




 本文详细介绍Flink与ApacheDoris 1.1在实时数仓中的优化,包括流式写入策略改进、秒级数据同步、Exactly-Once语义实现,以及对高并发场景和数据可见性的增强
本文详细介绍Flink与ApacheDoris 1.1在实时数仓中的优化,包括流式写入策略改进、秒级数据同步、Exactly-Once语义实现,以及对高并发场景和数据可见性的增强
导读:随着数据实时化需求的日益增多,数据的时效性对企业的精细化运营越来越重要,使得实时数仓在这一过程中起到了不可替代的作用。本文将基于用户遇到的问题与挑战,揭秘 Apache Doris 1.1 特性,对 Flink 实时写入 Apache Doris 的优化实现与未来规划进行详细的介绍。
背景
随着数据实时化需求的日益增多,数据的时效性对企业的精细化运营越来越重要,在海量数据中,如何能实时有效的挖掘出有价值的信息,快速的获取数据反馈,协助公司更快的做出决策,更好的进行产品迭代,实时数仓在这一过程中起到了不可替代的作用。
在这种形势下,Apache Doris 作为一款实时 MPP 分析型数据库脱颖而出,同时具备高性能、简单易用等特性,具有丰富的数据接入方式,结合 Flink 流式计算,可以让用户快速将 Kafka 中的非结构化数据以及 MySQL 等上游业务库中的变更数据,快速同步到 Doris 实时数仓中,同时 Doris 提供亚秒级分析查询的能力,可以有效地满足实时 OLAP、实时数据看板以及实时数据服务等场景的需求。
挑战
通常实时数仓要保证端到端高并发以及低延迟,往往面临诸多挑战,比如:
-
如何保证端到端的秒级别数据同步?
-
如何快速保证数据可见性?
-
在高并发大压力下,如何解决大量小文件写入的问题?
-
如何确保端到端的 Exactly Once 语义?
结合这些挑战,同时对用户使用 Flink+Doris 构建实时数仓的业务场景进行深入调研,在掌握了用户使用的痛点之后,我们在 Doris 1.1 版本中进行了针对性的优化,大幅提升实时数仓构建的用户体验,同时提升系统的稳定性,系统资源消耗也得到了大幅的优化。
优化
流式写入
Flink Doris Connector 最初的做法是在接收到数据后,缓存到内存 Batch 中,通过攒批的方式进行写入,同时使用 batch.size、batch.interval 等参数来控制 Stream Load 写入的时机。这种方式通常在参数合理的情况下可以稳定运行,一旦参数不合理导致频繁的 Stream Load,便会引发 Compaction 不及时,从而导致 version 过多的错误(-235);其次,当数据过多时,为了减少 Stream Load 的写入时机,batch.size 过大的设置还可能会引发 Flink 任务的 OOM。为了解决这个问题,我们引入了流式写入 :
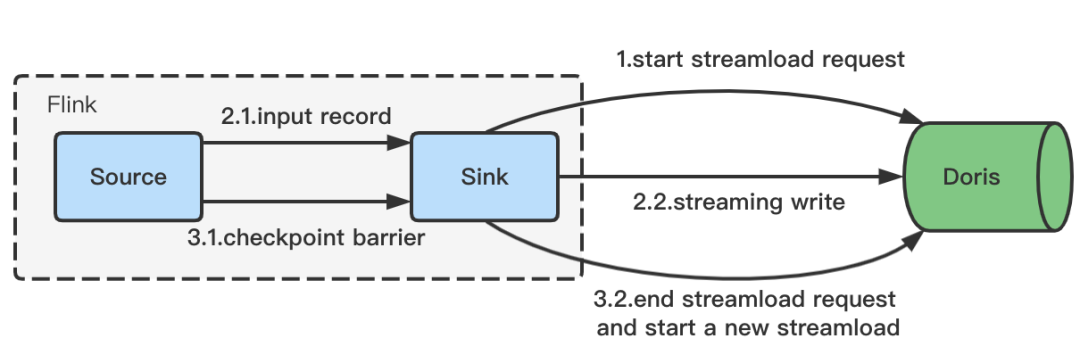
-
Flink 任务启动后,会异步发起一个 Stream Load 的 Http 请求。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4434
4434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











