 离散数据图表解析:直方图与条形图的选择与技巧
离散数据图表解析:直方图与条形图的选择与技巧





 本文探讨了为离散数据选择图表的最佳实践,重点比较了直方图和条形图的适用场景。直方图在设置分组边界时需要注意避免歧义,而条形图通过空隙强调离散性,但可能引发误解。文章还提到了核密度估计(KDE)作为另一种可视化选择,适用于数据点较少的情况。在创建图表时,应关注描述统计量、异常值以及坐标轴范围的设定,以准确传达数据信息。
本文探讨了为离散数据选择图表的最佳实践,重点比较了直方图和条形图的适用场景。直方图在设置分组边界时需要注意避免歧义,而条形图通过空隙强调离散性,但可能引发误解。文章还提到了核密度估计(KDE)作为另一种可视化选择,适用于数据点较少的情况。在创建图表时,应关注描述统计量、异常值以及坐标轴范围的设定,以准确传达数据信息。
为离散数据选择图表
如果想要绘制离散型数值变量,直方图或条形图都是可能的选择 。
直方图可能是最直接的选择,因为数据是数值型的,但是需要特别考虑一下分组边界的问题。因为离散型数值都是特定的值,而你的读者可能并不了解分组边界的值属于右边的分组,所以将分组边界设置为实际的两个值之间可以减少歧义。请比较下面两个图表,图表的数据是 100 次随机掷骰结果(die_rolls),左图是分组边界值等于数据实际值的情况,右边是分组边界在数据实际值之间的情况。
plt.figure(figsize = [10, 5])
# histogram on the left, bin edges on integers
plt.subplot(1, 2, 1)
bin_edges = np.arange(2, 12+1.1, 1) # note `+1.1`, see below
plt.hist(die_rolls, bins = bin_edges)
plt.xticks(np.arange(2, 12+1, 1))
# histogram on the right, bin edges between integers
plt.subplot(1, 2, 2)
bin_edges = np.arange(1.5, 12.5+1, 1)
plt.hist(die_rolls, bins = bin_edges)
plt.xticks(np.arange(2, 12+1, 1))
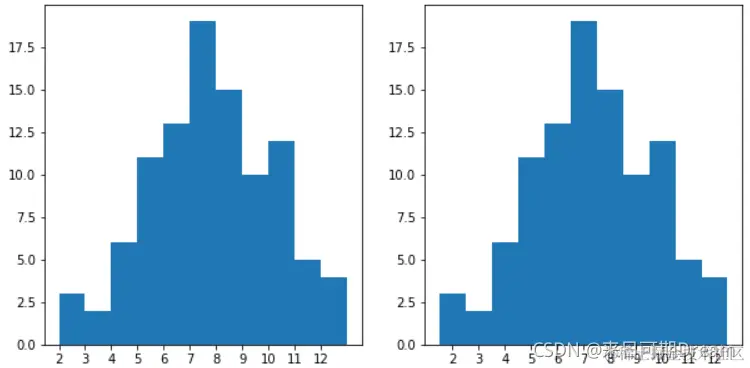 你会注意到左侧的直方图在设置分组边界时,我在最大值(12)的基础上加了 1.1,而不是 1。回想一下前面讲的内容,最右侧的边界会落在最后一个分组内,如果数据中包含很多个最大值,它们都会落在左边属于数据值 11 的分组内,这个潜在问题对于离散型数值尤其需要注意。为最大值加上 1.1,可以让 12 这个值单独存放在最后一个分组内,避免 11 和 12 在同一个分组。
你会注意到左侧的直方图在设置分组边界时,我在最大值(12)的基础上加了 1.1,而不是 1。回想一下前面讲的内容,最右侧的边界会落在最后一个分组内,如果数据中包含很多个最大值,它们都会落在左边属于数据值 11 的分组内,这个潜在问题对于离散型数值尤其需要注意。为最大值加上 1.1,可以让 12 这个值单独存放在最后一个分组内,避免 11 和 12 在同一个分组。
考虑一下长条不相连的条形图是否可以成为替代直方图的更好方案。 以下的图表采用了之前的代码,只是添加了 “rwidth” 参数,用来设置每个直方图长条占各自宽度的比例。将 “rwidth” 参数设置为 0.7,长条只会占据原本分组条形空间的 70%,左侧留出 30% 的空白。
bin_edges = np.arange(1.5, 12.5+1, 1)
plt.hist(die_rolls, bins = bin_edges, rwidth = 0.7)
plt.xticks(np.arange(2, 12+1, 1))
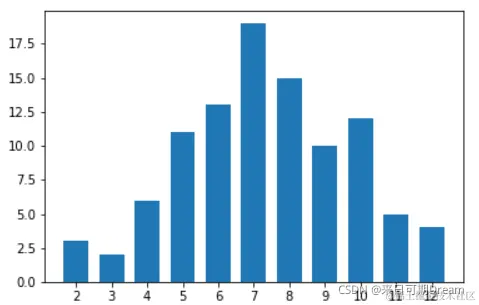 通过在长条之间增加空隙,强调数据的值是离散的。但另一方面,以这种方式绘制数值型数据可能会被理解为数据是有序分类数据,这样会对整体的理解带来影响。
通过在长条之间增加空隙,强调数据的值是离散的。但另一方面,以这种方式绘制数值型数据可能会被理解为数据是有序分类数据,这样会对整体的理解带来影响。
==对于连续型数据,最好不要使用 “rwidth” 参数,因为长条的空隙暗示数值是离散的。==另外注意,你可能会尝试使用 seaborn 的 countplot 函数将离散数值变量的分布情况绘制成条形图。这样操作时要小心,因为无论两个值之间的间距多大,每个唯一数 值都对应一个长条(比如,如果唯一值为 {1,2,4,5},缺少了 3,那么 countplot 只会绘制 4 个条形,其中 2 和 4 相邻)。此外,即使数据是离散数字,也尽量不要考虑此页面上描述的直方图变体版本,除非唯一值的数量很小,允许半个单位的位移使离散长条可解释。如果有大量唯一值并且分布在很大的范围内,则最好采用标准直方图,避免出现解释性问题的风险。
虽然你可以使用条形图绘制离散数据,但你很难充分地解释以下情况
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1459
1459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









