




 某工商信息商业查询平台为应对数据处理挑战,从传统Lambda架构演进到基于Doris Multi - Catalog的湖仓一体架构。介绍了OLAP引擎选型,阐述各架构特点,分享实践与优化经验,如引入Merge - on - Write提速、解决文件版本过多等问题,未来还有升级计划。
某工商信息商业查询平台为应对数据处理挑战,从传统Lambda架构演进到基于Doris Multi - Catalog的湖仓一体架构。介绍了OLAP引擎选型,阐述各架构特点,分享实践与优化经验,如引入Merge - on - Write提速、解决文件版本过多等问题,未来还有升级计划。
作者|某工商信息商业查询平台 高级数据研发工程师 李昂
信息服务行业可以提供多样化、便捷、高效、安全的信息化服务,为个人及商业决策提供了重要支撑与参考。对于行业相关企业来说,数据收集、加工、分析能力的重要性不言而喻。以某工商信息商业查询平台为例,其面对企业公开信息不断变化的挑战,如注册资本变更、股权结构变更、债务债权转移、对外投资变更等,这些信息的变更都要求平台及时更新。然而,面对庞大且频繁的数据变更,如何保证数据的准确性和实时性成为一项艰巨的任务。此外,随着数据量的不断增加,如何快速、高效的处理和分析这些数据成为另一个亟需解决的问题。
为应对上述挑战,该商业查询平台自 2020 年开始搭建数据分析平台,成功地实现了从传统 Lambda 架构到基于 Doris Multi-Catalog 的湖仓一体架构的演进。这种创新性的架构转变,使得该平台实现了离线及实时数仓的数据入口和查询出口的统一,满足了 BI 分析、离线计算、C 端高并发等业务需求,为企业内部、产品营销、客户运营等场景提供了强大的数据洞察及价值挖掘能力。
