




过去,图书馆、档案室等场所被视为知识的圣地,人类在其中寻求、保存和传承着千古智慧结晶。如今,搜索引擎的崛起使人们能更便捷地获取公共领域的知识,极大地推动了人类文明的进步。未来,随着大数据和人工智能的兴起,企业自身的知识和经验将成为其发展的核心资产和竞争优势,数据已经成为了一种重要的生产要素和战略资源。特别是对研发企业来说,研发数据将成为企业的重要资产。然而,随着国际形式的日渐复杂,越来越多的国际数据访问受限,作为中国企业,研发企业对文献数据的挖掘、对自己产生数据的记录、积累传承、对企业整体数据安全维护与隐私保护更应得到高度重视,只有加强数据积累和创新,才能在未来的竞争中保持竞争力,实现持续的发展和成功。
2013至今,鹰谷始终致力于为企业建立自己的研发数据库,基于500+实验室R&D真实需求,为科学家量身打造用得起、用得上、用得好的一体化科研数智工作平台,积累数据、安全合规、降低新人培养成本、激活创新、降本增效,人走经验带不走,我们希望帮助企业在未来的竞争中保持核心优势,让企业的研发既有历史可追溯,又有未来可期待,让研发有数据,有智慧,有未来,这既是鹰谷对未来的展望,也是我们的使命。
01 上海鹰谷信息科技有限公司简介
让研发有数据、有智慧、有未来
上海鹰谷信息科技有限公司(Integle)成立于2013年,致力于为企业建立自己的研发数据库。提供电子实验记录本InELN、试剂与生物样本库存管理InWMS、科研采购管理InPMS、化合物与生物分子注册管理InCMS等数字化实验室软件,由科学家打造,拥有生物序列编辑器InSequence、结构式编辑器InDraw等工具类软件,掌握IUPAC中英文命名、化学结构高精度AI图像识别、质粒设计、引物设计等专业技术。
目前已经服务了500 多家生物医药客户,其中包括80多家上市公司,率先出口美国,如华为、扬子江、倍特、马应龙、和记黄埔、艾力斯、人福医药、迈瑞医疗、晶泰、英矽智能、天境生物、益方生物、美国ADARx Pharmaceuticals、美国Staidson Biopharma、美国SparX Therapeutics、中科院上海神经科学研究所等企业或高校研究所。

02 鹰谷产品介绍
明星产品:电子实验记录本InELN
