



 Yogiyo的订单服务通过引入ApacheShardingSphere解决技术债务,实现了数据库分片的优化,提高了响应时间和系统可扩展性。在应对集成查询需求和面向业务的功能查询时,ShardingSphere-Proxy的采用消除了单一集成数据库的瓶颈,确保了更好的性能和水平扩展能力。
Yogiyo的订单服务通过引入ApacheShardingSphere解决技术债务,实现了数据库分片的优化,提高了响应时间和系统可扩展性。在应对集成查询需求和面向业务的功能查询时,ShardingSphere-Proxy的采用消除了单一集成数据库的瓶颈,确保了更好的性能和水平扩展能力。
导读:
Yogiyo 是韩国领先的移动和在线送餐平台,旨在为顾客提供更强大便捷的点餐服务。它是 Delivery Hero 的韩国分公司,直到 2021 年底被韩国十大上市公司之一的 GS Retail 以 6.84 亿美元收购。
本文来自 Yogiyo 研发中心从事 Orderyo(一种订购服务)的后端开发人员 Byungchul Kim,其团队最近为 Yogiyo 的订单服务使用了 Apache ShardingSphere。作者想通过本篇文章来分享来自 Yogiyo 的成功技术案例:如何用 Apache ShardingSphere 构建可扩展的订购服务?
订单服务数据库结构
为了解释背景,我想向你展示 Yogiyo 的订单服务的结构。下面是 Yogiyo 的订单服务的结构。
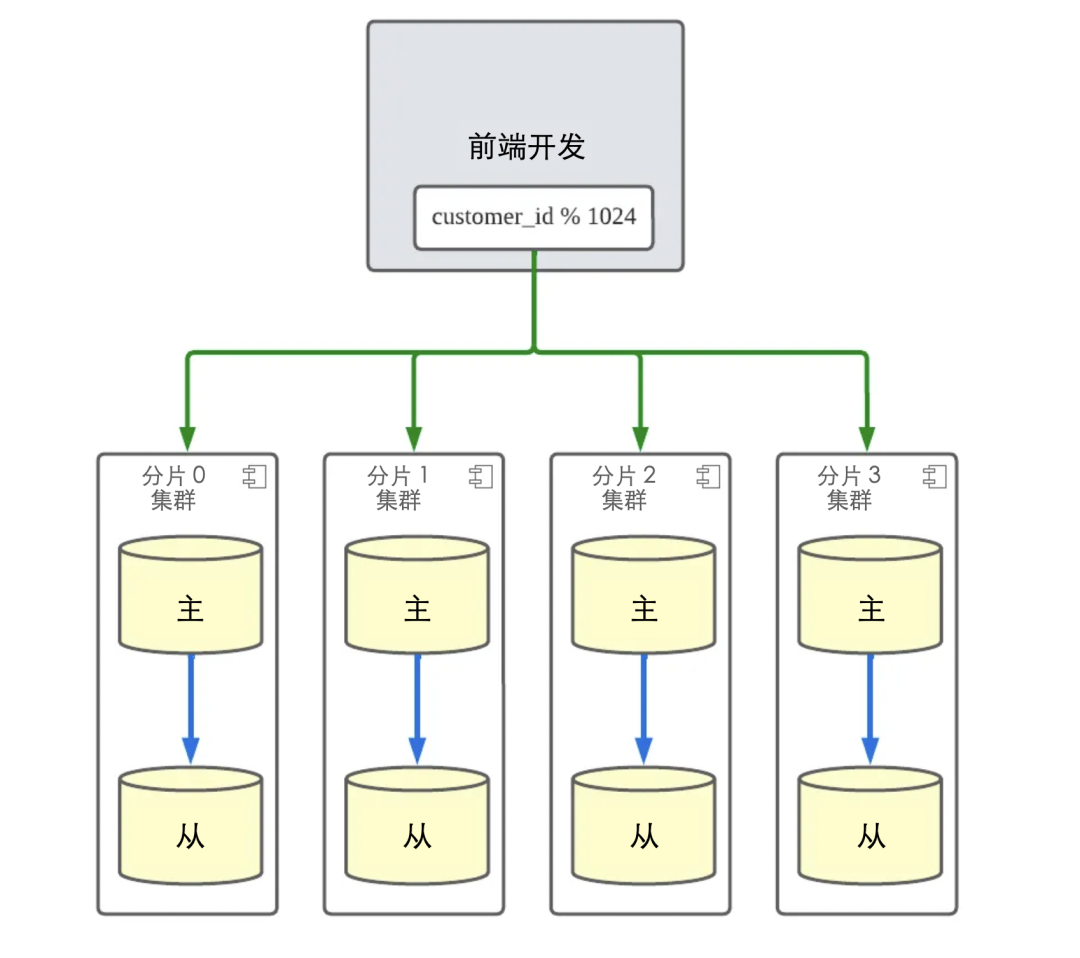
订单服务结构
当订单创建/取消/更新流量发生时,Orderyo 应用程序代码通过基于客户 ID 的模块化操作将写入负载分配到四个分片集群。因此,应用程序只需要 customer_id 来找到它需要访问的分片集群并执行操作。