架构 1.0:传统 Lambda 架构
该商业查询平台成立之初,主要致力于 ToC 和 ToB 这两条业务线。ToC 业务线主要是为 C 端用户提供个性化、精准化的服务;而 ToB 业务线侧重于为 B 端客户提供数据接口服务与交付服务,同时也会处理一些公司内部数据分析需求,以数据驱动企业进行业务优化。
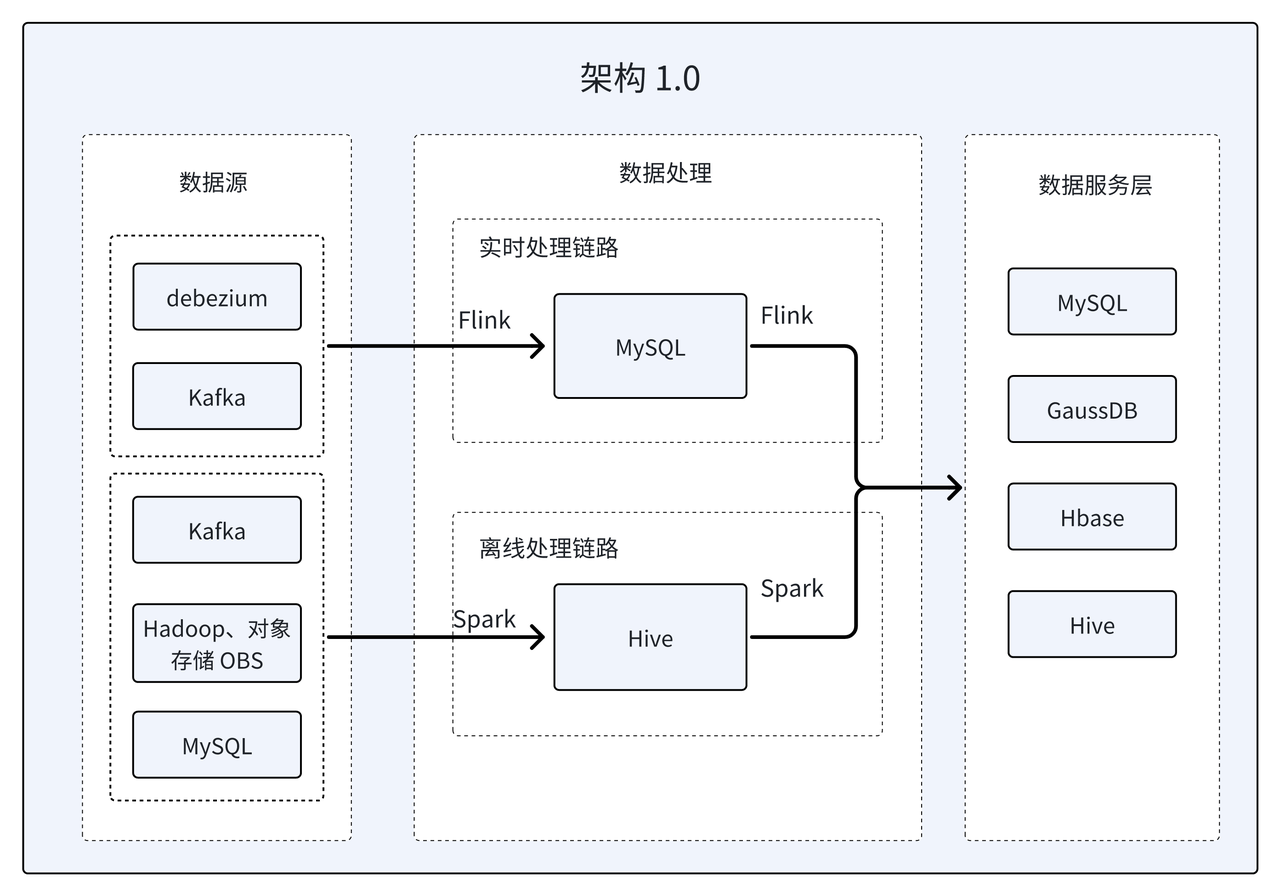
早期采用的是传统的 Lambda 架构,分为离线和实时两套处理流程。实时架构服务于对数据时效要求更高的 ToC 业务线, 离线架构侧重于存量数据修复与 T+7、T+15 的 ToB 数据交付服务等。该架构的优势在于项目开发可以灵活分段提测,并能快速响应业务需求的变化。但是在数据开发、运维管理等方面存在明显缺陷:
- 逻辑冗余:同一个业务方案需要开发离线和实时两套逻辑,代码复用率很低,这就增加了需求迭代成本和开发周期。此外,任务交接、项目管理以及架构运维的难度和复杂度也比较高,给开发团队带来较大的挑战。
- 数据不一致 :在当前架构中,当应用层数据来源存在多条链路时,极易出现数据不一致问题。这些问题不仅增加了数据排查的时间,还对数据的准确性和可靠性带来了负面影响。
- 数据孤岛:在该架构中,数据分散存储在不同的组件中。比如:普通商查表存储在 MySQL 中,主要支持 C 端的高并发点查操作;对于像 DimCount 涉及宽表频繁变更的数据,选择 HBase 的 KV 存储方式;对于单表数据量超过 60 亿的年度维表的点查,则借助 GaussDB 数据库实现。该方式虽然可以各自满足数据需求,但涉及组件较多且数据难以复用,极易造成数据孤岛,限制了数据的深度挖掘和利用。
