




 本文深入探讨了Unicode编码标准,特别是在Java中如何处理基本多语言平面与增补字符。详细介绍了char类型的设计原理,及其在表示增补字符时的限制与解决方案,通过实例演示了如何使用Character类的方法。
本文深入探讨了Unicode编码标准,特别是在Java中如何处理基本多语言平面与增补字符。详细介绍了char类型的设计原理,及其在表示增补字符时的限制与解决方案,通过实例演示了如何使用Character类的方法。
概述
本文主要关注字符编码,详细介绍了Unicode相关的基本多语言平面与增补字符编码,在此基础上介绍了java基本数据类型char,阐述了在java平台中如何表示增补字符,最后,对char的包装类Character的相关方法做了简要的说明与示例演示。
Unicode码表
在介绍char类型之前我们先介绍一下Unicode.以下是百度百科给出的解释:
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
每个字符对应一个二进制编码,全世界的字符与其对应的编码共同构成了字符码表,只要知道字符编码便可以通过该码表找到对应的字符,通常我们看到的U+FF00这样的数值就是将字符的二进制码进行16进制转换后的值。由于该码表一开始的字符数目是少于2个字节的存储空间的,所以运用2个字节去编码每个字符是够用的,但随着情况的改变比如一些古老文字的发现,新的字被造出来等因素,运用两个字节来编码字符显然是不够用了。
那怎么办呢?Unicode标准为了能够适应更多的字符编码需求,其编码范围已经从两个字节U+0000到U+FFFF扩展到节U+0000到10FFFF。
引入一个概念,我们把能够用2个字节编码的字符,也即是从U+0000到U+FFFF的字符集称为基本多语言平面(BMP),超出这个范围的称为增补字符。
好,重点来了,我们平常写代码的时候涉及字符编码的时候好像并没有使用到Unicode呀?但是你一定使用过“UTF-8”!可能还会有UTF-16,UTF-32。这些又是什么呢?
这些其实就是Unicode的使用方式,UTF(UnicodeTransferFormat)就是把Unicode转作某种格式的问题。为什么需要这么多的代码规范?直接存储代码点不就行了吗?当然不行,我们在使用字符的时候通常并不是单个字符单个字符来使用,大多数情况下都是成串成串的使用(字符串),而这些字符一旦被存储下来,在存储的时候可能是一连串的FF00这样的值,那么在解析的时候可能就不知道怎样去划定哪些表示一个字符哪些表示另一个字符,举个例子,比如”汉字”两个字的Unicode代码点是“0x6c49和0x5b57”也就是”6c495b57”。而且,Unicode的代码点还有3个字节的,比如”10FF3B”,对于一个很长16进制串,比如“10FF3B6c495b57”,我们该怎样去解析呢?
这里就需要某种编码方案来区分哪几个数值是一个Unicode代码点,这种方案就是UTF-8、UTF-16、UTF-32这样的编码方案。
以UTF-8为例:

UTF-8的特点是对不同范围的字符使用不同长度的编码。对于0x000000-0x00007F之间的字符,UTF-8编码与ASCII编码完全相同,也就是用一个字节表示的字符与ASCII编码完全相同。对于在0x000080-0x0007FF之间Unicode表示的字符,UTF-8用三个字节对其Unicode码再进行编码;而对于在0x010000-0x10FFFF之间Unicode表示的字符,UTF-8用4个字节对其编码。从上表可以看出,4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。举个例子:
“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001,
将这个二进制数据依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
由此可见,UTF-8主要就是对unicode代码点根据自己的规则进行了再编码。
char基本字符类型
回到java的基本数据类型char,一开始设计的时候就是针对Unicode的基本多语言平面设计的,只使用了16位来表示,这种构造缺陷,决定了其在表示增补字符时的不足,前面我们讲过Unicode扩展了基本多语言平面使其适应增补字符的表示需求,但是我们的基本数据类型char不可能改变其设计,那么如果我们要在java语言中表示一个增补字符要怎么做?
