






回答问题的思路
不要问什么答什么 要学会扩充
比如问你go map的原理
- map 是什么
数据结构,字典,k/v 结构 - map的应用场景有哪些
快速查找、计数器、配置管理、去重、缓存实现 - map有哪些限制
无序性、非线程安全的读写 - map的key的访问
v:= mp[key]
v,ok := mp[key]
for k,v:=range mp {} - map相关原理
比如问你内存逃逸
面试应该从以下角度回答
- 什么是逃逸?
- 导致内存逃逸的原因是什么
- 常见的发生逃逸的情况与逃逸分析
- 如何避免
如何面试遇到不会回答的 想办法转移 乾坤大挪移
比如问你go应用启动发生什么 想办法扯到gmp模型去
语言层面通用
调用一个函数,说出调用函数的具体过程
gc中的根对象是什么?
在Go语言的垃圾回收(GC)中,根对象是指那些可以直接访问到的对象,它们是GC标记过程的起点。
根对象包括全局变量、栈上的变量(因为栈上的变量可以被当前执行的函数访问)、寄存器中的对象等。从这些根对象开始,垃圾回收器会通过指针遍历所有可达的对象,标记为存活状态,而不可达的对象则会在清除阶段被回收。
go
杂项
slice和数组的区别?底层结构
grpc协程溢出与grpc连接池实现
Printf() , Sprintf(), Fprintf()都是格式化输出,有什么不同?
深拷贝与浅拷贝
方法的receiver到底是 T类型*T类型
开辟多个写协程向一个channel中写数据 是有序吗
gin框架常用中间件分享
map,slice 未初始化,操作会怎么样。发生 panic 应该怎么办
map 有序无序,为什么? 无序
map并发读安全么
String和byte切片的区别
生产者、消费者用有缓存channel通信场景,如何让生产者和消费者退出
map可以寻址么
for range 中赋值的变量,这个变量指向的是真实的地址吗,还是临时变量>如果在for range里面有一个函数,这个函数需要传一个指针,这时候应该怎么写?
回答: 临时变量 v:=v 如果是go1.22后的版本 则无需
// 实现10个协程并发执行,打印出数字:0-9//
go实现一个消息处理协程池//
go实现一个简单的cache
select两个channel性能稳定,三个channel时性能会发生抖动,为什么?
golang 常见gcflags有哪些,如何查找更多的flags?
make 一个切片的时候三个参数分别是什么意思,会出现容量比长度小的情况吗
golang协程调度、什么时候一定会发生线程上下文切换(系统调用 还有呢?)——GMP模型中几种阻塞情况下 切换阻塞的G,从队列在调一个G到工作线程M。
go语言的函数可以设置多个参数是什么原理
协程怎么关闭?自然关闭、通过Context上下文关闭、通过通道关闭
make 一个切片的时候三个参数分别是什么意思,会出现容量比长度小的情况吗
sync.map数据结构以及Read与dirty的转化关系
go协程可能会引发哪些问题?
tag的作用
结构体tag用于序列化、数据库操作、数据绑定和验证。
只会在反射中读取到。有些库会用反射来读取特定内容以支持对字段的配置操作,尤其是各种序列化反序列化,数据库解析类,校验类型。
好处是可以减少代码量,坏处是tag没有语法标记,以及依赖反射
将结构体转换为 JSON 字符串其实就是序列化
内存泄露的场景
循环引用:
在 Go 中,即使启用了垃圾回收,循环引用也会导致内存无法被释放。例如,两个对象互相引用对方,而没有外部引用这两个对象,这将导致内存泄漏。
示例代码:
type A struct {
b *B
}
type B struct {
a *A
}
func main() {
a := &A{b: &B{a: &A{b: nil}}}
b := &B{a: &A{b: a}}
// 由于 a 和 b 互相引用,而没有外部引用它们,这将导致内存泄漏。
}
未关闭的文件或网络连接:
打开的文件或网络连接如果没有被正确关闭,它们占用的资源将不会被释放。这可以通过在适当的时候调用 Close() 方法来解决。
示例代码:
file, err := os.Open(“example.txt”)
if err != nil {
log.Fatal(err)
}
// 忘记关闭文件
定时器或通道泄漏:
如果你创建了定时器(time.Ticker 或 time.Timer)但没有停止它们,它们会持续占用内存。同样,如果你创建了通道但没有关闭它们,也会导致内存泄漏。
示例代码:
timer := time.NewTimer(time.Hour)
// 忘记停止或重置 timer
大量临时对象未被回收:
在某些情况下,如果程序中创建了大量的临时对象,但没有外部引用指向这些对象,垃圾回收器可能无法及时回收这些对象。虽然这不是严格意义上的“泄漏”,但如果频繁发生,也可能导致内存使用量异常增加。
示例代码:
for i := 0; i < 1000000; i++ {
_ = make([]byte, 1024) // 大量小对象的分配可能导致内存使用量增加。
}
全局变量持续增长:
如果程序中存在全局变量或静态变量不断增加而没有相应的清理机制,随着时间的推移,这些变量的内存占用会持续增长。
示例代码:
var data []byte
for i := 0; i < 1000; i++ {
data = append(data, make([]byte, 1024)…) // 不断增长的数据结构可能导致内存泄漏。
}
go的并发编程如何避免死锁
首先是死锁定义 避免条件 然后go中注意哪些
用redis缓存和本地缓存,可以用本地缓存么
(答了可以,但不建议,然后面试官反问维护redis的成本呢)
redis缓存适用于那些比较关键、而且不同的机器要去统一读取的场景 比如session
但是对于一些不这么重要的 也无需统一分布式的 可以用本地缓存
比如 配置文件再redis统一存一份 然后就很少改了 这时候单机的配置文件就可以用本地缓存存一下 如果修改了再做对应处理
goroutine怎么做同步控制
面向对象
defer panic recover
总结和常见注意点
来自教程defer详解那 如果有更改 请同步过去
- defer执行顺序 后进先出 栈
- return是先计算值 然后defer 然后再真正return 但是也分引用的情况 比如命名返回值
- defer也是 申明的时候就先计算好值了,如果要使用最终值 请使用“最终的值”,可以传入 指针 或 闭包。
- defer关闭chan要谨慎
- defer会再return和panic之前执行 但是exit会退出
- defer需要在panic或者return之前申明 不然会失效
- 利用上面这个特性 defer可以捕获错误panic ,看到panic了 先将panic和参数压到栈中 然后再执行defer 等到defer执行完了 再真正panic 所以defer中panic能被recover捕获
- recover必须再defer的匿名函数中使用
- 外层的协程一般不能捕获子协程的panic,一般只能捕获当前协程的panic
- 通过处理 可以将panic转化为error 避免程序退出
- 特别小心map和slice 并发写会panic 且不能被捕获
- 为了避免不必要的麻烦,defer 函数中最好不要有能够引起 panic 的代码。
- defer的应用场景
- 资源释放
- 异常捕获,避免程序崩溃。
- 互斥锁解锁
- 计算执行时间(简单性能分析)
如果在匿名函数内panic了,在匿名函数外的defer是否会触发panic-recover?反之在匿名函数外触发panic,是否会触发匿名函数内的panic-recover?
这是面试真题
在 Go 语言中,panic 的捕获作用域由 defer 函数的注册位置决定,与是否为匿名函数无关。以下是具体分析:
一、匿名函数内触发 panic,外部的 defer recover 能否捕获?
可以捕获,但需满足以下条件:
匿名函数与外部 defer 处于同一 goroutine 且同步执行;
外部的 defer recover 注册在匿名函数调用之前。
示例代码:
func main() {
defer func() { // 外部的 defer
if err := recover(); err != nil {
fmt.Println("捕获到 panic:", err) // 输出:捕获到 panic: 内部 panic
}
}()
func() { // 匿名函数
panic("内部 panic")
}()
}
逻辑分析:
panic 会从匿名函数向外层函数(main)传播,最终被外层 defer 中的 recover 捕获13。
若匿名函数在独立 goroutine 中触发 panic(如 go func(){…}),则外部的 defer 无法捕获,程序会崩溃4。
二、匿名函数外触发 panic,匿名函数内的 defer recover 能否捕获?
无法捕获,除非满足以下条件:
匿名函数内的 defer recover 注册在外部 panic 触发之前;
匿名函数未执行完毕,且外部 panic 触发时仍在同一 goroutine 中。
示例代码:
func main() {
func() { // 匿名函数
defer func() {
if err := recover(); err != nil {
fmt.Println("匿名函数捕获 panic:", err) // 无输出
}
}()
}()
panic("外部 panic") // 程序崩溃
}
逻辑分析:
匿名函数执行完毕后,其 defer 已出栈,无法捕获外部 panic58。
若外部 panic 触发时,匿名函数仍在执行中(如通过嵌套调用),则其 defer 可能捕获 panic(但需符合作用域规则)。
go哪些内置类型是并发安全的
原子类型(如sync/atomic包中的类型)是并发安全的,例如atomic.Value可以在多个协程中安全地存储和读取任意类型的值。
sync.Mutex和sync.RWMutex本身也是并发安全的,用于实现互斥和读写锁的功能。
sync.Once用于保证某个操作只执行一次,是并发安全的。
sync.WaitGroup用于协程的同步,在多个协程中正确使用时是并发安全的,它可以用来等待一组协程完成。
sync.Cond用于条件变量,是并发安全的,可用于协程之间的同步等待某个条件满足。
sync.Map是一个并发安全的map类型。
两个结构体可以等值比较吗
如果结构体的所有字段都是可以比较的(如基本类型、指针类型等),那么两个结构体可以进行等值比较。当进行比较时,会按照字段的顺序逐个比较结构体中的字段。例如,有一个包含两个int字段的结构体struct {a, b int},可以直接使用运算符来比较两个这样的结构体是否相等,它会先比较第一个int字段,如果相等再比较第二个int字段。
但是,如果结构体中包含不可比较的字段(如map、slice类型等),那么这个结构体就不能直接使用运算符进行比较。
如何理解interface类型
interface是一种抽象类型,它定义了一组方法签名。一个类型如果实现了interface中定义的所有方法,那么这个类型就实现了这个interface。例如,定义一个Animal interface,其中包含Speak()方法,那么任何结构体只要实现了Speak()方法,就可以被看作是实现了Animal interface。
interface在Go语言中有很多用途,比如可以用于实现多态,使得代码更加灵活和可扩展。可以通过接口类型的变量来调用实现了该接口的具体类型的方法,而不需要关心具体的类型是什么。
1.18版本后interface有什么增强
Go 1.18版本对interface进行了泛型支持的增强。
这使得interface可以与泛型结合使用,更加灵活地定义和使用抽象类型。例如,可以定义带有类型参数的interface,这些类型参数可以在具体实现中被替换为具体的类型,从而可以更好地处理不同类型的数据,并且在编译时可以进行更严格的类型检查,提高代码的安全性和可维护性。
interface可以进行等值比较吗
interface可以进行等值比较。如果两个interface变量的动态类型相同且动态值相等,那么它们相等。例如,如果有两个interface变量,一个是实现了某个接口的结构体A的实例,另一个也是结构体A的实例,并且它们的字段值都相等,那么这两个interface变量相等。
但是如果两个interface变量的动态类型不同,即使它们的底层值在某种程度上看起来相似,它们也不相等。
map和slice哪个是线程安全的,map手动加锁和sync.Map的区别是什么
都不安全 区别在于性能 后面数据结构那详细讲了
map并发访问会怎么样?这个异常可以捕获吗?
new和make区别
值传递和引用传递
如何检测死锁
遇到死锁或泄漏,可以用这些方法定位:
runtime.GoroutineProfile:用 pprof 看 goroutine 状态,找卡在 channel 上的。
打印日志:在发送/接收处加日志,追踪谁没就位。
go vet:静态分析工具,能揪出一些潜在问题。
你知道 Go 条件编译吗?
Golang支持两种条件编译的实现方式:
编译标签(build tags):
编译标签由空格分隔的编译选项(options)以”或”的逻辑关系组成
每个编译选项由逗号分隔的条件项以逻辑”与”的关系组成
每个条件项的名字用字母+数字表示,在前面加!表示否定的意思
不同tag域之间用空格区分,他们是OR关系
同一tag域之内不同的tag用都好区分,他们是AND关系
每一个tag都由字母和数字构成,!开头表示条件“非”
% head headspin.go
// Copyright 2013 Way out enterprises. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// +build someos someotheros thirdos,!amd64
// Package headspin implements calculates numbers so large
// they will make your head spin.
package headspin
文件后缀(file postfix):
这个方法通过改变文件名的后缀来提供条件编译,这种方案比编译标签要简单,go/build可以在不读取源文件的情况下就可以决定哪些文件不需要参与编译。
文件命名约定可以在go/build 包里找到详细的说明,简单来说如果你的源文件包含后缀:_GOOS.go,那么这个源文件只会在这个平台下编译,_GOARCH.go也是如此。这两个后缀可以结合在一起使用,但是要注意顺序:_GOOS_GOARCH.go, 不能反过来用:_GOARCH_GOOS.go. 例子如下:
mypkg_freebsd_arm.go // only builds on freebsd/arm systems
mypkg_plan9.go // only builds on plan9
3. 如何实现交叉编译?
我们知道golang一份代码可以编译出在不同系统和cpu架构运行的二进制文件。go也提供了很多环境变量,我们可以设置环境变量的值,来编译不同目标平台。
GOOS: 目标平台; GOARCH: 目标架构。
# 编译目标平台linux 64位
GOOS=linux GOARCH=amd64 go build main.go
# 编译目标平台windows 64位
GOOS=windows GOARCH=amd64 go build main.go
并发原语
- groutine
- chan
- select
- sync包
groutine
如何控制 goroutine 的生命周期(channel 的作用,context 的作用)
goroutine内存泄漏的情况?如何避免
常见的goroutine内存泄漏情况
泄漏的goroutine:
-
启动了一个goroutine但没有正确地等待其完成。
例如,使用了go关键字启动了一个goroutine,但没有使用sync.WaitGroup或channel来同步。 -
循环创建goroutine:在循环中无限制地创建goroutine,而没有适当的机制来限制或回收它们。
-
泄漏的channel:创建了channel但没有关闭,导致垃圾回收器无法回收相关资源。
-
泄漏的锁:使用sync.Mutex或其他同步机制时,没有正确释放锁。
如何避免goroutine内存泄漏
-
使用sync.WaitGroup等待goroutine完成:
确保每个启动的goroutine在完成时都调用Done(),并且在主goroutine中使用Wait()来等待所有goroutine完成。 -
合理控制goroutine的数量:
-
如果需要在循环中创建大量goroutine,考虑使用限流(如使用chan来限制并发数)或使用time.Ticker或time.Ticker来控制频率。
ch := make(chan struct{}, maxGoroutines) // 控制同时运行的goroutine数量
for i := 0; i < totalTasks; i++ {
ch <- struct{}{} // 等待空槽位
go func(i int) {
defer func() { <-ch }() // 完成任务后释放槽位
// 你的代码逻辑
}(i)
}
-
正确关闭channel:
-
及时释放锁:
-
资源监控和限制:在生产环境中,监控goroutine的数量和资源使用情况,确保不会因为过多的goroutine而导致系统资源耗尽。可以使用pprof等工具进行性能分析。
协程切换的时机?
一、主动阻塞操作触发切换
系统调用阻塞
当协程执行阻塞型系统调用(如文件 I/O、网络 I/O)时,调度器会将该协程挂起,并切换到其他可运行的协程。
管道读写阻塞
若协程尝试读写无缓冲管道且未匹配到操作方,或缓冲管道已满/空,会触发协程挂起并切换上下文。
定时器操作
使用 time.Sleep、time.After 或 time.Ticker 时,协程会主动让出 CPU 并进入休眠状态,调度器切换至其他协程。
context也可以?
二、调度器公平性机制触发切换
本地队列调度
每个调度周期(通过 schedtick 计数),调度器会检查本地队列中的协程执行时间。若某个协程占用时间过长(如未主动让出),调度器强制将其切出并重新调度其他协程。
全局队列轮询
每经过若干次本地调度周期,调度器会优先从全局队列中取出一个协程执行,避免全局队列因本地队列繁忙而长时间饥饿。
三、隐式切换时机
协程创建或结束
通过 go func() 创建新协程时,或在协程函数执行完毕退出时,调度器可能触发切换以执行其他任务。
垃圾回收(GC)阶段
垃圾回收器运行期间,可能暂停用户协程并切换至标记/清理协程,待 GC 完成后再恢复原协程执行。
四、底层切换实现
寄存器状态保存与恢复
协程切换时仅需保存/恢复 CPU 寄存器(如程序计数器 %rip、栈指针 %rsp)及栈帧信息,无需内核介入,开销仅为数十纳秒量级。
mcall 与 g0 调度
通过 mcall 函数保存当前协程状态,并在当前线程的 g0(调度协程)堆栈上执行 schedule() 函数,完成新协程的调度
chan
是否可以先判断channel是否阻塞,再写入数据
不能
你最多只能 类似select+default 然后循环几次select的方式去尝试解决
能否检测channel是否关闭
没有直接的api 只能间接的方法去实现
即使ok 或者range方法 也可能会阻塞
常见方法看另一篇博客
如果chan 在有缓冲区的情况下缓冲区满了不想要后续的数据了怎么做
方案一:非阻塞发送结合默认处理
使用 select 的 default 分支实现非阻塞写入,当缓冲区满时直接丢弃数据或执行其他逻辑:
select {
case ch <- data: // 正常写入
// 处理成功发送逻辑
default: // 缓冲区已满时触发
// 丢弃数据或记录日志(如 log.Println("channel full, discard data"))
}
此方法通过非阻塞机制直接跳过无法写入的数据13。
方案二:动态关闭通道
若需彻底停止接收新数据,可主动关闭 channel,但需配合同步机制(如 sync.Once)确保关闭操作仅执行一次:
go
Copy Code
var once sync.Once
select {
case ch <- data:
// 正常处理
default:
once.Do(func() { close(ch) }) // 关闭通道,后续写入会 panic
}
需注意:关闭后再次写入会引发 panic,需通过协程状态或标志位控制写入行为14。
方案三:缓冲区容量检查(限特定场景)
在单协程写入或低并发场景中,可通过 len() 和 cap() 检查缓冲区状态:
go
Copy Code
if len(ch) < cap(ch) {
ch <- data // 写入数据
} else {
// 处理缓冲区已满逻辑
}
需注意:len() 和 cap() 在并发场景下可能产生竞态,需结合锁或原子操作保证准确性28。
选择建议
实时性要求高:优先使用 select + default,避免阻塞且代码简洁。
需彻底终止数据流:结合关闭通道和状态标志位。
简单场景:单协程写入时可尝试缓冲区容量检查。
使用channel时需要注意哪些事项?阻塞 死锁 panic 关闭 内存泄漏
这里改了的话 要同步到那篇博客里
- 阻塞(暂时) 如果要求时间的流程 则阻塞会造车不好的体验
- 避免死锁(永久阻塞)
确保发送和接收操作能够匹配,避免因为通道的两端都在等待对方而导致死锁。 - 注意会不会panic
- 优雅关闭
- 内存泄露
- 使用select处理多个通道
当需要同时监听多个通道时,使用 select 语句可以提高代码的效率和可读性。 - 慎用全局通道
全局通道可能导致难以调试的并发问题,尽量在局部范围内使用通道。
什么时候会阻塞 什么时候会panic?
| chan的状态\动作 | 发送 | 接收 | 关闭 |
|---|---|---|---|
| nil(为初始化) | 阻塞 | 阻塞 | panic |
| 无缓冲 | 阻塞 | 阻塞 | 成功:返回零值 |
| 缓冲区是空的 | 成功 | 阻塞 | 成功:返回零值 |
| 缓冲区有值但没满 | 成功 | 成功 | 成功:返回零值(剩余数据后) |
| 缓冲区满 | 阻塞 | 成功 | 成功:返回零值(剩余数据后) |
| 已关闭 | panic | 成功:返回零值(或无数据时) | panic |
表说明:
- nil代表通道此时没有初始化 比如 你声明了一个通道但没有使用make函数进行初始化
- 这个表要竖着看,当动作为发送的时候,下面那些都是当chan为发送chan时的状态
- 由于chan的发送接受是按照顺序的 有个延时 所以这些结果是那一瞬间,比如发送完和对方接收的中间态
- 没值、有值、满是说此时通道内缓冲区没有值、有值、缓冲区满
- 如果是不带缓冲区的chan 那可以当成慢缓冲区的处理
注意:
- 关闭(close)未初始化的channel会引起panic。
- 对已经关闭的通道再执行 close 也会引发 panic。
- 从一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值,并不会引起panic。
- 关闭空的通道是安全的。关闭一个空的通道不会导致panic,但接收方需要检查通道是否已关闭,以避免接收零值
什么时候会死锁?
