 符号化生成任务框架A-Language
符号化生成任务框架A-Language





论文链接:https://arxiv.org/abs/2504.17261
代码链接:https://github.com/Jiaqi-Chen-00/Any-2-Any
Abstract
我们提出了一种符号化生成任务描述语言(symbolic generative task description language)及其对应的推理引擎,能够将任意多模态任务表示为结构化的符号流(structured symbolic flows)。
不同于传统依赖大规模训练和隐式神经表示来学习跨模态映射的生成模型——这些方法往往计算成本高且灵活性有限——我们的框架引入了一种显式的符号表示,由三个核心原语组成:函数(functions)、参数(parameters)和拓扑逻辑(topological logic)。
该推理引擎利用一个预训练语言模型,可以在无需训练(training-free)的情况下,将自然语言指令直接映射为符号化工作流。
我们的框架成功执行了12种以上多样化的多模态生成任务,在无需针对特定任务微调的前提下展现出强大的性能与灵活性。实验结果表明,本方法在内容质量上不仅能够匹敌甚至超越现有最先进的统一生成模型(unified models),同时具备更高的效率(efficiency)、可编辑性(editability)和可中断性(interruptibility)。
我们相信,符号化任务表示为推动生成式人工智能的发展提供了一种**高性价比(cost-effective)且可扩展(extensible)**的基础。
Contribution
-
我们提出了一种统一的符号化表示——A-LANGUAGE,它能够系统地将任意生成任务分解为三个核心组成部分:用于原子操作的函数(function)、用于行为控制的参数(parameter),以及用于描述符号流结构的拓扑(topology)。
-
我们设计了一个无需训练(training-free)的推理引擎,该引擎利用预训练语言模型(pre-trained LMs),可将自然语言指令自动转换为可执行工作流的符号化表示。
-
实验验证表明,该框架在泛化性(generalizability)、**可修改性(modifiability)以及用户体验(user experience)**方面表现出色。
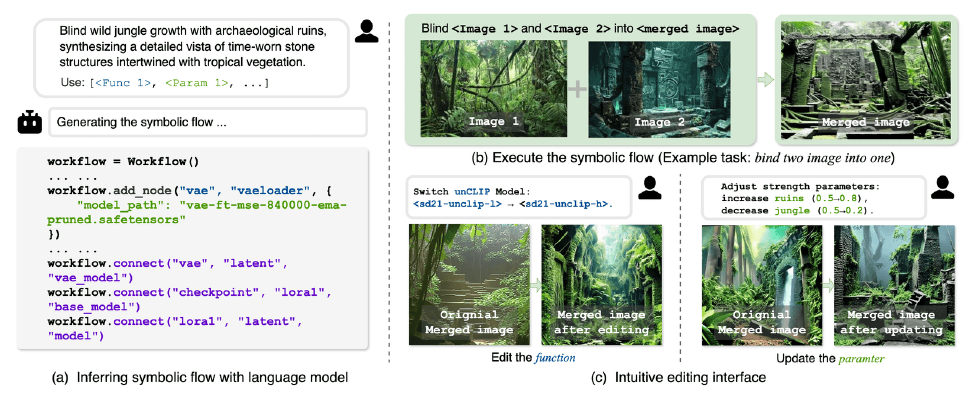
Figure 1. A symbolic representation for Any-to-Any generative tasks. (a)我们开发了一个无需训练的推理引擎,将自然语言任务描述转换为包含函数、参数和拓扑(functions, parameters, and the topology)的可执行符号流。(b)符号流允许作为程序执行生成任务。第1节的第一句话提到了示例任务。(c)函数和参数都可以很容易地修改,以自定义生成过程和输出样式。
Related work
Unified multi-modal framework
这一节回顾了近年来**多模态大语言模型(MLLMs)**的发展。
-
背景: 传统的大语言模型(LLMs)在自然语言理解和推理任务中已经展现出极强的能力。
-
扩展: 基于此,研究者将LLM的能力扩展到多模态领域,让模型能够同时处理和生成多种类型的数据,例如图像、音频、视频、3D结构等。
-
发展趋势: 研究从早期的单一模态模型发展到如今的**“any-to-any”统一框架**,即单一架构下能支持任意输入输出模态的组合。
-
主要问题:
-
多模态高质量数据匮乏 —— 特别是跨模态复杂任务,缺乏足够的多样化训练样本。
-
不同模态的处理机制差异大 —— 各模态在特征提取、编码方式、表示形式上存在显著差别,难以统一建模。
-
模态对齐问题(modality alignment) —— 如何在统一框架中保持模态间的一致性,同时保留各自特性,是目前的核心挑战。
-
总之,这一节指出了:虽然统一多模态模型取得了进展,但在跨模态一致性、性能均衡性和数据稀缺性上仍存在明显瓶颈。
Workflow synthesis
这一节介绍了另一条相关研究路线——任务工作流的自动合成。
