




任务:只给出图像目标类别级的标签,不给位置标签。
摘要
本文的主要思想:
背景中包含很多有用的潜在信息,例如天空中的飞机,如果可以学习到这些潜在的信息,就可以减少目标-背景歧义来抑制背景。本文提出了潜在类别学习(latent category learning LCL),这是一个无监督的学习问题,只给出图像级别的类标签。首先受潜在语义发现的启发,使用典型的概率潜在语义分析(pLSA)去学习潜在的类别,它可以代表目标,目标的一部分或者是背景。其次,为了确定那一个类别包含目标对象,本文提出了一种评估每个类别歧视的类别选择方法。
方法
提出了弱监督定位的潜在类别学习(LCL。 首先介绍了语义候选区域的提取,然后详细介绍了如何学习潜在类别和发现这些类别中的对象区域。
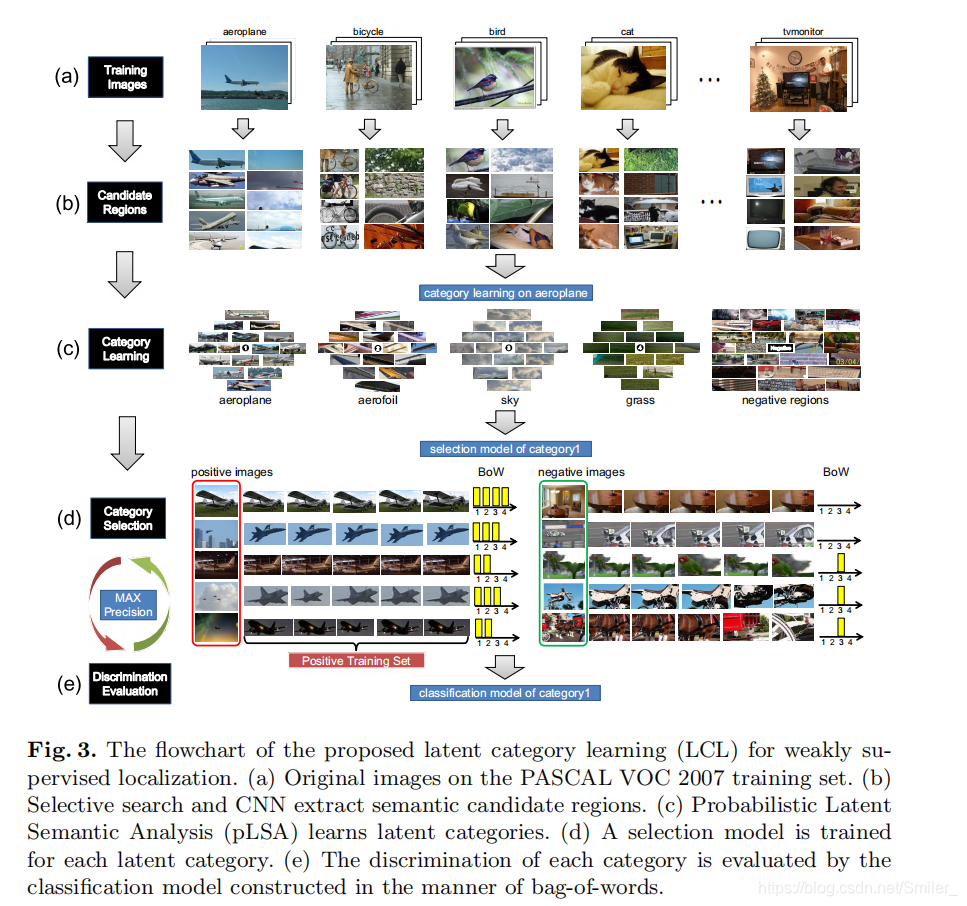
1、Region Extraction
使用Selective Search生成Regio proposal,使用CNN提取regio proposal 的特征
2、 Category Learning
从候选区域中学习潜在的类别。由于这些区域是没有类别标签的,所以潜在类别学习是一个无监督学习问题。在本文,使用经典的pLSA去解决潜在类别学习。
使用目标类别正样本进行类别学习。假设在一个正样本中有N个候选区域,CNN学习到的区域特征为djd_jdj 。在文本分析中,pLSA以词的出现频率直方图作为输入,CNN区域表示满足这种直方图输入。首先,所有区域表示都是非负的;其次CNN表示是对这些单词的出现置信度,可信度越大,一个单词的出现频率越高。
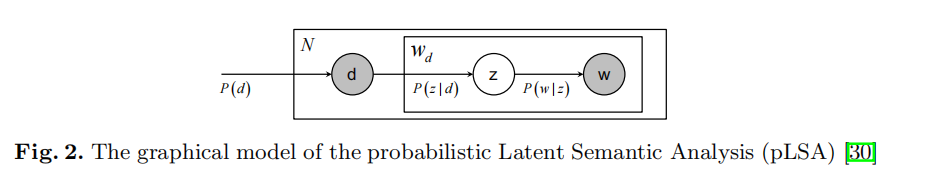
将每个单词表示为wiw_iwi,wiw_iwi在区域 djd_jdj中出现的频率就是 djd_jdj的iii维。隐藏层变量zkz_kzk与所有单词相关联。本文中将zkz_kzk作为一个目标类别的潜在类别。pLSA优化联合概率P(wi,dj,zk)P(w_i,d_j,z_k)P(wi,dj,zk)。在潜在变量zkz_kzk上的边缘化决定了条件概率P(wi∣dj)P(w_i|d_j)P(wi∣dj):
