




Flink-Doris-Connector 作为 Apache Flink 与 Doris 之间的桥梁,打通了实时数据同步、维表关联与高效写入的关键链路。本文将深入解析 Flink-Doris-Connector 三大典型场景中的设计与实现,并结合 Flink CDC 详细介绍了整库同步的解决方案,助力构建更加高效、稳定的实时数据处理体系。
一、Apache Doris 简介
Apache Doris 是一款基于 MPP 架构的高性能、实时的分析型数据库,整体架构精简,只有 FE 、BE 两个系统模块。其中 FE 主要负责接入请求、查询解析、元数据管理和任务调度,BE 主要负责查询执行和数据存储。Apache Doris 支持标准 SQL 并且完全兼容 MySQL 协议,可以通过各类支持 MySQL 协议的客户端工具和 BI 软件访问存储在 Apache Doris 中的数据库。
在典型的数据集成和处理链路中,往往会对 TP 数据库、用户行为日志、时序性数据以及本地文件等数据源进行采集,经由数据集成工具或者 ETL 工具处理后写入至实时数仓 Apache Doris 中,并由 Doris 对下游数据应用提供查询和分析,例如典型的 BI 报表分析、OLAP 多维分析、Ad-hoc 即席查询以及日志检索分析等多种数据应用场景。
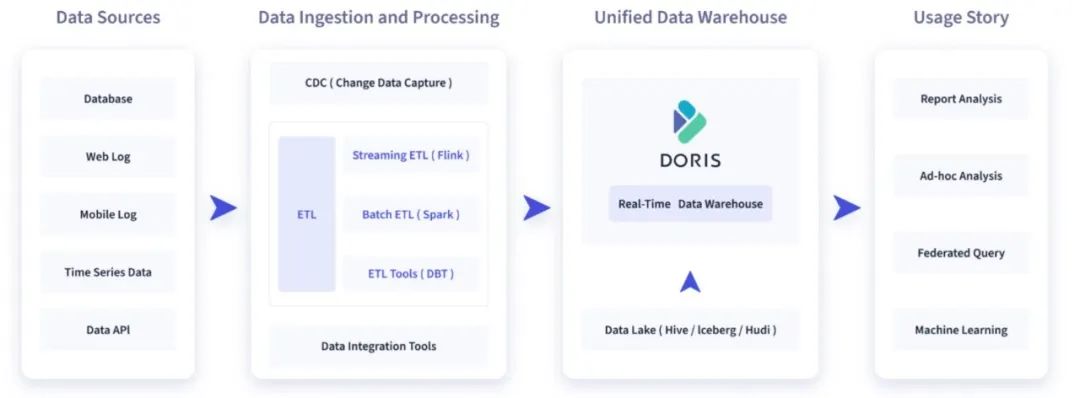
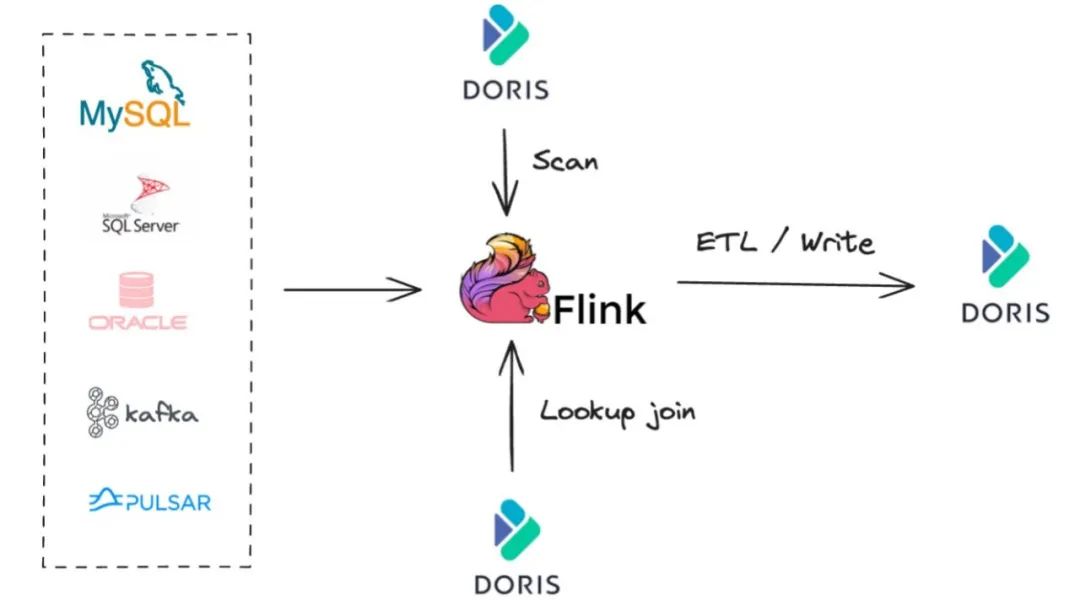
Flink-Doris-Connector 是 Apache Doris 与 Apache Flink 在实时数据处理 ETL 的结合,依托 Flink 提供的实时计算能力,构建高效的数据处理和分析链路。Flink-Doris-Connector 的使用场景主要分为三种:
-
Scan:通常用来做数据同步或是跟其他数据源的联合分析;
-
Lookup Join:将实时流中的数据和 Doris 中的维度表进行 Join;
-
Real-time ETL:使用 Flink 清洗数据再实时写入 Doris 中。
二、Flink-Doris-Connector 典型场景的设计与实现
本章节结合 Scan、Lookup Join、Write 这三种场景,介绍 Flink-Doris-Connector 的设计与实现。
01 Scan 场景
Scan 场景指将 Doris 中的存量数据快速提取出来,当从 Doris 中读取大量数据时,使用传统的 JDBC 方法可能会面临性能瓶颈。因此 Flink-Doris-Connector 中可以借助 Doris Source ,充分利用 Doris 的分布式架构和 Flink 的并行处理能力,从而实现了更高效的数据同步。
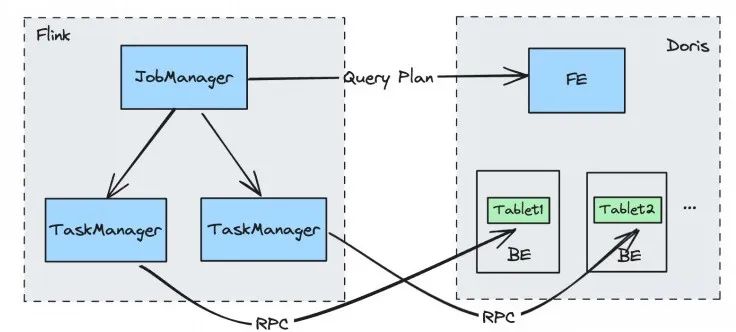
Doris Source 读取流程
-
Job Manager 向 FE 端发起请求查询计划,FE 会返回要查询的数据对应的 BE 以及 Tablet;
-
根据不同的 BE,将请求分发给不同的 TaskManager;
-
通过 Task Manager 直接读取每个 BE 上对应 Tablet 的数据。
通过这种方式,我们可以利用 Flink 分布式处理的能力从而提高整个数据同步的效率。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











