







应用场景
之前基于OpenFeign的调用都属于是同步调用,会存在一些问题,比如:
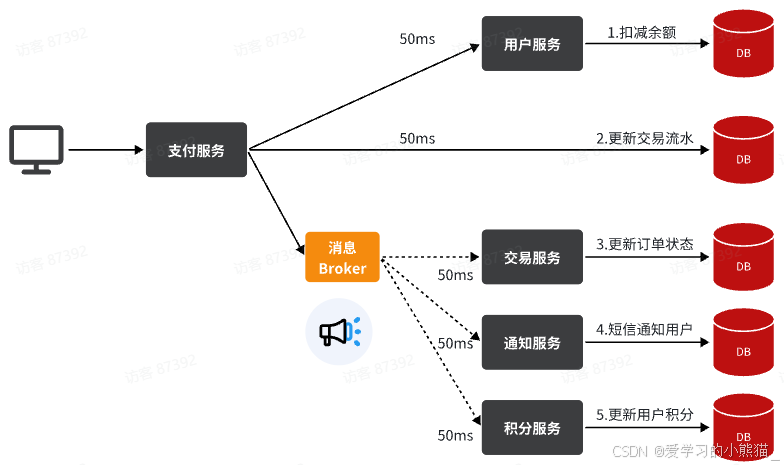
余额支付功能的工作流程:
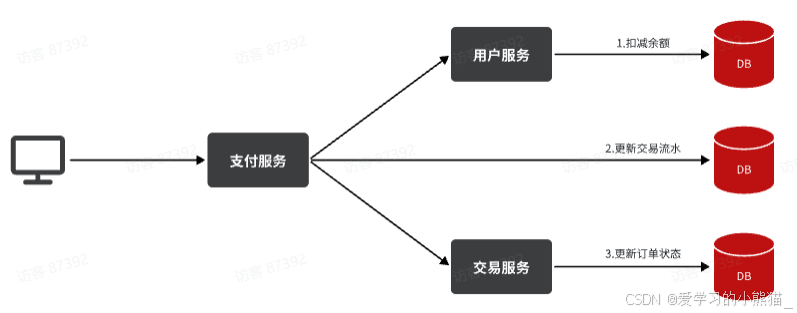
目前我们采用的是基于OpenFeign的同步调用,也就是说业务执行流程是这样的:
- 支付服务需要先调用用户服务完成余额扣减
- 然后支付服务自己要更新支付流水单的状态
- 然后支付服务调用交易服务,更新业务订单状态为已支付
三个步骤依次执行。
这其中就存在3个问题:
第一,拓展性差
我们目前的业务相对简单,但是随着业务规模扩大,产品的功能也在不断完善。
在大多数电商业务中,用户支付成功后都会以短信或者其它方式通知用户,告知支付成功。这是需要修改支付服务的代码,最终你的支付业务会越来越臃肿。。。也就是说每次有新的需求,现有支付逻辑都要跟着变化,代码经常变动,不符合开闭原则,拓展性不好。
第二,性能下降
由于我们采用了同步调用,调用者需要等待服务提供者执行完返回结果后,才能继续向下执行,也就是说每次远程调用,调用者都是阻塞等待状态。最终整个业务的响应时长就是每次远程调用的执行时长之和:
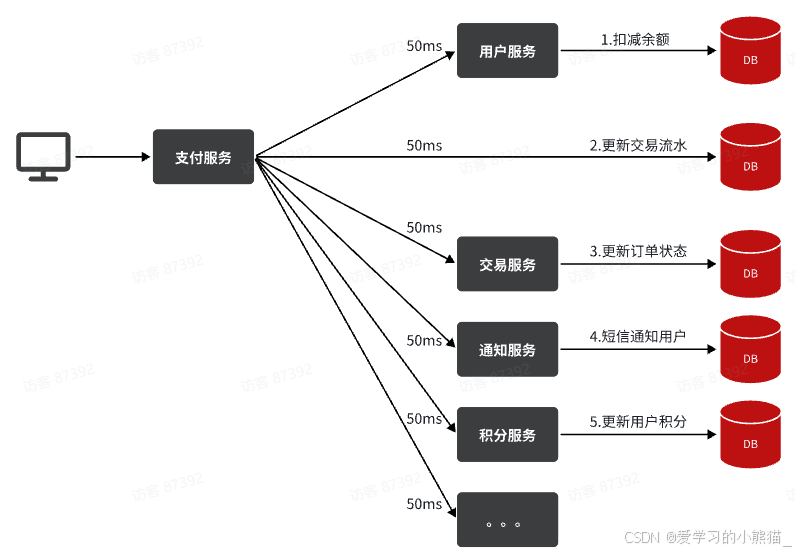
假如每个微服务的执行时长都是50ms,则最终整个业务的耗时可能高达300ms,性能太差了。
第三,级联失败
由于我们是基于OpenFeign调用交易服务、通知服务。当交易服务、通知服务出现故障时,整个事务都会回滚,交易失败。
这其实就是同步调用的级联失败问题。
但是大家思考一下,我们假设用户余额充足,扣款已经成功,此时我们应该确保支付流水单更新为已支付,确保交易成功。毕竟收到手里的钱没道理再退回去吧。
因此,这里不能因为短信通知、更新订单状态失败而回滚整个事务。
而要解决这些问题,我们就必须用异步调用的方式来代替同步调用。
异步调用
异步调用方式其实就是基于消息通知的方式,一般包含三个角色:
- 消息发送者:投递消息的人,就是原来的调用方
- 消息Broker:管理、暂存、转发消息,你可以把它理解成微信服务器
- 消息接收者:接收和处理消息的人,就是原来的服务提供方
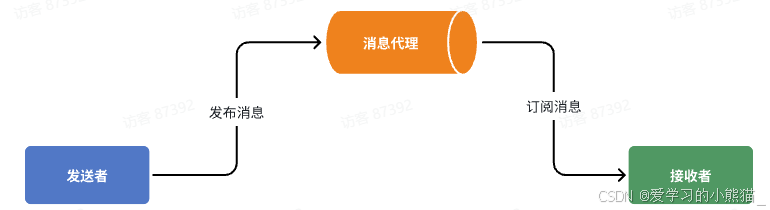