这里插入一个简单的概念:代码点。代码点是指可用于编码字符集的数字(相当于Unicode码表的键值)。编码字符集定义一个有效的代码点范围,但是并不一定将字符分配给所有这些代码点。有效的 Unicode 代码点范围是 U+0000 至 U+10FFFF。Unicode 4.0 将字符分配给一百多万个代码点中的 96,382 代码点。
引入代码点的概念解释一下UTF-16这种Unicode代码点表示方式,UTF-16使用一个或两个无符号16位代码单元的序列来编码Unicode代码点。 值U+0000至U+FFFF以一个16位单位编码,具有相同的值。 补充字符以两个代码单元编码,第一个来自高代理范围(U+D800到U+DBFF),第二个来自低代理范围(U+DC00到U+DFFF)。 这在概念上似乎与多字节编码类似,但有一个重要的区别:值U+D800到U+DFFF保留用于表示补充字符的编码; 没有把单个代码单元表示的字符分配给这些代码点。 因此,可以通过对代码点是否处于这个范围内,可以得到该代码点是表示一个字符还是只是一个增补字符中两个代码单元中的一个。这是对一些传统的多字节字符编码的重大改进,其中字节值0x41可以表示字母“A”或者是双字节字符的第二个字节。
言归正传,到底怎么在java平台中表示增补字符呢?专家组确定了一种分层的方法:
- 使用基本类型 int 在低层 API 中表示代码点,例如 Character 类的静态方法。
- 将所有形式的 char 序列(char[],String,StringBuilder)均解释为 UTF-16 序列,并促进其在更高层级 API 中的使用。
- 提供 API,以方便在各种 char 和基于代码点的表示法之间的转换。
在需要时,此方法既能够提供一种概念简明且高效的单个字符表示法,又能够充分利用改进了可支持增补字符的现有 API。同时,还能够促进字符序列在单个字符上的应用,这一点一般对于国际化的软件很有好处。
在这种方法中,char表示UTF-16代码单元,它并不总是足以表示代码点。 您将看到J2SE规范中,与文中讨论相关的地方现在都使用术语代码点和UTF-16代码单元,在与本文讨论不相关的地方使用通用术语:character API 通常使用名称 codePoint 描述表示代码点的 int 类型变量,而 UTF-16 代码单元的类型当然为 char 。
char包装类Character的部分方法截图:
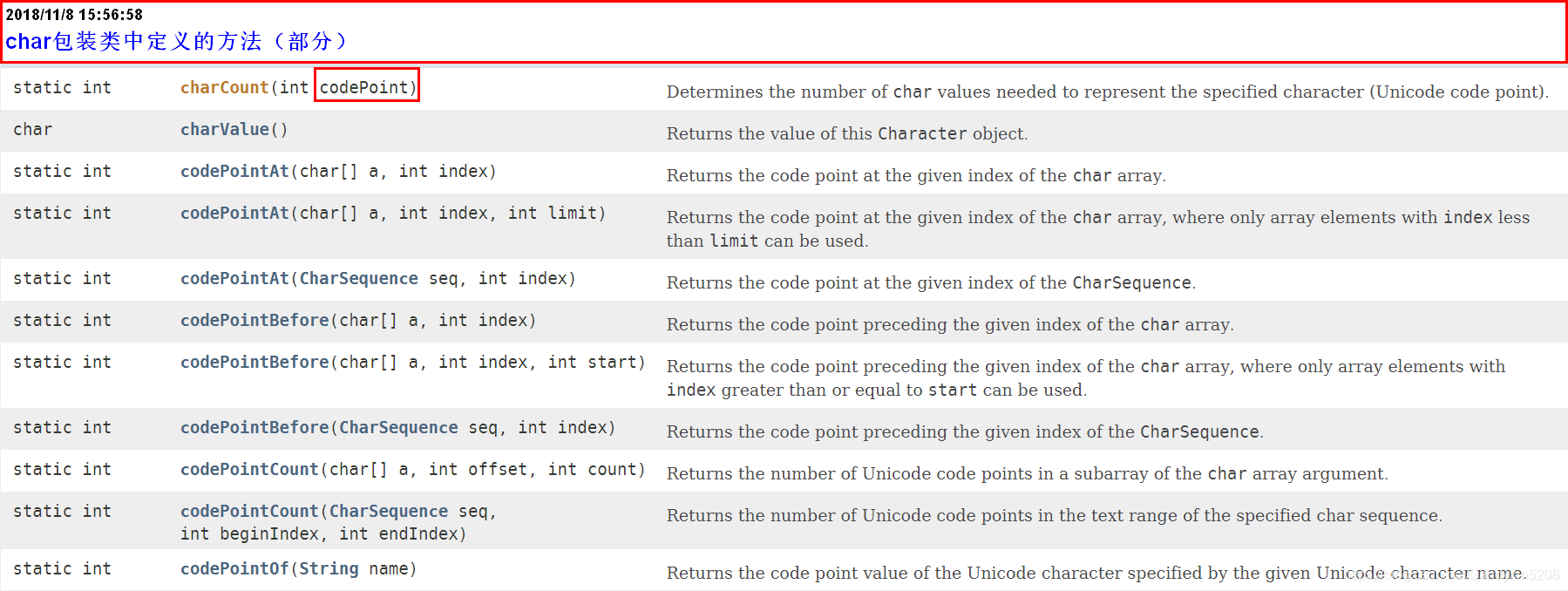
以下是一些方法测试:
//1D306是一个增补字符
int t=Integer.parseInt("1D306",16);
System.out.print("一个增补字符1D306用int类型变量来表示:");
System.out.println(t);
System.out.print("判断这个增补字符用几个char表示:");
System.out.println(Character.charCount(t));
//System.out.print("用字符串数组表示这个增补字符:");
char[] c = Character.toChars(t);
