




摘要:在如 Snowflake、ElasticSearch、ClickHouse… 等传统系统中,对于 JSON 的处理往往面临灵活性及性能无法兼得的困境,而 Apache Doris 的 VARIANT 类型,通过动态子列、稀疏列存储、延迟物化和路径索引等能力,实现了灵活结构 + 列存性能的平衡。本文将对该能力的实现一一讲解,全面展示其优势。
在大数据时代,JSON 已成为数据交换的事实标准。从日志、埋点到 IoT 设备数据,从用户画像到实时监控,JSON 凭借其灵活、可扩展、无需预定义 Schema 的特性,完美契合了快速迭代的现代业务需求。然而,JSON 的动态灵活性与传统数据库的静态处理模型存在根本矛盾,这直接导致了查询性能低下、Schema 管理复杂以及在超宽表场景下的扩展性危机。
因此,对于 JSON 数据的处理,用户常常陷入两难抉择:
- 牺牲 性能 换取 灵活性(用 JSON 存储,承担高昂查询开销)
- 牺牲 灵活性 换取 性能(提前建立 Schema,丧失动态响应业务变化能力)
那么,是否存在两全之策,能让性能与灵活性兼得?答案是肯定的。 Doris VARIANT通过底层的存算创新,将半结构化数据的灵活性与结构化数据的分析性能完美结合,全面超越了 Snowflake、ClickHouse 等传统方案。
具体而言,Doris Variant 充分发挥列存与索引优势,避免频繁解析和全量扫描导致 CPU 与 I/O 过高引发性能问题。此外,它能从容应对字段动态变化及类型不一致场景,简化 Schema 维护难度,消除了灵活性与性能间冲突。同时,Doris 优化了超宽表中键值繁多、稀疏分布带来的存储与索引复杂性,解决超宽表场景下扩展性问题。

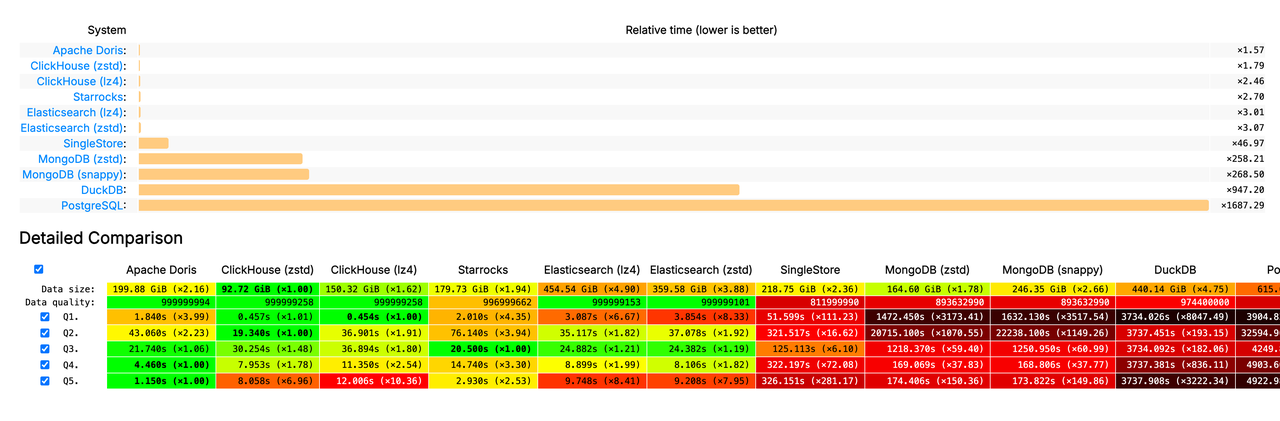
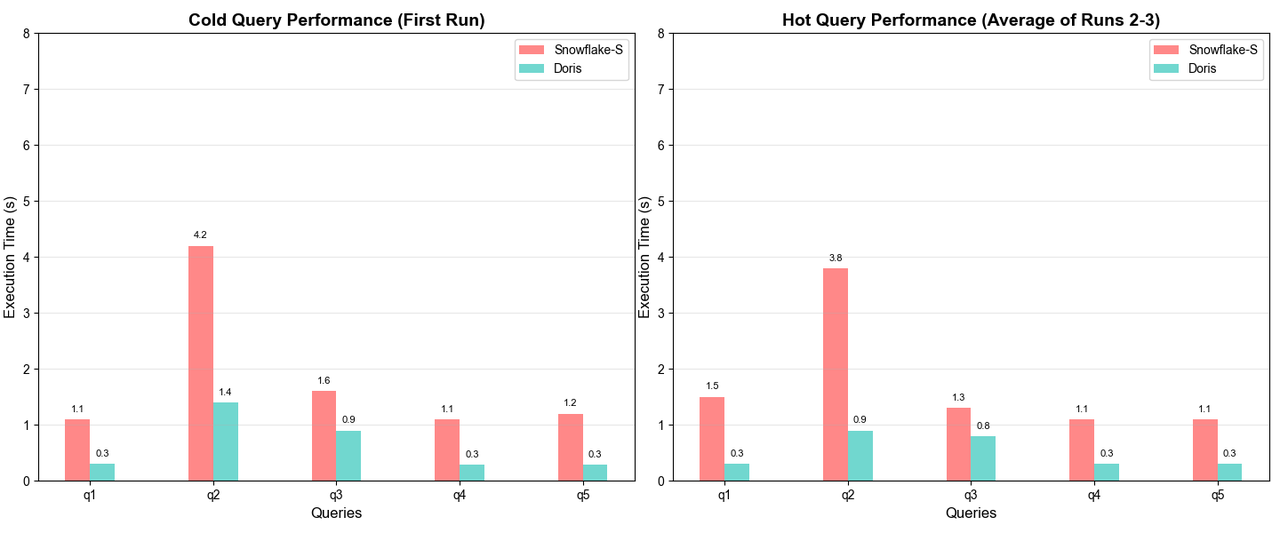
Doris VARIANT 的卓越性能也在业界公开的 JSONBench 半结构化数据测试中得到了充分验证:冷查询性能排名第一、热查询性能位居第二,全面领先 ClickHouse、Elasticsearch 等一众知名产品。 其查询速度约是 MongoDB 的 164 倍、PostgreSQL 的 1074 倍。此外,对 Doris、 Snowflake 进一步对比, 不管是在冷查询还是热查询中,Doris 相较 Snowflake 有约 2-5 倍的性能优势。具体可见下图:
- 登顶 JSONBench 榜单
- Doris vs. Snowflake
Doris Variant 能够具备上述优势,主要得益于以下设计巧思及技术创新。
一、如何让 JSON 获得列存性能?
