




Series
创建
pd.Series(data,index,name,dtype)
index(索引)、name(series名称)、dtype(类型)、index.name(索引名)
import pandas as pd
data = [1,2,3,4,5,6,7,8,9,9]
name = ['w','s','e','f','g','h','i','j','k','l']
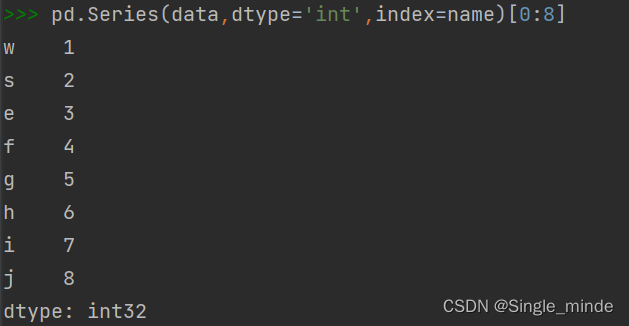
pd.Series(data,dtype='int',index=name)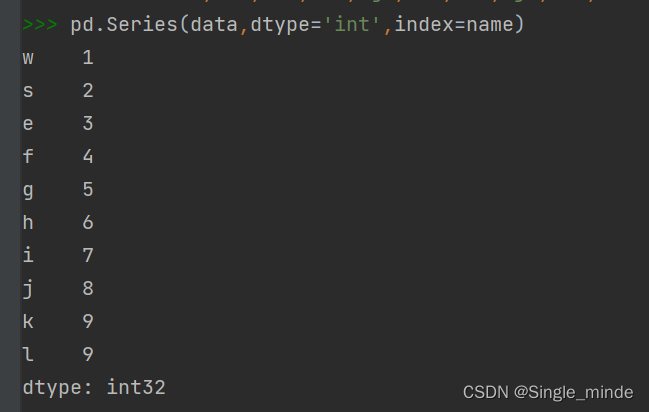
索引与切片(两种方法)
将Series当字典。
将Series当作列表。
DataFrame
创建
pd.DataFrame(data,index,columns)
data可以用两种传入方式,一个是字典,一个是列表。
字典是key为列名,value为数据。
列表是行,一条就是一行。
import pandas as pd
data2 = [[1,2,3,4,5,6,7,8,9,9],[3,2,3,4,5,6,7,8,9,9]]
name = ['w','s','e','f','g','h','i','j','k','l']
pd.DataFrame(data2,columns=name,index=['gg','GG'])
索引与定位
df.['列名'] #获得列
df['j']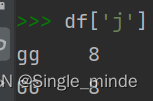
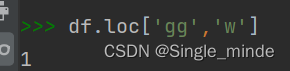
df.loc['行名','列明'] #显示定位
df.loc['gg','w']
df.loc['GG','w']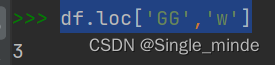
df.iloc[行位置,列位置] #隐式定位
df.iloc[0,0]
df.iloc[0,1]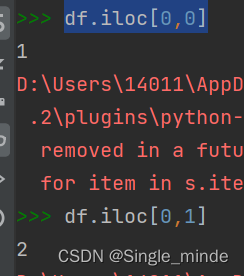
新增、删列
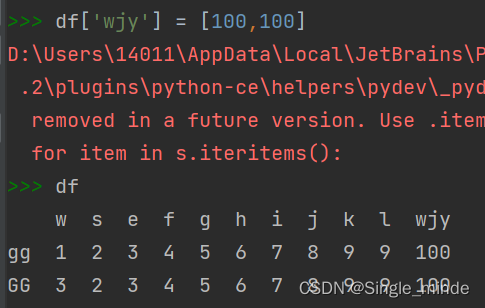