- 无缓冲区 channel 的生产者和消费者必须成对出现,如果缺乏一个,就会造成死锁
- 无缓冲区 生产者和消费者出现在同一个 goroutine 中会死锁
- buffered channel 已满,且出现上述情况
chan的应用场景
- 一、同步控制
- 停止信号
通过关闭channel或发送特定元素,实现协程间优雅终止的通信机制,常用于任务结束通知或系统退出控制
- 协程同步
使用无缓冲channel强制协程执行顺序,例如主协程通过阻塞接收channel关闭事件等待异步任务完成。
- 停止信号
- 二、数据流处理
- 生产消费模型
构建任务队列系统,生产者协程向channel发送数据,消费者协程异步处理数据,适用于日志收集、订单处理等场景。 - 管道式数据处理
通过串联多个channel实现数据流管道,支持数据分阶段处理与转换,提升处理链路的可维护性。
- 生产消费模型
- 三、并发管理
- 并发数限制
使用带缓冲channel作为令牌桶,通过限制channel容量控制同时执行的协程数量,防止资源耗尽。 - 互斥锁实现
利用容量为1的缓冲channel实现轻量级互斥锁,控制临界区访问(替代传统sync.Mutex)。
- 并发数限制
- 四、定时与超时
- 超时控制
结合time.After和select实现操作超时机制,例如网络请求超过指定时间自动终止。 - 定期任务执行
通过time.Tick创建定时channel,周期性触发任务执行,适用于心跳检测、数据定时拉取等场景。
- 超时控制
- 五、系统解耦
- 事件驱动架构
用channel作为事件总线,实现模块间低耦合通信,例如微服务间的事件通知。 - 任务分发系统
结合worker池模式,通过channel动态分配任务给空闲worker,提升系统吞吐量。
- 事件驱动架构
- 六、状态管理
- 状态同步广播
多个订阅协程通过监听同一channel获取状态变更通知,适用于配置热更新等场景。 - 数据聚合处理
多个数据源协程向聚合channel发送结果,由统一处理器进行汇总计算。
- 状态同步广播
sync包
- 等待组用于等待一组go routine完成工作。例如,在并行计算中,将一个大任务拆分成多个小任务,每个小任务在一个go routine中执行,使用等待组来等待所有小任务完成后再进行后续操作。
- 互斥锁
- 底层结构 state 和sema(信号量)
state的不同位分别表示了不同的状态,使用最小的内存来表示更多的意义,其中低三位由低到高分别表示mutexed、mutexWoken 和 mutexStarving,剩下的位则用来表示当前共有多少个goroutine在等待锁 - 饥饿模式(公平锁)与正常模式(非公平锁)
- 自旋模式与睡眠模式
- 再深入问就是不知道 太复杂了 搞不明白 直接放弃
- 底层结构 state 和sema(信号量)
- 读写锁
互斥锁了解多少 知道sema么
看上面
怎么在go中并发编程下等待多个协程的结束,Add()是什么意思,了解过waitgroup么
是waitgroup的实现
add是计数器 调用wg.add后 再将wg传递到开启的协程中 最终才能用
package main
import (
"fmt"
"sync"
)
func worker(id int, wg *sync.WaitGroup) {
defer wg.Done() // Goroutine 完成时调用 Done()
fmt.Printf("Worker %d started\n", id)
fmt.Printf("Worker %d finished\n", id)
}
func main() {
var wg sync.WaitGroup
for i := 1; i <= 3; i++ {
wg.Add(1) // 增加计数器
go worker(i, &wg)
}
wg.Wait() // 等待所有 Goroutine 完成
fmt.Println("All workers done")
}
golang 读写锁的基本原理
以后再补
数据结构
slice
动态数组,cap和len,还有个指针指向底层定长数组
扩容 :1024长度阈值 翻倍与1.25
如果你预测到切片的增长很大,可以考虑在创建切片时预先设置合适的容量,以减少内存分配和复制的次数
slice是线程不安全的
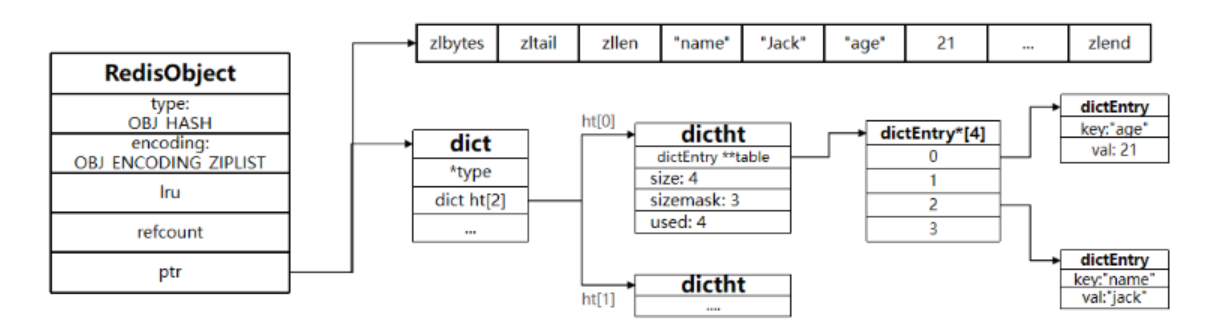
map
基本结构介绍
桶的集合 哈希种子 旧桶 溢出桶 迁移进度字段
桶每个存8个 链表中每个节点存储的不是一个键值对,而是8个键值对
存储是先key再value 类似数组 这样存储的好处是可以消除字节对齐带来的空间浪费形式存储
有oldbuckets,存在则先在oldbuckets中查询 否就在正常桶中
hash 低八位定位bucket的位置 高八位定位桶中的位置
多的溢出桶中
生成map的时候会预先生成一些溢出桶 存在字段中
扩容条件
- 负载因子过高:负载因子是指map中元素数量与桶数量的比值。当负载因子超过一定阈值时,map会进行扩容。默认情况下,负载因子的阈值为6.5,即当map中的元素数量超过桶数量的6.5倍时,会触发扩容。
- 溢出桶过多:
渐进式扩容 每次新建 删除等操作
是线程安全的么?map是线程不安全的
sync.map
线程安全
核心思想是尽可能无锁化与读写分离
适合读多写少的场景
read相当于是dirty的备份快照或者高速缓存,dirty中保存的是最新完整的数据。sync.map的核心就在于read和dirty的互动
写入时则只写入 dirty
读取 read 并不需要加锁,而读或写 dirty 都需要加锁
另外有 misses 字段来统计 read 被穿透的次数(被穿透指需要读 dirty 的情况),超过一定次数则将 dirty 数据同步到 read 上
对于删除数据则直接通过标记来延迟删除
缺点:sync.Map没有像普通map那样的直观语法,必须使用特定的方法来操作键值对
对于键值对数量快速增长、写操作频繁的场景,sync.Map的性能可能不如使用普通map加锁的方式
读操作无锁情况下,可能会出现时间竞态问题
defer
在Go语言的实现中,defer 语句的实现是通过栈(stack)来管理的。每个 defer 调用实际上是在当前的 goroutine 的栈上压入了一个结构体,这个结构体包含了被推迟执行的函数调用的信息。具体来说,每个 defer 记录通常包含以下几个部分:
函数指针:指向被推迟执行的函数的指针。
参数:被推迟函数的参数。
返回值地址:如果被推迟的函数有返回值,这里会存储返回值的地址,以便在函数执行完毕后将返回值赋值回这些地址。
延迟链指针:指向下一个 defer 记录的指针,形成一个链表。
channel
简单来说
首先是再堆里 channel是用来实现goroutine间通信的,其生命周期和作用域几乎都不太可能仅仅局限于某个具体的函数内,所以在设计的时候就直接在堆上创建。
包含一个send队列和receive队列,当缓冲区满了或者无缓冲的时候,就会加到里面(比如多个向我们的chan发送数据 需要按照顺序连起来 然后阻塞接受) (虽然比如不带缓存 也要都存起来 体会下)
还含有一个环形数组用于缓冲区,虽然叫环形 但是实际上就是普通数组 只是我们的用法像环形 。之所以是环形 是因为chan既可以写也可以读 所以
此外就是一些一些标记的下标
如果面试官还要更多细节 则:
- Channel 的发送和接收操作均遵循了先进先出的设计原则,即:先从 Channel 读取数据的 Goroutine 会先接收到数据,先向Channel发送数据的 Goroutine 会先得到发送数据的权利。
这得益于其底层的数据结构。Channel的底层数据结构包含了两个阻塞队列(双向链表实现),分别为发送阻塞队列sendq和接收阻塞队列recvq,遵循FIFO原则。 - 当写 goroutine 或读 goroutine被阻塞时,它们会被封装成runtime.sudog对象,加入到 sendq或recvq 队尾。
当阻塞的 goroutine 被唤醒时,会从 sendq或recvq队头取出阻塞的 goroutine进行执行。 - 另外,Channel 的底层数据结构中还包含了代表缓冲的循环数组buf,以及循环数组的索引sendx和recvx,通过这个两个索引来保证 Channel 读写的有序性。
向一个已经关闭的 Channel 读时,如果 Channel 缓冲区有数据,直接返回缓冲区recvx索引位置的数据;如果缓冲区没数据或者无缓冲区,直接返回该 Channel 类型的零值
向一个已经关闭的 Channel 写时,会抛出panic,除此之外,关闭已经关闭的 Channel和关闭一个 nil 的 Channel 都会panic。
向一个nil 的 Channel 发送或者读取数据会永久堵塞。
是线程安全的
waitgroup
简单来说
里面三个字段 nocopy 、 state、sema
最核心的是state 最新版是64位uint 旧版是32位 还存在对其问题
state是个数字 但是里面通过划分位次 维护了 2 个计数器,一个是请求计数器counter ,另外一个是等待计数器waiter(已调用 WaitGroup.Wait 的 goroutine 的个数)
在WaitGroup里主要有3个方法:
WaitGroup.Add():可以添加或减少请求的goroutine数量,Add(n) 将会导致 counter += n
WaitGroup.Done():相当于Add(-1),Done() 将导致 counter -=1,请求计数器counter为0 时通过信号量调用runtime_Semrelease唤醒waiter线程
WaitGroup.Wait():会将 waiter++,同时通过信号量调用 runtime_Semacquire(semap)阻塞当前 goroutine
内存机制
介绍下内存机制
内存区域:堆、栈、对象池
内存管理:gc、内存逃逸、同步与并发支持等
go的 mcache , mspan , mcentral 和 mheap
内存池
sync.Pool 是 Go 标准库中提供的一个对象池(Object Pool)实现,用于缓存和复用临时对象,以减少内存分配和垃圾回收(GC)的压力。它的主要特点是:
- 临时对象复用:sync.Pool 可以存储和复用临时对象,避免频繁的内存分配和释放。
- 自动清理:sync.Pool 中的对象可能会被垃圾回收器自动清理,因此不能依赖它来长期保存对象。但好处是不会内存泄露会自动清理
- 并发安全:sync.Pool 是并发安全的,多个 Goroutine 可以安全地从中获取和放回对象。
使用场景 高性能 频繁使用 比如数据库连接池、在解析 JSON复用临时缓冲区、网络服务器中的请求处理对象等
gc
如果若干个线程发生OOM,会发生什么?Goroutine中内存泄漏的发现与排查?项目出现过OOM吗,怎么解决?
线程 如果线程发生OOM,也就是内存溢出,发生OOM的线程会被kill掉,其它线程不受影响。
Goroutine中内存泄漏的发现与排查
go中的内存泄漏一般都是goroutine泄露,就是goroutine没有被关闭,或者没有添加超时控制,让goroutine一只处于阻塞状态,不能被GC。在Go中内存泄露分为暂时性内存泄露和永久性内存泄露。
暂时性内存泄露,string相比切片少了一个容量的cap字段,可以把string当成一个只读的切片类型。获取长string或者切片中的一段内容,由于新生成的对象和老的string或者切片共用一个内存空间,会导致老的string和切片资源暂时得不到释放,造成短暂的内存泄漏。
永久性内存泄露,主要由goroutine永久阻塞而导致泄漏以及time.Ticker未关闭导致泄漏引起。
Go的垃圾回收算法
Go 现阶段采用的是通过三色标记清除扫法与混合写屏障GC策略。其核心优化思路就是尽量使得 STW(Stop The World) 的时间越来越短。
首先介绍早期的 普通标记清除
首先介绍三色标记法是什么 优点是 三色标记法相对于普通标记清除,减少了 STW 时间。这主要得益于标记过程是 “on-the-fly”的,在标记过程中是不需要 STW的,它与程序是并发执行的,这就大大缩短了 STW 的时间。
然后说存在的问题
之后引出解决方案 写屏障和删除屏障 强三色 弱三色
最后介绍go gc的混合屏障: 混合写屏障: GC开始将栈上的对象全部扫描并标记为黑色(之后不再进行第二次重复扫描,无需STW), GC期间,任何在栈上创建的新对象,均为黑色。 被删除的对象标记为灰色。 被添加的对象标记为灰色。
GC 的过程一共分为四个阶段:
- 栈扫描(STW),所有对象开始都是白色
- 从 root 开始找到所有可达对象(所有可以找到的对象),标记灰色,放入待处理队列
- 遍历灰色对象队列,将其引用对象标记为灰色放入待处理队列,自身标记为黑色
- 清除(并发)循环步骤3 直到灰色队列为空为止,此时所有引用对象都被标记为黑色,所有不可达的对象依然为白色,白色的就是需要进行回收的对象。
go内存逃逸
面试应该从以下角度回答
- 什么是逃逸?
- 导致内存逃逸的原因是什么
- 后果
- 常见的发生逃逸的情况与逃逸分析
Go程序启动时发生什么
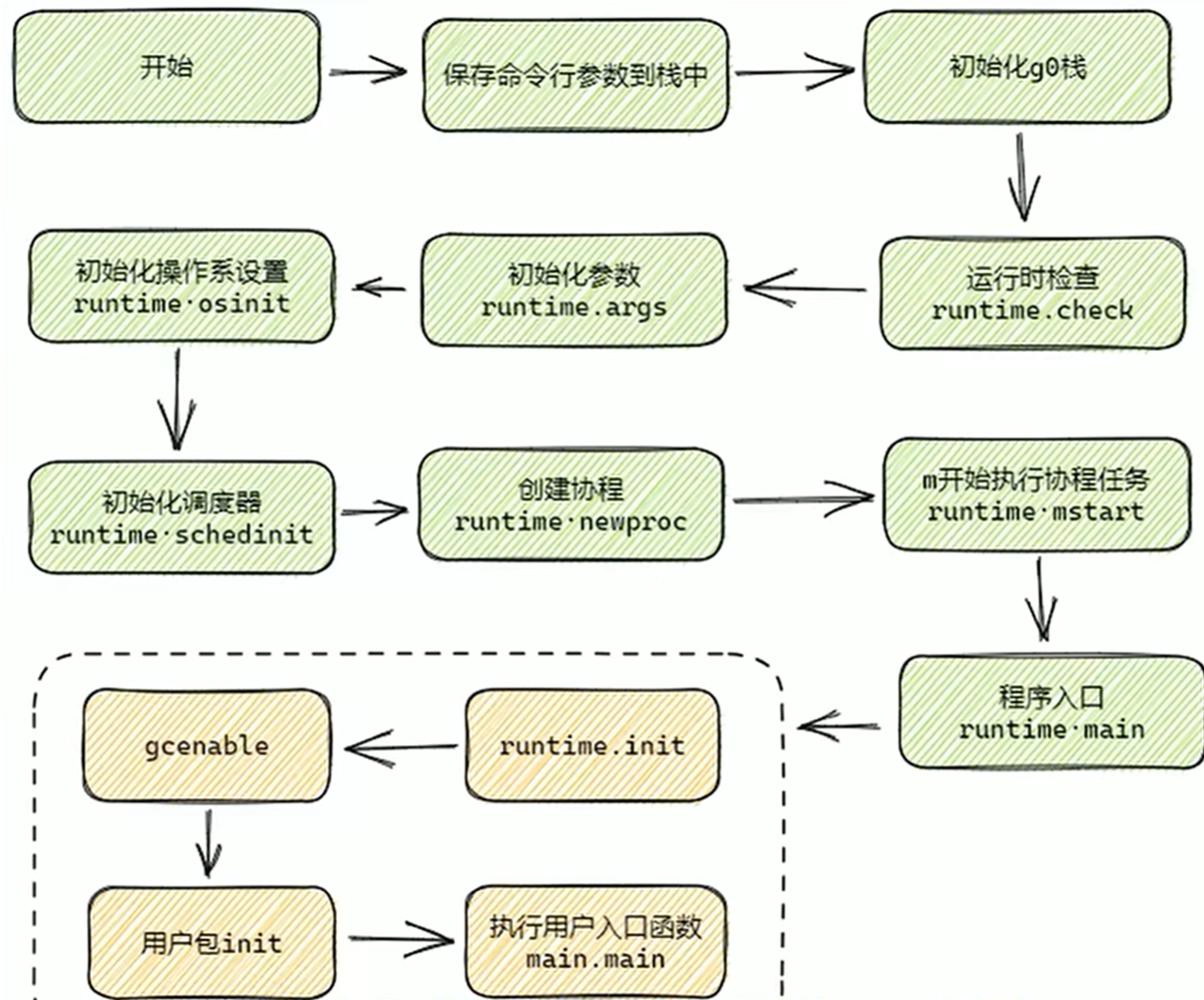
Golang 程序的运行入口是 runtime 定义的一个汇编函数。这个函数核心有三个逻辑:
第一、通过 runtime 中的 osinit、schedinit 等函数对 golang 运行时进行关键的初始化。在这里我们将看到 GMP 的初始化,与调度逻辑。
第二、创建一个主协程,并指明 runtime.main 函数是其入口函数。因为操作系统加载的时候只创建好了主线程,协程这种东西还是得用户态的 golang 自己来管理。golang 在这里创建出了自己的第一个协程。
第三、调用 runtime·mstart 真正开启调度器进行运行。
当调度器开始执行后,其中主协程会进入 runtime.main 函数中运行。在这个函数中进行几件初始化后,最后后真正进入用户的 main 中运行。
第一、新建一个线程来执行 sysmon。sysmon的工作是系统后台监控(定期垃圾回收和调度抢占)。
第二、启动 gc 清扫的 goroutine。
第三、执行 runtime init,用户 init。
第四、执行用户 main 函数。
本题:感觉只要答出来M0的创建和M0的G0是怎么初始化 runtime 环境、goroutine的生命周期的就好,再往深的地方走面试就不用面了,时间能都砸这个上面
GMP
有没有了解过gmp模型?
