



 本文深入探讨了深度学习领域中的四大经典网络结构:AlexNet、VGGnet、Resnet和DenseNet的发展历程、结构特点及创新之处。从ReLU激活函数的引入到残差块的设计,每一项革新都在推动深度学习技术的进步。
本文深入探讨了深度学习领域中的四大经典网络结构:AlexNet、VGGnet、Resnet和DenseNet的发展历程、结构特点及创新之处。从ReLU激活函数的引入到残差块的设计,每一项革新都在推动深度学习技术的进步。
AlexNet
- 发展:AlexNet是第一个在ImageNet分类上表现出色的大规模卷积神经网络体系结构。AlexNet在比赛中大大超越了以前所有基于非深度学习的模型。
- 结构:
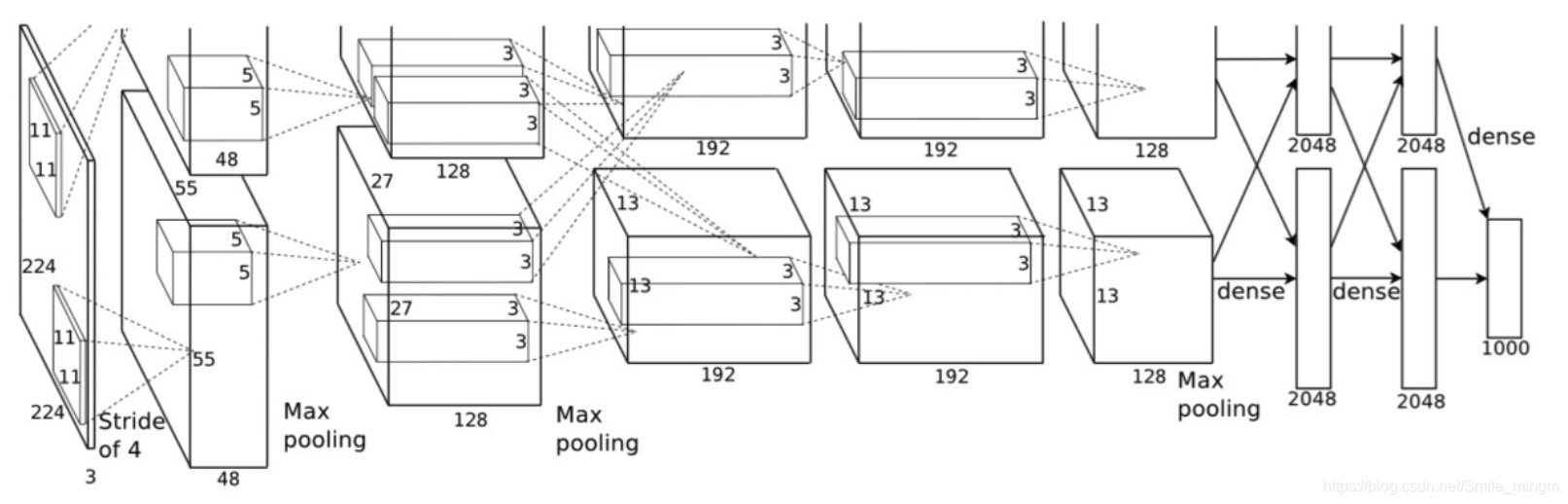 特点:
特点:
- 第一次使用ReLU激活函数,表达能力更强
- 使用了Dropout函数,防止过拟合
- 对数据集进行了数据增强
- 池化可以重叠(步长<窗口宽度)
VGGnet
- 发展:证明更深层的卷积神经网络会有更好地效果。
- 结构:vgg19
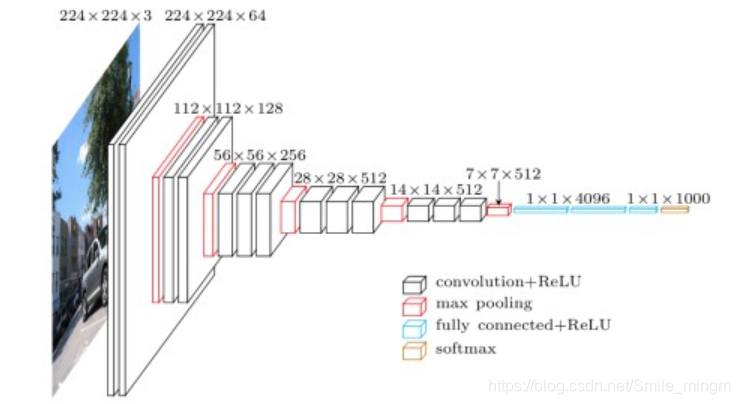