定义: 工作流合成旨在为复杂任务生成一系列可执行的操作序列,自动协调不同的AI模型与资源,尤其适用于生成式AI任务(如图像生成、程序生成、推理等)。
传统方法的问题: 以往的做法通常依赖于神经模块(neural modules)或预定义操作集,因此难以应对现代AI任务中开放且多样化的指令。
-
新进展:
-
HuggingGPT:利用LLM进行任务规划与模型协同。
-
VISPROG:采用**神经-符号(neuro-symbolic)**方法,将任务拆解为程序化子步骤。
-
GenAgent:通过多智能体协作的方式逐步构建复杂任务的执行流程。
-
-
不足与启示: 虽然这些方法各有不同,但都凸显了灵活、可解释的任务表示形式的必要性。
作者的创新:
本文进一步推动了该领域的发展,提出了一个统一的符号化框架,能够以可执行且具可解释性的方式描述和执行生成任务,实现**表达能力(expressiveness)与实用性(practicality)**的平衡。
A-Language
本文的 A-LANGUAGE 则结合两者优势,通过符号化方法实现对任意生成任务的统一表示与执行。
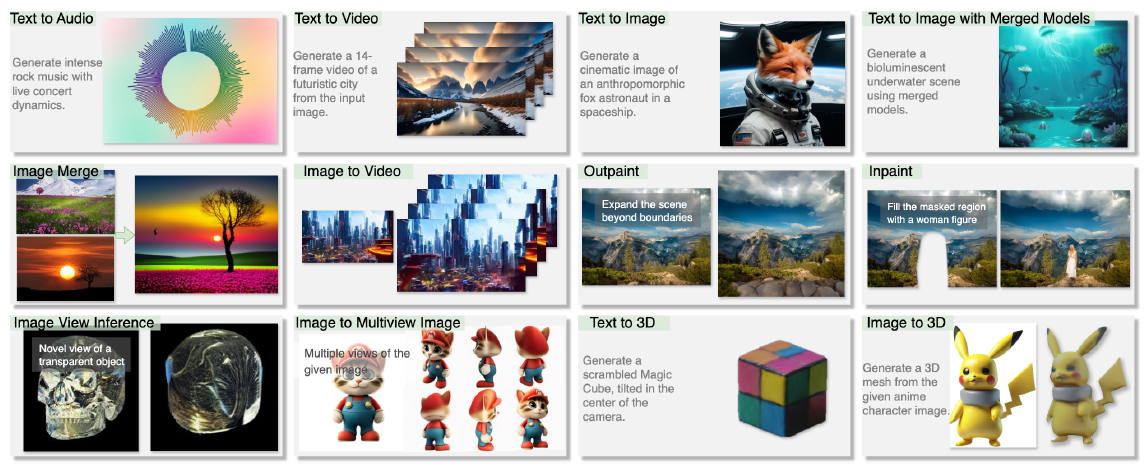
我们的模型展示了处理各种模态之间任意到任意生成任务的能力,包括文本、图像、视频、音频和 3D 内容。从形式上讲,任意到任意的生成任务指的是从任何模态的输入生成任何期望模态的输出,所有这些都由自然语言指令引导[42]。
Method
Formulation
A-LANGUAGE formalizes any generative task t as a triple:
![]()
This unified formulation decomposes any generative task into its essential constituents: the computational functions F, their corresponding parameters Φ, and the topological structure T that elucidates 阐明 their interrelations and data flow dynamics.
Functions, 𝓕
定义有哪些基础运算或模块(比如“图像融合”、“文本生成”、“特征提取”等原子操作)
defined as F = {f1, f2, ..., fn}, where n ∈ N, which represents atomic computational units.
Each function fi takes both input data and parameters to produce outputs, formally defined as:
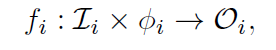
-
输入空间 Ii:函数需要什么类型的输入;
-
参数配置 ϕi:控制函数行为的参数;
-
输出空间 Oi:函数输出结果。
假设 fi 是“图像融合”函数,它的输入空间可能是两张图片,参数空间包含 blending ratio(混合比例),输出空间是生成的新图像和注意力掩码(attention mask)。
Parameters, Φ
定义这些函数的配置方式或超参数(比如 blending ratio, temperature, filter strength 等)
每个函数 fi 都有自己的一组参数(parameter space) ϕfi ,这些参数决定它的行为。
![]()
参数的作用:同一个函数在不同参数下可能表现完全不同。例如“图像滤波”函数,用不同的 kernel size 或 intensity 值会生成不同效果。
参数与输入解耦:参数空间与输入空间独立,因此即使输入相同,参数不同也能让函数产生不同的行为。这让模型具备灵活性(如同一个任务可以多样化执行)。
Topology, 𝓣
定义这些函数之间是如何连接、数据如何流动的(比如输出1传给函数2的输入)
![]()
每个 dk 表示一个数据流连接,也就是函数间的有向边(directed edge)。
形式化定义为:
![]()