- 首先介绍下线程和进程的区别
- 然后介绍下历史发展:
- 早期一个M多个g的缺点:不能利用多核以及一个阻塞全部阻塞
- 后面 多个M多个G 缺点:全局锁、频繁交接、每个M都要处理内存、数据局部性
- 后面进化到GMP模型:加了一个P,分全局队列和本地队列、复用线程、更优的调度策略等
- 然后详细介绍gmp
p是什么 调度器 维护了一个本地队列 为什么要抽象出一个p?handoff机制
然后介绍设计策略- 复用线程working stealing与hand off
- 多核并行能力 p的数量
- 数据局部性 本地队列和全局队列
- 抢占机制 最多10ms
一些数量的设置题目
P的数量怎么设置:在程序中通过runtime.GOMAXPROCS() 来设置
M的数量怎么设置:runtime/debug包中的SetMaxThreads函数来设置
最高能有多少个P:应该是内核数量
最高多少M:最⼤量一般默认是10000 但是内核很难支持这么多的线程数
GMP模型中协程的最长运行时间是多久:10ms
Work Stealing偷多少:
M 优先执行其所绑定的 P 的本地运行队列中的 G,如果本地队列没有 G,则会从全局队列获取,为了提高效率和负载均衡,会从全局队列获取多个 G,而不是只取一个,个数是自己应该从全局队列中承担的,globrunqsize / nprocs + 1;同样,当全局队列没有时,会从其他 M 的 P 上偷取 G 来运行,偷取的个数通常是其他 P 运行队列的一半;
groutine生命周期
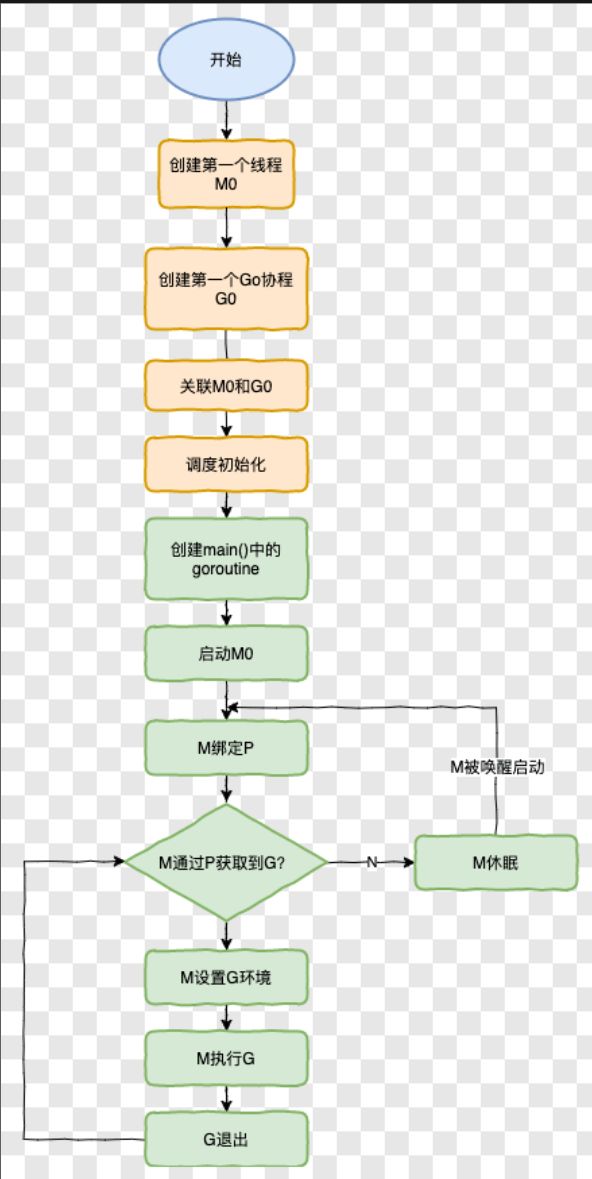
其实就是回答gmp模型
m0和g0是什么
m0 是 Go Runtime 所创建的第一个系统线程,一个 Go 进程只有一个 m0,也叫主线程。
执行用户任务的叫做 g。执行调度任务的叫 g0。g0 比较特殊,每一个 m 都只有一个 g0
如果 goroutine 一直占用资源怎么办,GMP模型怎么解决这个问题
如果有一个goroutine一直占用资源的话,GMP模型会从正常模式转为饥饿模式,通过信号协作强制处理在最前的 goroutine 去分配使用
GMP模型中什么时候把G放全局队列?
当本地队列已满,新创建的协程(G)会被放入全局队列。
另外,当某个P从它的本地队列中取出协程(G)执行时,如果本地队列已经空了,它会尝试从全局队列中获取协程来执行。这样可以保证协程在不同的逻辑处理器(P)之间能够比较均衡地分配,避免某些P空闲而其他P负载过重的情况。
栈里面除了局部变量,函数参数 返回值,还有啥?
栈中包含六类信息:函数调用信息、函数参数返回值局部变量、寄存器状态、协程信息异常处理信息、如果是Go还有特有的延迟调用信息。
面向对象
如何判断一个结构是否实现了某个接口
当一个结构拥有接口定义的全部方法 就是实现了它
- 类型断言
你可以使用类型断言来检查一个变量是否实现了某个接口。如果变量实现了该接口,则类型断言成功;否则,会引发panic。
type MyInterface interface {
DoSomething()
}
type MyStruct struct{}
func (m MyStruct) DoSomething() {}
func main() {
var x interface{} = MyStruct{}
_, ok := x.(MyInterface)
if ok {
fmt.Println("MyStruct implements MyInterface")
} else {
fmt.Println("MyStruct does not implement MyInterface")
}
}
- 使用reflect包
reflect包提供了更灵活的方式来检查类型是否实现了某个接口。
package main
import (
"fmt"
"reflect"
)
type MyInterface interface {
DoSomething()
}
type MyStruct struct{}
func (m MyStruct) DoSomething() {}
func main() {
var x interface{} = MyStruct{}
if reflect.TypeOf(x).Implements(reflect.TypeOf((*MyInterface)(nil)).Elem()) {
fmt.Println("MyStruct implements MyInterface")
} else {
fmt.Println("MyStruct does not implement MyInterface")
}
}
java
除了 clone() 还有哪些方式可以对对象进行深拷贝?
2、java 对象的内存结构?标记字是做什么的?
3、写个单例?为何静态内部类实现的单例可以做到线程安全且可延迟加载?
4、new Hashmap<1000> 和 new Hashmap<10000> 在数据都塞满的时候有什么区别?(提示 扩容相关)
5、java 弱引用和虚引用的区别?
6、垃圾回收时标记存活对象的三色标记法原理,以及在出现漏标、错标情况时是如何解决的?
7、jvm 调优你如何做的?现象->排查过程->解决方式->不同解决方案的对比与选择
8、为何引入 JIT 编译?逃逸分析是什么?
9、多线程中的三大问题 java 是如何解决的?
10、synchronized 底层实现原理?释放锁之后如何通知其他线程获取锁?
11、讲讲 AQS?
12、synchronized 做了哪些优化?(偏向锁、轻量级锁、自旋锁、锁粗化、锁消除等)
13、LongAdder 实现原理?
Spring 启动类的注解,介绍一下
因为我项目中用到了,所以被提问了 Spring 二次开发常用的扩展点,还涉及到了 Bean 的生命周期。 BeanPostProcessor,在你项目中如何使用的
Spring 中你常用哪些注解? Autowired 实现原理
看你项目中用到了 Netty,简单介绍下吧。这里还有个 问题是问到 Netty 和 SpringBoot 整合的,但我一直都没理解她想问什么
粘包拆包问题,Netty 解决粘包拆包的 Decoder
Spring 事务了解吗,Spring 事务的注解不生效,是什么原因
Java 引用类型,强软弱虚
Java 是引用传递还是值传递
Object 类你了解哪些方法
常用 GC 算法,常用的垃圾收集器, G1 了解吗
场景题: cpu 打满且频繁 full GC,怎么解决?
有 jvm 调优的经验吗?实际工作中遇到过内存相关的问题吗?用过哪些堆栈工具调试?
Mysql 索引,数据结构为什么使用 B+ 树
索引覆盖了解吗
索引失效的场景
简单描述一下数据库的四种隔离级别以及对应的三种相关问题
MVCC + 锁 保证隔离性
造成幻读的原因了解吗,快照读、当前读。
数据库自增 ID 和 UUID 对比
HashMap 源码,数据结构,如何避免哈希冲突,对比 HashTable
HashMap 源码中,计算 hash 值为什么有一个 高 16 位 和 低 16 位异或的过程?
为什么重写 equals 还要重写 hashCode,不重写会有什么问题
ConcurrentHashMap 底层实现,扩容问题。
计算机网络
综合
网络分层
mac arp ip三张表区别
mac: mac地址与网线端口接口关系
apr:mac地址与ip关系
ip 网络掩码 ip 网关 下一跳等信息
浏览器寻址url过程?
看另一篇博客
网络攻击
XSS 攻击,全称跨站脚本攻击(Cross-Site Scripting),这会与层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,因此有人将跨站脚本攻击缩写为XSS。它指的是恶意攻击者往Web页面里插入恶意html代码,当用户浏览该页之时,嵌入其中Web里面的html代码会被执行
SYN泛洪攻击
TCP进入三次握手前,服务端会从CLOSED状态变为LISTEN状态,同时在内部创建了两个队列:半连接队列(SYN队列)和全连接队列(ACCEPT队列)。
什么是半连接队列(SYN队列) 呢? 什么是全连接队列(ACCEPT队列) 呢?
TCP三次握手时,客户端发送SYN到服务端,服务端收到之后,便回复ACK和SYN,状态由LISTEN变为SYN_RCVD,此时这个连接就被推入了SYN队列,即半连接队列。
当客户端回复ACK, 服务端接收后,三次握手就完成了。这时连接会等待被具体的应用取走,在被取走之前,它被推入ACCEPT队列,即全连接队列。
DoS、DDoS、DRDoS
DOS: (Denial of Service),中文名称是拒绝服务,一切能引起DOS行为的攻击都被称为DOS攻击。最常见的DoS攻击有计算机网络宽带攻击和连通性攻击。
DDoS: (Distributed Denial of Service),中文名称是分布式拒绝服务。是指处于不同位置的多个攻击者同时向一个或数个目标发动攻击,或者一个攻击者控制了位于不同位置的多台机器并利用这些机器对受害者同时实施攻击。常见的DDos有SYN Flood、Ping of Death、ACK Flood、UDP Flood等。
DRDoS: (Distributed Reflection Denial of Service),中文名称是分布式反射拒绝服务,该方式靠的是发送大量带有被害者IP地址的数据包给攻击主机,然后攻击主机对IP地址源做出大量回应,形成拒绝服务攻击。
CSRF攻击
CSRF,跨站请求伪造(英语:Cross-site request forgery),简单点说就是,攻击者盗用了你的身份,以你的名义发送恶意请求。跟跨网站脚本(XSS)相比,XSS 利用的是用户对指定网站的信任,CSRF 利用的是网站对用户网页浏览器的信任。
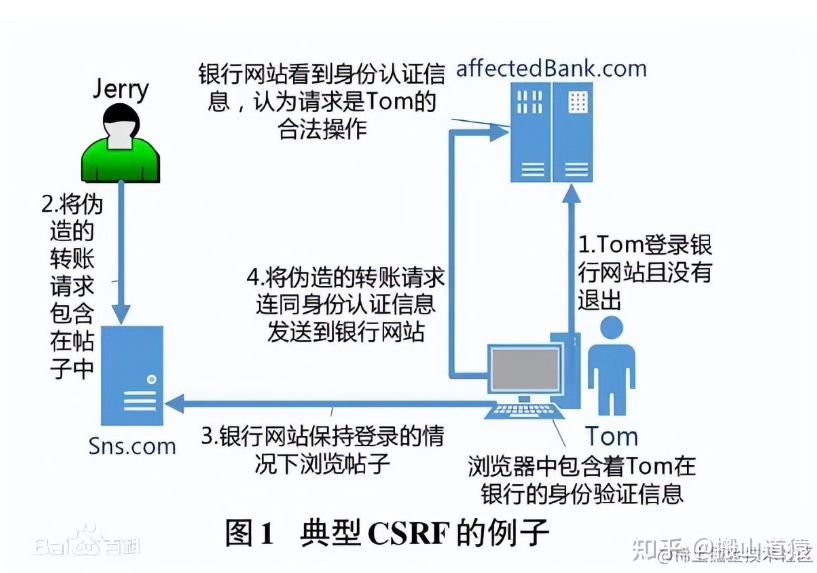
如何解决CSRF攻击
检查Referer字段。HTTP头中有一个Referer字段,这个字段用以标明请求来源于哪个地址。
添加校验token。
多路复用 c10k
看操作系统那里
Reactor与Proactor
看操作系统那里
数据链路层
网卡接收到一个数据包,怎么判断是否是自己的呢?些,不知道)
(我说mac,他说这还是到了内核,在底层一些
网络层 主要是ip
有了IP地址,为什么还要用MAC地址?
IP地址可以比作为地址,MAC地址为收件人
讲讲ARP 和RARP协议的原理
ARP:实现IP地址到MAC地址的映射
RARP:是设备通过自己知道的IP地址来获得自己不知道的物理地址的协议
原理大概就是 记录一张表 如果在就直接走 不在就发广播
下一跳路由转发数据包的过程?
ICMP协议与ping
ICMP协议是一种面向无连接的协议,用于传输出错报告控制信息。
它是一个非常重要的协议,它对于网络安全具有极其重要的意义。它属于网络层协议,主要用于在主机与路由器之间传递控制信息,包括报告错误、交换受限控制和状态信息等。
当遇到IP数据无法访问目标、IP路由器无法按当前的传输速率转发数据包等情况时,会自动发送ICMP消息。
比如我们日常使用得比较多的ping,就是基于ICMP的。
最终显示结果有这几项:发送到目的主机的IP地址、发送 & 收到 & 丢失的分组数、往返时间的最小、最大& 平均值
dhcp
dhcp是什么
dhcp流程
传输层tcp和udp
tcp的报文结构
- 源端口号和目的端口号
- 包的序号 乱序问题
- 确认号 丢包问题
- 状态位 例如 SYN 是发起一个连接,ACK 是回复,RST 是重新连接,FIN 是结束连接
- 校验和则是检测数据是否正确
- 窗口大小 流量控制
- 数据
tcp三次握手
- 本质是因为网络延时和可能网络的包可能被丢弃
- 网络存在延时,需要先证明现在网络条件还不错,否则浪费资源。比如客户端向服务端发了个请求,结果服务端一直没响应,客户端就得一直等着。
- 为了防止收到重复包,由于TCP可能重连或者乱序或者一系列其他原因,为了防止收到重复的包,需要一个序号来标记是第几个包(如下载一个视频,肯定是分段的,遇到意外重复发的短要舍弃,同时,有的段可能延迟了,从而先收到后面的,但是你下载到客户端时要重新排序)。而实现这个,需要先约定初始的序号,以区分是和谁的连接。
TCP 需要 seq 序列号来做可靠重传或接收,而避免连接复用时无法分辨出 seq 是延迟或者是旧链接的 seq,因此需要握手来约定确定双方的 ISN(初始 seq 序列号)。
1、客户端和服务端说,我要建立连接了 随机产生一个seq_i
2、服务端和客户端说,你确定要建立连接么?你的连接不是之前延迟发出的么?也随机产生一个seq_j,并且ack=seq_i+1
3、不是延迟发出的啊! ack = seq_j+1 seq_i ++;
为什么握手只用三次,而挥手要四次?
因为四次挥手中的2和3 在连接建立阶段可以合并 不需要等待那一方是否还有数据要发送
小明和小红打电话聊天,通话差不多要结束时,小红说“我没啥要说的了”,小明回答“我知道了”。但是小明可能还会有要说的话,小红不能要求小明跟着自己的节奏结束通话,
但是因为小明准备要说的话可能时间比较久,他要先说一句,我知道了,避免小红以为网络卡了,一直重复问,我要挂了。
之后小明可能又叽叽歪歪说了一通,最后小明说“我说完了”,小红回答“知道了”,这样通话才算结束。
挥手可以三次么?
可以
为什么要wait 2ms
理论上,四个报文都发完了,就可以直接关闭了,那为什么time_wait还需要2msl的时间才能返回close状态?