df['新增列名'] = [数据] #新增列数据
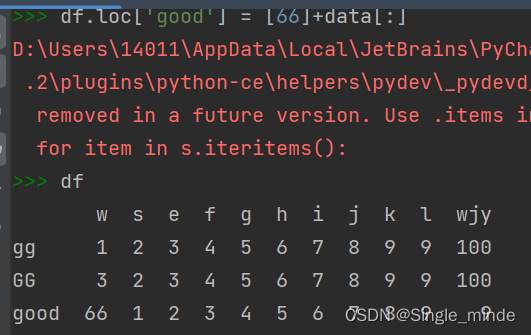
df.loc['新增行名'] = [数据] #新增行数据
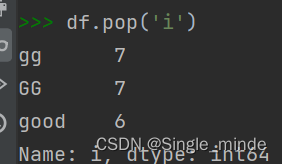
df.pop(行或者列) #删除数据
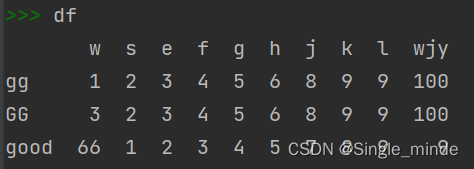
df.drop(行,列) #删除数据
数据的读取与保存
csv文件
pd.read_csv('文件地址+后缀')
pd.to_csv('保存地址+后缀')
excel文件(xlsx)
pd.read_excle('文件地址+后缀')
pd.to_excel('保存地址+后缀')
查看数据的整体情况
name.shape
name.head
name.tail
name.index
name.colmuns
address_book.shape
address_book.head()
address_book.tail()
address_book.index
address_book.columns
基本描述性统计方法
sum、min、max、mean、prod、mode...
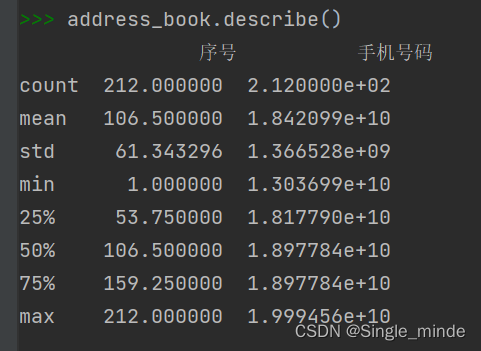
describe统计每类型出现的次数
value_counts统计次数。
离散化操作
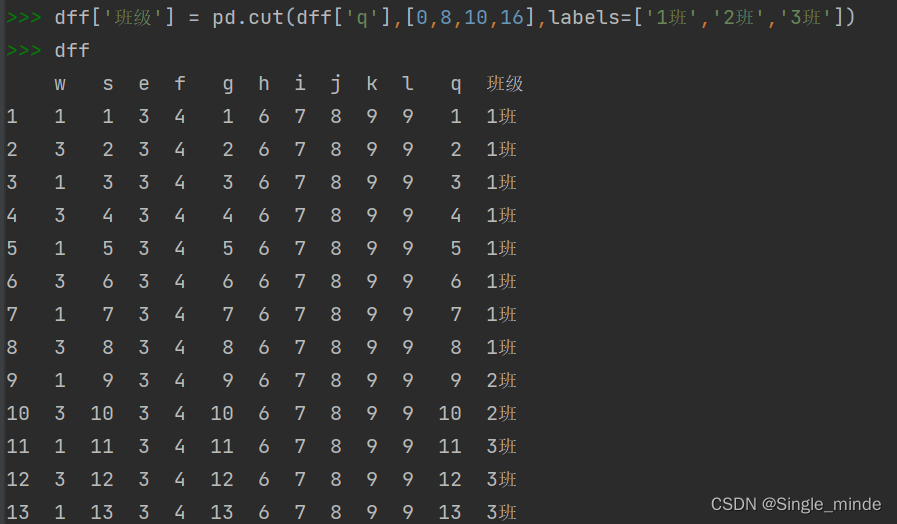
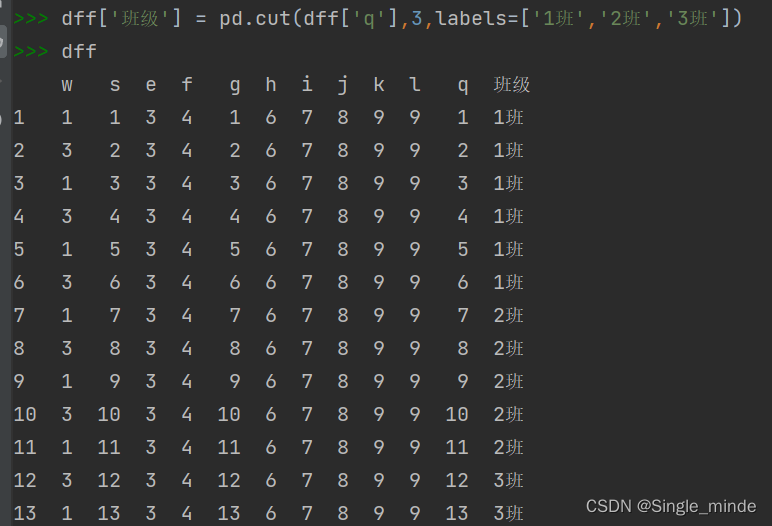
cut函数 切分数据
pd.cut(data,nums,labels)
#nums可以设置分割的条件,如果是单个数字,如3,则等分成3份,如果是数列,则按右开区间分开。
#labels可以对分割后的数据进行命名。
qcut函数
pd.qcut(data,nums) #可以自动对数据进行分割,分割是进行一个等深分割。
排序
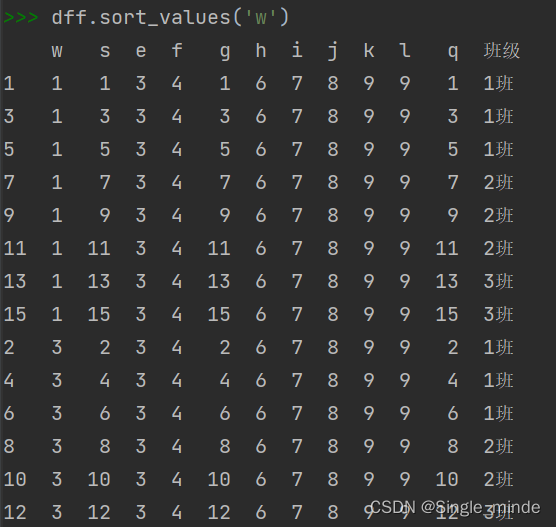
按值排序(默认从低到高)
data.sort_values('数学',ascending=False) #ascending选择排序是高到低还是低到高。
