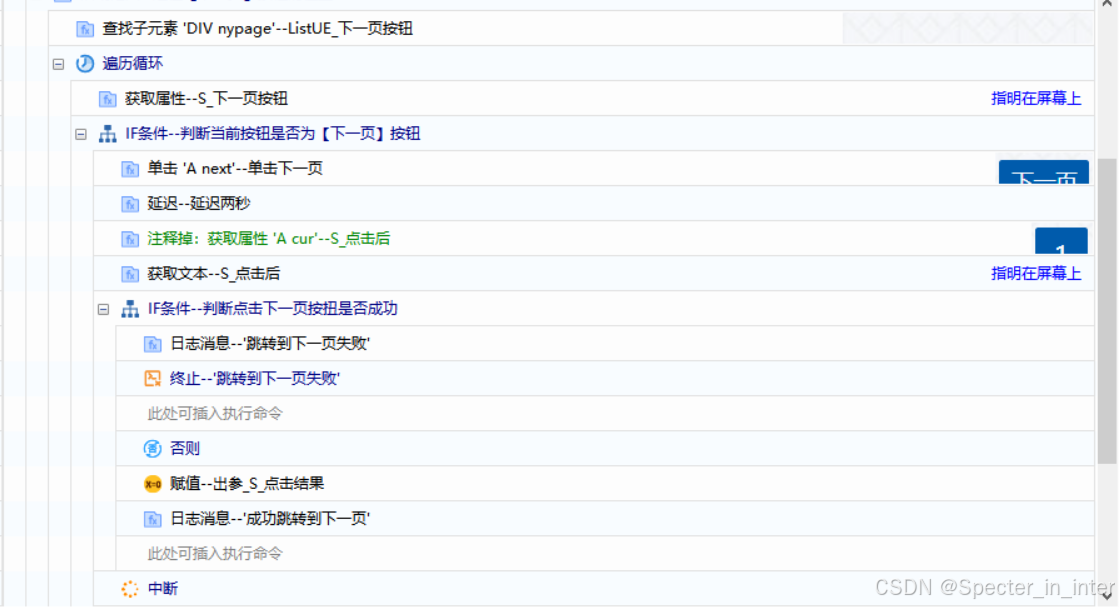
3、点击下一页
当页面中需要点击下一页按钮实现翻页操作时,并且同一个系统网站中的页数框的元素大致是相同的,那么这时候就可将这个功能单独作为一个组件
实现思路:
(1)判断是否存在页数框,如果不存在就终止(正常)组件
(2)判断总页数,将总页数作为后面判断当前页数是否大于等于总页数的依据
(3)点击【下一页】按钮:先获取当前页数,判断当前页数是否大于等于总页数,如果是,就终止(正常)组件,并输出“当前页数为最大页数”。通过【查找子元素】、【遍历循环】、【获取属性】或【获取文本】来判断【下一页】按钮所在处,获取到后进行单击并在延迟几秒后再次获取当前页数,将前后的当前页数进行对比来判断是否成功跳转到下一页。如果跳转失败就终止组件,如果成功就中断【遍历循环】并输出参数''True''。
4、网址拼接
因为在网页列表中获取的文章路径是不完整的(后面统称添加字段),需要将网址进行拼接。
实现思路:
当前的不完整的网址开头有几个格式——>./、../、/、https:
(1)判断添加字段开头是否为'https:'
如果添加字段为'https:'时,直接终止组件,直接输出添加字段的字符串
(2)判断入参网址的末位字符串是否为'/'
通过【右字符】获取入参网址的末位字符串,判断末尾字符串是否为'/',如果是就不管,否则就在网址后面加'/'
(3)判断添加字段前面的符号(循环次数为添加字符串长度)
1)如果为../
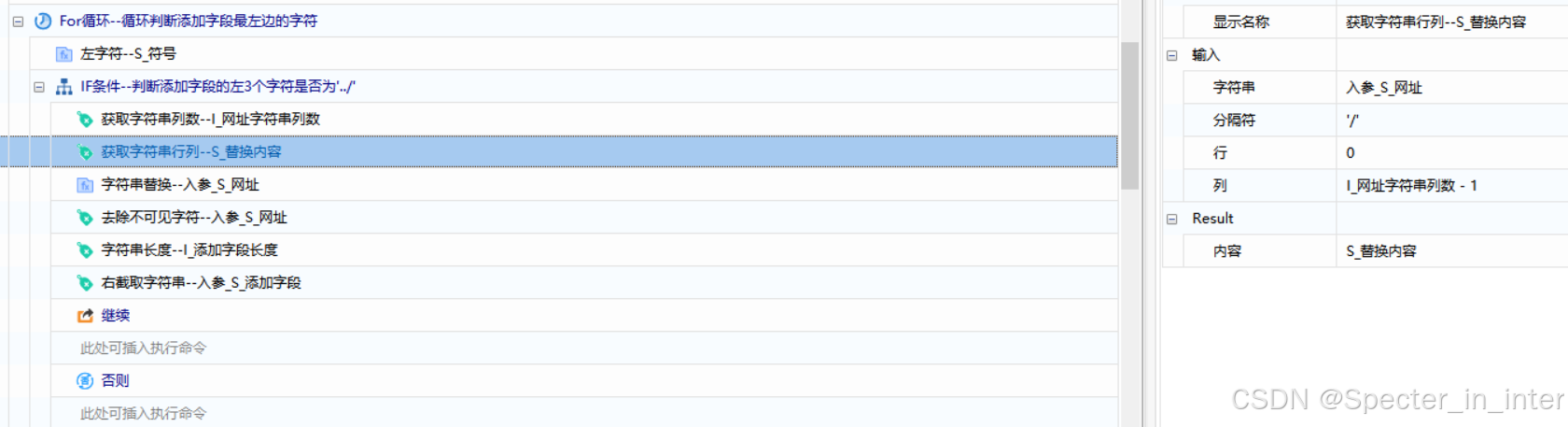