例如:
-
f1 是“文本生成”,输出文本 →
-
f2是“图像生成”,输入 prompt →
则拓扑连接可以写作:
d1=(f1,ytext)→(f2,xprompt)
每个 dk 代表一次数据传输,这样整个系统的执行路径就可以完全追踪,像一个数据流图(Data Flow Graph, DFG)。
总之,A-LANGUAGE 就像是在构建一个符号化的“生成任务电路,不需要训练,仅凭符号规则和语言模型的推理,就能自动将自然语言任务映射成一个可执行的流程结构
Symbolic flow
A-LANGUAGE 的符号流(symbolic flow)定义为:
![]()
其中
| ( f_i ) | 函数 | 一个具体的计算单元(例如图像融合、文本生成) |
| (ϕfi) | 参数配置 | 控制该函数行为的具体参数(例如温度、混合比例、风格强度等) |
| ( D_i ) | 数据流集合 | 描述该函数的输入来自哪里,即哪些上游函数的输出被传入这个函数 |
![]()
表示所有连接到函数 fi 的有向边集合,也就是它的输入依赖。
可以理解为这个是可执行的符号化计算图(Symbolic Computation Graph)
系统就能从自然语言指令中自动推理出一个任务的“执行图”
e.g

Syntax styles
这一节讲的是:
A-LANGUAGE 如何用**不同的语法风格(syntax styles)**来表达同样的符号化任务结构 Ω(t)。
它实际上探讨了三种“领域特定语言(DSL)”风格,主要区别在于——表达方式的形式性、可读性、以及与自然语言的接近程度。
Declarative Syntax(声明式语法)
核心特征:结构清晰、形式化强、机器友好。
-
这种语法把任务的**组成部分(functions)和关系(topology)**明确分开。
-
先“声明”所有节点(函数及其参数),再“声明”它们之间的连接。
-
非常类似于传统编程语言里的模块定义,比如 PyTorch 的
add_module()+forward()的分离结构。

第一行定义了一个名为“vae”的节点(函数),指定参数 model_path。
第二行再明确连接它的输出 “latent” 到另一个节点 “vae_modeli”。
✅ 优点:
-
结构化强、适合复杂任务;
-
便于系统解析和执行。
⚠️ 缺点:
-
表达较啰嗦、不自然;
-
对人类阅读不够直观。
Dataflow syntax(数据流语法)
核心特征:强调执行顺序和数据流动。
-
强调函数之间的组合关系(compositionality);
-
用“函数嵌套调用”的方式直接表达拓扑结构;
-
非常像函数式编程(functional programming)或 pipeline 模型。

✅ 优点:
-
表达自然;
-
特别适合线性、顺序型工作流;
-
更接近人类推理的“先做 A → 再做 B”逻辑。
⚠️ 缺点:
-
对复杂分支(并行、多输入多输出)任务不够直观;
-
拓扑结构隐式存在于函数顺序中,不易全局追踪。
Pseudo-natural syntax(数据流语法)
核心特征:最接近自然语言、人类可读性最高。
-
这种语法模仿自然语言描述方式;
-
使符号任务看起来像普通语言指令,但仍保持形式化和严谨;
-
相当于在“自然语言”和“程序语言”之间的中间层。