按索引排序
data.sort_index()
Python内置函数
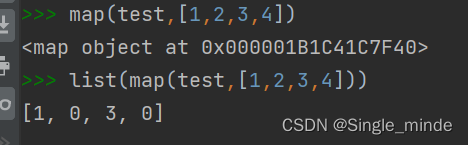
map函数
map(操作函数,序列型数据)
如:
def test(x):
if x%2==0:
return 0
else:
return xmap(test,[1,2,3,4])
它会循环把列表的元素放到函数中运行。
apply函数
可以对列或者行进行操作
data.apply(操作函数,axis) #利用np的函数,如sum等对列或者行进行操作;axis是选择对列或者行操作(0或1)。
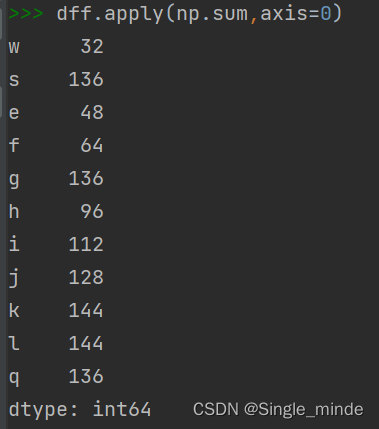
注:在dff中含有班级列时,这么操作会报错,因为班级不能进行列累加。
applymap函数
两者的结合
可以利用函数对列或行进行操作,就是说添加函数判断数据。
data.applymap(函数名)
表合并
三个函数都可以拼接多个数据源。
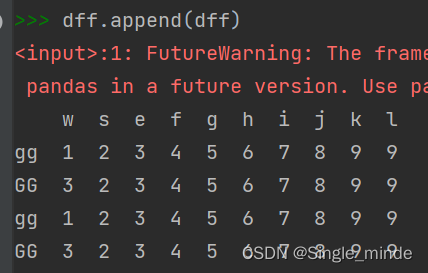
append函数
data.append(data1) #一般append拼接,列名不同补充NAN。可以设置不允许有重复,有重复报错。
concat函数
data.concat() #可以选择横、纵向拼接,用axis选择。可以选择左右内连接,join选择。
merge函数
merge数据库合并,与数据库的拼接方式非常相似。
data.merge(left.data1,right.data2,on,how,indicator) #how默认内连接,可选择左右内外连接。on选择匹配的主键。indicator是否查看数据在那个表。
处理缺失值
两种方式:删除缺失值、填充缺失值。
提取空值
data.某列.isnull() #判断出为空的值。
提取:data[data.某列.isnull()]
统计为空的数量:np.sum(data.isnull)
删除丢失值
data.dropna() #直接删除空值。axis选择行或列,如果行或列中有空值直接删除。
可以利用subset来选择
data.dropna(subset=['姓名'])姓名为空的列删除。
填充缺失值