因为我们要假设网络是不可靠的,若最后发的确认信息服务端没有受到,那么服务端会一直重发关闭的信息过来,说如果收到 证明最后的一步丢失了 因而需要等待等待
首先,能够保证服务端能接收到ACK,从而正常关闭。如果服务端在1MSL内没有收到ACK,会继续发送FIN,从而重新更新TIME_WAIT时间。
然后,2MSL时间能够让历史连接中的报文全部消失,从而能够防止历史连接中的报文被接收。
重传机制
保活机制-探测报文、保活计时器
超时重传:
当一个报文段丢失时,会等待一定的超时周期然后才重传分组,增加了端到端的时延。 当一个报文段丢失时,在其等待超时的过程中,可能会出现这种情况:其后的报文段已经被接收端接收但却迟迟得不到确认,发送端会认为也丢失了,从而引起不必要的重传,既浪费资源也浪费时间。
并且,TCP有个策略,就是超时时间间隔会加倍。超时重传需要等待很长时间。因此,还可以使用快速重传机制。
快速重传
快速重传机制,它不以时间驱动,而是以数据驱动。它基于接收端的反馈信息来引发重传。
接收方连续收到乱序数据时,发送重复ACK(通常3次),发送方立即重传丢失段,无需等待超时。
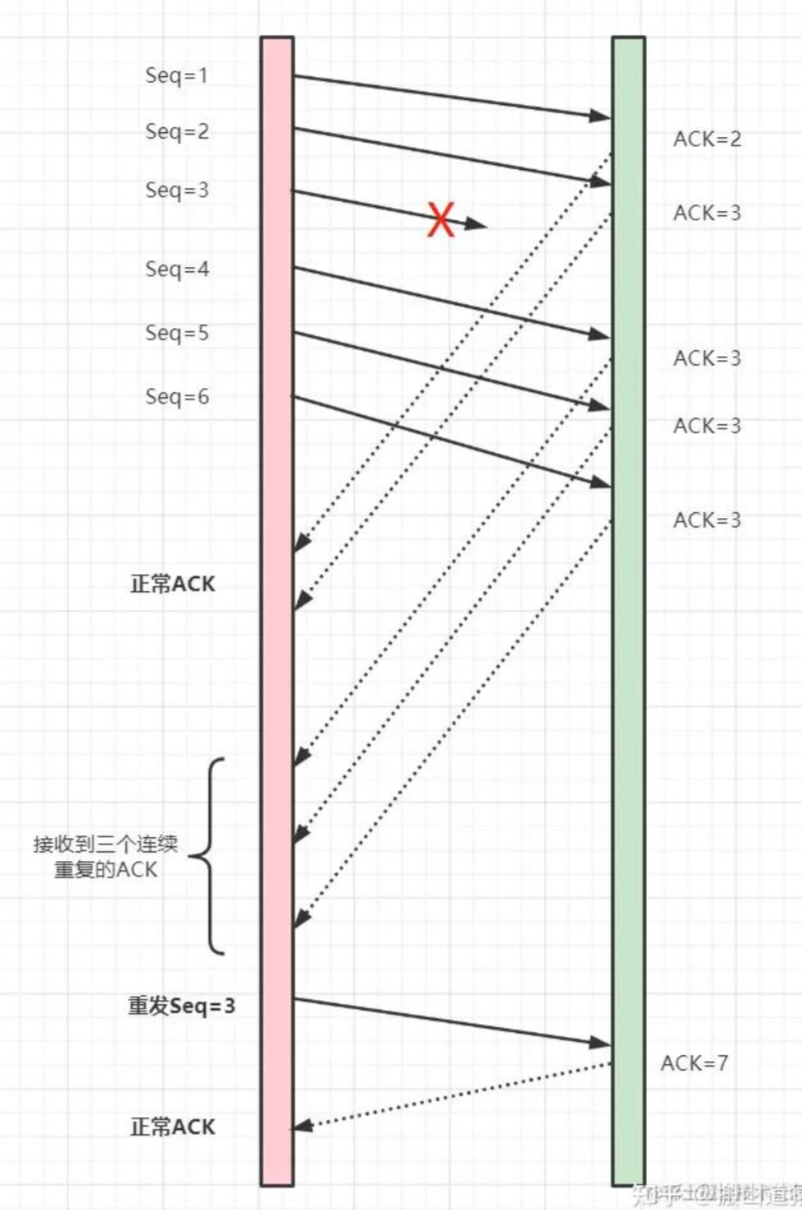
发送端发送了 1,2,3,4,5,6 份数据:
第一份 Seq=1 先送到了,于是就 Ack 回 2;
第二份 Seq=2 也送到了,假设也正常,于是ACK 回 3;
第三份 Seq=3 由于网络等其他原因,没送到;
第四份 Seq=4 也送到了,但是因为Seq3没收到。所以ACK回3;
后面的 Seq=4,5的也送到了,但是ACK还是回复3,因为Seq=3没收到。
发送端连着收到三个重复冗余ACK=3的确认(实际上是4个,但是前面一个是正常的ACK,后面三个才是重复冗余的),便知道哪个报文段在传输过程中丢失了,于是在定时器过期之前,重传该报文段。
最后,接收到收到了 Seq3,此时因为 Seq=4,5,6都收到了,于是ACK回7.
但快速重传还可能会有个问题:ACK只向发送端告知最大的有序报文段,到底是哪个报文丢失了呢?并不确定!那到底该重传多少个包呢?
是重传 Seq3 呢?还是重传 Seq3、Seq4、Seq5、Seq6 呢?因为发送端并不清楚这三个连续的 ACK3 是谁传回来的。
带选择确认的重传(SACK)
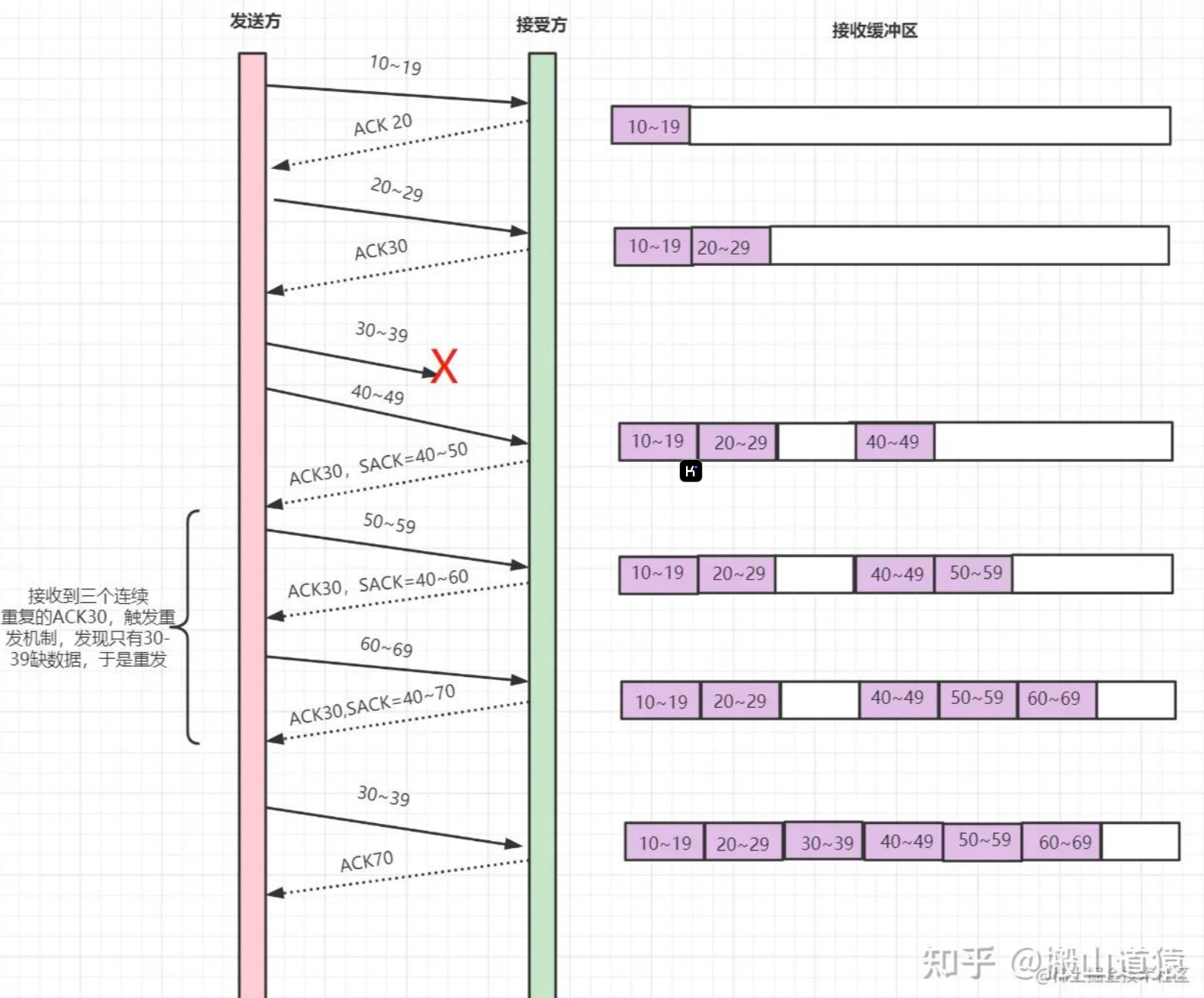
D-SACK
D-SACK,即Duplicate SACK(重复SACK),在SACK的基础上做了一些扩展,,主要用来告诉发送方,有哪些数据包自己重复接受了。DSACK的目的是帮助发送方判断,是否发生了包失序、ACK丢失、包重复或伪重传。让TCP可以更好的做网络流控。
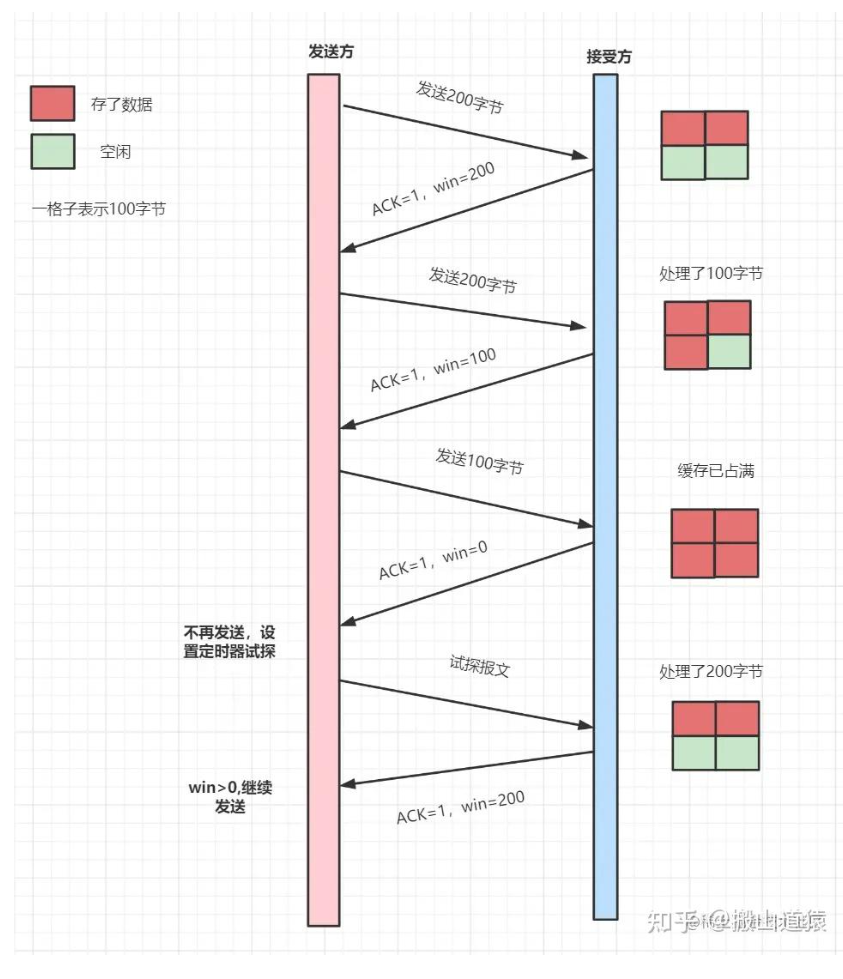
TCP的滑动窗口与流量控制
通俗点讲,就是接受方每次收到数据包,在发送确认报文的时候,同时告诉发送方,自己的缓存区还有多少空余空间,缓冲区的空余空间,我们就称之为接受窗口大小。这就是win。
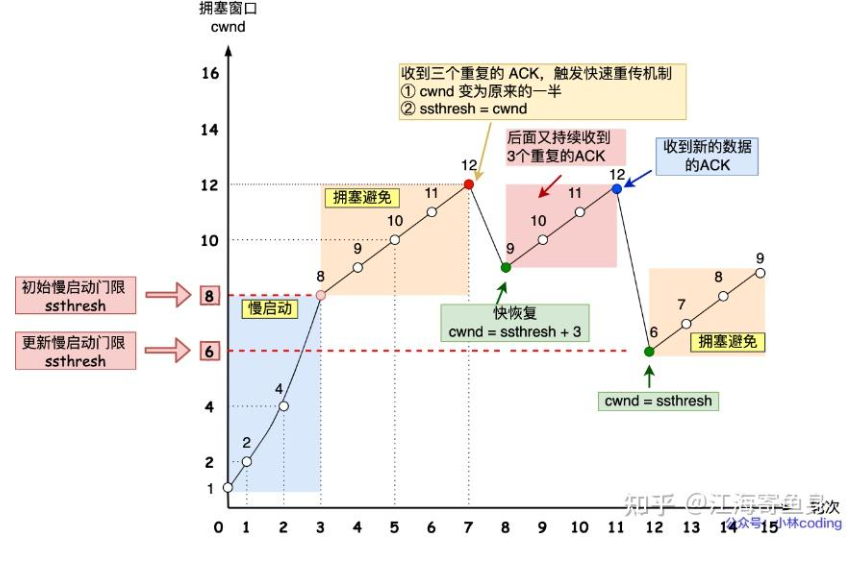
拥塞控制
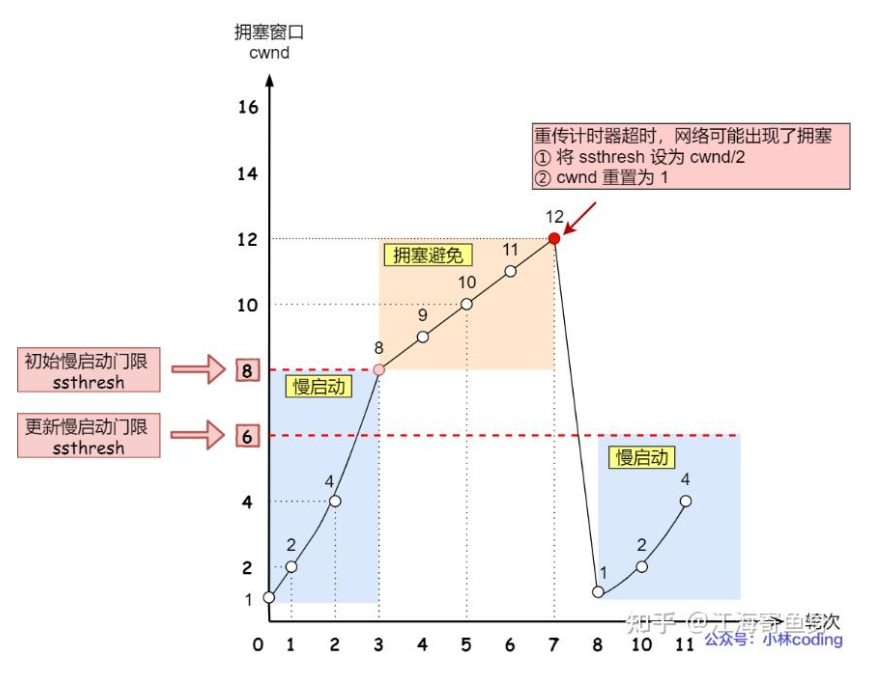
针对快速重传
延迟确认与Nagle 算法
延迟确认:
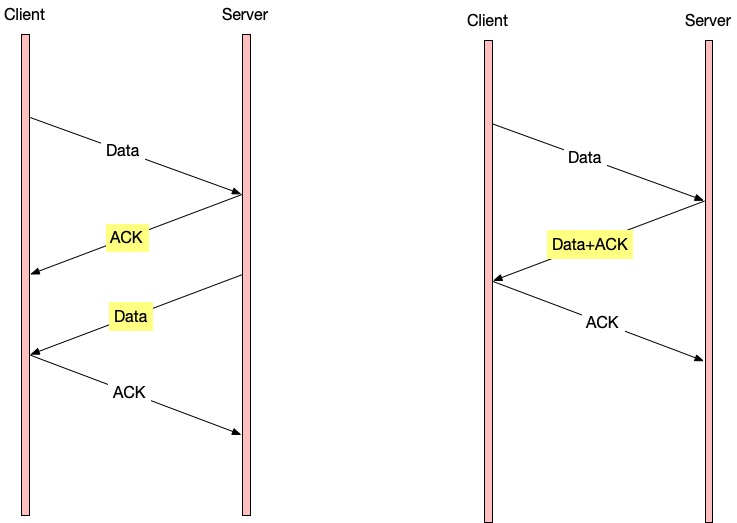
Nagle 设计了一个巧妙的算法 (Nagle’s Algorithm),其本质就是:发送端不要立即发送数据,攒多了再发。但是也不能一直攒,否则就会造成程序的延迟上升。
- 如果包长度达到MSS,则允许发送;
- 如果该包含有FIN,则允许发送;
- 设置了TCP_NODELAY选项,则允许发送;
- 未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
- 上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
nagle和延迟确认不能一起用,否则会死锁造成更大延迟
粘包、分段、面向字节流
如果 HTTP 请求消息比较长,超过了 MSS 的长度,这时 TCP 就需要把 HTTP 的数据拆解成一块块的数据发送,而不是一次性发送所有数据。
MTU:一个网络包的最大长度,以太网中一般为 1500 字节。
MSS:除去 IP 和 TCP 头部之后,一个网络包所能容纳的 TCP 数据的最大长度。
TCP是面向流,没有界限的一串数据。TCP底层并不了解上层业务数据的具体含义,它会根据TCP缓冲区的实际情况进行包的划分,所以在业务上认为,一个完整的包可能会被TCP拆分成多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送,这就是所谓的TCP粘包和拆包问题。
解决方案:
发送端将每个数据包封装为固定长度
在数据尾部增加特殊字符进行分割
将数据分为两部分,一部分是头部,一部分是内容体;其中头部结构大小固定,且有一个字段声明内容体的大小。
tcp的可靠传输
三次握手四次分手、 序列号与确认应答(ACK)、拥塞控制、流量控制、重传机制、
校验和:每个数据段包含16位校验和,接收方验证数据是否损坏,损坏则丢弃并请求重传。
tcp和udp区别
连接:TCP面向连接,UDP无连接
服务对象:TCP一对一,UDP一对一、一对多、多对多
可靠性:TCP可靠,UDP尽全力交付
TCP有拥塞控制和流量控制
TCP的首部开销比UDP大
TCP面向字节流,UDP面向报文
udp为什么有报文丢失
UDP丢包的主要原因是其无连接、不可靠的传输特性,具体表现为网络拥堵、缓冲区溢出、数据包分片丢失、发送频率过快等。以下为详细原因分析:
一、核心原因分类
网络层问题
网络拥塞:网络带宽不足时,类似高速公路拥堵,数据包因排队超时被丢弃。
中间设备限制:路由器或交换机因负载过高主动丢弃数据包。
传输层设计缺陷
缓冲区溢出:
接收缓冲区满:UDP接收端的缓冲区容量有限,若处理速度跟不上接收速度,新数据包会被直接丢弃。
无流量控制:UDP缺乏类似TCP的滑动窗口机制,无法动态调整发送速率。
数据包分片与重组失败
MTU超限:UDP数据包超过链路层最大传输单元(如以太网1500字节)时会被强制分片,若分片丢失则整个数据包失效。
应用层处理不当
高频发送:发送端速率远高于接收端处理能力,导致缓冲区溢出。
目标服务异常:接收端未启动或目标端口无监听进程,数据包直接被丢弃。
upd面向报文
UDP面向报文的主要原因是因为其设计理念和特性。
UDP是一种无连接的协议,这意味着它不建立和维护连接状态。发送数据时,UDP将应用层传递的报文直接封装成数据包发送,接收方收到数据包后直接传递给上层应用,不进行任何拆分或合并操作,保持报文的完整性
这种设计使得UDP具有轻量级和高效率的特点,特别适合于那些对实时性和简单性要求较高的应用场景,如DNS查询和实时音视频流传输
UDP面向报文的具体表现
报文边界保留:UDP在发送和接收数据时,保持报文的完整性,不进行拆分或合并操作。发送方将应用层传递的完整报文封装成数据包发送,接收方收到数据包后直接传递给上层应用,保持报文的边界
无连接性:由于UDP不建立和维护连接状态,每个数据包都是独立的,这使其在网络中的传输更加灵活和高效。但这也意味着UDP不保证数据的可靠性,可能会丢失或乱序到达
udp如何实现可靠传输
应用层自己封装 实现那些特性 或者用别人包装好的框架
应用层
一次网络请求的流程
http、https
看另一篇专门的博客
dns
主要是 递归查询和迭代查询
http协议
总结介绍
- 特性 无状态 无连接 媒体独立 进一步到cookie seesion
- 请求响应报文:
- 请求行:方法、 url、协议版本
- 请求头:(connection、connection-type、user-agent、content-type、gzip、encoding)
- 请求携带数据:比如page:1
- 响应报文 对比多了一个状态码
- 更进一步细化
- 不同版本的区别
- 0.9 get和纯网页
- 1.0 新增方法 mime cache
- 1.1 管道,keepalve
- 2.0 帧 二进制 头压缩(gzip和维持一个表) 多工复用 服务器主动主动推送
- 3 可靠udp替代tcp并解决对头阻塞、更快的连接建立tls、连接迁移
- post和get 以及其他方法
- 端口号
- keep-alive
- content-type
- gzip
- 不同状态码的含义
1xx 类状态码属于提示信息,是协议处理中的一种中间状态,实际用到的比较少
200 - 请求成功
301- (永久移动)资源(网页等)被永久的转移到其它URL 服务器返回此响应(作为对GET或HEAD请求的响应)时,会自动将请求者转到新位置。 301资源还在只是换了一个位置,返回的是新位置的内容;
302(临时移动) 服务器目前正从不同位置的网页响应请求,但请求者应继续使用原有url来进行以后的请求。此代码与响应GET和HEAD请求的301代码类似,会自动将请求者转到不同的位置。302资源暂时失效,返回的是一个临时的代替页上。
「304 Not Modified」不具有跳转的含义,表示资源未修改,重定向已存在的缓冲文件,也称缓存重定向,也就是告诉客户端可以继续使用缓存资源,用于缓存控制。
305-必须使用代理访问
400-语法错误 服务器无法理解
401-要求身份认证
403-拒绝 服务器端理解需求 但是拒绝执行
404 - 请求的资源(网页等)不存在
405-客户端请求中的方法被禁止
500 - 内部服务器错误
「501 Not Implemented」表示客户端请求的功能还不支持,类似“即将开业,敬请期待”的意思。
「502 Bad Gateway」通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。
「503 Service Unavailable」表示服务器当前很忙,暂时无法响应客户端,类似“网络服务正忙,请稍后重试”的意思。
- 不同版本的区别
以上内容来自另一篇博客 如果变更请同步过去
post和get区别
POST实际需要两次TCP,而GET只需要一次
缓存
安全性
https+tls
https流程
数字签名
数字证书
对称加密和非对称
中间人攻击
抓包原理
根证书信任链
rpc
RPC可以像调用本地方法那样调用远端方法
rpc早于http 那既然有 RPC 了,为什么还要有 HTTP 呢?
