






 Flume是一个用于高效、可靠、可用的数据收集系统。本文概述了Flume Agent的内部工作原理,包括Source(数据来源)、Channel(数据缓冲区)和Sink(数据输出)。Source接收事件,Channel作为缓冲存储,Sink负责将事件传输到目标系统。Flume适用于实时推送大量数据,其组件设计允许灵活的数据路由和处理,如通过拦截器进行事件修改,以及通过Channel选择器决定事件流向。
Flume是一个用于高效、可靠、可用的数据收集系统。本文概述了Flume Agent的内部工作原理,包括Source(数据来源)、Channel(数据缓冲区)和Sink(数据输出)。Source接收事件,Channel作为缓冲存储,Sink负责将事件传输到目标系统。Flume适用于实时推送大量数据,其组件设计允许灵活的数据路由和处理,如通过拦截器进行事件修改,以及通过Channel选择器决定事件流向。
一.概述
Flume将数据表示为事件,事件是非常简单的数据结构,具有一个主体和一个报头集合,事件的主体是一个字节数组,通常是是Flume传送过来的负载,抱头被标记为一个map,其中有字符串key和字符串value。报头并不是用来传输数据的,只是为了路由和标记事件的优先级。报头也可以用来给事件增加ID或者UUID。
每个事件本质上必须是一个独立的记录,而不是记录的一部分,这也就要求每个事件要适应Flume Agent JVM的内存。而如果使用File Channel,应该有足够的硬盘空间来支持,如果数据不能表示为多个记录,那么Flume可能不太适合这种场景。
Flume真正适合做的是实时推送事件,尤其是在数据流是持续的且量级很大的情况,否则没必要采用Flume增加系统的复杂度。
Flume中最简单的部署单元是Flume Agent,Agent是一个Java应用程序,接受并生产数据并缓存数据,直至最终写入到其他Agent中或者是存储系统中。
二.组件
Flume Agent中包含了三个重要的组件,Source,Channel,Sink。
1.Source
Source是从其他生产数据的应用中接受数据的组件。Source可以监听一个或者多个网络端口,用于接受数据或者从本地文件系统中读取数据,每个Source必须至少连接一个Channel。当然一个Source也可以连接多个Channnel,这取决于系统设计的需要。
2.Channel
Channel主要是用来缓冲Agent以及接受,但尚未写出到另外一个Agent或者存储系统的数据。Channel的行为比较像队列,Source写入到他们,Sink从他们中读取数据。多个Source可以安全的写入到同一Channel中,并且多个Sink可以从同一个Channel中读取数据。可是一个Sink只能从一个Channel读取数据,如果多个Sink从相同的Channel中读取数据,系统可以保证只有一个Sink会从Channel读取一个特定的事件。
3.Sink
Sink会连续轮训各自的Channel来读取和删除事件。Sink将事件推送到下一阶段(RPC Sink的情况下),或者到达最终目的地。一旦在下一阶段或者其目的地中数据是安全的,Sink通过事务提交通知Channel,可以从Channel中删除这一事件。
三.执行流程和原理
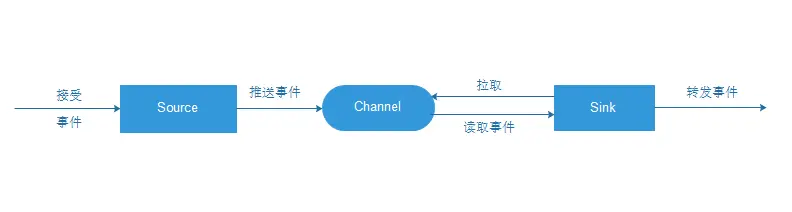
Flume本身不限制Agent中Source,Channel,Sink的数量,因此Flume Source可以接受事件,并可以通过配置将事件复制到多个目的地。这使得Source可以通过Channel处理器、拦截器和Channel选择器,写入到Channel。
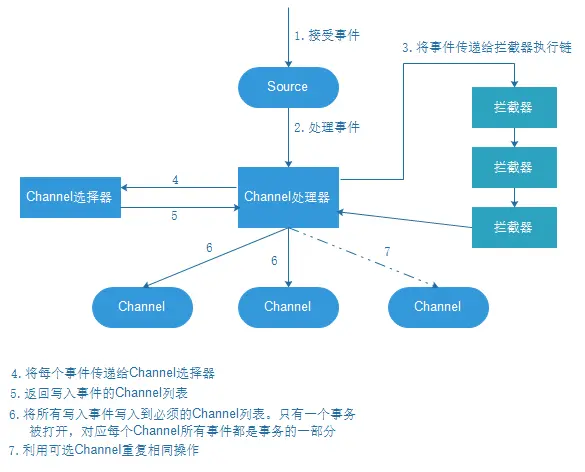
每个Source都有自己的Channel处理器,每次将Source取得的事件写入到Channel,都要通过Channel处理器,然后Channel处理器,将这些事件,传送到一个或者多个拦截器中。
拦截器(Interceptor)是简单的插入式组件,设置在Source和Source写入数据的Channel之间,Source接收到的事件在写入到Channel之前,拦截器都可以对时间进行拦截,转换或删除这些事件。拦截器也有很多类型,如正则表达式的拦截器,时间戳拦截器,可以为事件添加报头,或者移除现有报头等。某个Source可以配置成使用多个拦截器,这些拦截器按照配置的顺序依次被调用,这就是所谓的责任链模式。一旦拦截器处理完事件,拦截器链返回的事件列表传递到Channel列表,即通过Channel选择器为每个事件选择Channel。
Source可以通过处理器-拦截器-选择器来路由写入多个Channel。Channel选择器是决定每个事件必须写入到Source附带的哪个Channel组件中。因此拦截器可以用来插入或者删除事件中的数据,这样Channel选择器可以应用一些条件在这些事件上,来决定事件必须写入到哪些Channel中,Channel选择器可以对时间应用任意过滤条件,来决定哪个事件必须写入到哪些Channel中,以及哪些Channel是必须或者可选的。
写入到必须的Channel失败将会导致Channel处理器抛出ChannelException异常,表明Source必须重试该事件,而对于可选的Channel写入失败了,会忽略。一旦写出事件,处理器会对Source指示成功状态,会发送AKC确认给发送该事件的系统,并继续接受更多的事件。
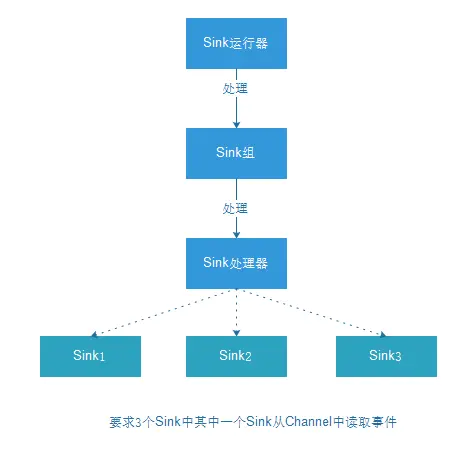
Sink运行器运行一个Sink组,一个Sink组中可以含有一个或者多个Sink。如果组中只存在一个Sink,那么没有组将更有效率。Sink运行器仅仅是一个询问Sink组,来处理下一批事件的线程,每个Sink组都有一个Sink处理器,处理器去选择组中的Sink之一去处理下一个事件集合.每个Sink只能从一个Channle中去获取数据。选定的Sink从Channel中接受事件,将事件写入到下一阶段或者最终目的地。

















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