实现半结构化数据高性能分析的前提是,使其能够像处理结构化数据一样,为其构建高效的列式存储结构,这是后续高性能分析的基础。因此,在 Doris 中,通过动态子列、压缩算法、列裁剪等设计,将半结构数据规范化,从而获获得列存的高性能。
1.1 动态子列
在如 Snowflake 这样的系统中,JSON 数据的底层存储对用户而言是一个黑盒,难以进行查询优化、无法保证性能。而在 Doris 中,当 JSON 对象写入 VARIANT 列时,系统会执行以下操作:
- 子列与类型推断:解析 JSON 的层级结构,提取出所有的 Key Path(如
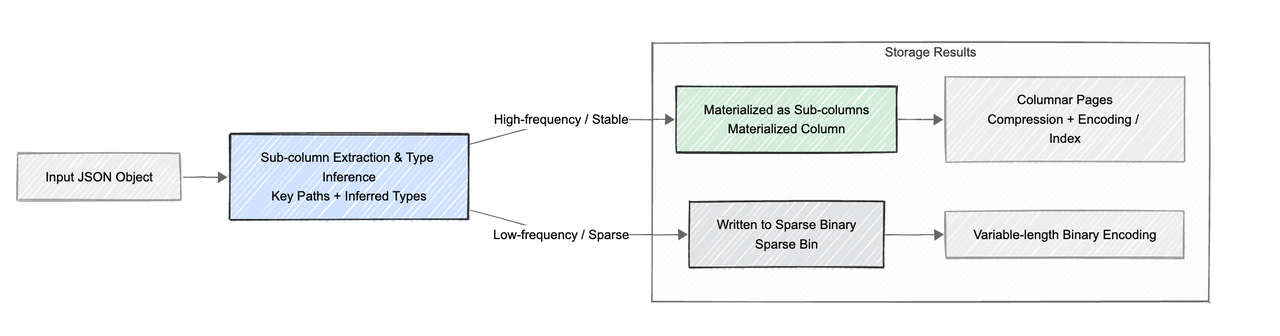
user.id,event.properties.timestamp),并自动推断每个子列的值类型(如BIGINT,DOUBLE,STRING等)。 - 动态列化(Subcolumnization): 对于频繁出现的子列,将其物化为独立的内部子列。例如,嵌套在 JSON 中的
user.id字段在物理存储上会拥有独立的BIGINT列式存储结构。 - 透明访问 :该过程对用户完全透明。无需预先定义 Schema,数据写入时自动完成列式转换。用户仍可使用
v['user']['id']查询 ,但查询引擎可以直接访问到已物化的user.id子列,充分利用列存和向量化执行的性能优势。 - 稀疏列 :对于出现频率极低或结构复杂的稀疏子列,不为其创建独立子列以避免列爆炸。相反,这些数据会被高效组织在一个类 JSONB 的二进制“稀疏”列中,保留完整数据而不为罕见字段额外建列。
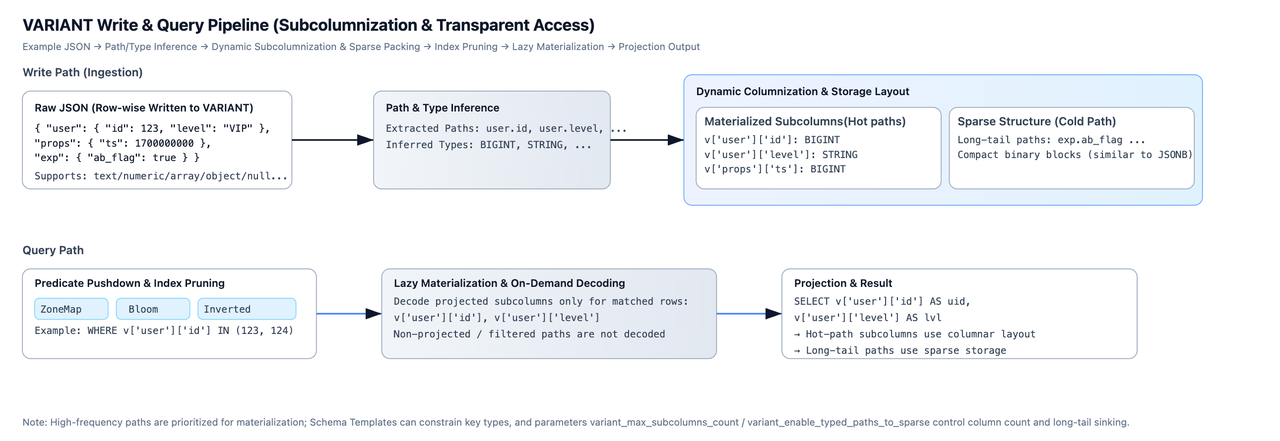
通过这一机制,Doris 在数据写入阶段就完成了从半结构化到准结构化的转换,为高性能分析奠定了基础。
1.2 列式存储
在动态子列的基础上,Doris 进一步运用成熟的列式存储技术,实现存储与 I/O 效率的倍增。
- 压缩: Doris 会根据子列的数据分布自动挑选压缩算法,例如枚举型字段使用字典编码、连续数值用 RLE,从而实现更紧凑的存储并降低读取成本。
- 子列级 I/O (列裁剪):查询只读取实际需要的字段,消除了过去整块 JSON 拉入再解析的方式。通过 Path 级别列裁剪和延迟物化机制,仅加载必需的 JSON 子列数据,有效减少了数据读取的放大问题。

