



 本文详细介绍了如何使用Pandas对含有文本数据的DataFrame进行操作,如转换大小写、创建新列、拆分、筛选和替换,以及使用字符串索引。通过实际案例演示,展示了如何高效处理微信ID、户籍地址等信息并提取关键信息。
本文详细介绍了如何使用Pandas对含有文本数据的DataFrame进行操作,如转换大小写、创建新列、拆分、筛选和替换,以及使用字符串索引。通过实际案例演示,展示了如何高效处理微信ID、户籍地址等信息并提取关键信息。
毋庸置疑,Pandas是使用最广泛的 Python 库之一,它提供了许多功能和方法来执行有效的数据处理和数据分析。
我们平时的操作,大多围绕着数字的处理,这是因为大家习惯将表格数据与数字联系起来。然而我们无论是使用Excel还是Pandas,其实都离不开文本类型的数据。

今天,我们会通过一个例子,总结这些常用的Pandas处理文本数据的操作。
首先,先创建一个带有模拟数据的DataFrame。
import pandas as pd
df = pd.DataFrame({
"姓": ["王","仲","宝", "王", "朱"],
"名": ["玉环","觅晴","清俊", "鸿博", "小五"],
"户籍地址": ["黑龙江省·哈尔滨市", "黑龙江省·哈尔滨市", "黑龙江省·佳木斯市", "广西·柳州市", "湖北省·武汉市"],
"微信": ["Tomout", "Sm857", "Adamshffhhjfj", "Tull88", "ZPW505"],
"邮箱": ["tom02@163.com", "smitt@163.com", "adams@163.com", "tull03@163.com", "five@163.com"]
})
df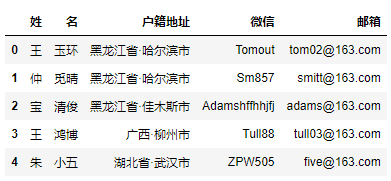
一共五列文本数据:姓、名、户籍地址、微信id、邮箱地址。
讲个冷知识:微信id是不区分大小写的。

如果将微信id这列的文本数据,全部转换为小写,在Pandas中可以这样操作。
df["微信"] = df["微信"].str.lower()
df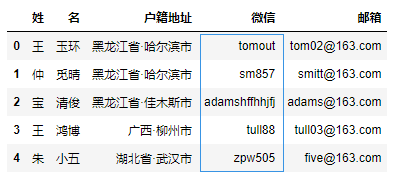
我们可以通过组合姓氏和名字,来创建姓名这列。
df["姓名"] = df["姓"] + df["名"]
df但是在默认情况下,新列会被添加在末尾。
想要更多的自定义选择,可以参考下面的代码。既可以在特定位置插入创建新列,也可以使用 cat 方法组合字符串(此处还可设置分隔符sep,这里并未设置)。
df.insert(2,
"姓名",
df["姓"].str.cat(df["名"], sep=""))
df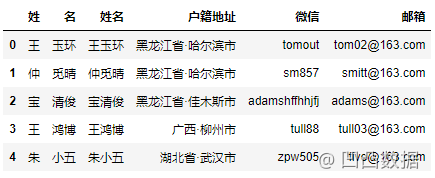
对字符串的一个常见操作是拆分,当文本数据包含多条信息时,它就派上用场啦。
例如,户籍地址这列包括省份和城市,我们可以通过拆分此列来提取城市的信息。
df["城市"] = df["户籍地址"].str.split("·", expand=True)[1]
df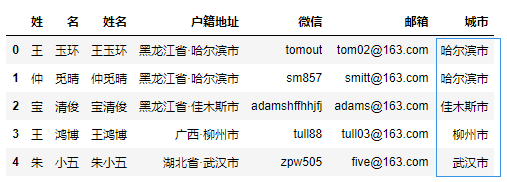
对字符串的另一个常见操作是筛选过滤,那么在Pandas中如何操作呢?
如果想筛选“王”字开头的姓名,既可以直接筛选 姓 这一列,也可以使用startswith()来过滤。
startswith() 和endswith() 这两个函数,是分别基于字符串的第一个或最后一个字母进行筛选。
df[df["姓名"].str.startswith("王")]
注意:
startswith()和endswith()这两个函数,还可以通过设置参数,既能检测多个字符,又能设置字符串检测的起始和结束位置。

如果想直接筛选包含特定字符的字符串,可以使用contains()这个方法。
例如,筛选户籍地址列中包含“黑龙江”这个字符的所有行。
df[df["户籍地址"].str.contains("黑龙江")]
replace()方法可用于替换字符串中的字符序列,通过该方法可以修改Pandas中的文本数据。
df["户籍地址"] = df["户籍地址"].str.replace("广西", "广西壮族自治区")
df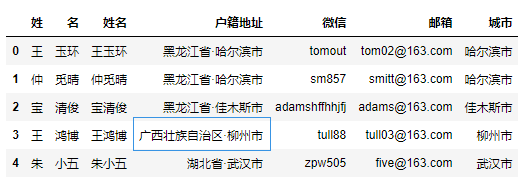
最后,我们还可以使用字符串的索引。
例如,我们可以用“str[:5]”表达式选择前8个字符,用“str[-8:]”选择后8个字符。
df["邮箱"].str[:5]
df["邮箱"].str[-8:]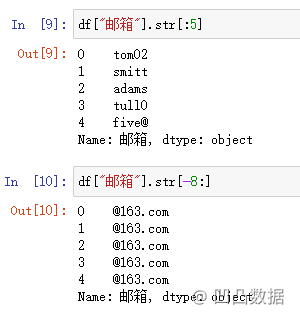
本文已经罗列了在Pandas中比较常用文本数据处理操作,欢迎大家在评论区补充!

●分析师最常用的10大分析方法。
●品牌知名度分析实例在看支持 👇
















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









