




 本文详细介绍了Hadoop的安装部署流程,包括下载、配置、环境变量设定及HDFS文件系统的基本操作,如文件上传、下载、移动、删除等,并提供了在Windows环境下操作Hadoop的特殊配置说明。
本文详细介绍了Hadoop的安装部署流程,包括下载、配置、环境变量设定及HDFS文件系统的基本操作,如文件上传、下载、移动、删除等,并提供了在Windows环境下操作Hadoop的特殊配置说明。
目录
2.1.1 修改hadoop-env.sh 指定Java的安装目录
2.1.2 修改core-site.xml --指定hadoop的默认文件系统
2.1.3 修改hdfs-site.xml 指定namenode、datanode存储的本地目录
2.1.4 拷贝整个hadoop安装目录到其他机器(先创建apps目录)
2.1.5 配置Hadoop命令的环境变量,便于手动启动和调试
2.3.3 hadoop 在 windons 上操作需先修改以下内容:
1. Hadoop安装部署
1.1 Hadoop安装包下载:
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/
具体目录:
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz1.2 下载后上传文件并解压:
tar -zxvf hadoop-2.10.0.tar.gz -C /apps解压后可删除压缩包和/share/doc 文件夹(文档),节省空间。
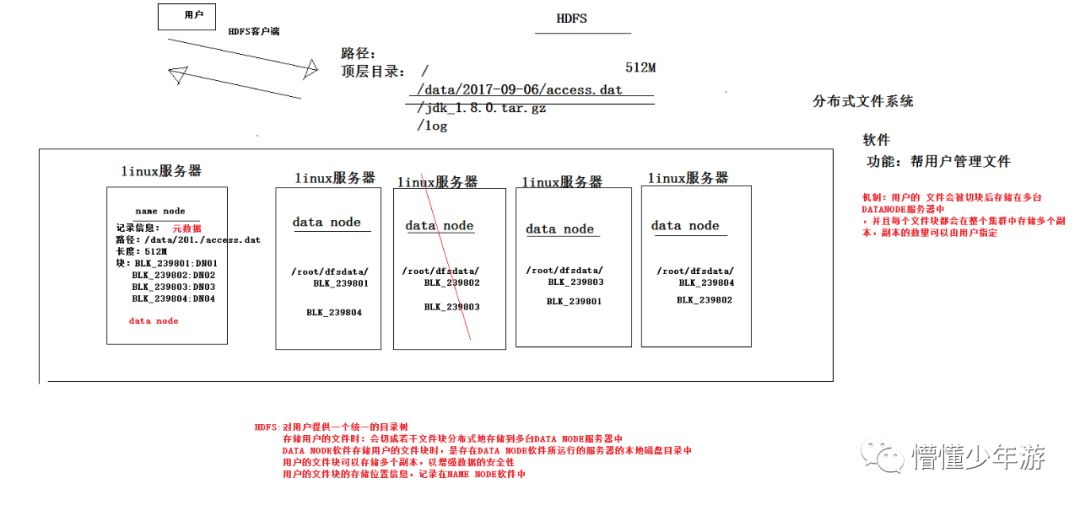
2.HDFS文件系统操作
2.1修改配置文件
需要修改以下参数
1)指定hadoop的默认文件系统为:hdfs
2)指定hdfs的namenode节点为哪台机器
3)指定namenode软件存储元数据的本地目录
4)指定datanode软件存放文件块的本地目录
配置文件目录:/root/apps/hadoop-2.10.0/etc/hadoop
2.1.1 修改hadoop-env.sh 指定Java的安装目录
export JAVA_HOME=/root/apps/jdk2.1.2 修改core-site.xml --指定hadoop的默认文件系统
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp-01:9000</value>
</property>
</configuration>2.1.3 修改hdfs-site.xml 指定namenode、datanode存储的本地目录
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/dfs/data</value>
</property>
</configuration>2.1.4 拷贝整个hadoop安装目录到其他机器(先创建apps目录)
scp -r /root/apps/hadoop-2.10.0 hdp-01:/root/apps/hadoop-2.10.0
scp -r /root/apps/hadoop-2.10.0 hdp-02:/root/apps/hadoop-2.10.0
scp -r /root/apps/hadoop-2.10.0 hdp-03:/root/apps/hadoop-2.10.02.1.5 配置Hadoop命令的环境变量,便于手动启动和调试
vi /etc/profile
export HADOOP_HOME=/root/apps/hadoop-2.10.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin2.2启动hdfs
2.2.1 初始化namenode的元数据目录
hadoop namenode -format
# 创建一个全新的元数据存储目录
# 生成记录元数据的文件fsimage
# 生成集群的相关标识:如:集群id——clusterID等,再次初始化时变更。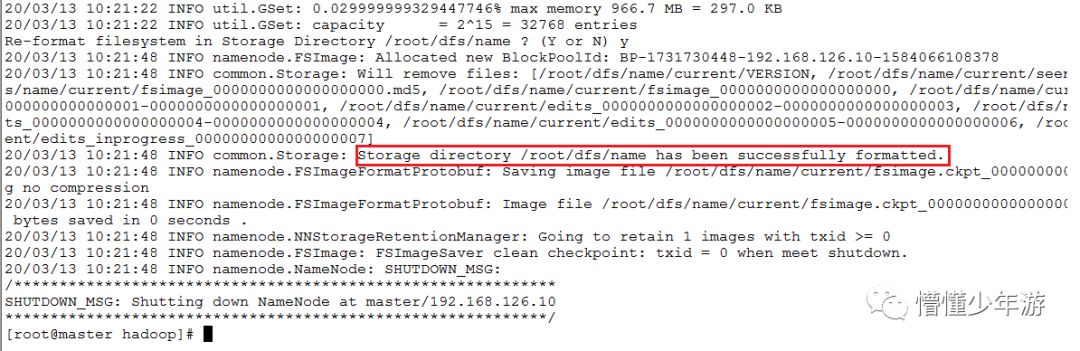
已生成datanode数据后,初始化namenode,会导致2者的clusterID不一致而无法启动dataNode.