通过以上策略,Doris 解决传统系统中 JSON 查询的慢和重问题,成功地将 JSON 数据的灵活性与列式存储的高性能相结合,实现了半结构化数据的高效分析。 这种方法不仅提高了查询性能,还简化了 Schema 管理,为用户带来显著的使用优势。
1.3 千列级存储的性能跃升
然后,当数据模型从宽进一步演化为超宽时,新的挑战也随之而来。因此 Doris Variant 持续优化,使其能够从容面对元数据膨胀与合并(Compaction)开销巨大的问题。
1.3.1 元数据存储优化
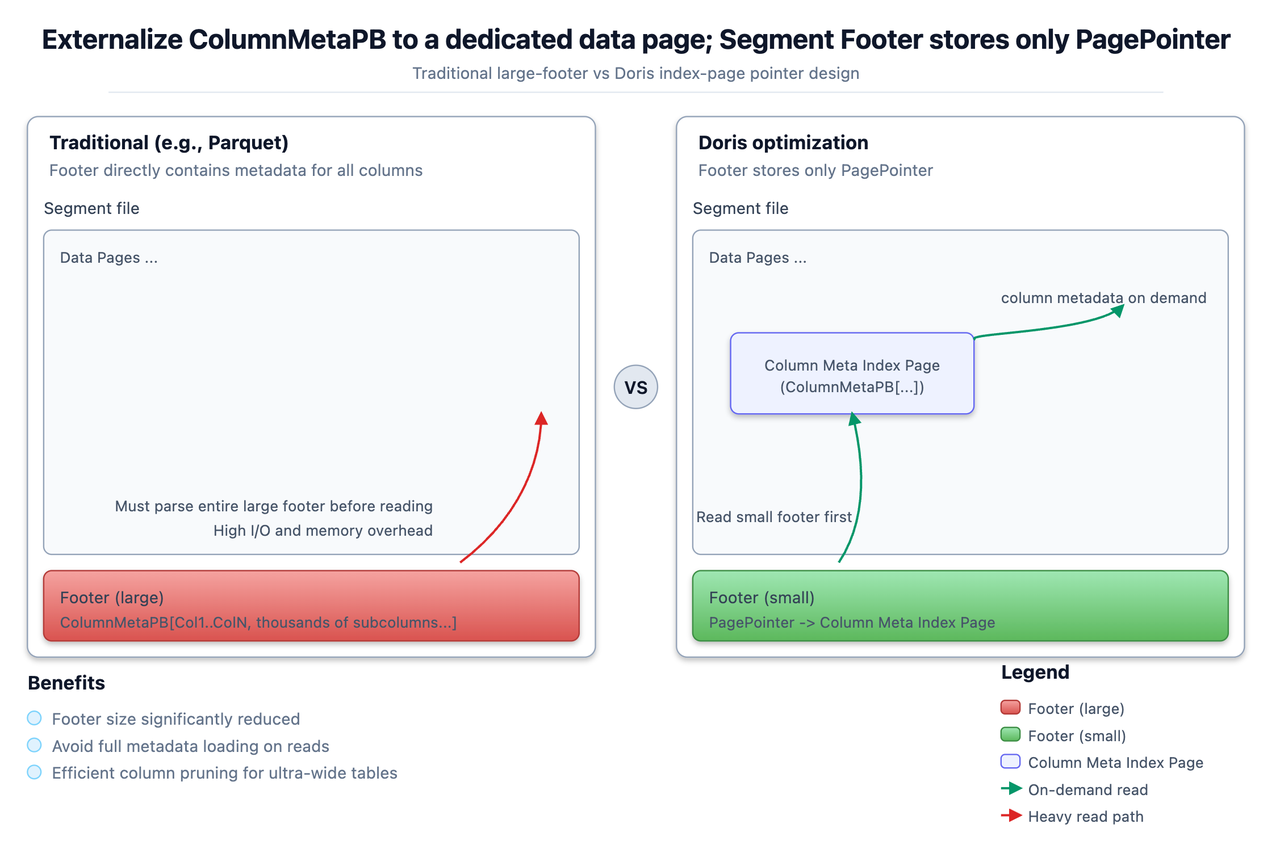
在日志分析、用户画像等超宽表场景中,单表常涉及上千个列(列存)。即便查询仅需访问其中几列,也需将包含所有列元数据的庞大 Footer 完整加载至内存并解析,内存和反序列化成本急剧膨胀,导致严重的 I/O 与内存开销。
为此,Doris 在 Segment 文件格式层进行了关键优化:将列元数据从 Footer 中剥离,独立存储于专用的数据页(可理解为元数据索引页)中,Footer 仅保留指向该页的轻量指针。读取时先加载精简 Footer,再按需定位并加载所需列元数据。这种 Externalize Meta 的设计,从根本上避免了宽表场景下的元数据膨胀问题,使列裁剪始终保持高效。
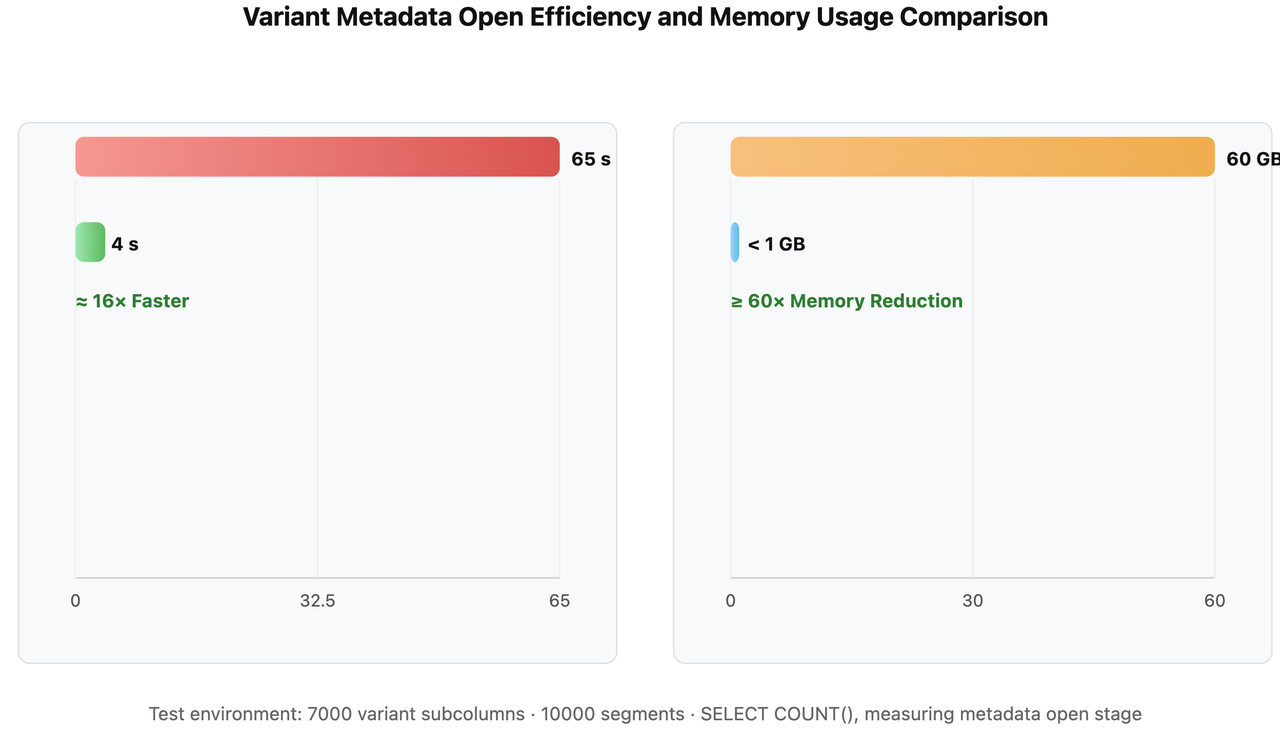
以下是关于 VARIANT 元数据打开效率的测试对比(环境设置包含 10,000 个 Segment,每个 Segment 拥有 7,000 个 JSON Path,且均已物化为子列):
- 优化前:需要解析巨大 Footer(包含所有列的 ColumnMeta),导致大量无效的 I/O 操作、反序列化和内存膨胀,I/O 成为性能瓶颈。
- 优化后:首先读取小型 Footer(仅包含 PagePointer),然后按需加载被访问列的元数据,避免全量解析。打开速度从 65s 缩减至 4s,效率提升约 16 倍;内存从 60GB 缩减至小于 1GB。
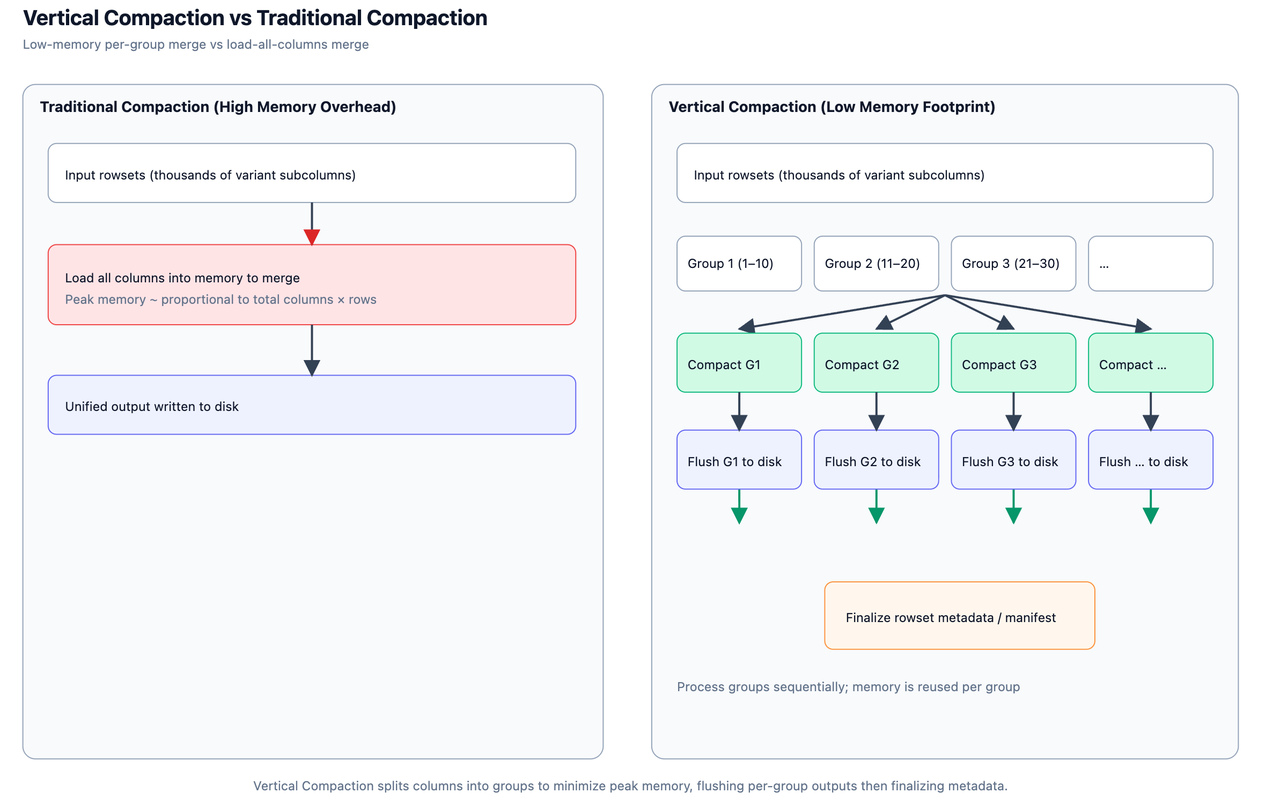
1.3.2 Vertical Compaction
在超宽表场景中,数据合并(Compaction)一直是最棘手的环节。随着表中列数达到上千甚至上万,传统合并策略会暴露出两个主要问题:首先,每次合并都需扫描并重写所有列,即使绝大多数字段并未更新;其次,列元数据和 Segment 文件体积庞大,导致合并的 I/O 成本和内存消耗大幅增加。