电子实验记录本是研发实验室数字化转型升级的核心,解决纸质实验记录书写潦草、写回忆录、难检查、管理成本高、没有时间戳易伪造篡改、协作性差、无法远程管理等一系列问题,实验数据的电子化是未来自动化和智能化的基础。
自2013年起,鹰谷一直专注于以电子实验记录相关技术为核心的自主研发,按照国际标准打造,符合FDA、欧盟以及中国等地区的相关电子记录法规要求;支持云端部署或本地私有部署,节省实验记录时间,确保记录完整准确,积累数据,提升管理效率。与国际主流同类产品相比,鹰谷电子实验记录本用户界面更友好,可以快速上手使用;功能更强大,整合AI技术,帮助管理者和科学家真正解决在实际工作中的效率、合规和安全性问题。通过全文搜索、结构式搜索、基因序列比对、数据结构化等,便于合作者间实现网络协同、促进合作,大大提高团队工作效率。
了解详情:eln.integle.com
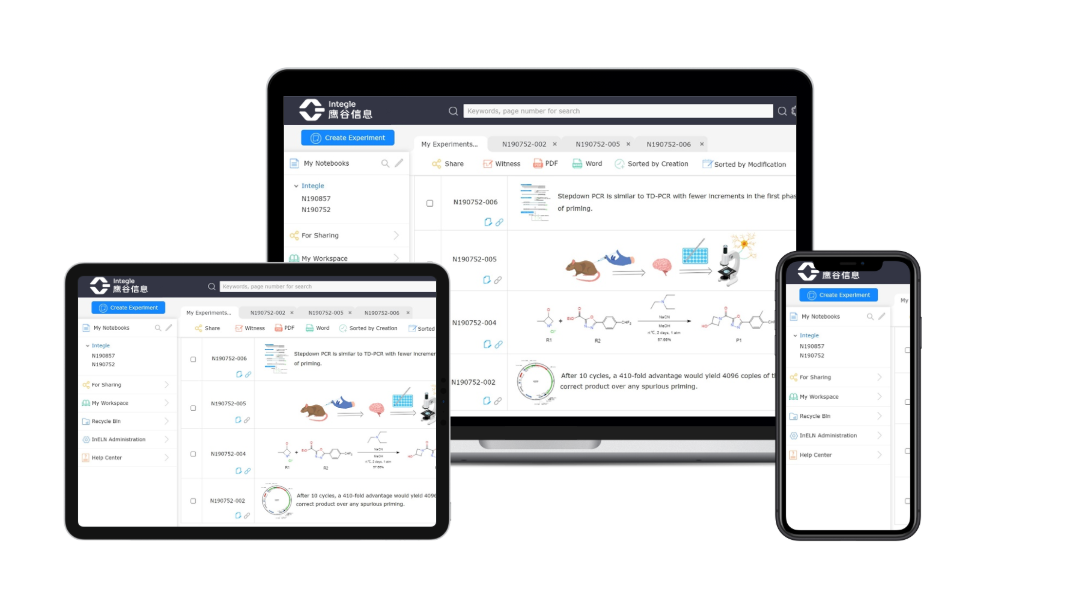
核心工具软件:InDraw结构式编辑器
InDraw是国内首个自主研发的化学结构式编辑器,旨在为科研工作者提供简单、易用的绘制化学结构式、反应式、聚合材料、生物聚合物、生物信号通路、流程图和生物图形的绘图工具,支持化学结构中文(全球首家)或英文的IUPAC命名,高精度AI图像识别,HELM大分子分级编辑语言绘制多肽、核酸、多糖、高分子材料,兼容ChemDraw,有网页端、客户端两种版本,使用人数高达数十万,遍及各大高校、科研院所和企业单位,可用于发表专利、论文、报告等,不用担心版权问题。
基本功能免费提供,也有更高级的企业版付费提供,目前企业版已被华为、国家知识产权局、艾力斯等国内知名研发企业和机构采用。
免费下载链接:integle.com/static/indraw
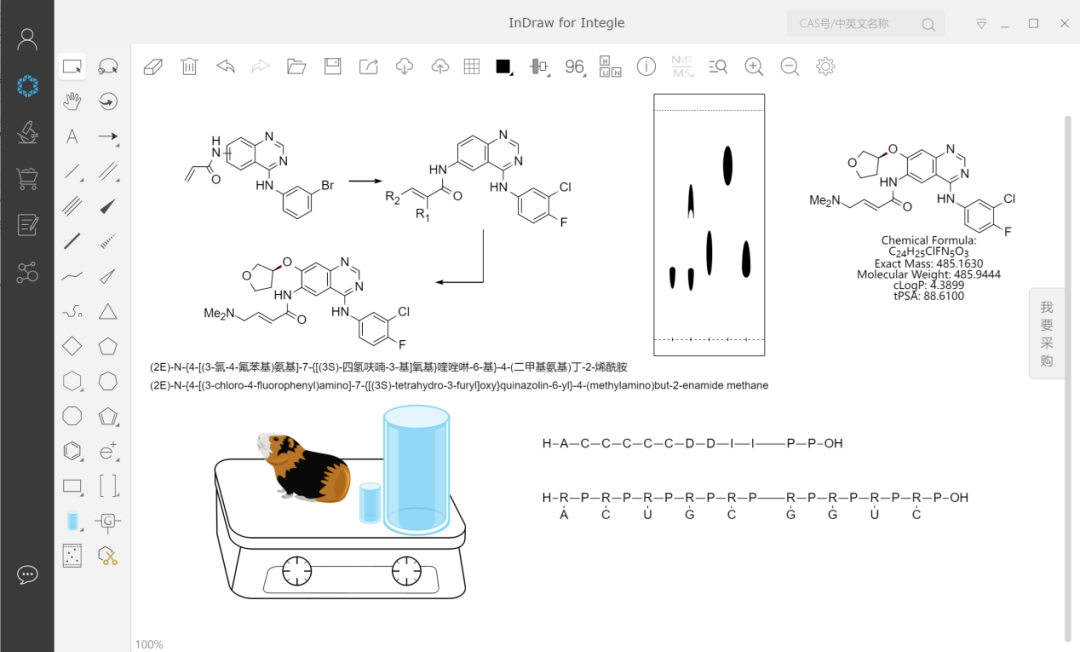
新品工具软件:InSequence生物序列编辑器
对标SnapGene,由鹰谷纯自主研发,攻克分子生物学核心算法技术,可用于DNA/RNA/蛋白序列编辑,实现序列编辑器科研软件的国产替代,拥有自主知识产权,简单易用,免费下载。
兼容GenBank、Addgene文件中的序列信息,支持自动标注与手动修改特征、酶切位点、引物、开放阅读框等信息,实时计算引物长度、Tm值、GC含量,高效设计引物,支持引物碱基的添加、删除与替换,支持自动翻译序列与翻译框架移动,快速分析特定的序列区域,支持收藏和管理多个序列、引物及酶组信息,支持与合作伙伴分享收藏夹内容,保持序列结构、引物、特征等信息的完整性和数据一致性,突破领域空白,持续升级迭代。