解决方法:
修改以下文件内的clusterID,保持一致即可
vi /root/dfs/data/current/VERSION
vi /root/dfs/data/current/VERSION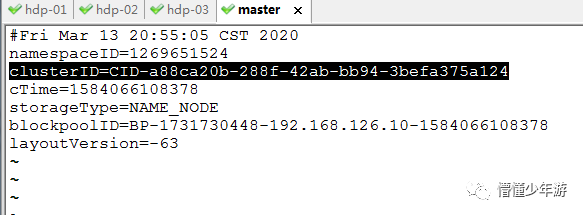
2.2.2 启动namenode进程(在master上)
hadoop-daemon.sh start namenode
# 可以浏览器访问namenode提供的web端口:500702.2.3 启动多个datanode(在任意节点)
hadoop-daemon.sh start datanode2.2.4 用自动批量启动脚本来启动HDFS
先配置master到集群中所有节点(包含自己)的免密登陆
修改hadoop安装目录中/etc/hadoop/slaves(把需要启动datanode进程的节点列入)
hdp-01
hdp-02
hdp-03
hdp-04master上执行:(或同步所有节点/profile文件及互相之间的免密登录后,任意节点执行)
start-dfs.sh
stop-dfs.sh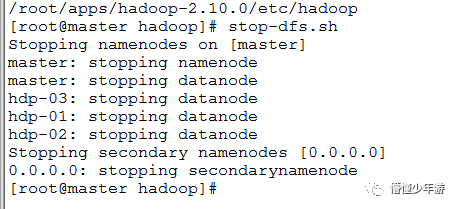
2.3 hdfs的客户端操作
hdfs的客户端有多种形式:网页形式、命令行形式、客户端在哪里运行,没有约束,只要运行客户端的机器能够跟hdfs集群联网
文件的切块大小和存储的副本数量,都是由客户端决定,是通过配置参数来定的
切块大小的参数:dfs.blocksize
副本数量的参数:dfs.replication
上面两个参数应该配置在客户端机器的hadoop目录中的hdfs-site.xml中配置
<property>
<name>dfs.blocksize</name>
<value>64m</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>2.3.1 hdfs命令行客户端的常用操作命令
hadoop fs -ls /hdfs路径 # 查看hdfs中的目录信息
hadoop fs -put /本地文件 /aaa # 上传文件到hdfs中
hadoop fs -copyFromLocal /本地文件 /hdfs路径 # copyFromLocal等价于 put
hadoop fs -moveFromLocal /本地文件 /hdfs路径 # 跟copyFromLocal的区别是:从本地移动到hdfs中
hadoop fs -get /hdfs中的路径 /本地磁盘目录 # 下载文件到客户端本地磁盘
hadoop fs -copyToLocal /hdfs中的路径 /本地磁盘路径 # 跟get等价
hadoop fs -moveToLocal /hdfs路径 /本地路径 # 从hdfs中移动到本地
hadoop fs -mkdir -p /aaa/xxx # 在hdfs中创建文件夹
hadoop fs -mv /hdfs的路径 /hdfs的另一个路径 # 移动hdfs中的文件(更名)
hadoop fs -cp /hdfs的路径 /hdfs的另一个路径 # 复制hdfs中的文件(更名)
hadoop fs -rm -r /aaa #删除hdfs中的文件或文件夹
hadoop fs -chown user:group /aaa # 修改文件的用户、组 可设置系统不存在的用户和组,与linux不同
hadoop fs -chmod 700 /aaa # 修改文件的权限
hadoop fs -appendToFile /本地文件 /hdfs中的文件 # 追加内容到已存在的文件
hadoop fs -cat /hdfs中的文件 # 显示文本文件内容
hadoop fs -tail /hdfs中的文件 # 显示文本文件尾部内容 -f实时 默认20行 没有-n 控制行数功能2.3.2 hdfs的java客户端编程
将hdfs客户端开发所需的jar导入工程
\common\hadoop-common-2.10.0.jar
\common\lib
\hdfs\hadoop-hdfs-2.10.0
\hdfs\hadoop-hdfs-client-2.10.0
\hdfs\libhdfs文件客户端创建