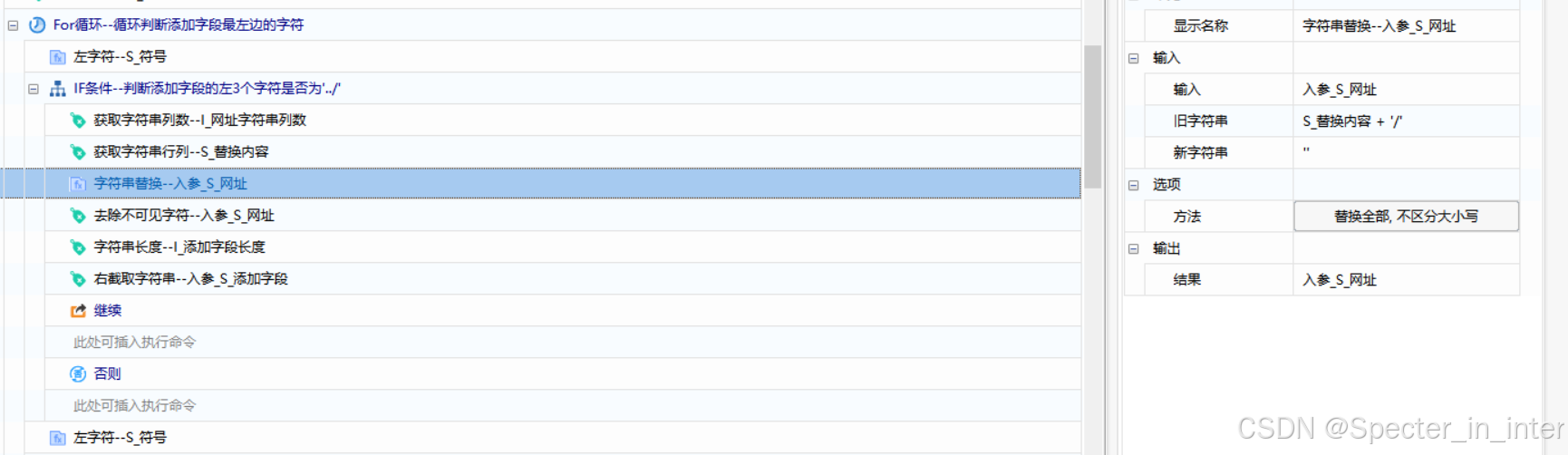
通过【左字符】获取添加字符串开头3个字符,判断获取的字符串是否为'../',如果是就去除添加字段的开头的三个字符串,然后通过【获取字符串行列】以''/''为分割符号分割入参网址,获取字符串列中最后一个字符串,将其替换成空,
2)如果为./
通过【左字符】获取开头一个字符串,判断其是否为'.',如果是就通过【右截取字符串】去除开头的一个字符串

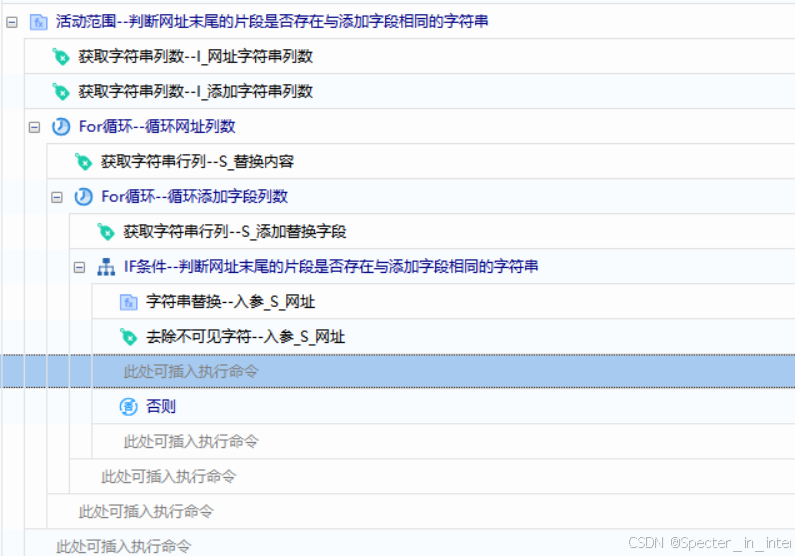
3)判断网址末尾的片段是否存在与添加字段相同的字符串
将入参网址、添加字段以'/'为分割符进行分割,将入参网址分割后的字符串列表(从尾到头)与添加字段分割后的字符串列表(从头到尾)中的字符串一一进行对比,如果出现相同的情况,入参网址就要把相同的字符串替换为空。
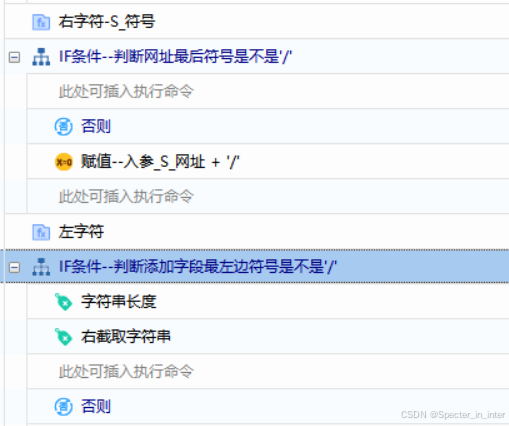
4)再次判断入参网址末尾、添加字段开头是否为'/'
入参网址末尾如果不为'/'时,就在末尾加'/',否则不管。
添加字段开头为'/'时,去除开头的字符串,否则不管
5)拼接字符,将拼接结果作为出参值
5、超链接录入文件
(1)判断需要写入链接的所在列,并获取该列的字母
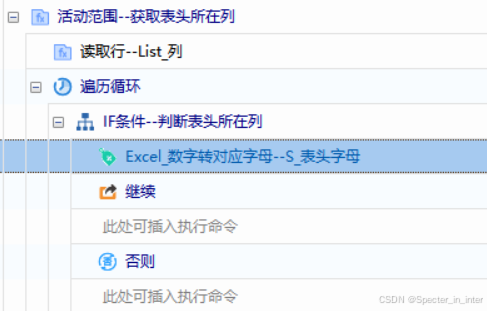
(2)查找网页列表元素,获取文章发布时间
(3)将获取到的时间格式化成【YYYY-MM-DD 00:00:00】格式(for循环次数为总页数)
