




在大模型与RAG技术蓬勃发展的今天,PDF文档解析已成为构建知识库的核心痛点。由于 PDF 在跨平台兼容性和格式固定性方面的优势,企业通常选择 PDF 作为知识资产的主要存储形式。然而,这些文档中的复杂排版(如多栏布局、嵌套表格、公式与图表混排)往往让传统解析工具难以应对。尤其在金融、法律、科研等专业领域,解析失误可能导致语义断层、数据错位,进而引发RAG系统"幻觉式"回答。
针对PDF格式文档版式多样、解析难度大等难题,上海人工智能实验室推出了一款究极武器——MinerU,各位开发者在以往的开发过程中可能听说过这个名字,但这玩意儿究竟是个啥呢?本文将带你一同探索它的奇妙之处,并带大家使用LazyLLM,结合MinerU打造PDF解析与RAG应用的无缝链路。
当RAG遇上PDF,一场AI的"阅读理解噩梦"
"这PDF怎么像俄罗斯套娃?"每个RAG开发者在深夜都会发出的灵魂拷问...
你永远不知道一份专业PDF里藏着多少"反AI陷阱":
🔹 金融报告里嵌套的九层表格
🔹 法律文书里突然出现的竖排注释
🔹 科研论文里公式和图表的花式排列组合
🔹 更别提那些扫描件里堪比抽象画的OCR结果
......

在MagicPDF诞生之前,市面上已经有了很多PDF解析工具,比如pypdf、llama-parse,然而都存在一些能力缺陷。我们调研了市面上n种PDF解析工具后得出一个结论——某些工具处理复杂文档时,像极了用汤勺拆快递的憨憨!(小编真的笑得很大声哈哈哈哈哈哈哈~)
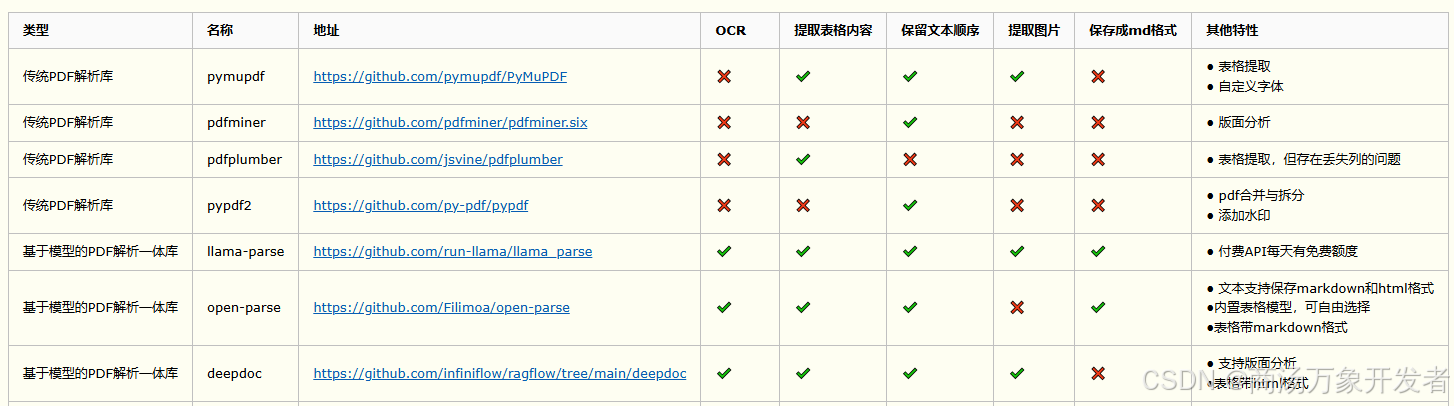
有人会说了:“解析组件只要基本够用就行,至于这么折腾不?”,你以为解析不准顶多让AI犯傻?太天真了!PDF拆包失误轻则社会性死亡,重则引发行业地震!

这些啼笑皆非的案例背后,暴露出RAG对于传统PDF解析技术面对复杂文档的困境。接下来为大家介绍破局利器。
技术CP出道,当"瑞士军刀"遇上"变形金刚"
MinerU——PDF解析界的扫地僧
MinerU是由上海人工智能实验室(上海AI实验室)大模型数据基座OpenDataLab团队开源的全新的智能数据提取工具(官网:https://github.com/opendatalab/MinerU)。MinerU 能够快速识别PDF版面元素,将文档转化为清晰、通顺、易读的Markdown格式。
其核心能力在于:
-
保留原文档的结构和格式,包括标题、段落、列表等;
-
自动删除页眉、页脚、脚注、页码等元素;
-
准确提取图片、表格和公式等多模态内容;
-
符合人类阅读顺序的排版格式。
MinerU代码公开之后,凭借精准、快速的SOTA效果,媲美甚至超过商业软件的性能,获国内外多个技术大V点赞,GitHub Star累计飙升29K+,登顶GitHub Python Trending(2024年7月28日-29日),成为AI数据清洗中一个亮眼的开源工具。
业界反馈确实不错:
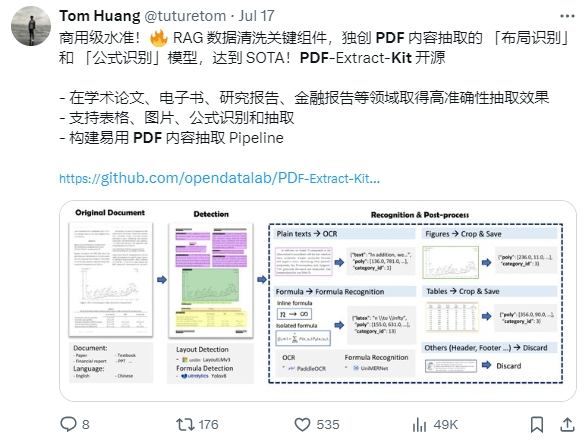
精准解析只是开始,如何把解析能力融入到RAG框架,提升知识提取与问答能力,协同解决复杂文件数据抽取与智能问答的瓶颈?
解决方案来了!
LazyLLM——RAG框架里的乐高大师
LazyLLM是一个开源大模型应用开发框架,可以让我们像搭建积木一样,快速构建出具有生产力的AI大模型应用(官网:https://github.com/LazyAGI/LazyLLM )。LazyLLM旨在以最简单的方法和最少的代码,快速构建复杂、强大的多Agent AI应用原型,即使没有大模型应用开发背景也能轻松上手。
LazyLLM架构图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