在异步调用中,发送者不再直接同步调用接收者的业务接口,而是发送一条消息投递给消息Broker。然后接收者根据自己的需求从消息Broker那里订阅消息。每当发送方发送消息后,接受者都能获取消息并处理。
这样,发送消息的人和接收消息的人就完全解耦了。
还是以余额支付业务为例:
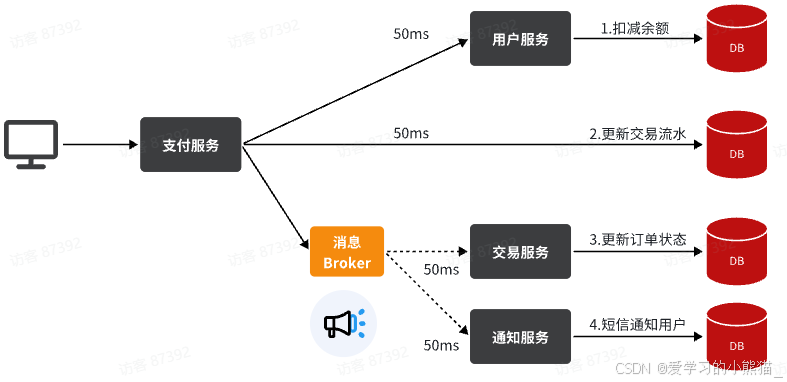
除了扣减余额、更新支付流水单状态以外,其它调用逻辑全部取消。而是改为发送一条消息到Broker。而相关的微服务都可以订阅消息通知,一旦消息到达Broker,则会分发给每一个订阅了的微服务,处理各自的业务。
假如产品经理提出了新的需求,比如要在支付成功后更新用户积分。支付代码完全不用变更,而仅仅是让积分服务也订阅消息即可:
不管后期增加了多少消息订阅者,作为支付服务来讲,执行问扣减余额、更新支付流水状态后,发送消息即可。业务耗时仅仅是这三部分业务耗时,仅仅100ms,大大提高了业务性能。
另外,不管是交易服务、通知服务,还是积分服务,他们的业务与支付关联度低。现在采用了异步调用,解除了耦合,他们即便执行过程中出现了故障,也不会影响到支付服务。
综上,异步调用的优势包括:
- 耦合度更低
- 性能更好
- 业务拓展性强
- 故障隔离,避免级联失败
当然,异步通信也并非完美无缺,它存在下列缺点:
- 完全依赖于Broker的可靠性、安全性和性能
- 架构复杂,后期维护和调试麻烦
RabbitMQ
RabbitMQ是基于Erlang语言开发的开源消息通信中间件。
RabbitMQ对应的架构如图:
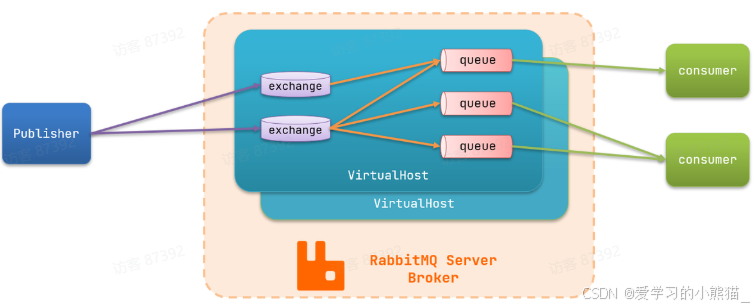
其中包含几个概念:
- publisher:生产者,也就是发送消息的一方
- consumer:消费者,也就是消费消息的一方
- queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理
- exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。
- virtual host:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue
SpringAMQP