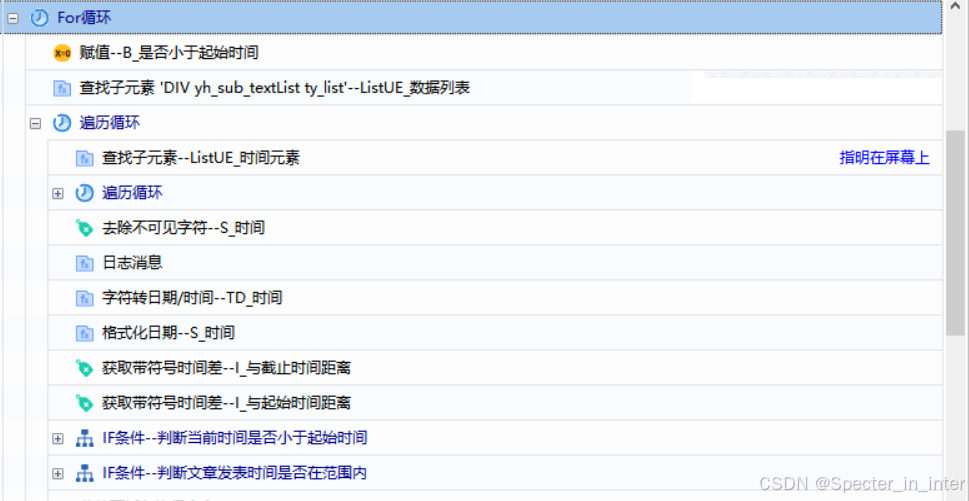
(4)通过【获取带符号时间差】判断获取到的时间是否在规定时间范围内,如果当前时间小于起始时间,那么就直接中断循环,并更改中断标记,使外循环一起被中断;如果在时间范围内就进行写入操作
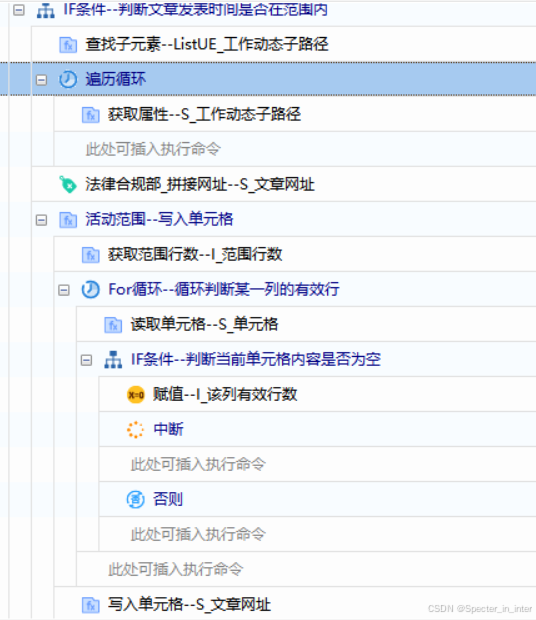
(5)写入操作
获取文章的子路径,并将路径拼接起来形成完整的网址,然后在指定列表内写入单元格。循环读取单元格是为了判断指定列的有效行数,用于追加写入内容
注意:可使用【插入Js脚本】获取当前网页的网址作为入参网址,获取当前网页代码为(代码不唯一):
'function geturl(){ var url = document.URL; return url };'
6、整体流程
先检查各个程序是否已经关闭,然后跳转到指定页面,在指定页面里获取符合时间范围要求的文章的子路径,将这些作为添加字段,并于获取到的网页进行拼接,最后将拼接完成的网址写入指定的列里,最后保存关闭工作簿,关闭浏览器。
具体实现的组件有:

三、项目总结
1、碰到的困难以及解决方法
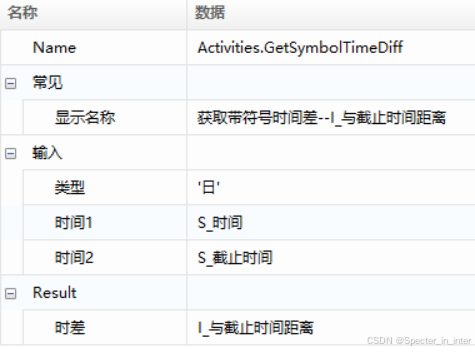
(1)困难:不知如何比较时间,判断当前获取到的时间是否在规定的时间范围内
解决方法:使用【获取带符号时间差】,该函数可通过时间2减时间1的方式求得时间差,类型可根据自身要求的时间单位进行更改,如‘年’、‘月’、‘日’、‘时’等。