rpc更私有 http更公有
http基于tcp 粘包
纯裸 TCP 是能收发数据,但它是个无边界的数据流,上层需要定义消息格式用于定义消息边界。于是就有了各种协议,HTTP 和各类 RPC 协议就是在 TCP 之上定义的应用层协议。
RPC 本质上不算是协议,而是一种调用方式,而像 gRPC 和 Thrift 这样的具体实现,才是协议,它们是实现了 RPC 调用的协议。目的是希望程序员能像调用本地方法那样去调用远端的服务方法。同时 RPC 有很多种实现方式,不一定非得基于 TCP 协议。
从发展历史来说,HTTP 主要用于 B/S 架构,而 RPC 更多用于 C/S 架构。但现在其实已经没分那么清了,B/S 和 C/S 在慢慢融合。很多软件同时支持多端,所以对外一般用 HTTP 协议,而内部集群的微服务之间则采用 RPC 协议进行通讯。
RPC 其实比 HTTP 出现的要早,且比目前主流的 HTTP/1.1 性能要更好,所以大部分公司内部都还在使用 RPC。
HTTP/2.0 在 HTTP/1.1 的基础上做了优化,性能可能比很多 RPC 协议都要好,但由于是这几年才出来的,所以也不太可能取代掉 RPC。
操作系统
写直达和写回
看另一篇博客
为什么需要虚拟内存?
如果更改了 同步到另一篇博客
第一,虚拟内存可以使得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU 访问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理内存之外,比如硬盘上的 swap 区域。
第二,由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址冲突的问题和进程内存独立性安全的问题。
第三,页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
第四、通过虚拟内存的映射,内核空间和用户空间某些时候比如io可以映射同一片内存,避免了拷贝复制的耗时操作(具体看零拷贝那里)
内存分配管理有几种
看另一篇博客
内存满了,会发生什么 以及怎么避免oom
看另一篇博客
预读失效和缓存污染——如何改进 LRU 算法
如果更改了 同步到另一篇博客
传统的 LRU 算法法无法避免下面这两个问题:
- 预读失效导致缓存命中率下降;
- 缓存污染导致缓存命中率下降;
为了避免「预读失效」造成的影响,Linux 和 MySQL 对传统的 LRU 链表做了改进:
Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表(active list)和非活跃 LRU 链表(inactive list)。
MySQL Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域:young 区域 和 old 区域。
但是如果还是使用「只要数据被访问一次,就将数据加入到活跃 LRU 链表头部(或者 young 区域)」这种方式的话,那么还存在缓存污染的问题。
为了避免「缓存污染」造成的影响,Linux 操作系统和 MySQL Innodb 存储引擎分别提高了升级为热点数据的门槛:
Linux 操作系统:在内存页被访问第二次的时候,才将页从 inactive list 升级到 active list 里。
MySQL Innodb:在内存页被访问第二次的时候,并不会马上将该页从 old 区域升级到 young 区域,因为还要进行停留在 old 区域的时间判断:
如果第二次的访问时间与第一次访问的时间在 1 秒内(默认值),那么该页就不会被从 old 区域升级到 young 区域;
如果第二次的访问时间与第一次访问的时间超过 1 秒,那么该页就会从 old 区域升级到 young 区域;
通过提高了进入 active list (或者 young 区域)的门槛后,就很好了避免缓存污染带来的影响。
进程和线程区别
进程和线程 使用资源的详细情况 结构
同一个进程内多个线程之间可以共享代码段、数据段、打开的文件等资源,但每个线程各自都有一套独立的寄存器和栈,这样可以确保线程的控制流是相对独立的。
线程挂了回导致进程挂了么
当进程中的一个线程崩溃时,会导致其所属进程的所有线程崩溃(这里是针对 C/C++ 语言,Java语言中的线程奔溃不会造成进程崩溃
锁
如何破坏死锁
死锁只有同时满足以下四个条件才会发生:
互斥条件;
持有并等待条件;
不可剥夺条件;
环路等待条件;
破坏其一即可 最常见的并且可行的就是使用资源有序分配法,来破环环路等待条件。也就是说,线程 A 和 线程 B 总是以相同的顺序申请自己想要的资源。
数据库
设计范式
1NF:列需要保持原子性 如地址可拆分为省市县
2NF:表中的字段由主键决定,而不能是部分主键的情况(主要针对联合主键),能够减小冗余
3NF:确保除了主键的每列都和主键列直接相关,而不是间接相关(无传递依赖)
BCNF:
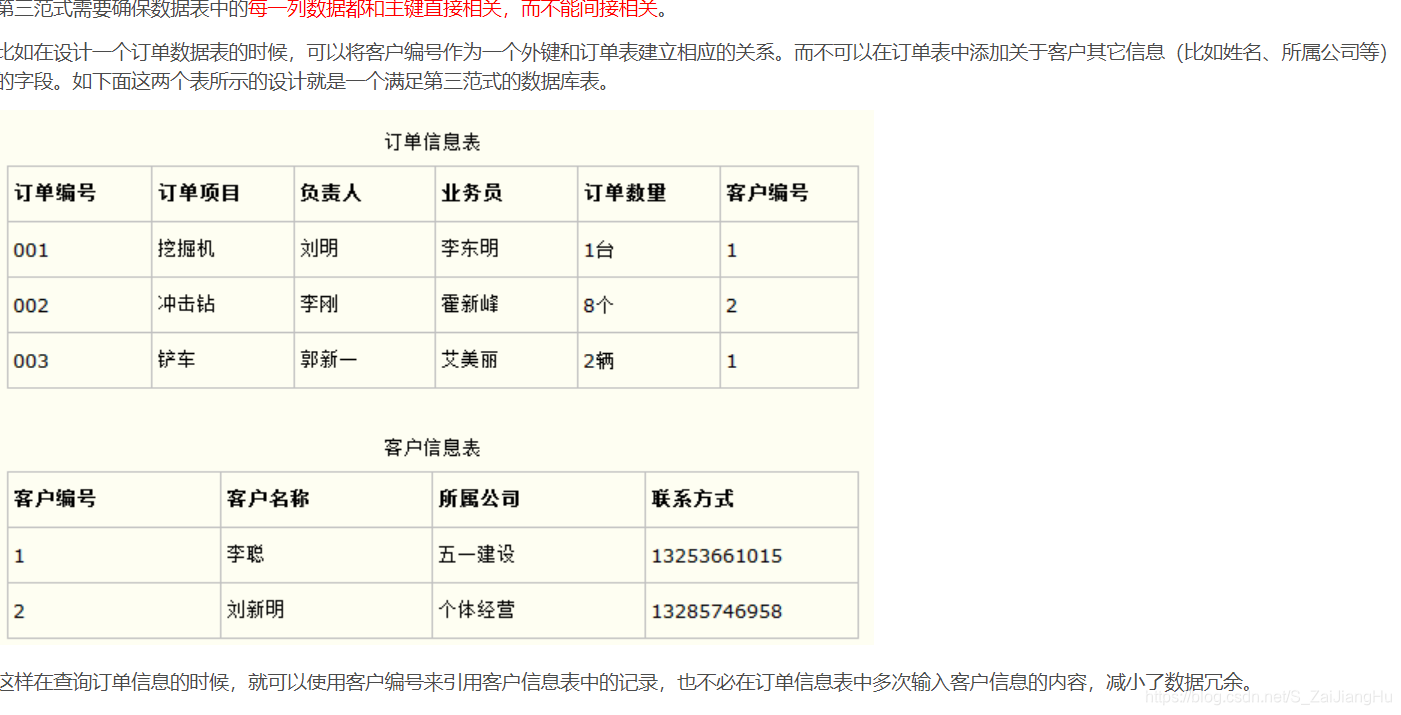
数据库通用
隔离级别有几种,分别会产生什么样的问题
事务的acid
a 原子性
c 一致性 比如集群主从
i 隔离性 事务状态是否可见
d 持久性 如果宕机 也要保证持久性
隔离性
隔离的四种问题
- 脏读 读到未提交事务的
- 不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值。
- 幻读:例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样
- 丢失更新 两个事务同时读取同一条记录,A先修改记录,B也修改记录(B是不知道A修改过),B提交数据后B的修改结果覆盖了A的修改结果。
隔离的四种级别
1️⃣Read uncommitted (读未提交):最低级别,任何情况都无法保证
2️⃣ Read committed (读已提交):可避免脏读的发生
3️⃣ Repeatable read (可重复读):可避免脏读、不可重复读的发生。
4️⃣ Serializable (串行化):可避免脏读、不可重复读、幻读的发生。会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
串行化也不需要真的严格串行化,比如git,你增加行 修改没影响的行 是不影响的 你只要不两个人同时改一行就好 。加锁不让别人改这一行或者当别人改这行后提交报错提醒。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 丢失更新 | 并发模型 | 更新冲突检测 |
|---|---|---|---|---|---|---|
| 读未提交 | 会 | 会 | 会 | 会 | 悲观 | 否 |
| 读已提交 | 不会 | 会 | 会 | 会 | 悲观 | 否 |
| 可重复读 | 不会 | 不会 | 会 | 会 | 悲观 | 否 |
| 串行化读 | 不会 | 不会 | 不会 | 不会 | 悲观 | 否 |
丢失更新如何解决
MVCC解决的是读写并发问题,而更新丢失是写写并发问题
-
乐观锁(Optimistic Locking)
使用版本号或时间戳检测冲突,更新时检查版本是否匹配。UPDATE account SET balance = 70, version = version + 1 WHERE id = 1 AND version = 1; -
悲观锁(Pessimistic Locking)
使用 SELECT … FOR UPDATE 提前锁定数据,阻止其他事务修改。BEGIN; SELECT balance FROM account WHERE id = 1 FOR UPDATE; -- 加锁 UPDATE account SET balance = 70 WHERE id = 1; COMMIT;
mvcc、undolog、readview是干啥的
解决读已提交和可重复读的
有了mvcc为什么还需要锁
解决RR级别 当前读下的幻读问题
当前读和快照读
我们称其中的select xxx for update为当前读,即读取最新的数据,普通的select则是快照读,在mysql中insert、update、delete、select xxx for update都是当前读。
讲讲undolog、readview和mvcc
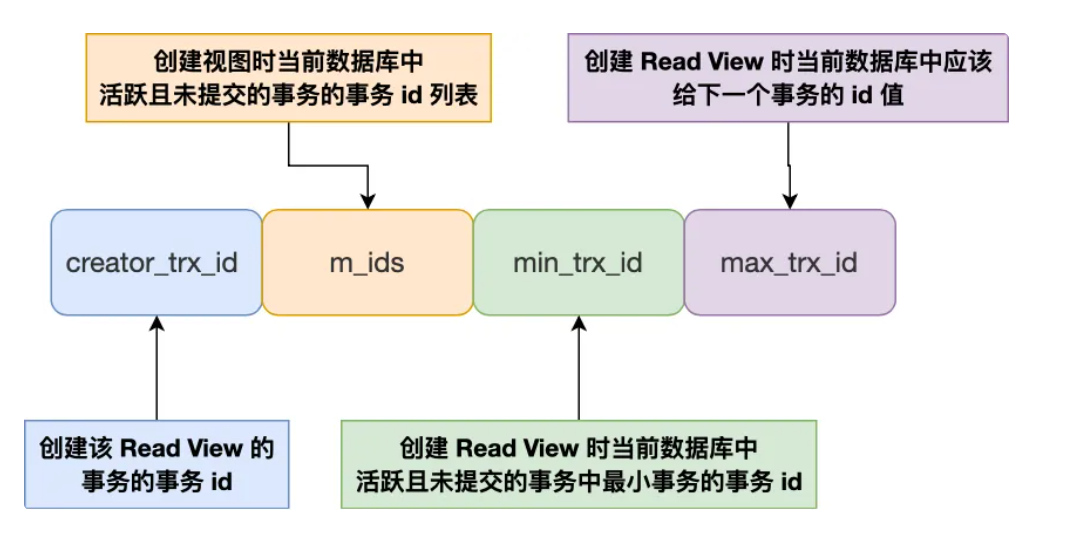
四个隐藏列
对于使用 InnoDB 存储引擎的数据库表,它的聚簇索引记录中都包含下面两个隐藏列:
- trx_id,当一个事务对某条聚簇索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里;也叫 创建版本号 指示创建一个数据行的快照时的系统版本号
- roll_pointer,每次对某条聚簇索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。也叫删除版本号
其实除了这两个 还有两个隐藏字段
- DB_ROW_ID : 6 byte,隐含的自增ID(隐藏主键),如果数据表没有主键, InnoDB 会自动以 DB_ROW_ID 产生一个聚簇索引
- 补充:实际还有一个删除flag隐藏字段, 既记录被更新或删除并不代表真的删除,而是删除flag变了。比如delete的时候 也要记录这个undolog 但是直接没了怎么记录?
undo log
存的就是“还没有提交的undo的”修改
Read View四字段
在某事务创建 Read View 后,我们可以将记录中的 trx_id 划分这三种情况:
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
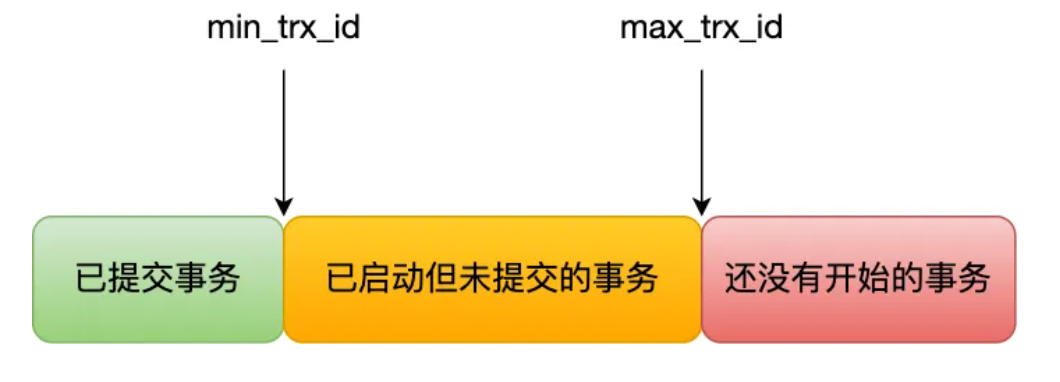
- 如果记录的 trx_id 值小于 Read View 中的 min_trx_id 值,表示这个版本的记录是在创建 Read View 之前已经提交的事务生成的,所以该版本的记录对当前事务可见。
- 如果记录的 trx_id 值大于等于 Read View 中的 max_trx_id 值,表示这个版本的记录是在创建 Read View 之后才启动的事务生成的,所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 值在 Read View 的 min_trx_id 和 max_trx_id 之间,需要判断 trx_id 是否在 m_ids 列表中:
- 如果记录的 trx_id 在 m_ids 列表之中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 不在 m_ids 列表之中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
mvcc如何工作
解决读写冲突问题
MVCC是一种用来解决读写冲突的无锁并发控制,也就是为事务分配单项增长的时间戳,为每个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据库的快照,所以MVCC可以为数据库解决以下问题:
1、在并发读写数据库时,可以做到在读操作时不用阻塞写操作,写操作也不用阻塞读操作,提高了数据库并发读写的性能
2、解决脏读、幻读、不可重复读等事务隔离问题,但是不能解决更新丢失问题
对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 **Read View **来实现的,它们的区别在于创建 Read View 的时机不同:
- 「读提交」隔离级别是在每个 select 都会生成一个新的 Read View,也意味着,事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务。
- 「可重复读」隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View,这样就保证了在事务期间读到的数据都是事务启动前的记录。
这两个隔离级别实现是通过「事务的 Read View 里的字段」和「记录中的两个隐藏列」的比对,来控制并发事务访问同一个记录时的行为,这就叫 MVCC(多版本并发控制)。
RR级别下,是如何解决幻读问题的?