将来我们开发业务功能的时候,肯定不会在控制台收发消息,而是应该基于编程的方式。由于RabbitMQ采用了AMQP协议,因此它具备跨语言的特性。任何语言只要遵循AMQP协议收发消息,都可以与RabbitMQ交互。并且RabbitMQ官方也提供了各种不同语言的客户端。
但是,RabbitMQ官方提供的Java客户端编码相对复杂,一般生产环境下我们更多会结合Spring来使用。而Spring的官方刚好基于RabbitMQ提供了这样一套消息收发的模板工具:SpringAMQP。并且还基于SpringBoot对其实现了自动装配,使用起来非常方便。
SpringAMQP提供了三个功能:
- 自动声明队列、交换机及其绑定关系
- 基于注解的监听器模式,异步接收消息
- 封装了RabbitTemplate工具,用于发送消息
WorkQueues模型
Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。
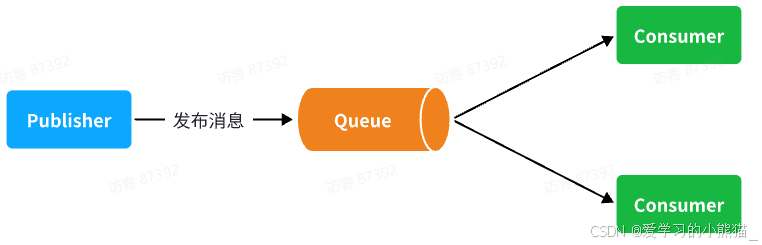
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
此时就可以使用work 模型,多个消费者共同处理消息处理,消息处理的速度就能大大提高了。
Work模型的使用:
- 多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
- 通过设置prefetch来控制消费者预取的消息数量
交换机类型
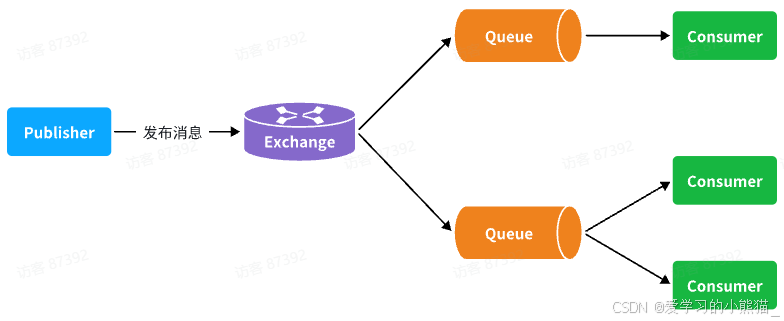
可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:
- Publisher:生产者,不再发送消息到队列中,而是发给交换机
- Exchange:交换机,一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
- Queue:消息队列也与以前一样,接收消息、缓存消息。不过队列一定要与交换机绑定。
- Consumer:消费者,与以前一样,订阅队列,没有变化
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
交换机的作用是什么?