✅ 优点:
-
可读性最强;
-
适合自然语言推理(LLM 在此结构下能更好解析任务);
-
更容易让模型从人类指令中自动生成对应符号表示。
⚠️ 缺点:
-
可解析性(parseability)略低;
-
对机器而言不如前两种直接、严格。
我确实挺好奇这块到底哪种表达形式效果最好
Inferring via pre-trained language model
解释了 A-LANGUAGE 是如何让一个预训练语言模型(LLM)充当“推理引擎”,把自然语言任务描述一步步转化为可执行的符号化任务流(symbolic flow)

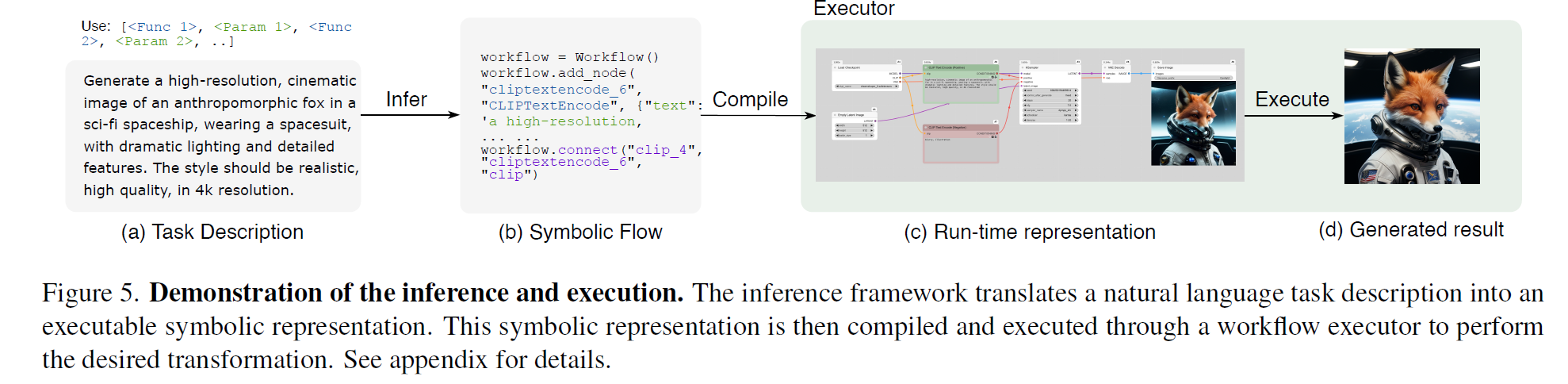
通过让 预训练语言模型(LLM) 充当“符号推理引擎(inference engine)”,系统可以:
-
理解用户任务指令(任务描述 + 输入 + 约束);
-
推理出需要的函数(功能模块);
-
明确它们的连接与参数;
-
自动生成完整的符号流结构。
形式化地,他们把整个过程定义为:
![]()
| X | 输入,可以是任意模态(图像、文本、音频、视频等) |
| s | 任务描述(自然语言,例如“把这张图片转换成草图并加标题”) |
| C | 约束条件(constraints),定义允许使用的函数、参数范围、模型兼容性等 |
| Ω(t) | 最终生成的符号任务表示(即完整可执行工作流) |
Component inference 组件推理
![]()
根据输入、任务描述和约束,推理出需要哪些函数 F 以及它们的参数配置 Φ。
-
LLM 读取自然语言指令;
-
判断需要哪些功能模块;
-
决定这些模块的参数或模式
e.g
任务:“给图像加风格滤镜并生成说明文字。”
→ 推理结果:

这一阶段对应“任务拆解”与“函数选择”。
Topology construction 拓扑构建
![]()
建立各个函数间的连接关系(数据流拓扑)
-
确定哪个函数的输出作为下一个函数的输入;
-
保证连接符合约束 C(例如数据类型一致、模型兼容性等)。
这样系统就知道执行顺序
Iterative refinement 迭代优化
![]()
不断检测并修复符号流中的错误或不一致,使其变为“正确且可执行”的版本。
📘 机制说明:
-
R:修正算子(refinement operator),负责调整;
-
ϵi :本次迭代中发现的问题(比如参数错误、数据不匹配、缺失节点等);
-
模型会根据错误信号自动修改函数、参数或连接;
-
迭代直到满足所有约束 C,或达到最大迭代次数。
e.g
第一次生成的符号流中,caption_generator 的输入缺失;
→ 模型检测出问题;
→ 自动补上 “styled_image”;
→ 完整任务就修复完成。
自然语言指令 (s)
↓
LLM 解析 + 约束 C
↓
[组件推理 ψ1] → 得到 (F, Φ)
↓
[拓扑构建 ψ2] → 得到 T
↓
[迭代优化 R] → 得到最终 Ω(t)
Experiment
这篇文章我也是主要看方法的,实验部分感兴趣自己去看哈
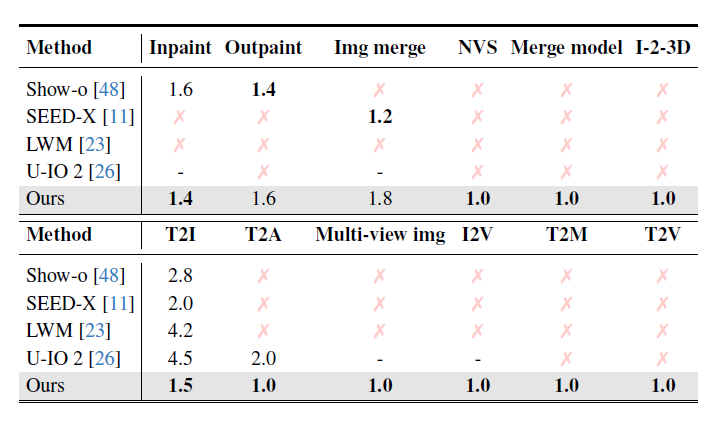

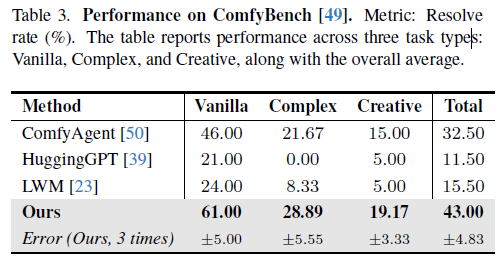
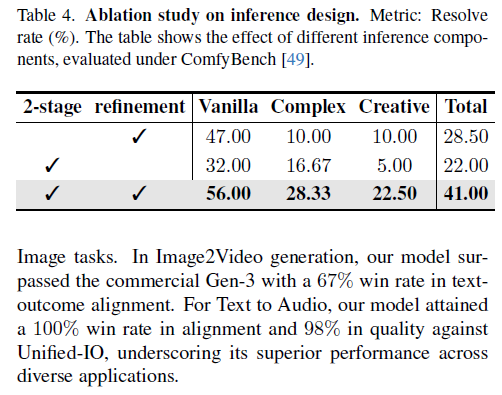

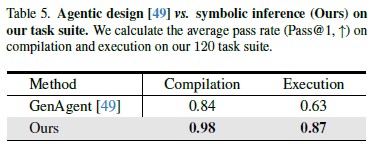

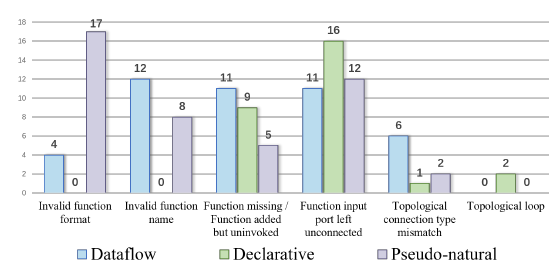
Conclusion
我们提出了一种符号化生成任务描述语言,并结合了一个推理引擎(inference engine),提供了一种全新且高效的方式,用于表示和执行多模态任务,且无需针对特定任务进行训练。
通过利用预训练的大语言模型(LLM)来推理符号化任务描述,我们的方法成功地合成了多种多样的多模态生成任务,充分展示了其灵活性以及在统一不同类型生成式 AI 能力方面的潜力。

















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