为此,Doris Variant 引入子列级 Vertical Compaction,将单次 Compaction 拆分为按列分组的多轮合并。每轮仅加载部分列组(如 10 列),逐步完成全量合并。此举带来两大核心改进:
- 内存峰值显著降低:每轮只需持有部分列的中间数据,避免了全列并发合并带来的内存瞬时激增;
- I/O 访问更加可控:更细粒度的列组处理,可以更好与磁盘调度、后台刷写并行化配合。
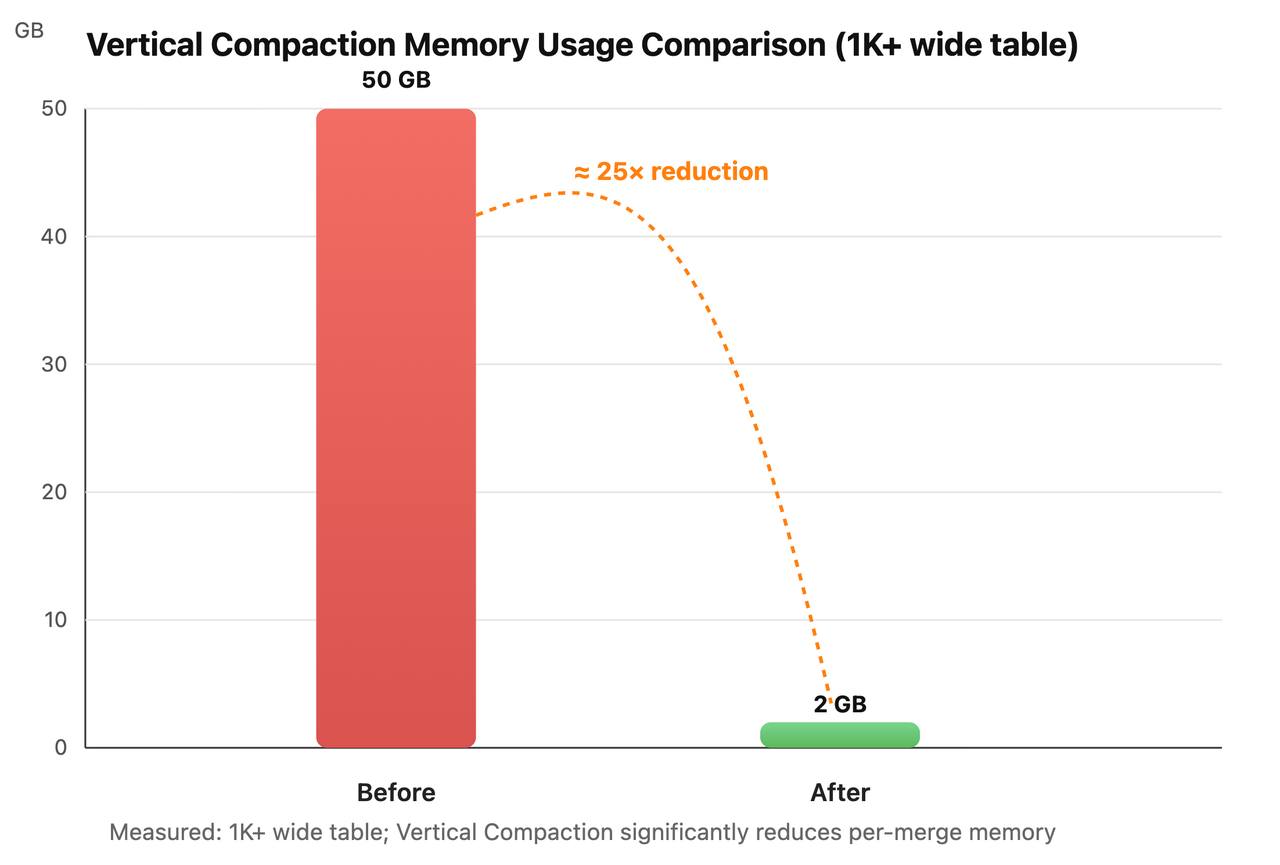
实测结果显示,在表结构中列数超过 1,000 时,开启 Vertical Compaction 后,单次合并的内存占用从约 50 GB 降至 2 GB 左右,降低近 25 倍;同时,整体吞吐量几乎未受影响。更重要的是,Vertical Compaction 使 VARIANT 不再只是能存 JSON,还能在动态 Schema 的超宽表模型中实现长期稳定的运行——这是大多数列式引擎的薄弱环节。
二、 兼备结构化查询与全文检索
动态子列解决了 JSON 在大规模扫描与聚合场景下的性能瓶颈,而 Doris 进一步为其构建了高度可定制的索引机制,使其在点查询与文本检索场景下也具备极速响应的能力。设计借鉴了 Elasticsearch dynamic mapping 的思想,可提供开箱即用的高性能索引能力。
Doris Variant 的索引体系,目标是在 结构化过滤 与 全文检索 之间取得平衡。它既能像列存一样高效命中结构化字段,又能像搜索引擎一样支持关键词匹配与短语检索。为实现这一目标,Doris 在存储层集成倒排索引,并与 ZoneMap、BloomFilter、延迟物化 等原生索引协同工作,实现从文件级到行级的多层剪枝与快速定位。下面从几个关键机制来看它的实现方式:
2.1 倒排索引的无缝集成
- 原理:
VARIANT允许用户为任意子列创建倒排索引。例如,CREATE INDEX idx ON tbl(v) USING INVERTED PROPERTIES("parser" = "english")。Doris 在数据写入时,自动提取v子列的值,并分词(如果需要)或按原始值建立一个从“词(Term)”到“行号(RowID)”的映射表。 - 查询: 当查询条件为
WHERE v['message'] MATCH_ANY 'error'或v['level'] = 'FATAL'时,查询引擎不需扫描全表数据。可直接利用倒排索引,快速定位包含关键词error或FATAL的所有行,查询复杂度从 O(N) 降至 O(logN) 甚至 O(1)。
2.2 内置索引的协同