采用固定值填充
data.列名.fillna(0) #某列空值填充0
上下文填充
使用上下临近值进行填充
data.列名.fillna(metod='bfill)
采用另外一列进行填充
data.某列.fillna(data.某列)
文本数据处理
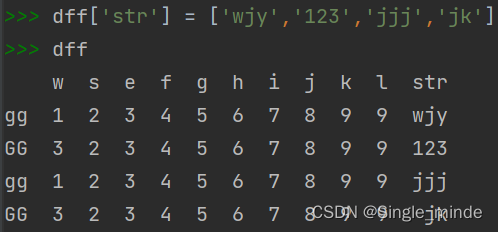
replace替换方法
data.列名.replace(to_replace,values) #只能完整替换,不能像replace替换单个字符。
注:可以使用正则表达式匹配。设regex参数为真。
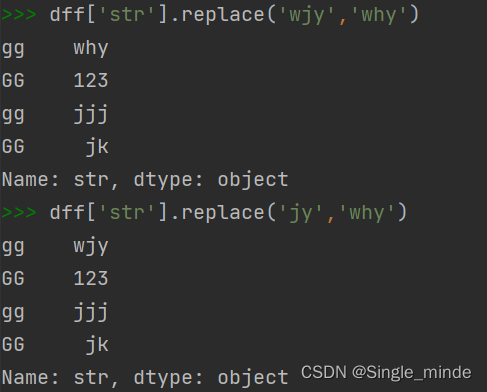
使用str字符串向量化处理字符串
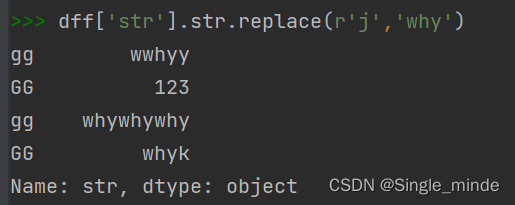
在str中使用replace,可以像使用单字符那样使用replace。
data.列名.str.replace(to_replace,values)
也可以使用正则表达式,不用设参数。
--正则表达式:
正则表达式常用操作符 | |
. | 表示任何单个字符 |
[] | 字符集,对单个字符给出取值范围;如[abc]表示a,b,c任一个,[a-c]相当于[a,b,c],与前面一样。 |
[^] | 非字符集。[^abc]表示非a,或非b或非c的单个字符。 |
* | 前一个字符0次或无限次扩展。abc*:ab,abc,abcc..... |
+ | 前一个字符1次或无限次扩展。abc+:abc,abcc..... |
? | 前一个字符0次或1次扩展,abc?:ab,abc |
| | 左右表达式任意一个。abc|def:abc或def |
{m} | 扩展前一个字符m次。ab{2}c:abbc |
{m,n} | 扩展前一个字符m至n次。ab{1,2}c;abc,abbc |
^ | 匹配字符串开头。^abc:abc且在一个字符串的开头 |
$ | 匹配字符串结尾。 |
() | 分组标,内部只能用操作符:(abc|def) |
\d | 数字,等价于[0~9] |
\w | 单词字符,等价于[A-Za-Z0-9] |
str常用字符串操作
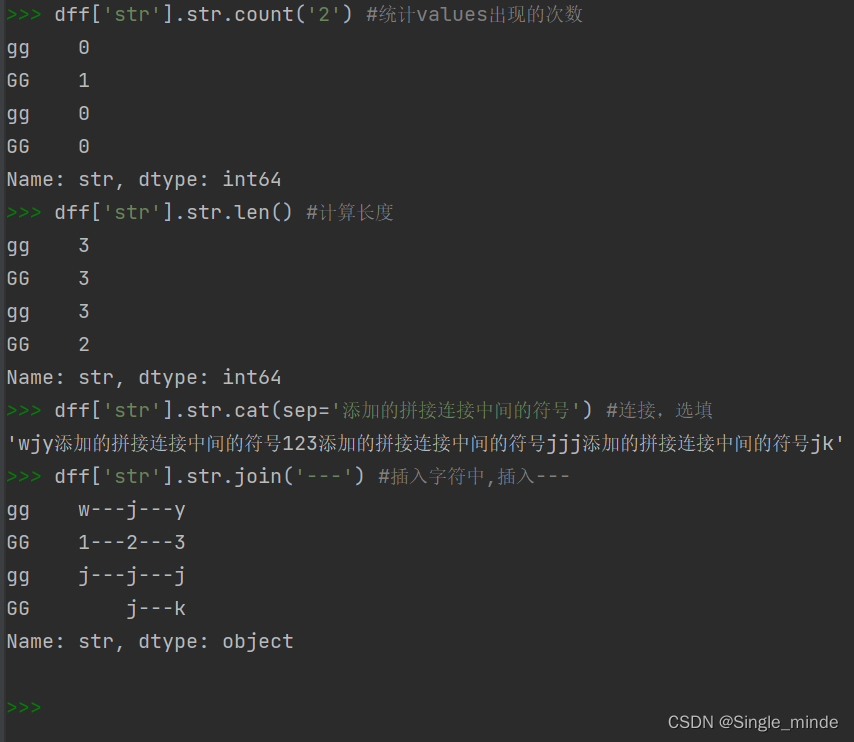