public static void main(String[] args) throws Exception {
/**
* Configuration参数对象的机制:
* 构造时,会加载jar包中的默认配置 xx-default.xml
* 再加载 用户配置xx-site.xml ,覆盖掉默认参数
* 构造完成之后,还可以conf.set("p","v"),会再次覆盖用户配置文件中的参数值
*/
// new Configuration()会从项目的classpath中加载core-default.xml hdfs-default.xml core-site.xml hdfs-site.xml等文件
Configuration conf = new Configuration();
// 指定本客户端上传文件到hdfs时需要保存的副本数为:2
conf.set("dfs.replication", "2");
// 指定本客户端上传文件到hdfs时切块的规格大小:64M
conf.set("dfs.blocksize", "64m");
// 构造一个访问指定HDFS系统的客户端对象: 参数1:——HDFS系统的URI,参数2:——客户端要特别指定的参数,参数3:客户端的身份(用户名)
FileSystem fs = FileSystem.get(new URI("hdfs://master:9000/"), conf, "root");
// 上传一个文件到HDFS中
fs.copyFromLocalFile(new Path("D:/jdk-8u141-linux-x64.tar"), new Path("/aaa/"));
fs.close();
}
fs.copyToLocalFile(new Path("/hdp20-05.txt"), new Path("f:/")); //从HDFS中下载文件到客户端本地磁盘
fs.rename(new Path("/install.log"), new Path("/aaa/in.log")); //在hdfs内部移动文件\修改名称
fs.mkdirs(new Path("/xx/yy/zz")); //在hdfs中创建文件夹
fs.delete(new Path("/aaa"), true); //在hdfs中删除文件或文件夹
//查询hdfs指定目录下的文件信息
RemoteIterator<LocatedFileStatus> iter = fs.listFiles(new Path("/"), true);
while(iter.hasNext()){
LocatedFileStatus status = iter.next();
System.out.println("文件全路径:"+status.getPath());
System.out.println("块大小:"+status.getBlockSize());
System.out.println("文件长度:"+status.getLen());
System.out.println("副本数量:"+status.getReplication());
System.out.println("块信息:"+Arrays.toString(status.getBlockLocations()));
}2.3.3 hadoop 在 windons 上操作需先修改以下内容:
1)下载winutils工具
https://github.com/steveloughran/winutils
解压后选择就近版本的hadoop/bin 替换Hadoop安装包下的/bin目录
2)配置环境变量
HADOOP_HOME E:\hadoop-2.10.0 #hadoop安装目录
PATH ;E:\hadoop-2.10.0\bin #hadoop/bin目录
Java环境变量配置不赘述
主要配置文件
core-default.xml
hdfs-default.xml
core-site.xml
hdfs-site.xml
















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