- VGG的输入为224×224×3的图像
- 对图像做均值预处理,每个像素中减去在训练集上计算的RGB均值。
- 网络使用连续的小卷积核(3×3)做连续卷积,卷积的固定步长为1,并在图像的边缘填充1个像素,这样卷积后保持图像的分辨率不变。
- 连续的卷积层会接着一个池化层,降低图像的分辨率。空间池化由五个最大池化层进行,这些层在一些卷积层之后(不是所有的卷积层之后都是最大池化)。在2×2像素窗口上进行最大池化,步长为2。
- 卷积层后,接着的是3个全连接层,前两个每个都有4096个通道,第三是输出层输出1000个分类。
- 所有的隐藏层的激活函数都使用的是ReLU
- 使用1×1的卷积核,为了添加非线性激活函数的个数,而且不影响卷积层的感受野。
- 没有使用局部归一化,作者发现局部归一化并不能提高网络的性能。
- 特点:
- 使用了更小的卷积核代替了Alexnet中的大卷积核。
- 使用了多个连续的卷积层。
- 结合以上两点,加深了网络的深度,同时减少了数据量。
- 通道数更多,特征度更宽。每个通道代表着一个FeatureMap,更多的通道数表示更丰富的图像特征。VGG网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道,通道数的增加,使得更多的信息可以被提取出来。
