



 本文介绍了如何通过优化Python代码提高Pandas操作的性能,从最初的for循环和apply方法,逐步过渡到使用iterrows、.apply以及矢量化操作如.isin和pd.cut。通过实例展示了如何利用这些方法减少计算时间,最终使用NumPy的digitize函数实现了最快的速度。对于处理大规模数据时,理解并运用这些技巧能显著提升效率。
本文介绍了如何通过优化Python代码提高Pandas操作的性能,从最初的for循环和apply方法,逐步过渡到使用iterrows、.apply以及矢量化操作如.isin和pd.cut。通过实例展示了如何利用这些方法减少计算时间,最终使用NumPy的digitize函数实现了最快的速度。对于处理大规模数据时,理解并运用这些技巧能显著提升效率。

大家好,我是小z
本篇分享一个常用的加速骚操作。
for是所有编程语言的基础语法,初学者为了快速实现功能,依懒性较强。但如果从运算时间性能上考虑可能不是特别好的选择。
本次介绍几个常见的提速方法,一个比一个快,了解pandas本质,才能知道如何提速。
下面是一个例子,数据获取方式见文末。
>>> import pandas as pd
# 导入数据集
>>> df = pd.read_csv('demand_profile.csv')
>>> df.head()
date_time energy_kwh
0 1/1/13 0:00 0.586
1 1/1/13 1:00 0.580
2 1/1/13 2:00 0.572
3 1/1/13 3:00 0.596
4 1/1/13 4:00 0.592
基于上面的数据,我们现在要增加一个新的特征,但这个新的特征是基于一些时间条件生成的,根据时长(小时)而变化,如下:
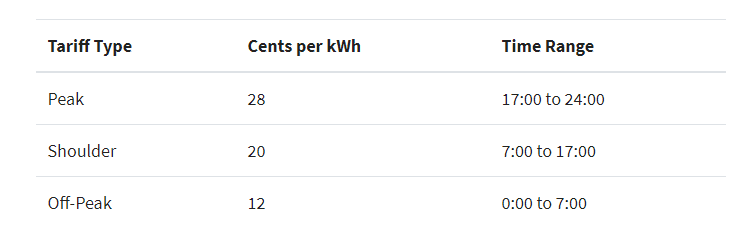
因此,如果你不知道如何提速,那正常第一想法可能就是用apply方法写一个函数,函数里面写好时间条件的逻辑代码。
def apply_tariff(kwh, hour):
"""计算每个小时的电费"""
if 0 <= hour < 7:
rate = 12
elif 7 <= hour < 17:
rate = 20
elif 17 <= hour < 24:
rate = 28
else:
raise ValueError(f'Invalid hour: {hour}')
return rate * kwh
然后使用for循环来遍历df,根据apply函数逻辑添加新的特征,如下:
>>> # 不赞同这种操作
>>> @timeit(repeat=3, number=100)
... def apply_tariff_loop(df):
... """用for循环计算enery cost,并添加到列表"""
... energy_cost_list = []
... for i in range(len(df)):
... # 获取用电量和时间(小时)
... energy_used = df.iloc[i]['energy_kwh']
... hour = df.iloc[i]['date_time'].hour
... energy_cost = apply_tariff(energy_used, hour)
... energy_cost_list.append(energy_cost)
... df['cost_cents'] = energy_cost_list
...
>>> apply_tariff_loop(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_loop` ran in average of 3.152 seconds.
对于那些写Pythonic风格的人来说,这个设计看起来很自然。然而,这个循环将会严重影响效率。原因有几个:
首先,它需要初始化一个将记录输出的列表。
其次,它使用不透明对象范围(0,len(df))循环,然后再应用apply_tariff()之后,它必须将结果附加到用于创建新DataFrame列的列表中。另外,还使用df.iloc [i]['date_time']执行所谓的链式索引,这通常会导致意外的结果。
这种方法的最大问题是计算的时间成本。对于8760行数据,此循环花费了3秒钟。
接下来,一起看下优化的提速方案。
一、使用 iterrows循环
第一种可以通过pandas引入iterrows方法让效率更高。这些都是一次产生一行的生成器方法,类似scrapy中使用的yield用法。
.itertuples为每一行产生一个namedtuple,并且行的索引值作为元组的第一个元素。nametuple是Python的collections模块中的一种数据结构,其行为类似于Python元组,但具有可通过属性查找访问的字段。
.iterrows为DataFrame中的每一行产生(index,series)这样的元组。
在这个例子中使用.iterrows,我们看看这使用iterrows后效果如何。
>>> @timeit(repeat=3, number=100)
... def apply_tariff_iterrows(df):
... energy_cost_list = []
... for index, row in df.iterrows():
... # 获取用电量和时间(小时)
... energy_used = row['energy_kwh']
... hour = row['date_time'].hour
... # 添加cost列表
... energy_cost = apply_tariff(energy_used, hour)
... energy_cost_list.append(energy_cost)
... df['cost_cents'] = energy_cost_list
...
>>> apply_tariff_iterrows(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_iterrows` ran in average of 0.713 seconds.
这样的语法更明确,并且行值引用中的混乱更少,因此它更具可读性。
时间成本方面:快了近5倍!
但是,还有更多的改进空间,理想情况是可以用pandas内置更快的方法完成。
二、pandas的apply方法
我们可以使用.apply方法而不是.iterrows进一步改进此操作。pandas的.apply方法接受函数callables并沿DataFrame的轴(所有行或所有列)应用。下面代码中,lambda函数将两列数据传递给apply_tariff():
>>> @timeit(repeat=3, number=100)
... def apply_tariff_withapply(df):
... df['cost_cents'] = df.apply(
... lambda row: apply_tariff(
... kwh=row['energy_kwh'],
... hour=row['date_time'].hour),
... axis=1)