str.count(values) #统计values出现的次数
str.len() #计算长度
str.cat(sep='添加的拼接连接中间的符号') #连接,选填
str.join('---') #插入字符中,插入---
str.........
匹配字串
str.contains('values')#返回出含有values的数据
str.startswith('values')#返回以values开头的数据
str.endsiwth('values')#返回以values结尾的数据
提取字串
利用正则表达式捕获匹配。
str.extract(正则表达式) #只返回第一个匹配上的东西。
str.extractall(正则表达式) #返回所有匹配得上的字符串。
生成哑变量
str.get_dummies()
哑变量就是利用0、1将数据表示出来。
比如:血型
A B AB O
A 1 0 0 (0)
B 0 1 0 (0)
C 0 0 1 (0)
O 0 0 0 (1)
数据分组
分组方法groupby的使用
data.groupby('分组依据') #这样只能还不能得到显示结果,还要加上聚合函数
比如data.groupby('分组依据').mean()
常用的分组操作
df = data.groupby('分组依据')
df.sum()
df.skew() #偏度
df.var() #方差
df.prod() #累乘
df.cov() #协方差
df.describe() #对每一组数据都做一个统计
df.count()
df.max()
df.min()
...
groupby下的agg方法
可以自己定义组合,可以同时定义多个规则。
df.agg(['mean','min','max']) #可以直接得到平均值、最小值、最大值。
自己定义规则:
df.agg( lambda )
筛选器
可以通过列表选择的方法,提取需要的列,单独进行分组。
可以省一些运算时间。
拓展处理方法
通过函数进行筛选数据,哪些数据需要做分组,哪些数据不用做分组。



















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