免费下载链接:integle.com/static/insequence
科研采购管理系统InPMS
科研采购管理系统InPMS立足于解决实验室采购问题,内置数千万条供应商商品实时库存和价格信息,涵盖化学品、生物制品、仪器耗材等,可以通过结构式搜索和全文搜索,适用于化学品、生物制品、仪器耗材等采购。替代手动填写 Email 提交订单,快速货比三家,整合供应商产品目录,可直接搜索下单,实现企业采购的“淘宝”模式,避免重复采买。可直接向供应商下单,与供应商互通,支持自定义下单,支持直接采购和集中采购,支持订单管理、发票管理、订单统计分析等,可与鹰谷试剂库存管理系统对接,避免手工重复录入。
了解详情:shop.integle.com
科研库存管理系统InWMS
通过InWMS专业的管理,可以把实验室成千上万种的生物和化学试剂进行规范管理,实现全文或化学结构式的秒级搜索,促进重复利用,减少浪费和提升效率。支持危险化学品如剧毒品、易制毒的专业化合规管理,提高安全管理能力。与InELN电子实验记录本等模块互相联通,可以实现各种实验物料的追溯。可高度灵活配置,适用于集团公司、中小微企业、课题组等多种组织机构。
了解详情:integle.com/static/in-stock
化合物注册管理系统 InCMS
InCMS为生物制药和化学用户打造,用于企业内部研发产生的大分子、小分子的注册和管理,帮助企业建立自己的研发数据库。用户可以DIY设置好项目的专属数据库模版,规范管理样品研发信息,计算化学信息、物化信息、生物信息,也可以同时上传文件、图片等;可以单个或批量注册大分子和小分子,基因序列,支持修改编号,进行数据分析和筛选,图表可视化,设置审批流程,进行样品管理、权限控制和痕迹追溯等。通过InCMS可以实现关键字和化学结构的快速搜索,信息共享,是提高研发效率的有利武器和企业的数据资产保险柜。
了解详情:incms.integle.com
科研项目管理系统InProject
InProject实现项目、目标、任务的分解,通过甘特图,一目了然项目进度,与电子实验记录本 (InELN) 和化合物注册管理系统(InCMS)相互联通,让管理者和项目经理们通过项目的维度来管理所有的实验记录和大小分子数据库,实现多维度的统计、分析和管理,以项目为中心,统筹管理所有项目有关的数据和进度。