由于高频子列已被物化为内部子列,它们自然享受到 Doris 的其他索引类型的加成:
- ZoneMap 索引: 默认开启,记录每个数据块(Page)内子列最大/最小值。对于
WHERE v['properties']['price'] > 1000这样的范围查询,可快速跳过不满足条件的数据块,甚至跳过文件。 - BloomFilter 索引: 对于高基数的子列(如
user_id),可创建布隆过滤器索引,快速判断某个值是否存在,过滤掉大量无关读取请求。 - 延迟物化配合索引: 先用 ZoneMap/BBloomFilter 倒排在文件/页/行级完成剪枝与定位,再对查询命中的行按需解码非谓词投影的子列,避免对未投影或被过滤掉的子列做无谓解码,可有效降低 CPU 与 I/O 成本。
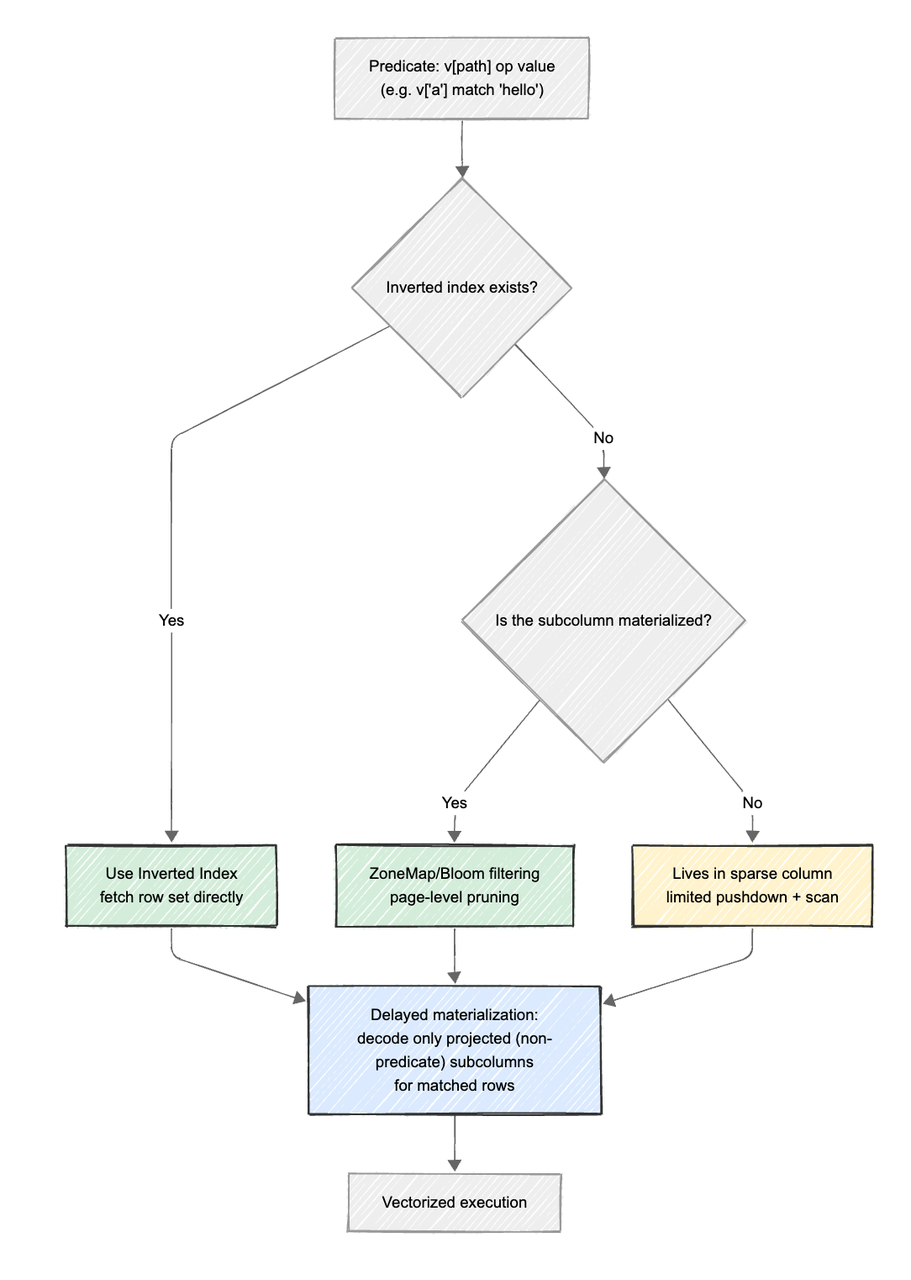
2.3 Schema Template 与 Path 级索引
Schema Template 和 Path 级索引 是实现精确索引下推的关键机制。前者定义「哪些 JSON 子列需被单独识别与优化」,后者定义「这些子列如何被索引与命中」。
通过 Schema Template,可以为关键子列预声明类型及索引属性,让系统在读写阶段就能识别这些高价值路径。 Path 级索引则在此基础上绑定倒排、Bloom 或 ZoneMap 等多层索引策略,实现结构感知的查询优化。
典型配置:
CREATE TABLE IF NOT EXISTS tbl (
k BIGINT,
v VARIANT<'content' : STRING>,
INDEX idx_tokenized(v) USING INVERTED PROPERTIES(
"parser" = "english",
"field_pattern" = "content",
"support_phrase" = "true"
),
INDEX idx_keyword(v) USING INVERTED PROPERTIES(
"field_pattern" = "content"
)
);
-- tokenized for MATCH; keyword for exact equality
SELECT * FROM tbl WHERE v['content'] MATCH 'Doris';
SELECT * FROM tbl WHERE v['content'] = 'Doris';
tokenized 用于
MATCH搜索;keyword 用于精确匹配。