- 接收publisher发送的消息
- 将消息按照规则路由到与之绑定的队列
- 不能缓存消息,路由失败,消息丢失
- FanoutExchange的会将消息路由到每个绑定的队列
交换机的类型有四种:
- Fanout:广播,将消息交给所有绑定到交换机的队列。我们最早在控制台使用的正是Fanout交换机
- Direct:订阅,基于RoutingKey(路由key)发送给订阅了消息的队列
- Topic:通配符订阅,与Direct类似,只不过RoutingKey可以使用通配符
- Headers:头匹配,基于MQ的消息头匹配,用的较少。
Fanout交换机
Fanout,英文翻译是扇出,我觉得在MQ中叫广播更合适。
在广播模式下,消息发送流程是这样的:
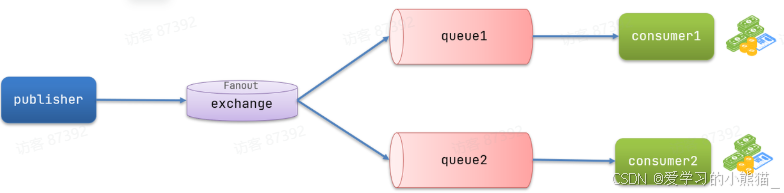
- 1) 可以有多个队列
- 2) 每个队列都要绑定到Exchange(交换机)
- 3) 生产者发送的消息,只能发送到交换机
- 4) 交换机把消息发送给绑定过的所有队列
- 5) 订阅队列的消费者都能拿到消息
Direct交换机
在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。
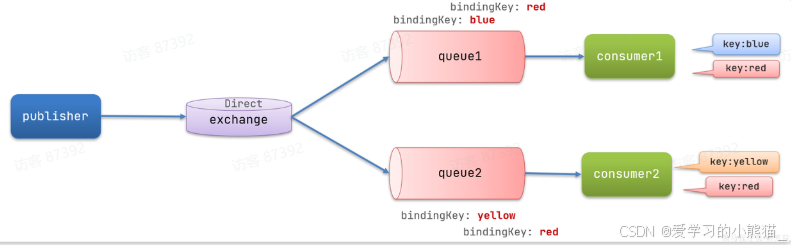
在Direct模型下:
- 队列与交换机的绑定,不能是任意绑定了,而是要指定一个RoutingKey(路由key)
- 消息的发送方在 向 Exchange发送消息时,也必须指定消息的 RoutingKey。
- Exchange不再把消息交给每一个绑定的队列,而是根据消息的Routing Key进行判断,只有队列的Routingkey与消息的 Routing key完全一致,才会接收到消息
Direct交换机与Fanout交换机的差异?
- Fanout交换机将消息路由给每一个与之绑定的队列
- Direct交换机根据RoutingKey判断路由给哪个队列
- 如果多个队列具有相同的RoutingKey,则与Fanout功能类似
Topic交换机
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。
只不过Topic类型Exchange可以让队列在绑定BindingKey 的时候使用通配符!
BindingKey 一般都是有一个或多个单词组成,多个单词之间以.分割,例如: item.insert
通配符规则:
- #:匹配一个或多个词
- *:匹配不多不少恰好1个词
举例:
- item.#:能够匹配item.spu.insert 或者 item.spu
- item.*:只能匹配item.spu
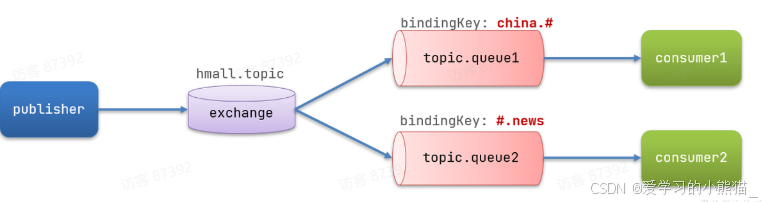
描述下Direct交换机与Topic交换机的差异?
- Topic交换机接收的消息RoutingKey必须是多个单词,以 . 分割
- Topic交换机与队列绑定时的bindingKey可以指定通配符
- #:代表0个或多个词
- *:代表1个词
本人水平有限,有错的地方还请批评指正。
什么是精神内耗?
简单地说,就是心理戏太多,自己消耗自己。
所谓:
言未出,结局已演千百遍;
身未动,心中已过万重山;
行未果,假想灾难愁不展;
事已闭,过往仍在脑中演。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











