



 本文介绍了垃圾收集算法的主要类型,包括引用计数和追踪式收集,重点阐述了追踪式中的分代收集理论,以及标记-清除、标记-复制、标记-整理三种具体算法。讨论了分代收集的优缺点,以及各算法在内存管理中的应用,如新生代和老年代的划分,以及为何需要两个Survivor空间以避免内存碎片。此外,还提及了StopTheWorld现象及其在不同收集器中的处理策略。
本文介绍了垃圾收集算法的主要类型,包括引用计数和追踪式收集,重点阐述了追踪式中的分代收集理论,以及标记-清除、标记-复制、标记-整理三种具体算法。讨论了分代收集的优缺点,以及各算法在内存管理中的应用,如新生代和老年代的划分,以及为何需要两个Survivor空间以避免内存碎片。此外,还提及了StopTheWorld现象及其在不同收集器中的处理策略。
从如何判定对象消亡的角度出发,垃圾收集算法可以划分为“引用计数式垃圾收集”(Reference Counting GC)和“追踪式垃圾收集”(Tracing GC)两大类。其均属于追踪式垃圾收集的范畴
目录
一、分代收集理论
建立在两个分 代假说之上:
1)e弱分碎片化代假说(Weak Generational Hypothesis):绝大多数对象都是朝生夕灭的。
2)强分代假说(Strong Generational Hypothesis):熬过越多次垃圾收集过程的对象就越难以消亡
把分代收集理论具体放到现在的商用Java虚拟机里,设计者一般至少会把Java堆划分为新生代 (Young Generation)和老年代(Old Generation)两个区域。
对象不 是孤立的,对象之间会存在跨代引用。
值得注意的是,分代收集理论也有其缺陷,最新出现(或在实验中)的几款垃圾收集器都展现出了 面向全区域收集设计的思想,或者可以支持全区域不分代的收集的工作模式。
二、标记-清除算法
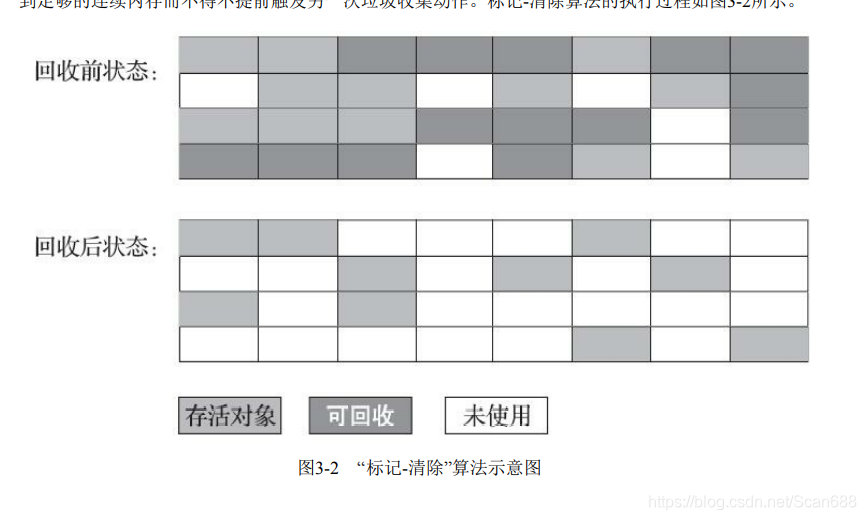
定义
首先标记出所有需要回 收的对象,在标记完成后,统一回收掉所有被标记的对象,也可以反过来,标记存活的对象,统一回 收所有未被标记的对象。
缺点
执行效率不稳定;内存空间的碎片化问题
三、标记-复制算法
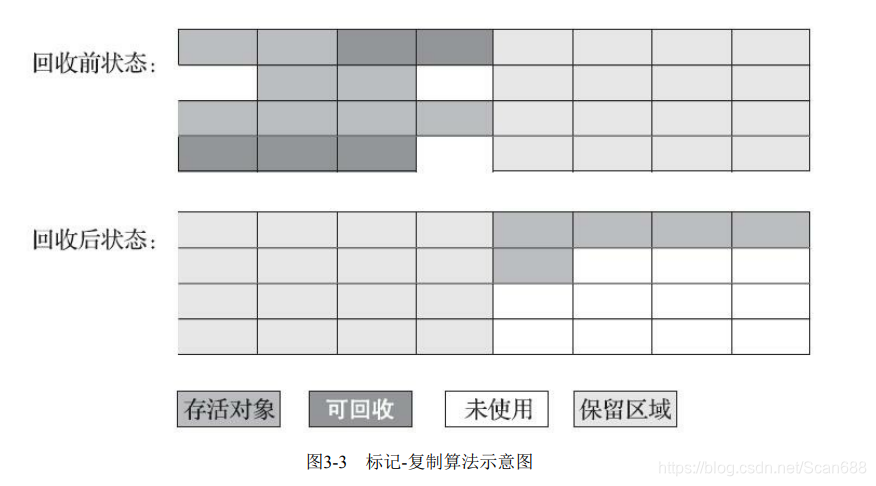
定义
将可用 内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着 的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