通配符示例:
INDEX idx_logs(v) USING INVERTED PROPERTIES(
"field_pattern" = "logs.*"
);
更多使用方式请参考:Variant 文档
三、典型场景实战指南
3.1 日志分析场景
基于 Elasticsearch 或 ClickHouse 的日志分析平台是较为常见的方案,但其问题也比较明显:写入成本高、字段变化难以管理以及查询吞吐不稳定等。
而如果使用 Doris ,Variant 类型可直接写入原始 JSON 日志,不再需要复杂的 ETL 或 Schema Flatten,无需复杂的预处理和 Schema 定义,即可对任意日志字段进行高性能的过滤和全文检索。
示例建表:
CREATE TABLE access_log (
dt DATE,
log JSON
)
DUPLICATE KEY(dt)
DISTRIBUTED BY HASH(dt)
PROPERTIES ("replication_num" = "1");
CREATE INDEX idx_log ON access_log(log) USING INVERTED;
日志通过 Stream Load 实时写入:
curl -u user:password \
-T access.json \
-H "format: json" \
http://fe_host:8030/api/db/access_log/_stream_load
随后就可以像操作结构化数据一样执行查询:
SELECT
log['status'] AS status,COUNT(*) AS cnt
FROM access_log
WHERE log['region'] = 'US'
GROUP BY status;
在这个场景中,Doris 会自动将 key 列化存储,例如 region 和 status,从而实现亚秒级聚合性能。同时日志结构若有新增字段(例如 latency 或 trace_id),系统会自动创建列存并写入索引,无需手动 ALTER TABLE 或重新导入。
实测表明,在同等硬件条件下,Doris 的日志聚合查询性能相比 Elasticsearch 快 2–3 倍,写入延迟降低 80% 以上,减少约 70–80% 存储空间。
3.2 动态用户画像
在用户画像系统中,每个用户通常拥有成百上千个标签,如地域、兴趣、偏好、活跃度和渠道来源等。这些标签往往需要频繁新增或变更。传统的列式建模方案意味着需要不断修改表结构或维护上百个宽表,这种做法效率极低。而 Doris 的 VARIANT 只需一个 Profile 列即可容纳所有标签信息。
