







上一篇中,安装和初步使用了requests+BeautifulSoup,感受到了它们的便捷。但之前我们抓取的都是文字信息,这次我们准备来抓取的是图片信息。
>第一个实例
我们来抓取这个网站的图片:http://www.ivsky.com/bizhi/stand_by_me_doraemon_v45983/
首先,审查网页元素:
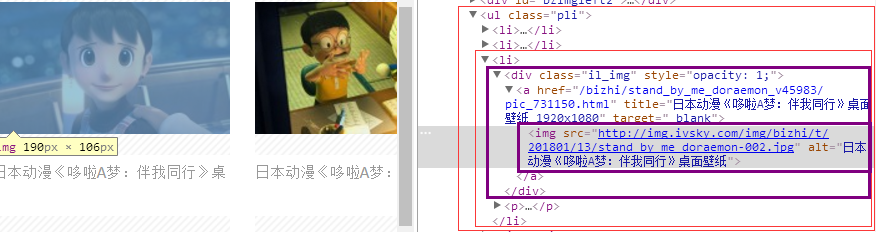
因此其结构就为:
<div class='il_img'> x 若干个,对每个div有 :
<img src='我们要的img src数据'>整体思路是:
- 获取每个图片的src地址;
- 构建requests去请求img的src并获取图片;
- 写入文件
代码如下:
import requests
from bs4 import BeautifulSoup
pic_id = 0 # 图片编号
url = 'http://www.ivsky. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1410
1410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