通过在订单服务中引入分片,基于 customer_id 的订单功能的整体响应时间得到了改善,并且通过分配 DB 负载,消除了数据库端的许多瓶颈问题。我们还可以将数据库扩展到适当的水平,以适应未来的流量增长。
然而,数据库分片并不全是好事。在过去一年为 Yogiyo 的订单服务实施和运行数据库分片的过程中,我们意识到有一个技术债务:DB 的结构要反映综合查询要求。订单服务功能的大部分流量都有 customer_id,所以我们使用分片 DB,但除此之外,我们还有订单的源数据,所以在面向运营和面向最高功能中,有一个没有分片键的综合查询要求。在过去的一年里,为了支持运营查询,我们通过从分片 DB 复制到一个单一的 DB(为了方便,我们称之为集成 DB)来收集数据,以实现查询。
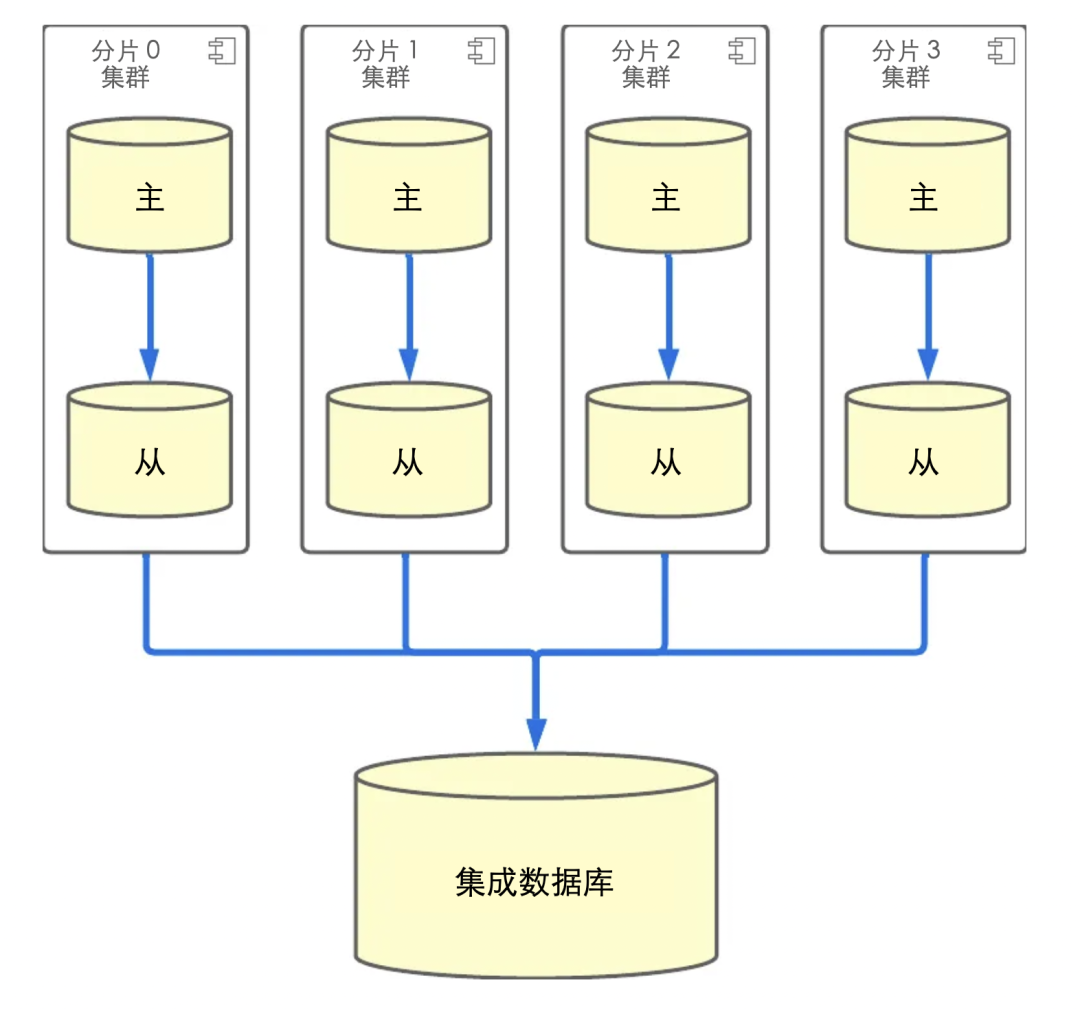
在这种结构中,随着分片的吞吐量增加,负载被放在单一的集成数据库上。因此,集成数据库成为一个瓶颈,而分片的优势之一--水平数据库扩展--就不复存在了。
支持面向商业侧功能的新要求
在我们的测试中,水平扩展的阈值远远高于我们目前的流量,但随着新的要求,这成为一个需要解决的问题。以前,我们只需要支持面向生产的查询,但新的要求是支持面向生产的功能查询,而面向生产的查询要比传统的生产查询流量大得多,而且是 DB 密集型的。
ShardingSphere-Proxy是如何被采用的
我们决定使用 Apache ShardingSphere 来解决我们现有的技术债务并满足我们的新要求。简单介绍一下 Apache ShardingSphere 项目,它是一个旨在建立分布式数据库生态系统的项目,顾名思义,它是一个允许 RDB 被分片并作为一个分布式数据库环境运行的解决方案。