示例建表:
CREATE TABLE user_profile (
user_id BIGINT,
profile VARIANT
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id);
写入时直接插入 JSON 结构:
INSERT INTO user_profile VALUES
(1001, '{"region": "US", "age": 28, "interest": ["movie","sports"]}'),
(1002, '{"region": "CA", "vip": true, "device": "ios"}');
查询时无需展开,也能高效聚合:
SELECT
CAST(profile['region'] AS String) AS region,COUNT(*) AS cnt
FROM user_profile
WHERE profile['vip'] = true
GROUP BY region;
在后台,Doris 会自动识别出现的 key (如 region 、vip ),并将其物化为独立列(支持成千上万的独立列)。极其低频字段仍保留在兜底 Sparse 列中。 因此即便标签数量增长到上千个,查询性能依然接近普通结构化表。
实际用户测试中,拥有 7000 个动态标签的用户画像表,查询 Top10 标签分布的平均响应时间保持在 1 秒以内。
3.3 客户使用反馈
度小满实现从 Greenplum 到 Apache Doris 的平滑迁移,构建了超大规模数据分析平台。借助内置的 Variant 类型,实现了对 2–3 万 JSON Key 的高效查询与存储(PB 级别)。系统整体性能提升 20–30 倍,JSON 查询速度提升 10 倍,存储占用为传统 JSON 类型的 1/10。在高并发实时查询与复杂分析任务下,成功支撑 金融级指标分析与实时数据服务,让度小满的数据平台实现从 离线分析 → 实时洞察的跨越。
——度小满
某大型互联网公司将原有 HBase + Elasticsearch + Snowflake 三套系统迁移至 Doris 这一套系统中来,实现了搜索与分析统一。Doris Variant 列式数据类型支持高维、动态 JSON 的高效存储与查询,让数十亿对象的非结构化属性也能以列式方式处理。并基于子列索引与裁剪机制,查询延迟从秒级降至百毫秒级,并发写入与复杂 Join 性能也显著提升。系统整体成本降低,架构得到简化,稳定性与一致性全面增强。