除此之外,随着商业查询平台业务的不断扩展,新的业务需求不断涌现,例如需要支持分钟级灵活的人群包圈选与优惠券发放计算、订单分析与推送信息分析等新增数据分析需求。为了满足这些需求,该平台开始寻找一个能够集数据集成、查询、分析于一身的强大引擎,实现真正的 All In One。
OLAP 引擎调研
在选型调研阶段,该平台深入考察了 Apache Doris、ClickHouse、Greenplum 这三款数据库。结合早期架构痛点和新的业务需求,新引擎需要具备以下能力:
- 标准 SQL 支持:可使用 SQL 编写函数,学习和使用成本较低;
- 多表联合查询能力:支持人群包即时交并差运算、支持灵活配置的人群包圈选;
- 实时 Upsert 能力:支持 Push 推送日志数据的 Upsert 操作,每天需要更新的数据量高达 6 亿条;
- 运维难度:架构简单,轻量化部署及运维。
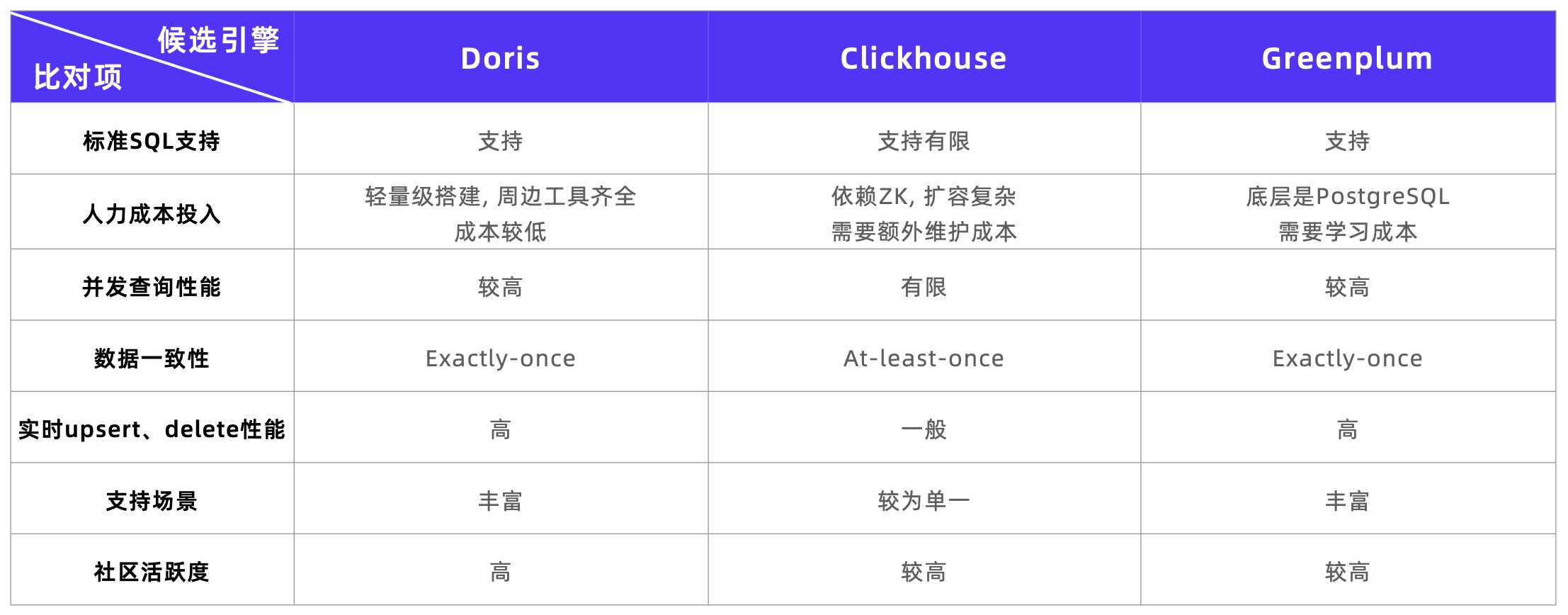
根据调研结果,可以发现 Apache Doris 优势明显、满足该平台的选型目标:
- 多种 Join 逻辑:通过 Colocation Join、Bucket Shuffle Join、Runtime Filter 等 Join 优化手段, 可在雪花模型的基础上进行高效的多表联合 OLAP 分析。
- 高吞吐 Upsert 写入:Unique Key 模型采用了 Merge-on-Write 写时合并模式,支持实时高吞吐的 Upsert 写入,并可以保证 Exactly-Once 的写入语义。
- 支持 Bitmap:Doris 提供了丰富的 Bitmap 函数体系,可便捷的筛选出符合条件的 ID 交并集,可有效提高人群圈选的效率。