我想到采用 Apache ShardingSphere 的主要原因是,我可以不费吹灰之力:我所要做的就是部署 ShardingSphere-Proxy,一个由 Apache ShardingSphere 项目提供的数据库代理服务器,并将使用 Integration DB 的查询转移到数据库代理服务器上。
我只是在本地环境中按照教程操作,看看能否在我的 Yogiyo 订购服务中实现它,然后在暂存服务器上验证了一段时间,并进行了路测,看看在将其转移到生产中之前是否有任何性能影响。
设置本地环境
首先,我们设置了与当前本地运行的服务相同的环境。对于分片数据库,我们设置了以下的 Mysqld 设置,以增加每个表的 p.k.,其中有 1024 个共同的、不同的偏移量,这样,即使这些表被分割成分片,也能有唯一的 p.k.。
分片 0 的配置
[mysqld]
server_id=20
auto_increment_increment = 1024
auto_increment_offset = 1分片 1 的配置
[mysqld]
server_id=21
auto_increment_increment = 1024
auto_increment_offset = 2如下图所示,我将上述两个 DB 设置为 DataSources,并在 ShardingSphere 代理服务器上设置了 sharding DB 的规则,这样它就可以根据 id 找到逻辑数据库 ds,也就是表的 pk。我还排除了 Django 框架中默认用 broadcastTables 创建的表,这样它们就不需要被分片了。
######################################################################################################