——某大型互联网公司
在原系统中(Elasticsearch),Dynamic Mapping 导致字段冲突频发、资源占用高、聚合性能受限。观测云携手飞轮科技,基于 Doris 引入 Variant 数据类型与倒排索引,并通过 S3 对象存储 构建弹性冷热分离架构,大幅提升日志与行为数据的查询效率。升级后,机器成本降低 70%,整体查询性能提升 2 倍,简单查询提速超 4 倍,以不到 1/3 的成本获得数倍性能提升,显著增强了可观测性平台的可扩展性与经济性。
——观测云
某全球领先的新能源与智能制造企业将原有 Hive/Kudu + Impala/Presto 体系迁移到 Apache Doris,构建了面向车联网与装备全生命周期的实时分析平台。依托 Doris 内置的 Variant 类型,高效处理 PB 级规模的 JSON 半结构化数据,实现秒级实时摄取和毫秒级查询性能。 在核心业务如实时看板、全链路追踪、设备运行与健康分析等场景中,复杂 JSON 查询提速 3–10 倍、高并发查询能力显著提升、且存储占用仅为传统方案的 1/3。借助统一的 Doris 引擎,实现从离线批处理到实时洞察的跨越,大幅降低整体架构复杂度与运维成本。
——某全球领先的新能源与智能制造企业
面对上百万辆车日均数十 TB 信号数据的挑战,零跑采用 Variant 动态列存 与 S3 对象存储 构建统一数据底座,支持了智能座舱、远程诊断和用户行为分析等多场景。结合物化视图与弹性计算,实现毫秒级查询与自动伸缩、存储成本下降 60% 的显著成效。团队正进一步验证 Serverless 形态,希望利用 S3 的高弹性与 Doris 的高性能,实现“按需使用、零运维伸缩”的数据云脑。
—— 零跑汽车
四、结束语
Apache Doris 的 VARIANT 类型,让半结构化数据能在列式引擎中被自然地处理。它通过动态子列、稀疏列存储、延迟物化和路径索引,将 JSON 解析、列裁剪与索引下推整合为统一体系,实现了灵活结构 与 列存性能的平衡。
未来,Apache Doris 将进一步增强 Variant 自动 Schema 推导能力,支持更丰富的类型、更强大的子列索引系统,并优化稀疏列的数据查询。


















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