(2)困难:在组件运行过程中,偶尔【获取属性】出现获取不到元素的问题
解决方法:将【获取属性】更换为【获取文本】,执行起来更加稳定。
(3)困难:频繁更改【拼接网址】组件,导致项目进展缓慢。
解决方法:在拼接网址时,应到各个不同页面查看其子路径的格式,先列举各个格式的拼接方式,再去具体实行组件,不要看一个改一个,会比较浪费时间。
(4)困难:写一个项目所耗费的时间太长了。原定5天实则7天
解决方法:在做项目前,先得仔细查阅需求说明书并认真过一遍流程,了解在实现项目前需要做哪些前提准备——检查某个程序是否已经关闭或打开,思考哪些功能可作为一个通用组件,如果该组件涉及到获取元素,得一个个查看相关页面并观察定位元素是否都相同。在空闲时可以自己做一些通用模板——登录浏览器,检查Excel是否已经关闭等不涉及元素的通用组件,到时候需要用时可直接导入使用,减少重复编程的时间。
2、项目实现后所注意到的事项
(1)在执行【查找子元素】、【遍历循环】时发现,遍历次数与预期不符合,导致多次出现错误。其原因是在【查找子元素】筛选获取子元素集合时,发现查找的源元素除了原本需要查询的子元素还多了其他不相关的元素,导致遍历次数过多从而出现运行错误。造成这一过错完完全全是自身粗心大意导致的。
(2)在实现项目功能时不断的修修改改,导致项目进程缓慢。其原因是在实现项目前并没有仔细的需求概述并规划所需要实现的通用组件与专用组件,导致在编写过程中不断修修改改

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