首先 我们要区分RC和RR,RC级别下 那肯定是会幻读的,而RR级别要分情况
对于快照读
快照读情况下 mvcc是完全可以解决幻读问题的,因为快照机制 仅会读取范围事务id内的行
对于当前读——需要加锁
如果你在当前事务中(注意 是当前事务 而非其他事务)使用了 当前读 比如select for update、SELECT … LOCK IN SHARE MODE、delete、insert、update
则会变成当前读,那么就可能出现幻读了!解决方法是,加锁,准确的说是范围锁。以防止类似insert造成的幻读问题
所以,MVCC仅能解决快照读的幻读问题,如果在RR级别下,当你使用当前读的语句的时候,innodb引擎会自动通过加锁(快照读不会)以解决幻读问题
mvcc一定能解决幻读么?
不一定,当你快照读和当前读混用的时候:
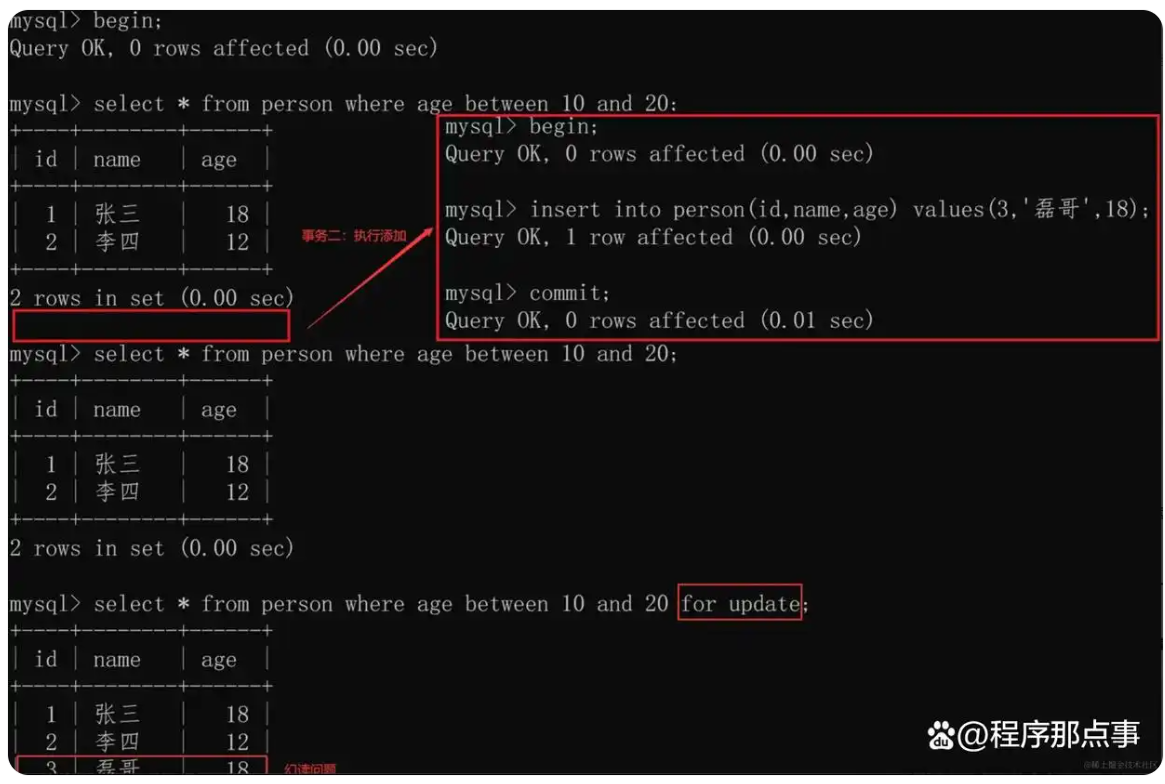
- a事务先select
- b事务insert确实会加一个gap锁(我们先不管锁是什么 而且这里不重要 因为这个锁会释放),但是如果b事务commit,这个gap锁就会释放(释放后a事务可以随意操作)
- a事务再select出来的结果在MVCC下还和第一次select一样
- 接下来
- 如果a:select for update 就会出现新行 因为是当前读
- 如果aa事务不加条件地update,这个update会作用在所有行上(包括b事务新加的)。然后再select 则也会出现新行
所以就会导致此时前后读取的数据不一致,出现幻读
如何彻底解决幻读?
想要彻底解决幻读问题,有两个方案:
-
使用串行化(Serializable)隔离级别:官方推荐方案,但这种解决方案,并发性能比较低。
-
RR + 一开始就手动锁:使用 RR 隔离级别,但在事务开启之后立即加锁,如下图所示:
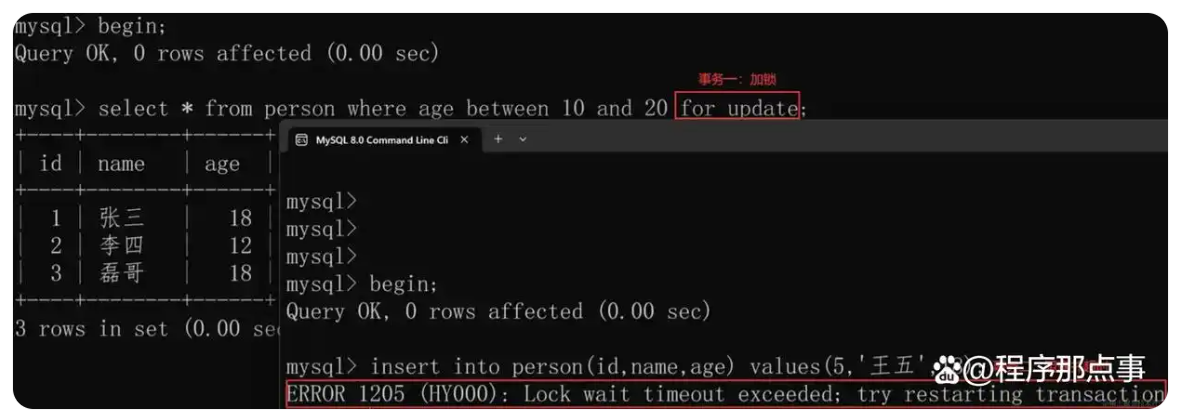
**然而,值得注意的是,间隙锁是引发死锁的重要因素,因此在使用时需要谨慎对待。**而且 在RP级别下,如果没命中索引,可能变成“表锁”
什么场景需要RR?为什么一般不用RR
主要是 类似 数据库整体快照(这个快照不是Read view那个快照)、备份这种 账本啊 类似的情况 其他一般不用
以及 statement情况下 为了避免binlog 主从不一样 需要
实际上 读已提交就够了 没必要可重复读 因为影响性能 以及逻辑上没必要 互联网公司应该也设置为读已提交
mysql innoDB默认级别是可重复读 而其他数据库是读已提交 是因为主从同步 statement格式binlog的问题
InnoDB 引擎的默认隔离级别虽然是「可重复读」,但是它还通过next-key lock锁(行锁和间隙锁的组合)来锁住记录之间的“间隙”和记录本身,防止其他事务在这个记录之间插入新的记录,在「可重复读」这个级别就避免了幻读现象。所以,对innodb来说,要解决幻读现象不建议将隔离级别升级到「串行化」,因为这样会导致数据库在并发事务时性能很差。
而且 在RP级别下,如果没命中索引等其他情况,可能变成“表锁”。即使正常 也可能大量的范围锁 影响性能
undo log 里面的内容什么时候会被清除?
当前最新的记录没有人修改,而且被提交了 且 mysql所有事物当前没有人再和undo log里面的数据有关了
mysql
mysql innodb一级索引三层b+树,主键bigint,每一行数据1kb,能存多少数据
B+ 为什么三层就能够存储三千万左右的数据
查询一条数据的流程
分表分区啊啥的是什么
分表分区后怎么查询?一次性得到结果?
分表好像可以union
select * from apporder.ord_shopping_order
union all
select * from apporder.ord_shopping_order_2
union all
select * from apporder.ord_shopping_order_3
经常用可以创建一个存储过程,方便以后更快速查询
分区好像类似这样
假设你想按年份和月份对订单进行分区,你可以这样做:
CREATE TABLE orders (
order_id INT,
order_date DATE,
amount DECIMAL(10, 2)
)
PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024)
);
然后你可以这样查询特定分区的记录:
SELECT * FROM orders PARTITION (p2023) WHERE order_date BETWEEN ‘2023-01-01’ AND ‘2023-12-31’;
这样,你就可以有效地利用MySQL的分区功能来管理大量数据,并提高查询性能。
慢查询优化
MySQL数据是怎么写的,写入的底层原理是什么,涉及到哪些主键的交互,比如innodb写入时是先写入buffer pool。
主节点崩溃:如果MySQL主节点崩溃了,数据会不会丢失。
从节点写入:主节点挂了但向客户端返回成功,怎么保证从节点数据写入进去。
数据量很大:数据量很大达到内存放不下时怎么解决。
查询优化
一、字段选择合适属性,不要过大, 并且一般设置为非NULL
二、使用索引
- 不要对数据库中某个含有大量重复的值的字段建立索引
- 在建有索引的字段上尽量不要算数运算或使用函进行操作 不然可能用不到索引
- 避免在查询中让MySQL进行自动类型转换
- 少用IN、NOT IN、<>、!=、or操作 连续数值用between
- 使用短索引
- 避免在 where 子句中对字段进行 null 值判断
- 避免在查询中让MySQL进行自动类型转换
三、查询语句 - 少回表
- 最好相同类型字段比较
- 少用like
- 拆分 比如分页join 拆分insert delete
- join替代子查询
- union
- 要limit
- count(1)
四、分库分表
如何排查 开启慢查询日志、explain
索引
比较熟 这里就不加了 需要注意还有个全文索引和哈希索引
对于 BLOB、TEXT 和 VARCHAR 类型的列,必须使用前缀索引,只索引开始的部分字符。
order_by本质也属于查询!也要加索引(联合索引)
索引下推?倒排索引?这两个没了解 暂时不搜了
语法
text和varchar区别
varchar(n)中括号中n代表字符的个数,并不代表字节个数,所以当使用了中文的时候(utf8)意味着可以插入m个中文,但是实际会占用m*3个字节。
text 的最大长度为 65,535 字节,与 varchar 相同。
mediumtext 的最大长度约为 16 兆字节。
longtext 的最大长度约为 4 gb。
另外,从官方文档中可以得知当varchar大于某些数值的时候其会自动转换为text
text是单独存储 需要再去查磁盘 而varchar可能内存中就查了
MYSQL避免重复插入、不存在插入 存在则更新的几种语句
避免重复插入
insert ignore into(有唯一索引)关键字/句: insert ignore into,如果插入的数据会导致 UNIQUE索引 或 PRIMARY KEY 发生冲突/重复,则忽略此次操作/不插入数据
当使用了insert ignore into 新增数据,即使没有插入,某些版本的mysql会自增主键。
比如原来有数据1(id为1),你又插入了数据1,但是重复了没插入,之后再插入数据2,此时的数据2的主键为3而非2.
mysql5.7.26不会自增,8.0会自增 ,但是可以修改参数设置
insert if not exists(无唯一索引)数据字段没有设置主键或唯一索引,当插入数据时,首先判断是否存在这条数据,不存在正常插入,存在则忽略。
不存在插入 存在更新
on duplicate key update
如果插入的数据会导致UNIQUE 索引或PRIMARY KEY发生冲突/重复,则执行UPDATE语句
bug在5.7.26以及8.0.15版本上已经修复了,当插入数据时,不会在形成间隙锁
但是此方法也有坑,如果表中不止一个唯一索引的话,在特定版本的mysql中容易产生dead lock(死锁)
replace into(先删除再插入)
count :count(1)、count(*)、count(列名)的区别
在innodb引擎下:按照性能排序
count(*)= count(1)>count(主键字段) >count(字段)
关于count 最明显的区别在于对null值的处理。
我们就记住 该函数作用永远是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录有多少个。
count(主键字段) 执行过程是怎样的
如果表里只有主键索引,没有二级索引时,那么,InnoDB 循环遍历聚簇索引进行加一操作,最后将结果返回。
但是,如果表里有二级索引时,InnoDB 循环遍历的对象就不是聚簇索引,而是二级索引。
这是因为相同数量的二级索引记录可以比聚簇索引记录占用更少的存储空间,所以二级索引树比聚簇索引树小,这样遍历二级索引的 1/0 成本比遍历聚簇索引的 !0 成本小,因此「优化器」优先选择的是二级索引。
count(1)
和count(主键)一样,区别是,count(1) 相比 count(主键字段) 少一个步骤,就是不需要读取记录中的字段值,所以通常会说count(1)执行效率会比 count(主键字段) 高一点。
对count的优化
如果对一张大表经常用 count()来做统计,:其实是很不好的。比如下面我这个案例,表torder 共有 1200+万条记录,我也创建了二级索引,但是执行一次 select要花费差不多 5 秒!count()from t order
如果你的业务对于统计个数不需要很精确,比如搜索引擎在搜索关键词的时候,给出的搜索结果条数是一
个大概值。
这时,我们就可以使用 show table status 或者 explain 命令来表进行估算。执行 explain 命令效率是很高的,因为它并不会真正的去査询,下图中的 rows 字段值就是 explain 命令对表 t order 记录的估算值。
limit
最好id>xxx 去查 不然emmm
时间还是时间戳
主要注意时间戳的时间范围问题
时间比较直观 但是好像时间戳也能改显示格式
时间有时区问题
分库 分表 分区
答案很简单:数据库出现性能瓶颈。用大白话来说就是数据库快扛不住了。
至于单表的数据量 单表不建议超过 500w 看另一篇博客
数据库出现性能瓶颈,对外表现有几个方面:
- 大量请求阻塞,并发性能差
在高并发场景下,大量请求都需要操作数据库,导致连接数不够了,请求处于阻塞状态。 - SQL 操作变慢(详见另一篇文章)
- 命中索引 但是b+树层太高 性能下滑。或者索引文件太大,无法加入到内存中
- 未命中索引导致全表扫描
如果数据库中存在一张上亿数据量的表,一条 SQL 没有命中索引会全表扫描,这个查询耗时会非常久。(一般小于1千万较好)
- 存储出现问题
业务量剧增,单库数据量越来越大,给存储造成巨大压力。(一般1、2T就极限了)
垂直分 水平分
分区表是什么

全局唯一id
MySQL InnoDB的表都是使用自增的主键ID,分库分表之后,数据表分布不同的分片上,如果使用自增 ID 作为主键,就会出现不同分片上的主机 ID 重复现象。
单库和多库的都存在,多库上的叫分布式全局唯一id
常用的分布式 ID 解决方案有:
UUID 不能自增 而且不一定有序 频繁变动
基于数据库自增单独维护一张 ID表
号段模式
Redis 缓存
雪花算法(Snowflake) 有序 唯一
百度uid-generator
美团Leaf
滴滴Tinyid
自增id
自增的主键的值是顺序的,所以Innodb把每一条记录都存储在一条记录的后面。当达到页面的最大填充因子时候(innodb默认的最大填充因子是页大小的15/16,会留出1/16的空间留作以后的 修改):
①下一条记录就会写入新的页中,一旦数据按照这种顺序的方式加载,主键页就会近乎于顺序地记录填满,提升了页面的最大填充率,不会有页的浪费
②新插入的行一定会在原有的最大数据行下一行,mysql定位和寻址很快,不会为计算新行的位置而做出额外的消耗
③减少了页分裂和碎片的产生
优点:
1.自增,趋势自增,可作为聚集索引,提升查询效率
2.节省磁盘空间。500W数据,UUID占5.4G,自增ID占2.5G.
3.查询,写入效率高:查询略优。在数据量大时候 高于uuid插入速度
缺点:
1.导入旧数据时,可能会ID重复,导致导入失败。
2.分布式架构,多个Mysql实例可能会导致ID重复。
3.容易被外界攻破,知道业务实际情况。且例如:显示公告内容index?id=3这样就很容易被人篡改为index?id=2.就可以调到第二条的内容。
4对于高并发的负载,innodb在按主键进行插入的时候会造成明显的锁争用,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争。Auto_Increment锁机制会造成自增锁的抢夺,有一定的性能损失
uuid 缺点看上面
自增id和业务id如何抉择
1、旧系统或者单部署系统,一般都采用自增主键,主要是便捷性考虑。优缺点如下:
优点:自增长字段往往用integer bigint类型,最多占8个字节。索引与外键 所占用的空间连带减少,增删改查 效率高。业务变化,不影响,不需要更新主键。
缺点:无法转移数据库,比如把表中的一批数据 转移 或 附带到 另一个表中,那么由于是自增长字段,那么会导致无法转移,因为另外一个表可能已经存在部分数据,会造成主键冲突。自增长字段的缺陷。业务数据的完整性,无法保证。
2、对于高并发业务型数据表,尤其是分布式部署架构,一般建议尽量使用业务主键,主要是考虑到查询效率、安全性以及分表分库等的情况,优缺点如下:
优点:可以转移数据库,最大化节省了空间,因为并没有多增加一个非业务字段做主键。可以保证业务逻辑的完整性。避免产生垃圾数据,银行就是用业务字段做主键的,虽然效率低,但是安全。
缺点:如果业务发生改变,有可能需要修改主键,举例:国家A表用身份证号做主键,然后其他很多表中的身份证号这列都是来自身份证表A中的主键(即外键),那么如果身份证号升级,比如从1代升级到2代,那么连带的表的外键 的索引 通通都得发生变化,效率极低 因为会连带更新一串用到这个外键的表,可见用业务字段做主键的话,要保证主键不经常变化 而且尽量是有序的
mysql不常用的功能以及注意
记得用utfmb4存储
json 甚至能添加json索引
mysql集群
MySQL 主从复制还有哪些模型?
主要有三种:
同步复制:MySQL 主库提交事务的线程要等待所有从库的复制成功响应,才返回客户端结果。这种方式在实际项目中,基本上没法用,原因有两个:一是性能很差,因为要复制到所有节点才返回响应;二是可用性也很差,主库和所有从库任何一个数据库出问题,都会影响业务。
异步复制(默认模型):MySQL 主库提交事务的线程并不会等待 binlog 同步到各从库,就返回客户端结果。这种模式一旦主库宕机,数据就会发生丢失。
半同步复制:MySQL 5.7 版本之后增加的一种复制方式,介于两者之间,事务线程不用等待所有的从库复制成功响应,只要一部分复制成功响应回来就行,比如一主二从的集群,只要数据成功复制到任意一个从库上,主库的事务线程就可以返回给客户端。这种半同步复制的方式,兼顾了异步复制和同步复制的优点,即使出现主库宕机,至少还有一个从库有最新的数据,不存在数据丢失的风险。
mysql主节点的binlog是同步的还是异步的
异步
mysql主节点崩溃了,数据是不是就没有了
mysql写数据时,主节点挂了,但是向客户端返回成功。怎么保证从节点数据写入进去
innodb与myisam的区别 还有哪几种
InnoDB 是 MySQL 默认的事务型存储引擎,只要在需要它不支持的特性时,才考虑使用其他存储引擎。
支持事务、mvcc 聚簇索引 在线热备份、崩溃恢复、行级锁等
myisam是早期的 设计简单,数据以紧密格式存储。对于只读数据,或者表比较小、可以容忍修复操作,则依然可以使用它。
MyISAM 支持压缩表和空间数据索引。
federated——跨节点join
memory 内存型
不同的表可以使用不同的存储引擎么 可以join么
在MySQL中,不同的表可以使用不同的存储引擎
可以join
mysql的锁机制以及通用机制
mysql的锁天生是和事务关联在一起的。当事务结束,则锁自动释放。如果你没有手动开启事务,则类似for update等语句 会随着这行sql的执行完成而自动释放
意向锁是什么
意向锁(分为意向共享锁IS、意向排他锁IX):这个是InnoDB中为了支持多粒度的锁,为了兼容行锁、表锁而设计的,使得表锁不用检查每行数据是否加锁,使用意向锁来减少表锁的检查
s和x锁区别
- 共享锁 / S锁:不同事务之间不会相互排斥、可以同时获取的锁。不会排斥其他事务来读数据,但其他事务尝试写数据时,就会出现排斥。阻止其他事务获得相同数据集的排它锁
- 排他锁 / X锁:不同事务之间会相互排斥、同时只能允许一个事务获取的锁
自旋锁和互斥锁?