了解详情:project.integle.com
文献结构化系统InPaper
科学家经常要分析专利或期刊,将其中有用的数据手动录入到 Excel 中,进行构效分析。鹰谷文献结构化系统 InPaper,将 AI 图像识别技术和 NLP 技术应用于 PDF 数据提取过程,自动化、高精度提取文献数据,获得结构式、反应式和活性数据,形成构效关系表。避免科学家繁重耗时地将专利中只有名称无结构图的几百个化学结构的相关数据录入到 Excel 中。
了解详情:integle.com
03 鹰谷发展历程
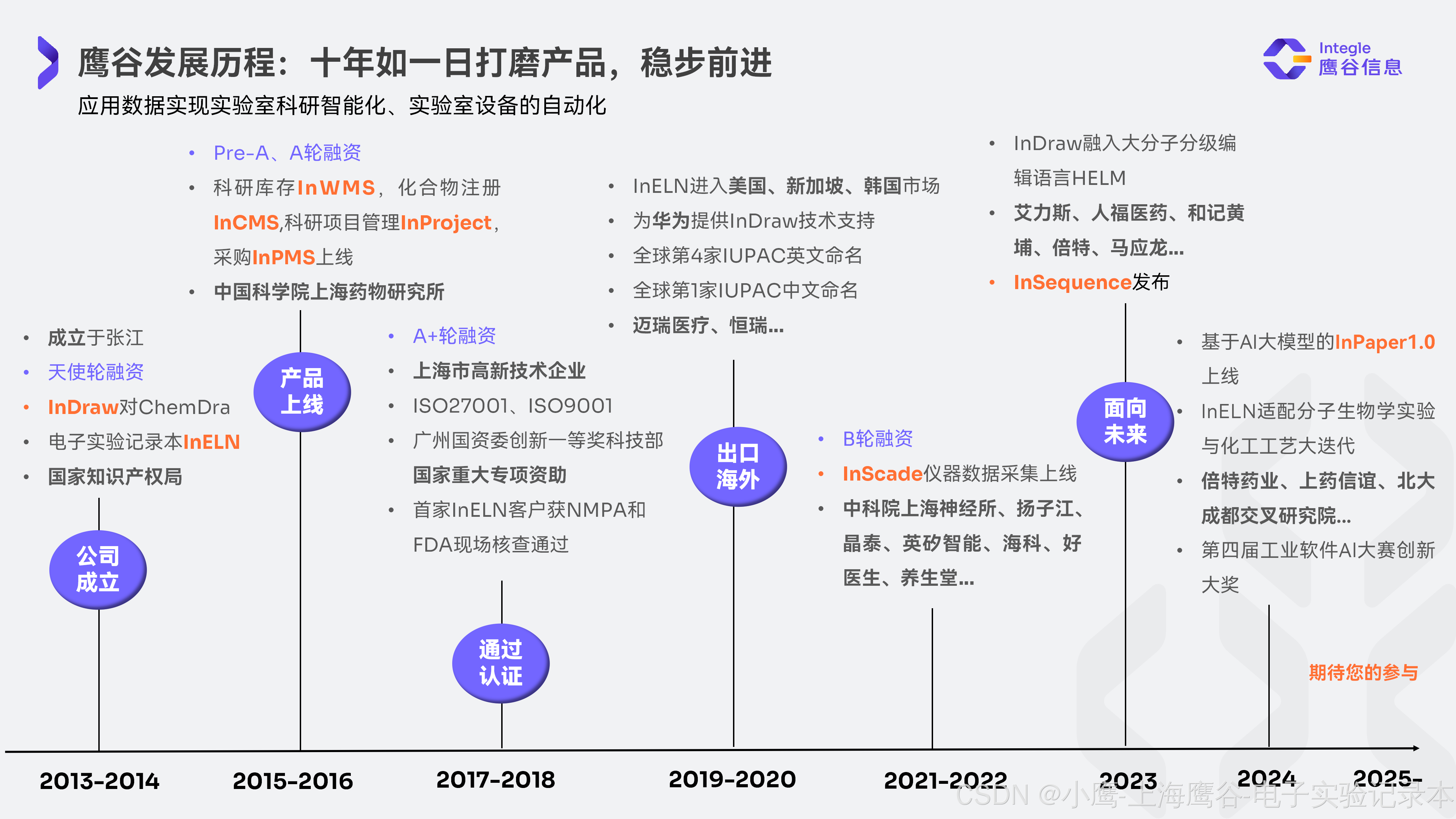
上海鹰谷信息科技有限公司2013年在上海张江成立,创始人、CEO为中科院药物所博士、GSK科学家,核心团队主要为清华、北大、交大、复旦、浙大等一流大学化学、生物、计算机等专业领域科研人才,基于国际化经历,设计鹰谷数字化实验室整体解决方案,根据FDA电子记录监管标准打造鹰谷电子实验记录本,符合中国、美国、欧盟等国际电子记录法规标准。十年来,我们专注打磨产品,不断有新产品问世,客户遍布国内外,2024年期待与您的进一步合作,共创数字化实验室!
04 鹰谷知识产权
鹰谷创始人和研发团队是科学家背景,对各种技术问题有钻研精神,不提倡简单的拿来主义,不提倡把各种第三方软件整合到自己系统,快速拼凑快速推向市场,后续无法持续更新升级。10年专注专一领域自主研发,打造行业内最有技术含量的电子实验记录本品牌,掌握专业性技术,拥有多项专利和近百项著作权,部分如下。

05 结语
让研发有数据、有智慧、有未来
鹰谷信息,努力成为国际领先的实验室数智化解决方案供应商,我们秉持着科技引领未来的信念,不断推动实验室数智化技术的创新与发展。我们致力于让研发过程更加智能化、数据化,让研发有数据,有智慧,有未来。为科研工作者提供强大的数据支持与智慧决策,让每一次实验都充满智慧与洞察,让未来的研发实验室将更加高效、精准,让研发工作焕发出无限可能,开启科技的新篇章。

















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









