



数据是互联网的石油,如何从石油中提取自己想要的部分,爬虫可以很好的帮助我们找到
打开豆瓣的top250榜单,按F12 控制台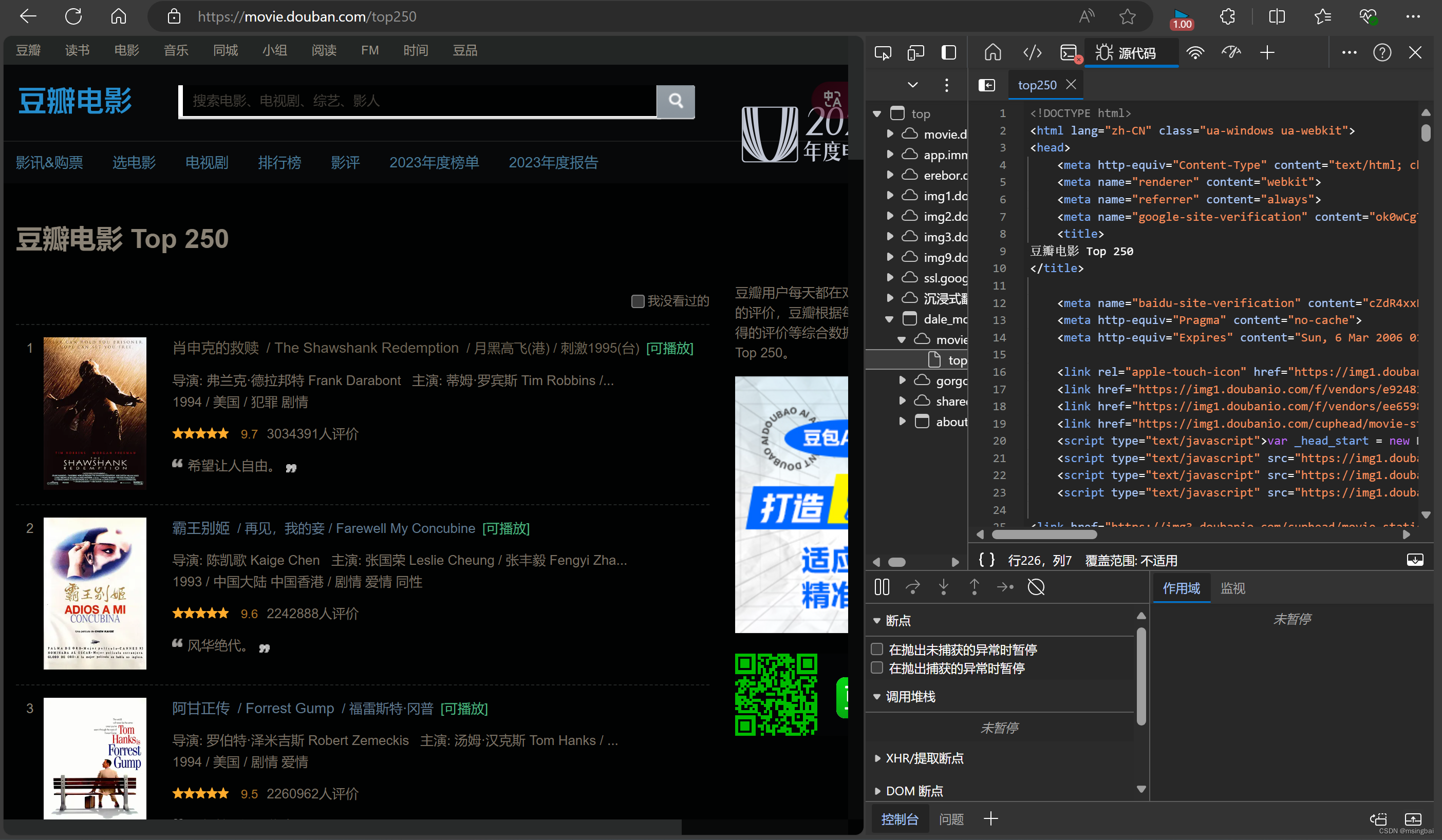
右侧可看到网页的html源代码,找到电影信息的部分
以肖申克的救赎为例,(这部电影的原作也很棒)
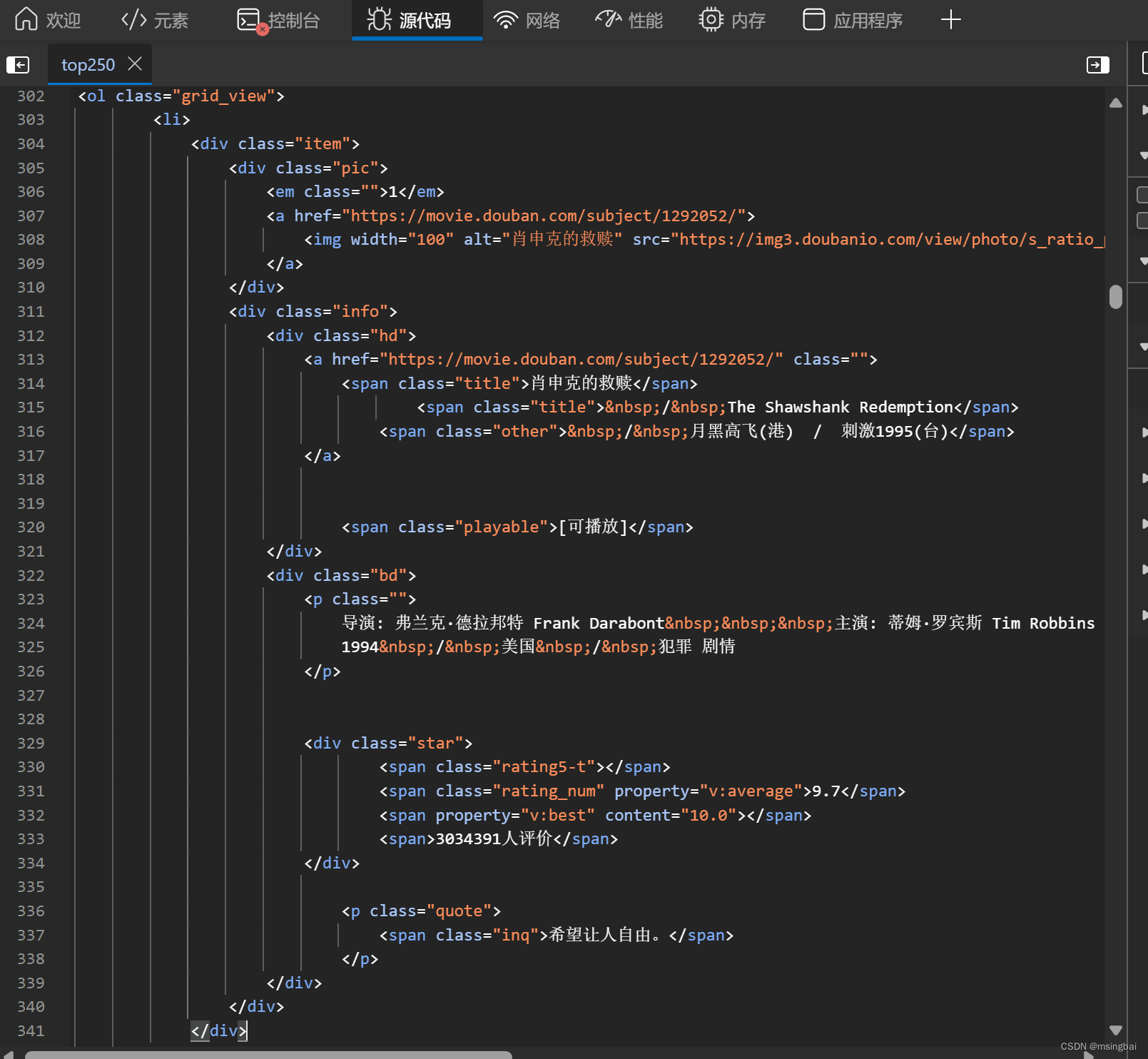
可以看到标签<div item>
<div> 标签定义 HTML 文档中的分割或部分(分区或小节,division/section)。
用 class 来标记 <div>,那么该标签的作用会变得更加有效。通过使用 class 属性,可以轻松地对 <div> 标签设置样式。
import requests
from bs4 import BeautifulSoup
import pandas as pd
#豆瓣电影Top250的url
base_url = 'https://movie.douban.com/top250'
#定义一个函数来获取页面内容
def get_page_content(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
else:
print('请求页面失败:',response.stats_code)
return None
#定义一个函数解析页面内容
def parse_page_content(html):
soup = BeautifulSoup(html,'html.parser')
movie_list = soup.find_all('div',class_='item')
movies = []
for movie in movie_list:
title = movie.find('span',class_='title').get_text()
rating = movie.find('span',class_='rating_num').get_text()
director = movie.find('p',class_='').get_text()
movies.append({'title':title,'rating':rating,'director':director})
return movies
#定义保存文件函数
def save_to_csv(movies):
df = pd.DataFrame(movies)
df.to_csv('douban_top250.csv',index=False,encoding='utf_8_sig')
def main():
movies = []
for i in range(0,250,25): #豆瓣电影top250分为10页,每页25部
url = f'{base_url}?start={i}&filter='
html = get_page_content(url)
if html:
movies.extend(parse_page_content(html))
save_to_csv(movies)
print('爬取完成,数据已保存到douban_top250.csv')
#运行主函数
if __name__ == '__main__':
main()


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