互斥锁加锁失败时,会从用户态陷入到内核态,让内核帮我们切换线程,虽然简化了使用锁的难度,但是存在一定的性能开销成本。
那这个开销成本是什么呢?会有两次线程上下文切换的成本:
当线程加锁失败时,内核会把线程的状态从「运行」状态设置为「睡眠」状态,然后把 CPU 切换给其他线程运行;
接着,当锁被释放时,之前「睡眠」状态的线程会变为「就绪」状态,然后内核会在合适的时间,把 CPU 切换给该线程运行。
线程的上下文切换的是什么?当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
上下切换的耗时有大佬统计过,大概在几十纳秒到几微秒之间,如果你锁住的代码执行时间比较短,那可能上下文切换的时间都比你锁住的代码执行时间还要长。
所以,如果你能确定被锁住的代码执行时间很短,就不应该用互斥锁,而应该选用自旋锁,否则使用互斥锁。
如何加锁
SELECT ...语句正常情况下为快照读,不加锁;SELECT ... LOCK IN SHARE MODE语句为当前读,加 S 锁;SELECT ... FOR UPDATE语句为当前读,加 X 锁;- 常见的
DML语句(如 INSERT、DELETE、UPDATE)为当前读,加 X 锁; - 常见的
DDL语句(如 ALTER、CREATE 等)加表级锁,且这些语句为隐式提交,不能回滚。
间隙锁和行锁加锁时机?是干什么的
间隙锁用于在RR级别的当前读下防止幻读
加锁时机:比如范围查询(update也算查询)、非唯一索引查询、insert等情况下
行锁是 只要当前读 都需要加行锁 以及RR级别命中唯一索引的时候
行级锁是锁什么?
锁索引
使用二级索引的话 如果是X锁需要在二级索引和主键索引上各加一把锁。如果是S锁 则只锁覆盖索引
临键锁(Next-Key Lock)
行锁和间隙锁组合,同时锁住数据,并锁住数据前面的间隙Gap,左开右闭。 在PR级别下支持,而在RC级别下会退化为行锁,实际上就相当于不支持了。
非唯一索引和唯一索引有什么区别、有索引和没有索引有什么区别
如果是非唯一索引,那么你光锁住那行是没用的 因为不唯一,所以需要范围锁
而如果没有索引,那就变成表锁了
行锁有可能变成表锁么 可能死锁么
在RP级别下,可能变成“表锁”
因为InnoDB引擎的 3种行锁算法(Record Lock、Gap Lock、Next-key Lock),都是锁定的索引,当触发X锁(写锁)的where条件无索引 或 索引失效 时, 查找的方式就会变成全表扫描,也就是扫描所有的聚集索引记录
而在RR隔离级别下,需要解决不可重复读 和幻读问题, 所以在遍历扫描聚集索引记录时, 为了防止扫描过的索引被其它事务修改(不可重复读问题) 或 间隙被其它事务插入记录(幻读问题), 从而导致数据不一致, 所以MySQL的解决方案就是把所有扫描过的索引记录和间隙都锁上, 这也就 发生了我们看到的锁表!
虽然是锁“表” ,但是实际上还是锁行 只是行的范围是全部
其中,索引失效除了还包括 MySQL成本计算分析认为全表扫描成本更低时
- 禁止where条件使用无索引列进行更新/删除
这是我们最应该做到的!除了会锁表,性能也是真的不好! - 尽可能使用聚集索引进行更新/删除
这是我们能做到的最优做法! - 确实需要使用非聚集索引 进行更新/删除,需要确认:
- 使用explain检查是否会索引失效!
- 避免对 索引列 进行类型转换、函数、运算符等会造成升级的情况!
- 尽可能减少检索条件范围, 范围越大就越可能被MySQL成本计算太高,从而导致索引失效!
- 尽可能控制事务大小,减少锁定时间
- 涉及事务加锁的sql语句尽可能放在事务最后执行!
- 推荐使用读已提交(RC)事务隔离级别
这条非常重要!
对于读已提交(RC)事务隔离级别,由于没有间隙锁(Gap Lock),所以它的加锁规则相当简单,都是针对匹配索引记录加Record Lock,因为不用解决不可重复读 和幻读问题,所以也就不存在 锁表了。
死锁
条件
产生死锁的四个必要条件
互斥条件:一个资源每次只能被一个进程使用。
请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
死锁的解除与预防
打破死锁的四个必要条件中任意一个。
如何检测
show查看锁信息
SHOW 命令是一个概要信息。InnoDB 还提供了三张表来分析事务与锁的情况:
select * from information_schema.INNODB_TRX; -- 当前运行的所有事务 ,还有具体的语句
select * from information_schema.INNODB_LOCKS; -- 当前出现的锁
select * from information_schema.INNODB_LOCK_WAITS; -- 锁等待的对应关系
死锁的避免
1、 在程序中,操作多张表时,尽量以相同的顺序来访问(避免形成等待环路);
2、 批量操作单张表数据的时候,先对数据进行排序(避免形成等待环路);
3、 申请足够级别的锁,如果要操作数据,就申请排它锁;
4、 尽量使用索引访问数据,避免没有 where 条件的操作,避免锁表;
5、 如果可以,大事务化成小事务;
6、 使用等值查询而不是范围查询查询数据,命中记录,避免间隙锁对并发的影响。
存储过程是什么
MySQL 存储过程是一种将 SQL 语句组合成一个逻辑单元的数据库对象,用户可以通过 CALL 语句调用它进行操作。存储过程的最大优势是可以通过封装逻辑来简化复杂的数据库操作,减少应用程序与数据库之间的交互。
redolog与binlog
更新数据的过程
下面都是默认参数的情况下 如有改动 同步到另一篇博客中
具体更新一条记录 UPDATE t_user SET name = 'xiaolin' WHERE id = 1; 的流程如下:
- 执行器负责具体执行,会调用存储引擎的接口,通过主键索引树搜索获取 id = 1 这一行记录:
- 如果 id=1 这一行所在的数据页本来就在
buffer pool中,就直接返回给执行器更新; - 如果记录不在 buffer pool,将数据页从磁盘读入到 buffer pool,返回记录给执行器。
- 如果 id=1 这一行所在的数据页本来就在
- 执行器得到聚簇索引记录后,会看一下更新前的记录和更新后的记录是否一样:
- 如果一样的话就不进行后续更新流程;
- 如果不一样的话就把更新前的记录和更新后的记录都当作参数传给 InnoDB 层,让 InnoDB 真正的执行更新记录的操作;
- 接下来才正式开启事务:
- InnoDB 层更新记录前,首先要记录相应的 undo log,因为这是更新操作,需要把被更新的列的旧值记下来,也就是要生成一条 undo log,undo log 会写入 Buffer Pool 中的 Undo 页面
- 在内存修改该 Undo 页面后,需要记录对应的 redo log。
- InnoDB 层开始更新记录,会先更新内存(同时标记为脏页),然后将记录写到 redo log 里面,这个时候更新就算完成了。为了减少磁盘I/O,不会立即将脏页写入磁盘,后续由后台线程选择一个合适的时机将脏页写入到磁盘。这就是 WAL 技术,MySQL 的写操作并不是立刻写到磁盘上,而是先写 redo 日志,然后在合适的时间再将修改的行数据写到磁盘上。
- 至此,一条记录本身已经更新完了
- 在一条更新语句执行完成后,然后开始记录该语句对应的 binlog,此时记录的 binlog 会被保存到 binlog cache,并没有刷新到硬盘上的 binlog 文件,在事务提交时才会统一将该事务运行过程中的所有 binlog 刷新到硬盘。
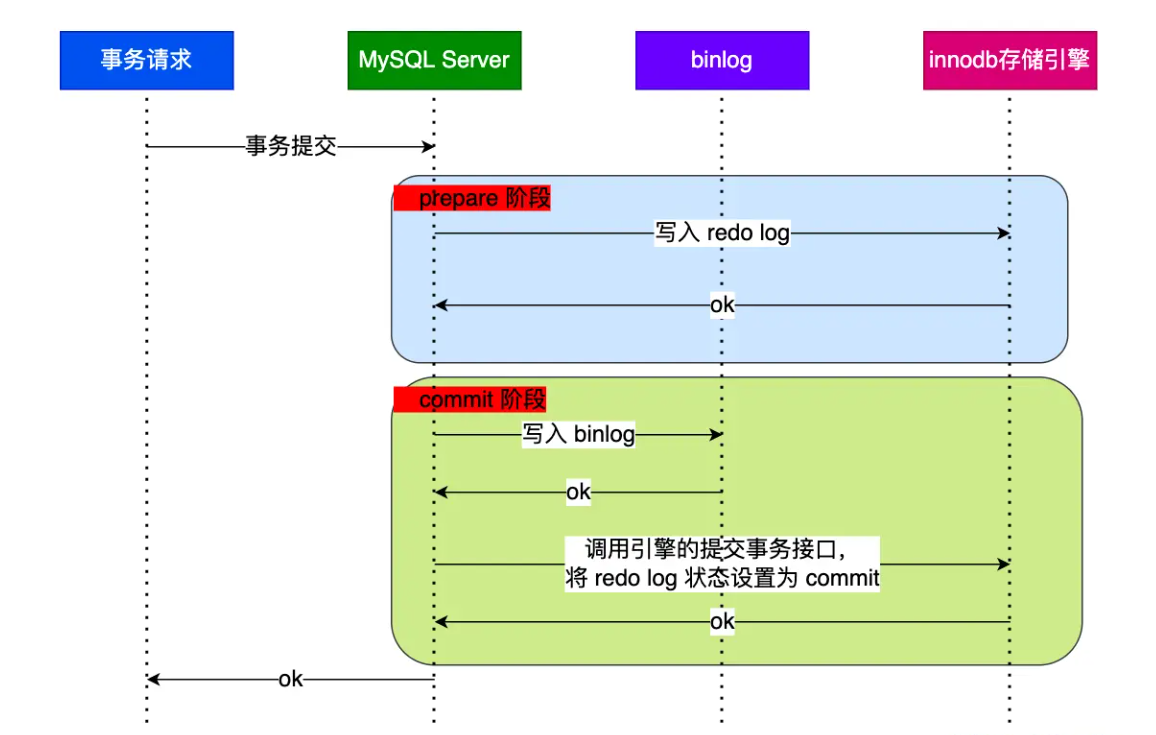
- 接下来开始事务提交阶段:
- 为了方便说明,这里不说组提交的过程,只说两阶段提交):
prepare 阶段:将 redo log 对应的事务状态设置为 prepare,然后将 redo log 刷新到硬盘;
commit 阶段:将 binlog 刷新到磁盘,接着调用引擎的提交事务接口,将 redo log 状态设置为 commit(将事务设置为 commit 状态后,刷入到磁盘 redo log 文件); - 至此,一条更新语句执行彻底完成。
redolog、binlog、undolog有什么区别(简要)
redolog 用于宕机恢复 redo log 是物理日志,记录了某个数据页做了什么修改,比如对 XXX 表空间中的 YYY 数据页 ZZZ 偏移量的地方做了AAA 更新
binlog 用于备份和主从同步
undolog用于事务回滚与mvcc机制
Buffer Pool与WAL
为了增加性能 注意 buffer pool与查询缓存不一样
缓存池存的是页 页是磁盘和内存交互的基本单位
- 当读取数据时,如果数据存在于 Buffer Pool 中,客户端就会直接读取 Buffer Pool 中的数据,否则再去磁盘中读取。
- 当修改数据时,如果数据存在于 Buffer Pool 中,那直接修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页(该页的内存数据和磁盘上的数据已经不一致),为了减少磁盘I/O,不会立即将脏页写入磁盘,后续由后台线程选择一个合适的时机将脏页写入到磁盘。

WAL (Write-Ahead Logging)
Buffer Pool 是提高了读写效率没错,但是问题来了,Buffer Pool 是基于内存的,而内存总是不可靠,万一断电重启,还没来得及落盘的脏页数据就会丢失。
所以,我们想到,在更改数据项内存的同时,将我们所做的操作,以日志的方式顺序写到磁盘中,这样如果内存崩溃,就可以根据日志去恢复数据,虽然是涉及磁盘操作,但是由于只记录操作命令本身,且是顺序写,不涉及数据库复杂的那些操作,对性能影响很小。
而这种日志就是redo log 和binlog。
redo log 要写到磁盘,数据也要写磁盘,为什么要多此一举?
redolog是顺序写 数据是随机写
修改 Undo 页面,需要记录对应 redo log 吗?
需要的。
因为undo log也要实现持久性的保护。
产生的 redo log 是直接写入磁盘的吗
也不是 redo log 也有自己的缓存—— redo log buffer,每当产生一条 redo log 时,会先写入到 redo log buffer,后续在持久化到磁盘
redo log 什么时候刷盘?如果追求性能 怎么改
如有改动 同步到另一篇博客中
缓存在 redo log buffer 里的 redo log 还是在内存中,它什么时候刷新到磁盘?
主要有下面几个时机:
- MySQL 正常关闭时;
- 当 redo log buffer 中记录的写入量大于 redo log buffer 内存空间的一半时,会触发落盘;
- InnoDB 的后台线程每隔 1 秒,将 redo log buffer 持久化到磁盘。
- 每次事务提交时都将缓存在 redo log buffer 里的 redo log 直接持久化到磁盘(这个策略可由 innodb_flush_log_at_trx_commit 参数控制
除此之外,InnoDB 还提供了另外两种策略,由参数 innodb_flush_log_at_trx_commit 参数控制,可取的值有:0、1、2,默认值为 1,这三个值分别代表的策略如下:
当设置该参数为 0 时,表示每次事务提交时 ,还是将 redo log 留在 redo log buffer 中 ,该模式下在事务提交时不会主动触发写入磁盘的操作。
当设置该参数为 1 时,表示每次事务提交时,都将缓存在 redo log buffer 里的 redo log 直接持久化到磁盘,这样可以保证 MySQL 异常重启之后数据不会丢失。
当设置该参数为 2 时,表示每次事务提交时,都只是缓存在 redo log buffer 里的 redo log 写到 redo log 文件,注意写入到「 redo log 文件」并不意味着写入到了磁盘,因为操作系统的文件系统中有个 Page Cache(如果你想了解 Page Cache,可以看这篇 (opens new window)),Page Cache 是专门用来缓存文件数据的,所以写入「 redo log文件」意味着写入到了操作系统的文件缓存。
redo log 文件写满了怎么办?
两个文件组,环形写
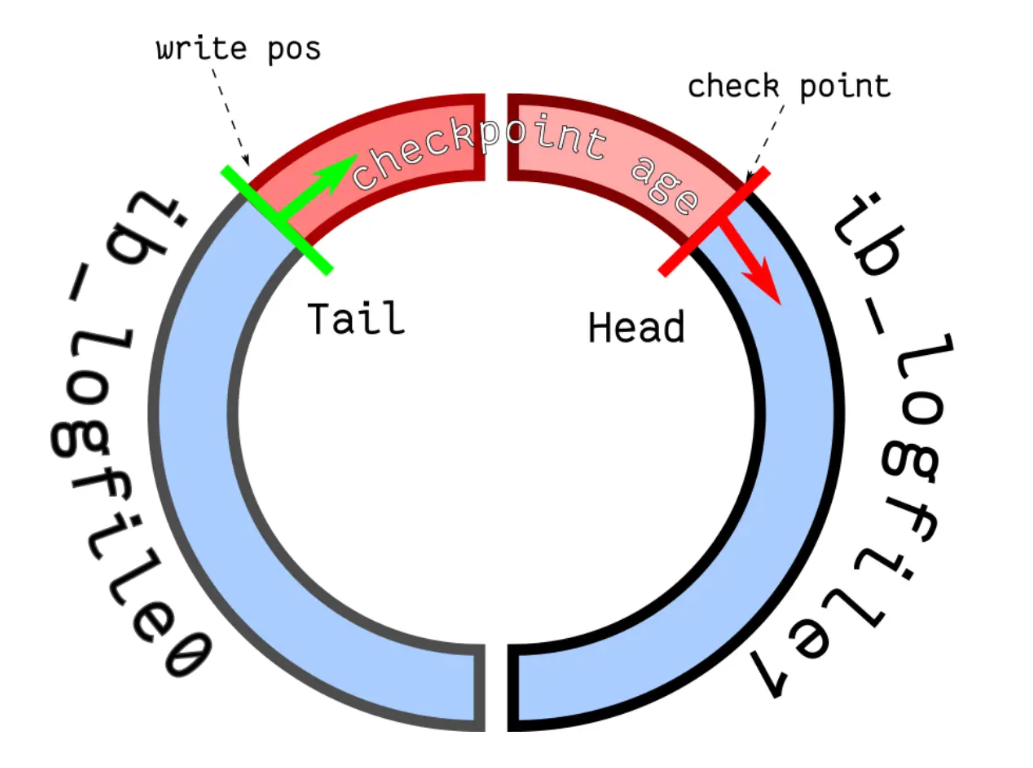
没必要全部保存 因为是宕机恢复的 既然过去了没问题 也就没留下的必要了
讲讲binlog
为什么有了 binlog, 还要有 redo log?
这个问题跟 MySQL 的时间线有关系。
最开始 MySQL 里并没有 InnoDB 引擎,MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。
用来备份和主从同步
binlog 有 3 种格式类型,分别是 STATEMENT(默认格式)、ROW、 MIXED
STATEMENT 逻辑日志 记录语句 会出现动态函数不一致问题 以及必须可重复读级别问题
ROW:记录行数据最终被修改成什么样了(这种格式的日志,就不能称为逻辑日志了)
MIXED:包含了 STATEMENT 和 ROW 模式,它会根据不同的情况自动使用 ROW 模式和 STATEMENT 模式;
binlog 是追加写,写满一个文件,就创建一个新的文件继续写,不会覆盖以前的日志,保存的是全量的日志
binlog是事务提交后才写 和redolog感觉随时都在写不一样
binglog什么时候刷盘
MySQL提供一个 sync_binlog 参数来控制数据库的 binlog 刷到磁盘上的频率:
sync_binlog = 0 的时候,表示每次提交事务都只 write,不 fsync,后续交由操作系统决定何时将数据持久化到磁盘;
sync_binlog = 1 的时候,表示每次提交事务都会 write,然后马上执行 fsync;
sync_binlog =N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
relaylog
MySQL 主库在收到客户端提交事务的请求之后,会先写入 binlog,再提交事务,更新存储引擎中的数据,事务提交完成后,返回给客户端“操作成功”的响应。
从库会创建一个专门的 I/O 线程,连接主库的 log dump 线程,来接收主库的 binlog 日志,再把 binlog 信息写入 relay log 的中继日志里,再返回给主库“复制成功”的响应。
从库会创建一个用于回放 binlog 的线程,去读 relay log 中继日志,然后回放 binlog 更新存储引擎中的数据,最终实现主从的数据一致性。
两阶段写
事务提交后,redo log 和 binlog 都要持久化到磁盘,但是这两个是独立的逻辑,可能出现半成功的状态,这样就造成两份日志之间的逻辑不一致。
两阶段提交有什么问题?