- 全连接转卷积(测试阶段)
Resnet
- 发展:
- 由于网络层数的不断加深,出现了几个问题。
1.计算资源的消耗
2.模型容易过拟合
3.梯度消失/梯度爆炸问题的产生。 - 问题1可以通过GPU集群来解决;问题2的过拟合通过采集海量数据,并配合Dropout正则化等方法也可以有效避免;问题3通过Batch Normalization也可以避免。貌似我们只要无脑的增加网络的层数,我们就能从此获益,但实验数据给了我们当头一棒。作者发现,随着网络层数的增加,网络发生了退化(degradation)的现象:随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当你再增加网络深度的话,训练集loss反而会增大。注意这并不是过拟合,因为在过拟合中训练loss是一直减小的。
- 当网络退化时,浅层网络能够达到比深层网络更好的训练效果。如果把低层的特征传到高层,那么效果应该至少不比浅层的网络效果差。Feature Map包含的图像信息会逐层减少,而ResNet的直接映射的加入,保证了 l+1层的网络一定比 l层包含更多的图像信息。基于这种使用直接映射来连接网络不同层直接的思想,残差网络应运而生。
- 由于网络层数的不断加深,出现了几个问题。
- 结构:
加入了残差块
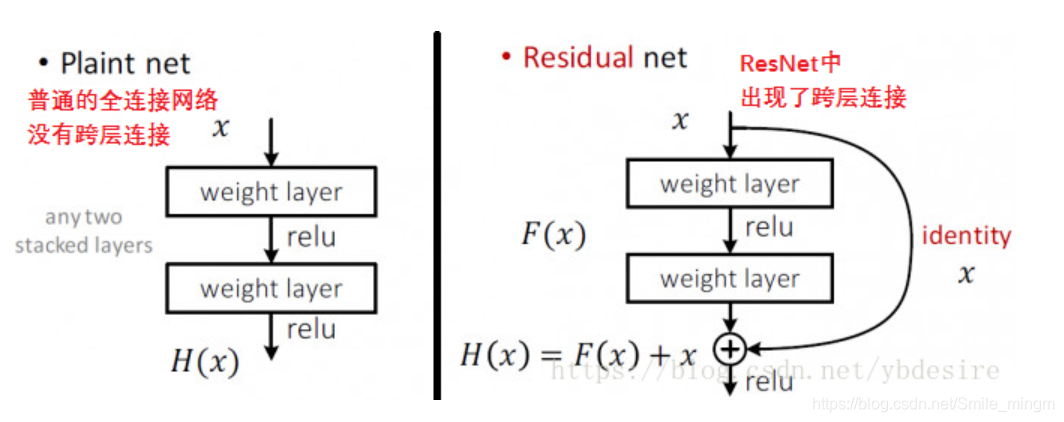
- 特点:短路连接有利于梯度的反向传播,从而能够训练更深的网络。
DenseNet
- 发展:基本思路类似于ResNet。
- 结构:
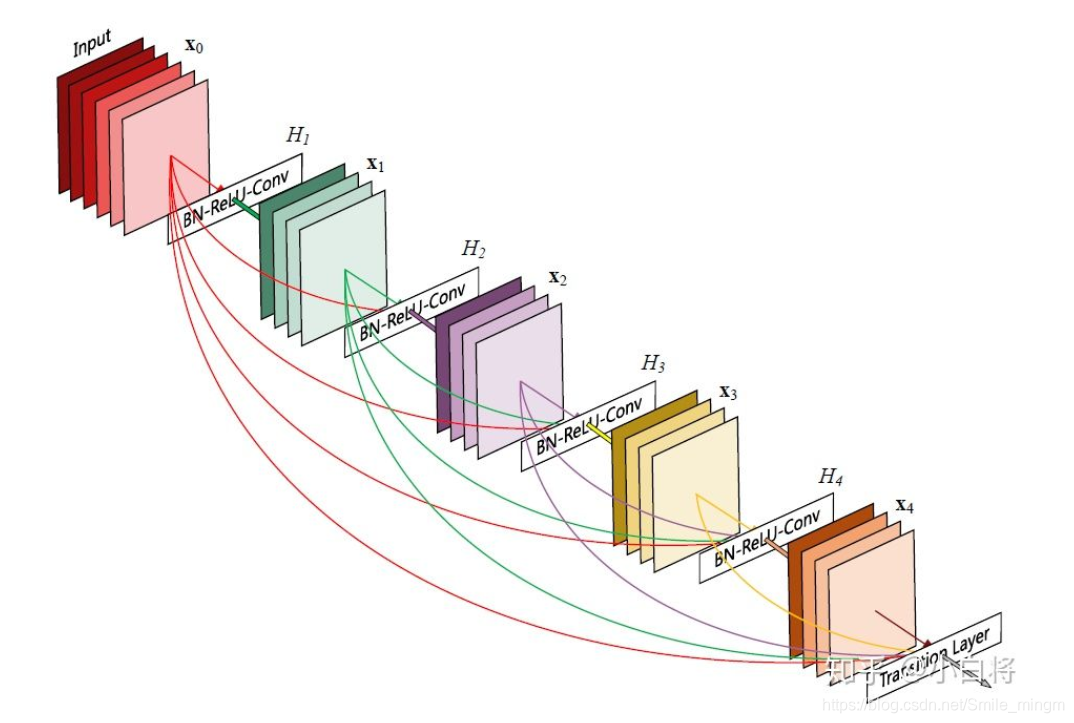
DenseNet的网络结构主要由DenseBlock和Transition组成
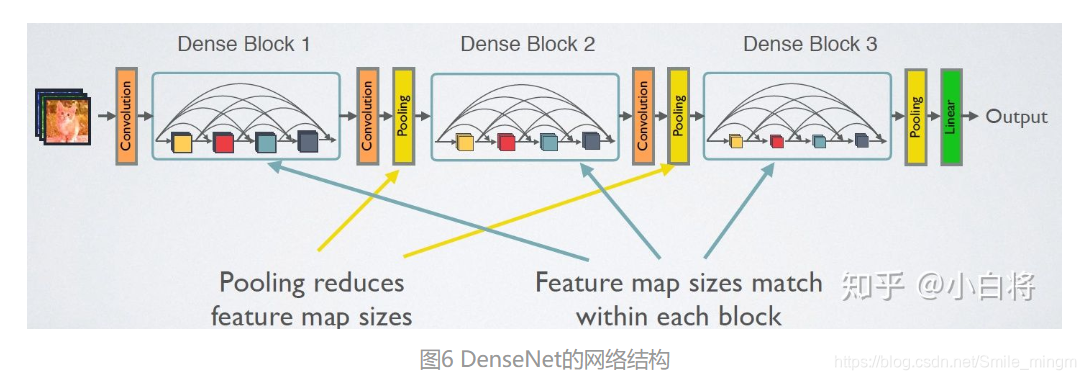
- 特点:
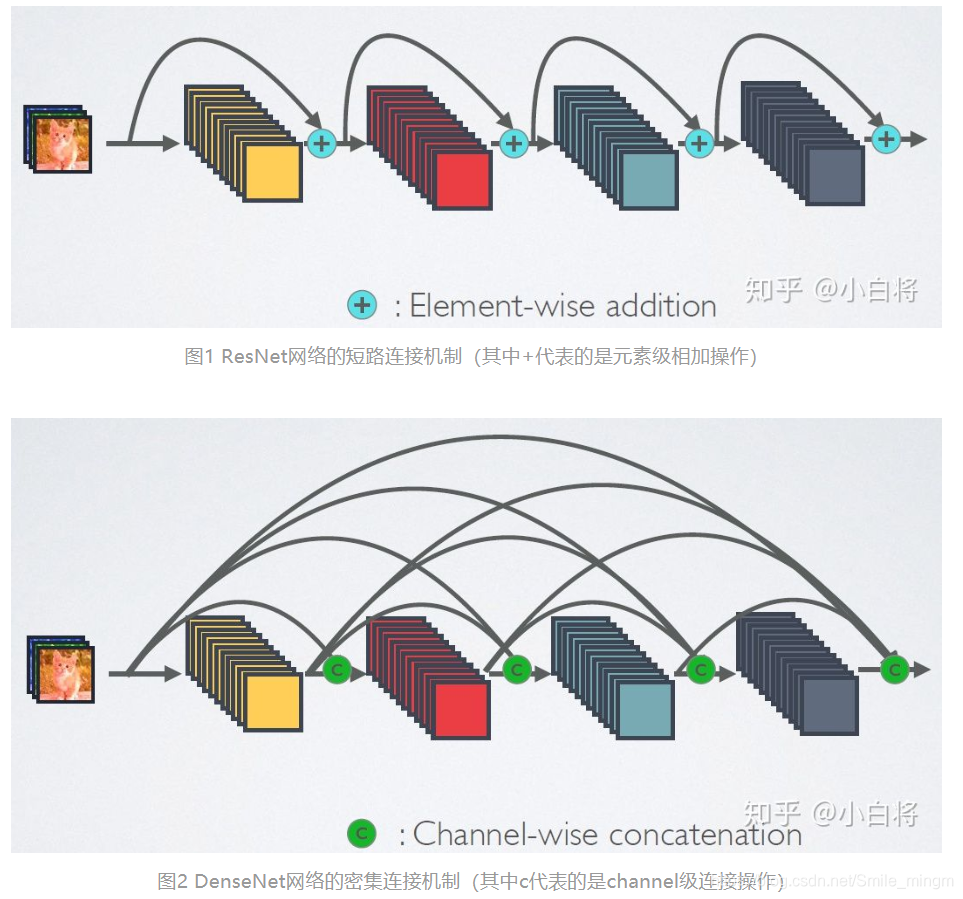
- 相较于ResNet来说,采用了更密集的连接,即互相连接所有的层 。
- ResNet连接后采用的是add,而DenseNet采用的是在channel维度上concat。这样也实现了特征重用,不会使计算量特别大。
- 详情可参考链接


















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