...
>>> apply_tariff_withapply(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_withapply` ran in average of 0.272 seconds.
apply的语法优点很明显,行数少,代码可读性高。在这种情况下,所花费的时间大约是iterrows方法的一半。
但是,这还不是“非常快”。一个原因是apply()将在内部尝试循环遍历Cython迭代器。但是在这种情况下,传递的lambda不是可以在Cython中处理的东西,因此它在Python中调用并不是那么快。
如果我们使用apply()方法获取10年的小时数据,那么将需要大约15分钟的处理时间。如果这个计算只是大规模计算的一小部分,那么真的应该提速了。这也就是矢量化操作派上用场的地方。
三、矢量化操作:使用.isin选择数据
什么是矢量化操作?
如果你不基于一些条件,而是可以在一行代码中将所有电力消耗数据应用于该价格:df ['energy_kwh'] * 28,类似这种。那么这个特定的操作就是矢量化操作的一个例子,它是在pandas中执行的最快方法。
但是如何将条件计算应用为pandas中的矢量化运算?
一个技巧是:根据你的条件,选择和分组DataFrame,然后对每个选定的组应用矢量化操作。
在下面代码中,我们将看到如何使用pandas的.isin()方法选择行,然后在矢量化操作中实现新特征的添加。在执行此操作之前,如果将date_time列设置为DataFrame的索引,会更方便:
# 将date_time列设置为DataFrame的索引
df.set_index('date_time', inplace=True)
@timeit(repeat=3, number=100)
def apply_tariff_isin(df):
# 定义小时范围Boolean数组
peak_hours = df.index.hour.isin(range(17, 24))
shoulder_hours = df.index.hour.isin(range(7, 17))
off_peak_hours = df.index.hour.isin(range(0, 7))
# 使用上面apply_traffic函数中的定义
df.loc[peak_hours, 'cost_cents'] = df.loc[peak_hours, 'energy_kwh'] * 28
df.loc[shoulder_hours,'cost_cents'] = df.loc[shoulder_hours, 'energy_kwh'] * 20
df.loc[off_peak_hours,'cost_cents'] = df.loc[off_peak_hours, 'energy_kwh'] * 12
我们来看一下结果如何。
>>> apply_tariff_isin(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_isin` ran in average of 0.010 seconds.
提示,上面.isin()方法返回的是一个布尔值数组,如下:
[False, False, False, ..., True, True, True]
布尔值标识了DataFrame索引datetimes是否落在了指定的小时范围内。然后把这些布尔数组传递给DataFrame的.loc,将获得一个与这些小时匹配的DataFrame切片。然后再将切片乘以适当的费率,这就是一种快速的矢量化操作了。
上面的方法完全取代了我们最开始自定义的函数apply_tariff(),代码大大减少,同时速度起飞。
运行时间比Pythonic的for循环快315倍,比iterrows快71倍,比apply快27倍!
四、还能更快?
太刺激了,我们继续加速。
在上面apply_tariff_isin中,我们通过调用df.loc和df.index.hour.isin三次来进行一些手动调整。如果我们有更精细的时间范围,你可能会说这个解决方案是不可扩展的。但在这种情况下,我们可以使用pandas的pd.cut()函数来自动完成切割:
@timeit(repeat=3, number=100)
def apply_tariff_cut(df):
cents_per_kwh = pd.cut(x=df.index.hour,
bins=[0, 7, 17, 24],
include_lowest=True,
labels=[12, 20, 28]).astype(int)
df['cost_cents'] = cents_per_kwh * df['energy_kwh']
上面代码pd.cut()会根据bin列表应用分组。
其中include_lowest参数表示第一个间隔是否应该是包含左边的。
这是一种完全矢量化的方法,它在时间方面是最快的:
>>> apply_tariff_cut(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_cut` ran in average of 0.003 seconds.
到目前为止,使用pandas处理的时间上基本快达到极限了!只需要花费不到一秒的时间即可处理完整的10年的小时数据集。
但是,最后一个其它选择,就是使用 NumPy,还可以更快!
五、使用Numpy继续加速
使用pandas时不应忘记的一点是Pandas的Series和DataFrames是在NumPy库之上设计的。并且,pandas可以与NumPy阵列和操作无缝衔接。
下面我们使用NumPy的 digitize()函数更进一步。它类似于上面pandas的cut(),因为数据将被分箱,但这次它将由一个索引数组表示,这些索引表示每小时所属的bin。然后将这些索引应用于价格数组:
@timeit(repeat=3, number=100)
def apply_tariff_digitize(df):
prices = np.array([12, 20, 28])
bins = np.digitize(df.index.hour.values, bins=[7, 17, 24])
df['cost_cents'] = prices[bins] * df['energy_kwh'].values
与cut函数一样,这种语法非常简洁易读。
>>> apply_tariff_digitize(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_digitize` ran in average of 0.002 seconds.
0.002秒! 虽然仍有性能提升,但已经很边缘化了。
以上就是本次加速的技巧分享。
案例数据源:
链接:https://pan.baidu.com/s/1-pykKdgXRvPVaEajBFrb0g,提取码:uzyo


后台回复“入群”即可加入小z干货交流群


















 19
19

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