- 极简易用:Doris 满足轻量化部署要求,仅有 FE、BE 两种进程,使得横向扩展变得简单,同时降低了版本升级的风险,更有利于维护。此外,Doris 完全兼容标准 SQL 语法,并在数据类型、函数等生态上提供了更全面的支持。
架构 2.0:数据服务层 All in Apache Doris
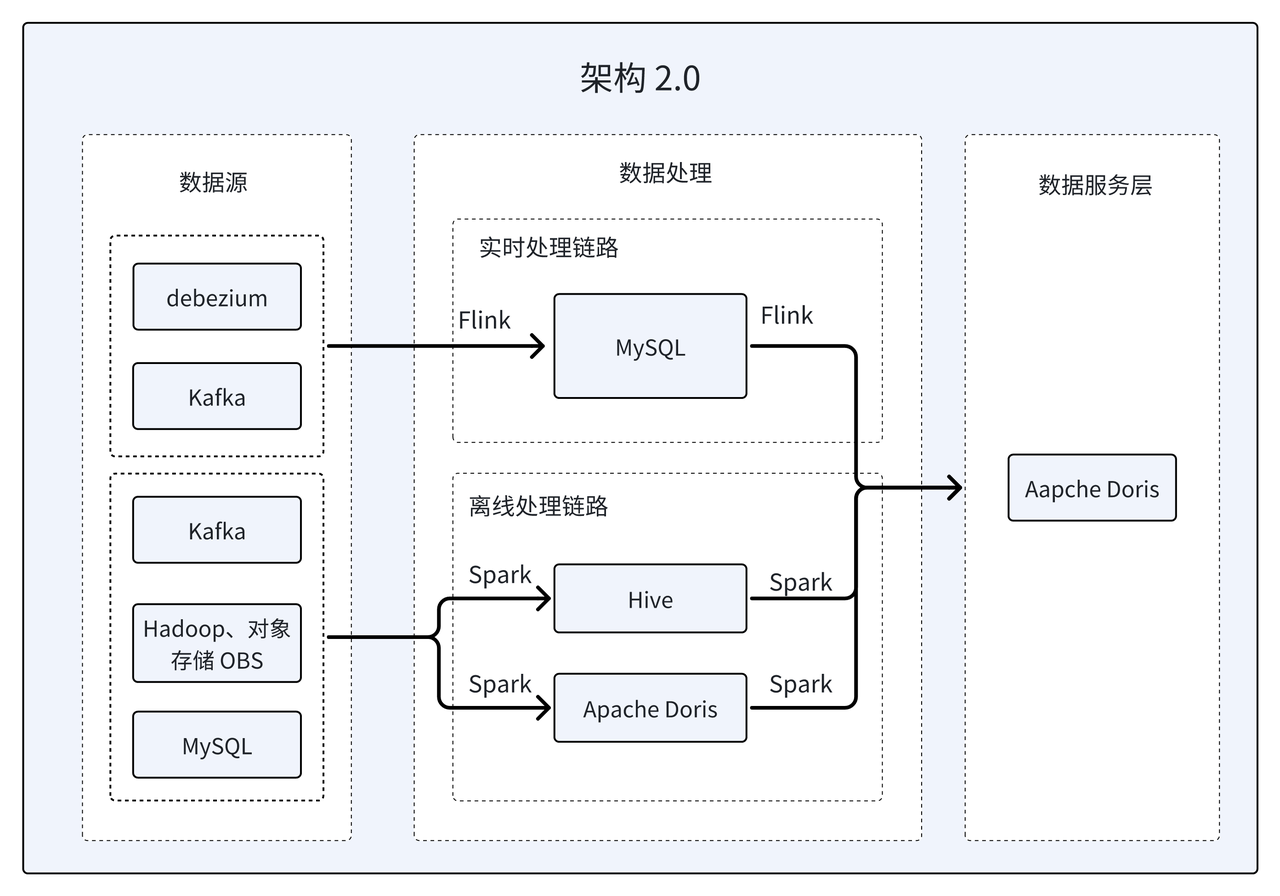
该商业查询平台基于 Apache Doris 升级了数据架构。首先使用 Apache Doris 替换了离线处理链路中的 Hive,其次通过对 Light Schema Change、Unique Key 写时合并等特性的尝试与实践,仅使用 Doris 就取代了早期架构中 GaussDB 、HBase、Hive 三种数据库,打破了数据孤岛,实现了数据服务层 All in Doris。
- 引入 Unique Key 写时合并机制 : 为了满足大表在 C 端常态并发下的点查需求,通过设置多副本并采用 Unique Key 写时合并机制,确保了数据的实时性和一致性。基于该机制 Doris 成功替代了 GaussDB,提供了更高效、更稳定的服务。
- 引入 Light Schema Change 机制 : 该机制使可以在秒级时间内完成 DimCount 表字段新增操作,提高了数据处理的效率。基于该机制 Doris 成功替代了 HBase,实现了更快速、更灵活的数据处理。
- 引入 PartialUpdate 机制 : 通过 Aggregate 模型的
REPLACE_IF_NOT_NULL,加速两表关联的开发,这一改进使得多表级联开发更加高效。
Apache Doris 上线后,其业务覆盖范围迅速扩大,并在短期内就取得了显著的成果:
- 2023 年 3 月,Apache Doris 正式上线后,运行了两个集群十余台 BE,这两个集群分别负责数分团队商业化分析与数据平台部架构优化,共同支撑大规模的数据处理分析的重要任务,每天支撑数据量高达 10 亿条,计算指标达 500+,支持人群包圈选、优惠券推送、充值订单分析及数据交付等需求。
- 2023 年 5 月,借助 Apache Doris 完成数分团队商业化分析集群 ETL 任务的流式覆写,近半离线定时调度任务迁移至 Doris 中,提高了离线计算任务的稳定性和时效性,同时绝大多数实时任务也迁移至 Apache Doris 中,整体集群规模达到二十余台。
尽管架构 2.0 中实现了数据服务层的 All in One,并且引入了 Doris 加速离线计算任务,但离线链路与实时链路仍然是割裂的状态,依旧面临处理逻辑重复、数据不一致的问题。其次,虽然引入 Doris 实现了大批量数据的实时更新与即时查询,但是对于时效性要求不高的离线任务,将其迁移至 Doris 集群可能会对在线业务的集群负载和稳定性产生一定的影响。因此,该平台计划进行下一步升级改造。
架构 3.0:基于 Doris Multi-Catalog 的湖仓一体架构
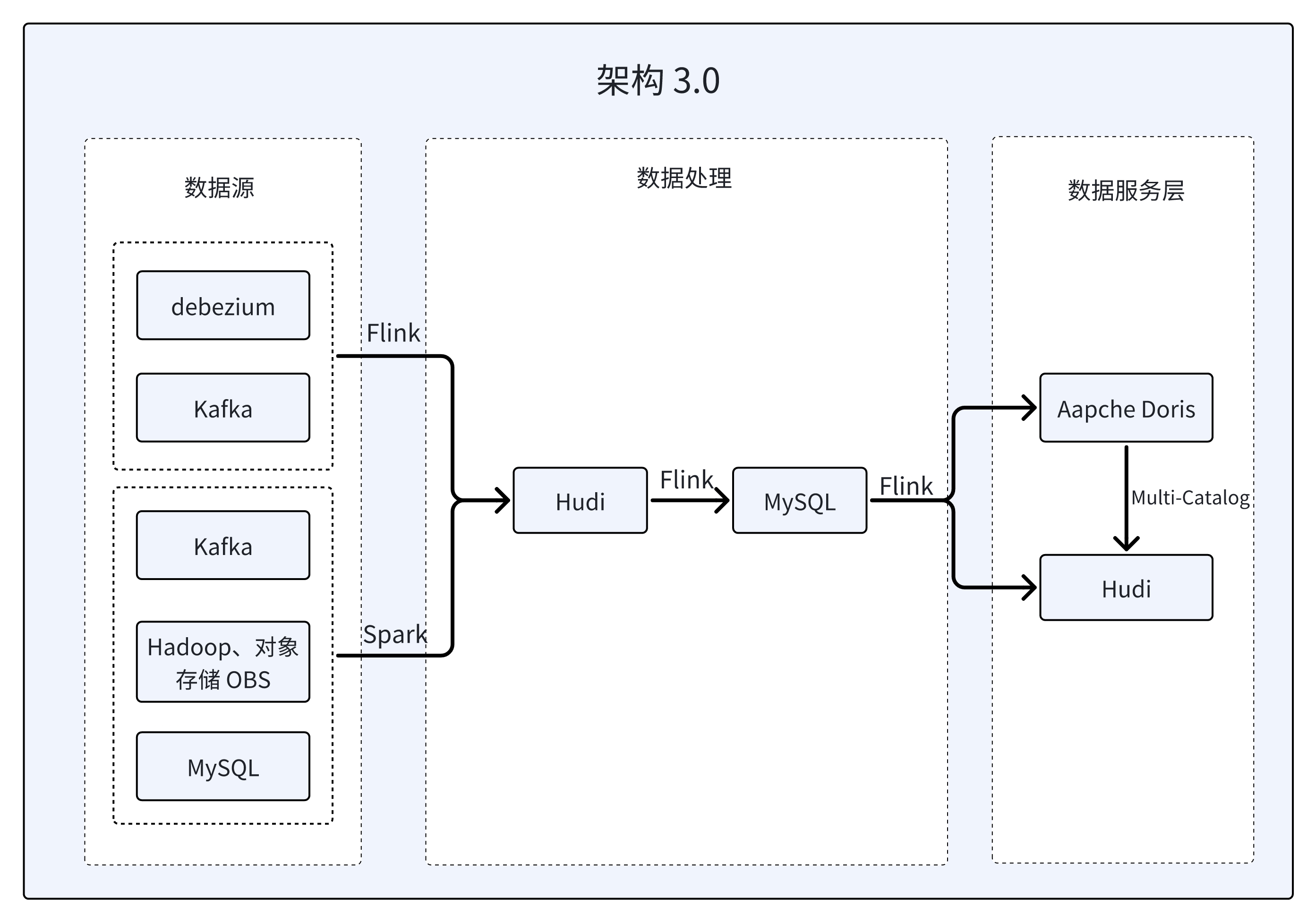
考虑到 Doris 多源 Catalog 具备的数据湖分析能力,该平台决定在架构中引入 Hudi 作为数据更新层
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7175
7175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