#
# Here you can configure the rules for the proxy.
# This example is configuration of sharding rule.
#
# If you want to use sharding, please refer to this file;
# if you want to use master-slave, please refer to the config-master_slave.yaml.
#
######################################################################################################
databaseName: orderyo
dataSources:
ds_0:
url: jdbc:mysql://sharding-sphere-mysql-shard-0:3306/orderyo?serverTimezone=Asia/Seoul&useSSL=false&characterEncoding=UTF-8
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds_1:
url: jdbc:mysql://sharding-sphere-mysql-shard-1:3306/orderyo?serverTimezone=Asia/Seoul&useSSL=false&characterEncoding=UTF-8
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
rules:
- !SHARDING
tables:
order_order:
actualDataNodes: ds_${0..1}.order_order
order_orderitem:
actualDataNodes: ds_${0..1}.order_orderitem
order_orderitemoption:
actualDataNodes: ds_${0..1}.order_orderitemoption
broadcastTables:
- django_admin_log,django_content_type,django_migrations,django_session
defaultShardingColumn: id
defaultDatabaseStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: database-inline
defaultTableStrategy:
none:
shardingAlgorithms:
database-inline:
type: INLINE
props:
algorithm-expression: ds_${id % 1024 - 1}通过添加这几个设置并将其作为节点浮动,我们发现我们可以通过简单地改变 DB 路径来替换我们应用程序中的集成 DB。
应用暂存环境
为了验证功能和性能,我让 Django 的 DBWrapper 向 Integration DB 发送一个查询,然后向 ShardingSphere-Proxy 服务器发送相同的查询,并留下日志,比较结果和响应时间。
class IntegrationDatabaseWrapper:
def __call__(self, execute, sql, params, many, context):
db_alias = context["connection"].alias
if db_alias != settings.INTEGRATION_DB_READ_ONLY_NAME:
return execute(sql, params, many, context)
try:
integration_start = time.monotonic()
integration_result = execute(sql, params, many, context)
integration_execution_time = time.monotonic() - integration_start
except Exception as e:
raise e
else:
return integration_result
finally:
if config.INTEGRATION_DB_MODE == DatabaseMode.DUAL:
self._call_proxy_db(sql, params, integration_result, integration_execution_time)
def _call_proxy_db(self, sql, params, integration_result, integration_execution_time):
from django.db import connections
proxy_start = time.monotonic()
shardingsphere_cursor = connections[settings.SHARDINGSHPERE_PROXY_DB_READ_ONLY_NAME].cursor()
shardingsphere_result = shardingsphere_cursor.execute(sql, params)
shardingsphere_cursor.close()
proxy_execution_time = time.monotonic() - proxy_start
logger.info(....)
integration_db_wrapper = IntegrationDatabaseWrapper()
with connections[settings.INTEGRATION_DB_READ_ONLY_NAME].execute_wrapper(integration_db_wrapper):
do_queries()当我们在分期测试时,我们遇到了两个问题。
1. 当数据库模式发生变化时,查询不工作。
2. 我们发现有些查询的结果与以前不同。
在更详细地查看了开源代码并检查了文档后,我发现,当 DB 模式发生变化时,对于需要进行数据处理的字段,如 datetime order_by,我需要用下面的命令在 ShardingSphere-Proxy 服务器上反映变化后的表信息。通过改变部署流程,在模式发生变化时自动运行该命令,这个问题就解决了。
REFRESH TABLE METADATA;一个查询的结果与以前不同,这是因为现有查询有一个相当复杂的子查询,而 ShardingSphere 项目中没有对这个特定的子查询的支持。通过删除子查询和调整查询,这个问题得到了解决。
负载测试
虽然我们能够确认我们在本地和暂存环境中有一个功能性的替换,但当我们把它推广到生产环境时,我们还需要测试和验证性能。为了验证这一点,我们要求我们的内部基础设施和自动化团队在与生产环境相同的环境中进行性能测试。性能测试包括将我们现有的集成数据库与 ShardingSphere-Proxy 结构的限制进行比较。测试工具是 locust.