P(wi∣dj)=∑k=1KP(zk∣dj)P(wi∣zk)P(w_i|d_j)=\sum_{k=1}^KP(z_k|d_j)P(w_i|z_k)P(wi∣dj)=∑k=1KP(zk∣dj)P(wi∣zk)
因此每个区域有K个潜在类别的K个概率。如果区域djd_jdj上概率最大的是类别zkz_kzk,那么就认为区域djd_jdj就是类别zkz_kzk。
每个区域被分成K个集合,每个区域都包含语义相似的区域。
3、 Category Selection
在学习了潜在类别之后,需要确定那一个包含目标物体类别的目标区域。本文提出了一个类别选择策略去发现目标区域。这种思想是基于潜在类别具有不同的语义含义,从而对目标对象类有不同的区分。
使用出现频率选择类别。
首先构造一个选择模型去选择能够代表类别的区域。对于任何目标类别(类别1),我们认为其区域为正区域,而负区域包括两部分:其他类别(类别2-4)和负图像(负)。其次,使用选择模型去选择前T分数的区域,包括正样本和负样本,T个选择区域的出现频率可以用BoW表示。 基于这些区域,我们构造了每个正负图像的BoW图像表示。
最后,利用BoW表示,在带有图像级类标签的训练集上训练目标潜在类别(类别1)的分类模型,并通过在验证集上的分类精度来评估模型的判别。 通过对所有类别的评估,将精度最高的类别视为最具鉴别性的类别。
构造BOW表示,有三个步骤:
(1)Codebook Generation
通过对其中的区域进行平均来量化每个潜在类别。 设Z=[z1,...zK]T∈RM∗KZ=[z_1,...z_K]^T\in{R^{M*K}}Z=[z1,...zK]T∈RM∗K表示具有K类别的码本。
(2)Feature Encoding
对于每个图片,假设T个选择的区域表示为[d1,...dT]T∈rM∗T[d_1,...d_T]^T\in{r^{M*T}}[d1,...dT]T∈rM∗T,使用Super Vector Coding对每个区域进行编码:
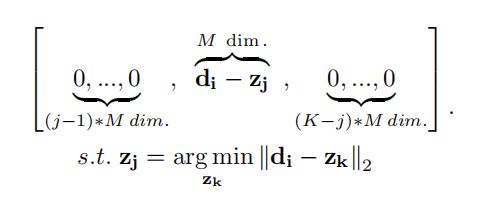
(3)Feature Pooling
在编码之后,在编码之后的T个区域上进行池化,构造BoW表示。

















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