这种复制回收算法的代价是将可用内存缩小为了原来的一半,空间浪费未免太多了一 点。
现在的商用Java虚拟机大多都优先采用了这种收集算法去回收新生代
Appel式回收
Appel式回收的具体做法是把新生代分为一块较大的Eden空间和两块较小的 Survivor空间,每次分配内存只使用Eden和其中一块Survivor。发生垃圾搜集时,将Eden和Survivor中仍 然存活的对象一次性复制到另外一块Survivor空间上,然后直接清理掉Eden和已用过的那块Survivor空 间。HotSpot虚拟机默认Eden和Survivor的大小比例是8∶1,也即每次新生代中可用内存空间为整个新 生代容量的90%(Eden的80%加上一个Survivor的10%),只有一个Survivor空间,即10%的新生代是会 被“浪费”的。
为什么需要两个Survivor空间
防止内存碎片化
四、标记-整理算法
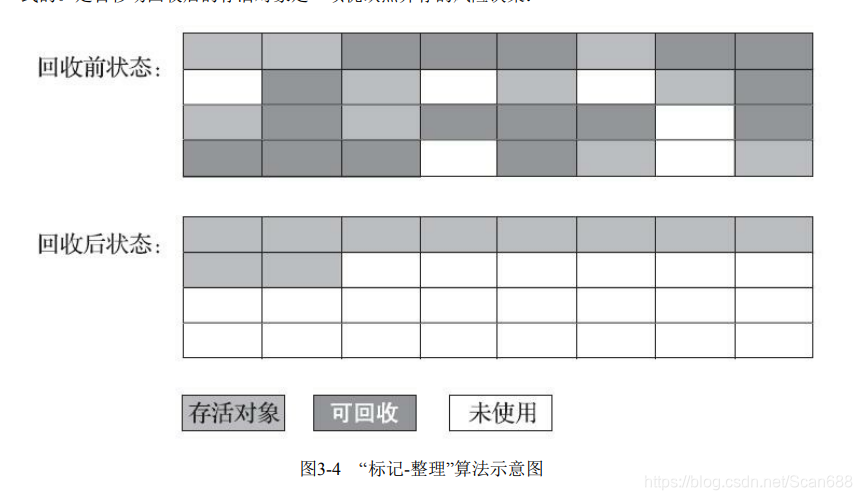
定义
标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可 回收对象进行清理,而是让所有存活的对象都向内存空间一端移动,然后直接清理掉边界以外的内存,
是否移动对象都存在弊端,移动则内存回收时会更复杂,不移动则内存分配时会 更复杂。
Stop The World
如果移动存活对象,尤其是在老年代这种每次回收都有大量对象存活区域,移动存活对象并更新 所有引用这些对象的地方将会是一种极为负重的操作,而且这种对象移动操作必须全程暂停用户应用 程序才能进行
HotSpot虚拟机里面关注吞吐量的Parallel Scavenge收集器是基于标记-整理算法的;
关注延迟的CMS收集器则是基于标记-清除算法的,这也从 侧面印证这点。
“和稀泥式”解决方案可以不在内存分配和访问上增加太大额外负担,做法是让虚 拟机平时多数时间都采用标记-清除算法,暂时容忍内存碎片的存在,直到内存空间的碎片化程度已经 大到影响对象分配时,再采用标记-整理算法收集一次,以获得规整的内存空间。前面提到的基于标 记-清除算法的CMS收集器面临空间碎片过多时采用的就是这种处理办法。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











