



 本文探讨了在Python中初始化二维列表时遇到的问题,通过示例展示了使用`list*`和列表推导式两种方式创建二维列表的区别。重点在于解释了为什么使用`list*`会导致所有子列表共享同一内存空间,从而在修改一个子列表时影响所有子列表。通过对比两种创建方式的内存地址,证明了列表推导式的独立性,为避免意外的共享状态提供了解决方案。
本文探讨了在Python中初始化二维列表时遇到的问题,通过示例展示了使用`list*`和列表推导式两种方式创建二维列表的区别。重点在于解释了为什么使用`list*`会导致所有子列表共享同一内存空间,从而在修改一个子列表时影响所有子列表。通过对比两种创建方式的内存地址,证明了列表推导式的独立性,为避免意外的共享状态提供了解决方案。
最近开始学习算法,在牛客网刷到一个题:
使用
res = list[[]] * len(R)创建数组的时候后续对单独一个内部数组进行写入操作时候会影响所有的内部数组,如图所示:
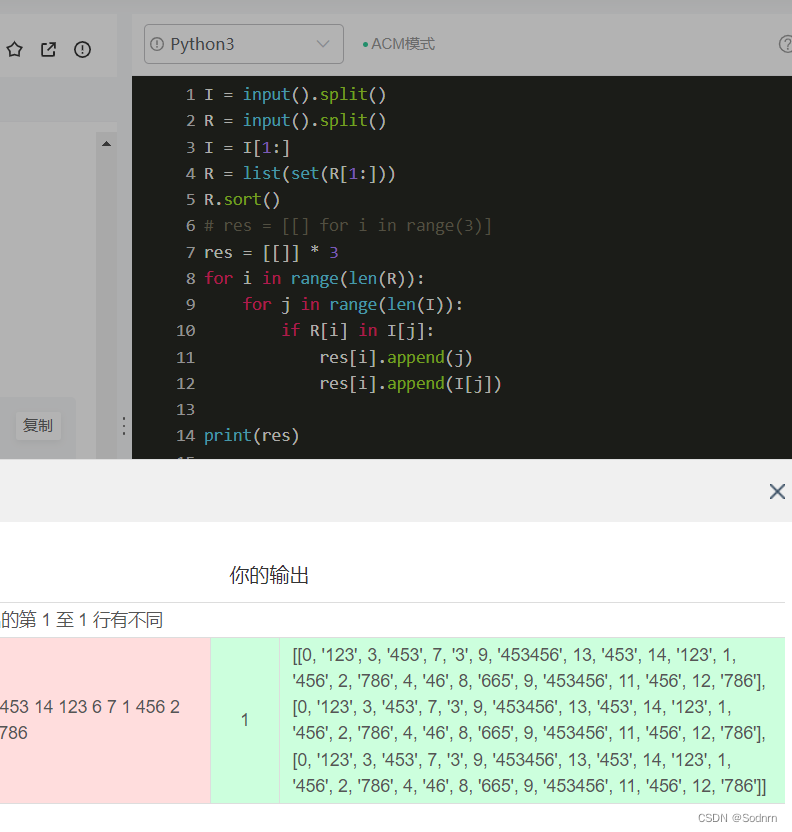
使用:
res = [[] for i in range(len(R))]创建就不会产生相似问题。
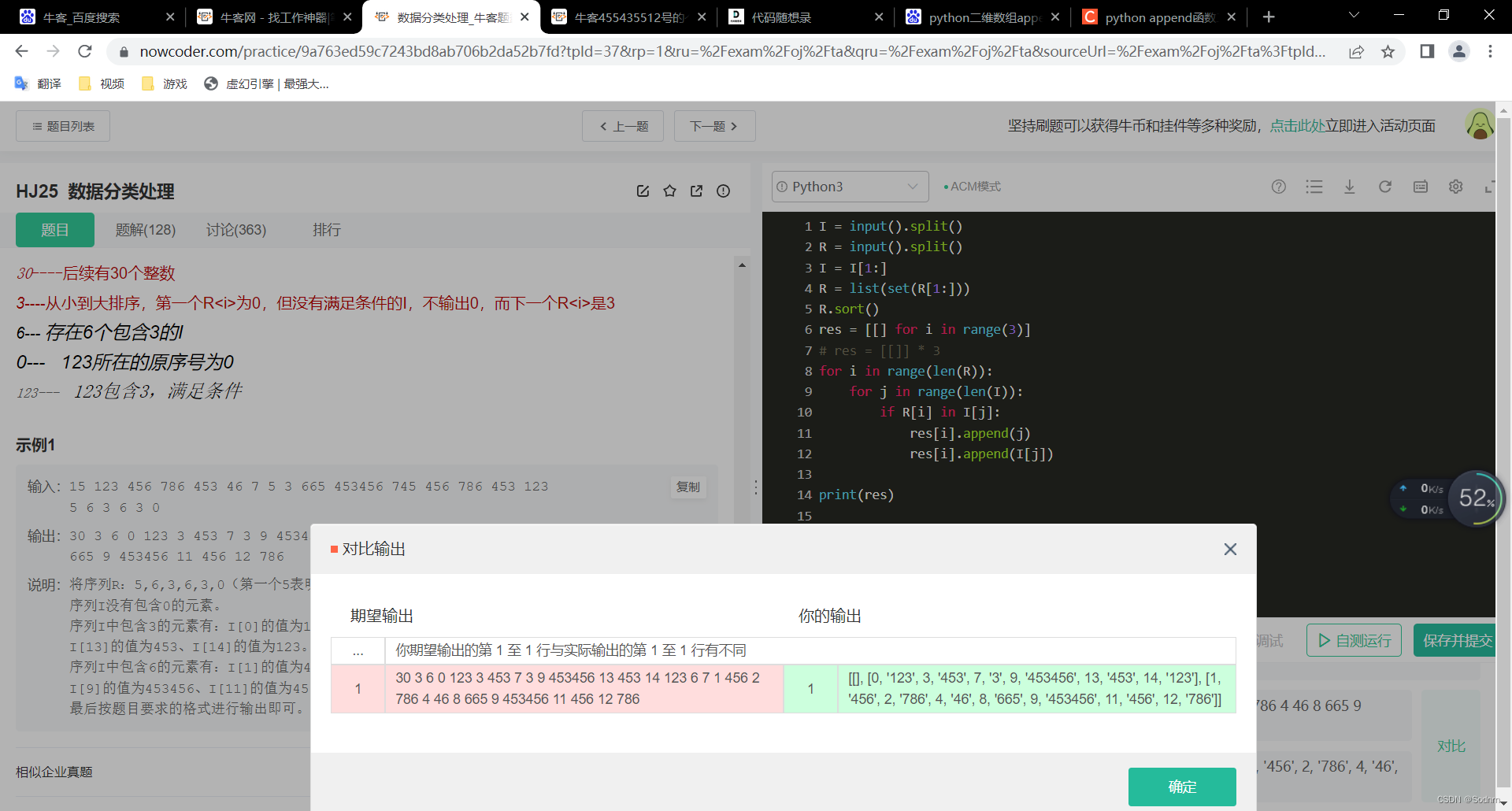
在网上搜索了一下,发现是第一种创建二维数组的方法会让他产生浅拷贝,也就是说所有的子列表指向的是同一块内存空间,所以当操作其中一个字列表时候,所有子列表引用的内容都会发生改变。
下面是在代码中验证,按照两种创建方式分别创建列表,然后输出他们子列表的内存地址
copy_list = [[]] * 3
print("copy_list子列表的内存地址: ",hex(id(copy_list[0])), hex(id(copy_list[1])), hex(id(copy_list[2])))
normal_list = [[] for i in range(3)]
print('normal_list子列表的内存地址: ', hex(id(normal_list[0])), hex(id(normal_list[1])), hex(id(normal_list[2])))输出结果:

可以看出第一个二维列表所有子列表的内存空间是同一块地址,而第二个二维列表所有子列表的内存地址各不相同,由此可以得知一开始操作一个子列表,所有子列表数组都发生改变的原因。

















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