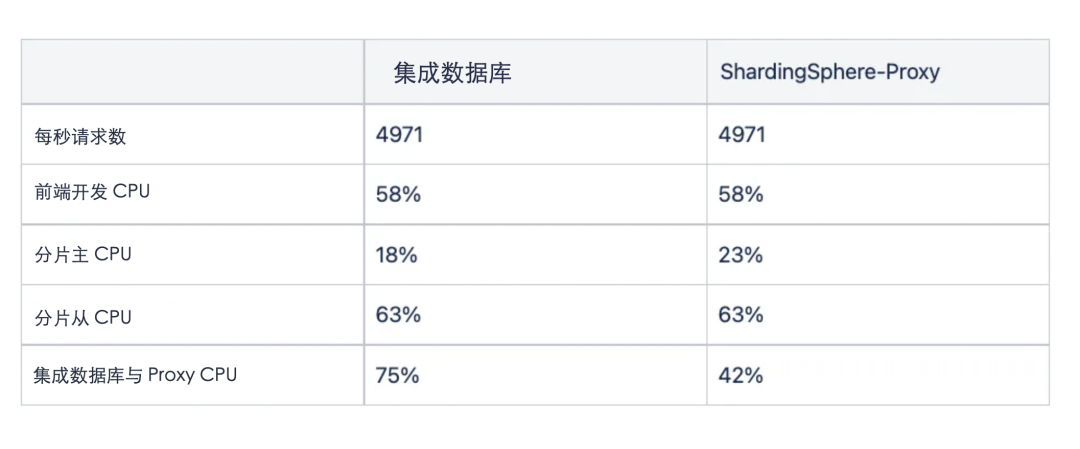
测试显示,在同一个用户池中的两个结构有不同的结果。首先,集成 DB 也需要资源来处理复制,所以随着作业创建负载的增加,它成为一个瓶颈。这可以从 Integration DB 和 Proxy 的 CPU 指标中看出,负载系数上升到 75%。这意味着我们在未来有可扩展性问题。
因为 ShardingSphere-Proxy 结构将查询分发到 Primary,所以我们看到 Shard Primary 上的负载全面增加。在生产中,我们将查询分布到分片从属区,所以理论上 DB 的可扩展性是没有限制的。
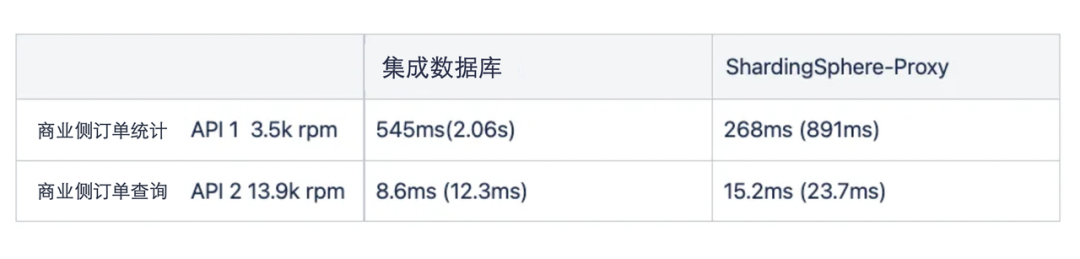
我们还可以看到,测试的 API 的响应速度因结构不同而有很大差异。在上表中,我们可以看到,由于 ShardingSphere-Proxy 的分布式处理,它的表现一直很好。然而,对于可以快速处理的面向客户的订单查询 API,没有网络跳转开销的 Integration DB 表现始终良好。
在性能测试中,我们发现 Integration DB 的最大吞吐量在峰值负载方面是有限的,由于 ShardingSphere-Proxy 的吞吐量大约是 Integration DB 的 1.5 倍,我们决定,无论分片的数量如何,它都可以水平扩展。因此,我们决定删除现有的 Integration DB,使用 ShardingSphere-Proxy。
总结
在 Yogiyo,订购服务是 DB 写操作数量最多的服务之一。我们一直在主动对 DB 进行分片,以便进行横向扩展,但我们发现,我们为满足集成查询的需求而构建的环境在结构上并不能利用分片的优势。经过反复考虑,我们决定实施开源的 Apache ShardingSphere,以恢复分片的优势,实现分布式处理,将性能提高到四倍。
我希望这篇文章对那些想实现比以前更有效的分片结构,但有特殊要求而难以实现的人有所帮助。如果有机会,我将再写一篇文章,介绍使用 ShardingSphere 时出现的问题和性能改进。

现在,从理论上讲
没有什么可以阻止 Orderyo 写订单
(试着增加你的订单看看)
最后,在这篇文章的最后,我想感谢我的团队、基础设施团队和性能测试团队在实施 ShardingSphere 时提供的帮助!P.S. 我们正在积极寻找开发人员加入 Yogiyo 订购服务。我们很希望有一个对服务大量流量的技术挑战有经验的人,欢迎推荐!

















 7718
7718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