//判断字符是否用代理对表示:
System.out.print("判断字符是否用代理对表示Character.isSurrogate(c[0]):");
System.out.println(Character.isSurrogate(c[0]));
//System.out.println(c.toString());
System.out.println("输出增补字符各代码单元的值:");
//输出119558,这个是1D306对应的10进制值;给定的指引处的char值如果在高代理范围,則返回整个代码对
System.out.println(Character.codePointAt(c, 0));
//输出119558,如果给定的指引处的char值如果在低代理范围,則返回对应char的十进制值
System.out.println(Character.codePointAt(c, 1));//输出57094,这个是c[1]对应字符的10进制值
//定义两个增补字符
int[] codePoints = {0x100001,0x100002};
String s = new String(codePoints,0,2);
System.out.println("s: " + s);
//4,说明length()是按代码单元计算的
System.out.println("s.length: " + s.length());
//以下两行的输出结果表明增补字符并非简单地把两个代码单元拆开
System.out.println("s.charAt(0): " + Integer.toHexString((int)s.charAt(0)));
System.out.println("s.codePointAt(0):" + Integer.toHexString(s.codePointAt(0)));
输出结果:
一个增补字符1D306用int类型变量来表示:119558
判断这个增补字符用几个char表示:2
判断字符是否用代理对表示Character.isSurrogate(c[0]):true
输出增补字符各代码单元的值:
119558
57094
s: ??
s.length: 4
s.charAt(0): dbc0
s.codePointAt(0):100001
通过以上的演示想说明一个问题:在我们使用增补字符时,更多的是先找到对应的Unicode代码点或者是增补字符的UTF-16格式的代码点,由这些代码点得到对应的无符号的int值或者是转化为String字符串或者是char[]类型数组,再使用相关的API来进行代码编写。
最后最后最后再补充一点:实际代码中很少用到增补字符,但是由于一些常用API中涉及到对单个字符返回字符个数以及代码点等这些内容,所以才花这个时间整理了一下(被小伙伴说有病囧~)。
参考资料
以下其实是同一篇文档的中英文版本,详细的可以参考这里:

















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