如有改动 同步到另一篇博客中
两阶段提交虽然保证了两个日志文件的数据一致性,但是性能很差,主要有两个方面的影响:
- 磁盘 I/O 次数高:对于“双1”配置,每个事务提交都会进行两次 fsync(刷盘),一次是 redo log 刷盘,另一次是 binlog 刷盘。
- 锁竞争激烈:两阶段提交虽然能够保证「单事务」两个日志的内容一致,但在「多事务」的情况下,却不能保证两者的提交顺序一致,因此,在两阶段提交的流程基础上,还需要加一个锁来保证提交的原子性,从而保证多事务的情况下,两个日志的提交顺序一致。
为什么两阶段提交的磁盘 I/O 次数会很高?
binlog 和 redo log 在内存中都对应的缓存空间,binlog 会缓存在 binlog cache,redo log 会缓存在 redo log buffer,它们持久化到磁盘的时机分别由下面这两个参数控制。一般我们为了避免日志丢失的风险,会将这两个参数设置为 1:
- 当 sync_binlog = 1 的时候,表示每次提交事务都会将 binlog cache 里的 binlog 直接持久到磁盘;
- 当 innodb_flush_log_at_trx_commit = 1 时,表示每次事务提交时,都将缓存在 redo log buffer 里的 redo log 直接持久化到磁盘;
可以看到,如果 sync_binlog 和 当 innodb_flush_log_at_trx_commit 都设置为 1,那么在每个事务提交过程中, 都会至少调用 2 次刷盘操作,一次是 redo log 刷盘,一次是 binlog 落盘,所以这会成为性能瓶颈。
可以看到,如果 sync_binlog 和 当 innodb_flush_log_at_trx_commit 都设置为 1,那么在每个事务提交过程中, 都会至少调用 2 次刷盘操作,一次是 redo log 刷盘,一次是 binlog 落盘,所以这会成为性能瓶颈。
为什么锁竞争激烈?
在早期的 MySQL 版本中,通过使用 prepare_commit_mutex 锁来保证事务提交的顺序,在一个事务获取到锁时才能进入 prepare 阶段,一直到 commit 阶段结束才能释放锁,下个事务才可以继续进行 prepare 操作。
通过加锁虽然完美地解决了顺序一致性的问题,但在并发量较大的时候,就会导致对锁的争用,性能不佳。
什么是组提交
如有改动 同步到另一篇博客中
binlog组提交
MySQL 引入了 binlog 组提交(group commit)机制,当有多个事务提交的时候,会将多个 binlog 刷盘操作合并成一个,从而减少磁盘 I/O 的次数,如果说 10 个事务依次排队刷盘的时间成本是 10,那么将这 10 个事务一次性一起刷盘的时间成本则近似于 1。
引入了组提交机制后,prepare 阶段不变,只针对 commit 阶段,将 commit 阶段拆分为三个过程:
flush 阶段:多个事务按进入的顺序将 binlog 从 cache 写入文件(不刷盘);
sync 阶段:对 binlog 文件做 fsync 操作(多个事务的 binlog 合并一次刷盘);
commit 阶段:各个事务按顺序做 InnoDB commit 操作;
redolog组提交
有 binlog 组提交,那有 redo log 组提交吗?
这个要看 MySQL 版本,MySQL 5.6 没有 redo log 组提交,MySQL 5.7 有 redo log 组提交。
在 MySQL 5.6 的组提交逻辑中,每个事务各自执行 prepare 阶段,也就是各自将 redo log 刷盘,这样就没办法对 redo log 进行组提交。
所以在 MySQL 5.7 版本中,做了个改进,在 prepare 阶段不再让事务各自执行 redo log 刷盘操作,而是推迟到组提交的 flush 阶段,也就是说 prepare 阶段融合在了 flush 阶段。
这个优化是将 redo log 的刷盘延迟到了 flush 阶段之中,sync 阶段之前。通过延迟写 redo log 的方式,为 redolog 做了一次组写入,这样 binlog 和 redo log 都进行了优化。
MySQL 磁盘 I/O 很高,有什么优化的方法?
如有改动 同步到另一篇博客中
现在我们知道事务在提交的时候,需要将 binlog 和 redo log 持久化到磁盘,那么如果出现 MySQL 磁盘 I/O 很高的现象,我们可以通过控制以下参数,来 “延迟” binlog 和 redo log 刷盘的时机,从而降低磁盘 I/O 的频率:
- 设置组提交的两个参数: binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 参数,延迟 binlog 刷盘的时机,从而减少 binlog 的刷盘次数。这个方法是基于“额外的故意等待”来实现的,因此可能会增加语句的响应时间,但即使 MySQL 进程中途挂了,也没有丢失数据的风险,因为 binlog 早被写入到 page cache 了,只要系统没有宕机,缓存在 page cache 里的 binlog 就会被持久化到磁盘。
- 将 sync_binlog 设置为大于 1 的值(比较常见是 100~1000),表示每次提交事务都 write,但累积 N 个事务后才 fsync,相当于延迟了 binlog 刷盘的时机。但是这样做的风险是,主机掉电时会丢 N 个事务的 binlog 日志。
- 将 innodb_flush_log_at_trx_commit 设置为 2。表示每次事务提交时,都只是缓存在 redo log buffer 里的 redo log 写到 redo log 文件,注意写入到「 redo log 文件」并不意味着写入到了磁盘,因为操作系统的文件系统中有个 Page Cache,专门用来缓存文件数据的,所以写入「 redo log文件」意味着写入到了操作系统的文件缓存,然后交由操作系统控制持久化到磁盘的时机。但是这样做的风险是,主机掉电的时候会丢数据。
redolog更多面试题
redo log 为什么可以保证crash safe机制.
binlog的概念是什么, 起到什么作用, 可以做crash safe吗?
binlog和redolog的不同点有哪些?
物理一致性和逻辑一致性各应该怎么理解?
什么是两阶段提交, 为什么需要两阶段提交, 两阶段提交怎么保证数据库中两份日志间的逻辑一致性(什么叫逻辑一致性)?
如果不是两阶段提交, 先写redo log和先写bin log两种情况各会遇到什么问题?
100G内存下,MySQL查询200G大表会OOM么?mysql是如何发送数据的【网易终面】
有个缓冲区,类似内存写到硬盘那样
这种大查询的情况,每次缓冲区满了,就通过网络发送,循环 所以不会oom 是边读边发的
全表扫描还是比较耗费IO资源的,所以业务高峰期还是不能直接在线上主库执行全表扫描的。
服务端查询后的结果集发送给客户端,客户端(客户端的查询引擎,例如mysqind)必须完整的接受,才会释放服务端的内存缓存,所以,如果只需要少数行,记得在sql语句添加使用limit,少用select*。
游标是什么
1,普通方式是一条sql过去,服务器把数据全部返回给你,还有一种方式是
2,游标方式,游标方式会在服务器端找到要查询的数据,然后分批次返回给你,这种方式适合要操作大量操作数据的场景,服务器给我一条,我处理一条,然后直到循环处理结束,客户端不会一次接受到全部的数据
mysql如何进行大量数据迁移
- 逻辑迁移 就是纯代码层面
- mysqldump
- 直接insert into insert into tb_user select * from tb_user_source;
- 文件迁移
- txt迁移法load data infile ‘/var/lib/mysql-files/1.txt’ into table s3.s1;
- 直接迁移数据文件ibd 也叫表空间
ALTER TABLE t1 IMPORT TABLESPACE:
- 外部组件
- Canal
缓存 redis
自旋锁的本质是什么 Redis自旋锁如何实现(字节)
分布式锁(包括zookeeper)
单机方案
setex(setnx+存在时间)
防止锁被误删:时间戳+随机值
防止释放别人的锁:释放锁的核心逻辑【GET、判断、DEL】,写成 Lua 脚本
防止锁过期:要么时间延长 要么watchdog自动延时的看门狗机制
集群方案
嘿嘿,上面redis这些都是锁在「单个」Redis 实例中可能产生的问题,确实单节点分布式锁能解决大部分人的需求。但是通常都是用【Redis Cluster】或者【哨兵模式】这两种方式实现 Redis 的高可用,这就有主从同步问题发生。
- 由于可能存在主从延时,而且必须要循环get获取锁信息,而get操作每次都要读主库,造成主库压力增加,性能降低。
- 还是由于主从同步问题,以及异步同步模型,假设master挂了,加锁信息还没同步到从库上,这时候新上任的master由于没收到前任master的锁信息,则这个锁信息就丢失了
针对问题2,Redis 的作者提供了RedLock 的算法来实现一个分布式锁
针对问题1和问题2,推荐用zookeeper实现
zookeeper如何实现 以及为什么zookeeper就不会出问题
如有改动 同步到文章中
看另一篇文章,这里是简要版
zookeeper官方推荐的分布式锁的实现步骤如下:
- 客户端调用create命令创建一个临时顺序节点(create -s -e locks/lock-)
- 客户端通过getChildren方法查看locks节点下子节点情况
- 如果locks节点下所有子节点的最小序号节点等于步骤1中创建操作返回的临时顺序节点的序号,说明获取锁成功。
- 否则就用exists命令判断小于自己创建节点序号的上一个节点是否存在,并watch此节点变化。
- 如果节点存在,等待节点删除时间的通知,受到通知后跳转到步骤2重新执行。如果节点不存在直接跳转到步骤2执行。
以下场景中Client1和Client2在窗口时间内可能同时获得锁:
Client 1 创建了 znode 节点/lock,获得了锁。
Client 1 进入了长时间的 GC pause。(或者网络出现问题、或者 zk 服务检测心跳线程出现问题等等)
Client 1 连接到 ZooKeeper 的 Session 过期了。znode 节点/lock 被自动删除。
Client 2 创建了 znode 节点/lock,从而获得了锁。
Client 1 从 GC pause 中恢复过来,它仍然认为自己持有锁。
不过很少见吧
和redis实现分布式锁的区别 为什么zookeeper能实现
- watch机制不同 redis的watch一个是它只能用在事务中,另一个是必须被其他客户端修改,自身的变动不算 而zookeeper的 被自己修改 或者到期了 也算变动
- 由于watch机制 所以虽然zookeeper的set性能更低 但是watch避免了多次轮询。如果后面redis能实现zoo的watch机制 也会好很多 但是redis的定位是缓存 不是专门的分布式套件
- 顺序临时节点机制,无需关注锁的时间 以及使得读操作可以读从库,因为你新建顺序临时节点的时候会告诉你分配的号码是多少,从而能够判断主从同步进度
- 由于zookeeper 需要一半的节点返回ack才会提交,其主从同步更接近同步模型比redis这种异步同步模型更加注重一致性。只有leader还没发送proposal就挂掉这种情况会丢数据,但是这时候写操作也并未成功,所以比redis数据更加一致。降低了写的性能,在写入阶段挂掉的话会抛出异常通知代码调用者 所以比redis优在这里。
相比redis方案的优缺点
Zookeeper 的优点:
- 临时节点,不需要考虑锁的过期时间,使用起来比较方便
- 顺序节点 新建顺序临时节点的时候会告诉你分配的号码是多少,从而能够判断主从同步进度
- watch 机制,加锁失败,可以 watch 等待锁释放,实现乐观锁。而且无需轮询。
- 解决了不能读从库的问题(watch机制 以及顺序节点机制 )。zookeeper的写有强一致性,虽然zookeeper的读操作并不保证强一致性,但是在这个方案中,不存在问题,详情看另一篇博客
- 高可用性:Zookeeper通过选举机制实现高可用性,即使部分节点失败,系统仍然可以正常运行。
- 有序性:Zookeeper支持有序节点,这有助于实现公平锁,也就是根据先来后到获取锁。
缺点:
- 性能不如 Redis,而且Zookeeper在处理大量写操作时可能会有更高的延迟和更大的开销(为了保证一致性,写入需要半数以上的从库成功写入后)
- 部署和运维成本高 需要更多的配置和维护。
- 客户端与 Zookeeper 的长时间失联,锁被释放问题
- 实现相对复杂
高并发和主从同步场景的区别
高并发 加锁解锁在同一个步骤里
主从延迟 :主库中设置一个key 然后读取主redis 如果不对就提示用户稍后刷新查看
redis之消息队列
list
list:通过 RPUSH/LPOP 或者 LPUSH/RPOP 即可实现简易版消息队列
不用sleep的话就用BRPOP或者BLPOP
- 不支持重复消费:消费者拉取消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费,即不支持多个消费者消费同一批数据
- 消息丢失:消费者拉取到消息后,如果发生异常宕机,那这条消息就丢失了
第一个问题是功能上的,使用 List 做消息队列,它仅仅支持最简单的,一组生产者对应一组消费者,不能满足多组生产者和消费者的业务场景。
第二个问题就比较棘手了,因为从 List 中 POP 一条消息出来后,这条消息就会立即从链表中删除了。也就是说,无论消费者是否处理成功,这条消息都没办法再次消费了。
pub/sub
pub/sub主题订阅者模式,可以实现 1:N 的广播消息队列。以及生产一次消费多次。
List 其实是属于「拉」模型,而 Pub/Sub 其实属于「推」模型。
List 中的数据可以一直积压在内存中,消费者什么时候来「拉」都可以。
Pub/Sub 是把消息先「推」到消费者在 Redis Server 上的缓冲区中,然后等消费者再来取。
主要是可能丢消息:
- 客户端宕机,客户端无法接收消息
- Redis服务宕机,没有客户端能连接上,肯定也无法接收到消息。因为 Pub/Sub 没有基于任何数据类型实现,所以它也不具备「数据持久化」的能力。
- 消费者必须先订阅队列,生产者才能发布消息,否则消息会丢失。
- 消息堆积 超过了缓冲区配置的上限,此时,Redis 就会「强制」把这个消费者踢下线。
stream
stream满足了那些消息队列的要求?
- 支持「阻塞式」拉取消息
- 支持发布 / 订阅模式
- 消息处理时异常,Stream 可以保证消息不丢失,重新消费 ack机制
- Stream 数据会写入到 RDB 和 AOF 做持久化
- 消息堆积时,和pub完全无法接受消息不同,Stream会丢弃旧消息,只保留固定长度的新消息,但是新的可以继续发
不满足的点:
一个专业的消息队列,必须要做到两大块:
- 消息不丢
- 生产者会不会丢消息?
- 消费者会不会丢消息?
- 队列中间件会不会丢消息?可能:专业的消息队列是集群备份的 而且选举机制
- AOF 持久化配置为每秒写盘,但这个写盘过程是异步的,Redis 宕机时会存在数据丢失的可能
- 主从复制也是异步的,主从切换时,也存在丢失数据的可能(从库还未同步完成主库发来的数据,就被提成主库)
- 消息可堆积:redis毕竟是内存型 无法和专业的对比
延时队列
用zset实现 for循环符合条件的
redis事务
实现事务有哪些方式
- redis命令 MULTI、EXEC、DISCARD、WATCH
- lua脚本
Redis事务支持回滚吗
不支持回滚
看到这里 我们可能觉得奇怪,redis不是有discard命令么?为什么说它不支持回滚呢?
区别在于,redis是内存型数据库,它没有mysql那种复杂的mvcc的设计,所以不支持回滚。
redis的事务和mysql事务的执行有很大区别,redis的事务是将命令串行加入一个缓存队列中,它此刻并没有真正执行,而是当你使用exec提交的时候,它才真正开始执行!只保证命令中途不被其他命令插入。
事务发生错误时Redis是怎么处理的?
- 组队过程中输入了错误的命令导致组队失败,整个命令队列被取消,一个都不执行
- 组队结束后使用exec其中有一条或多条命令执行失败,则报错的命令不执行,其他的正常执行
其中1是 比如你set key1 结果后面没有输入value 这种错误不运行阶段就能发现
2是,比如你对一个string类型的变量执行incr操作,这种只有运行的时候能够发现
redis watch
Redis Watch 命令用于监视一个(或多个) key ,如果watch命令之后开启的第一个事务,在使用exec执行命令之前,这个(或这些) key 被其他命令所改动,那么事务将回滚或者取消执行,并且通过exec函数告知执行失败。
一旦exec,之前加的所有watch全部失效。
redis本身实现watch的底层方案是乐观锁。
watch的特性可以实现分布式锁,详见另一篇文章
在任何对数据库键空间(key space)进行修改的命令成功执行之后 (比如FLUSHDB、SET、DEL、LPUSH、SADD、ZREM,诸如此类),multi.c/touchWatchedKey函数都会被调用 —— 它检查数据库的watched_keys字典, 看是否有客户端在监视已经被命令修改的键, 如果有的话, 程序将所有监视这个/这些被修改键的客户端的REDIS_DIRTY_CAS选项打开:
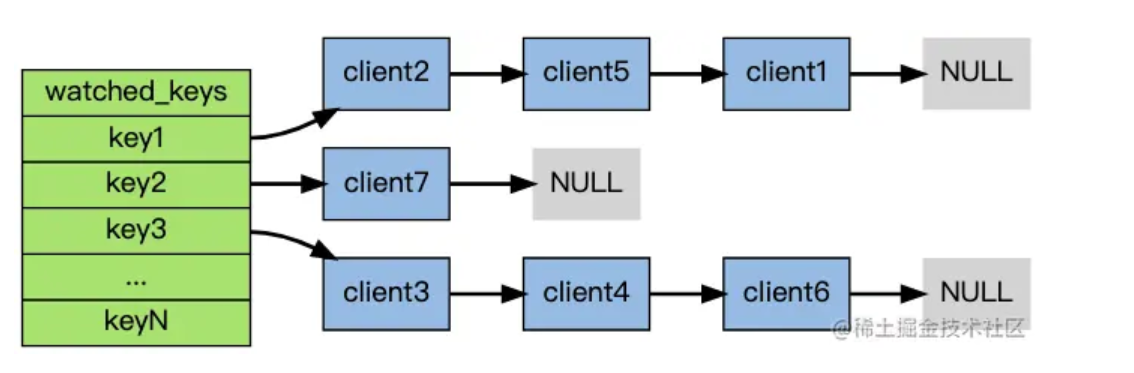
Redis 事务能保证一致性吗?
-
语法错误
发生语法错误可以保证 数据库一致性。
按照一致性的基本概念:事务执行完成后,数据库从一个一致性状态变为另一个一致性状态。假设事务操作过程中命令出现语法错误,那么 Redis 就会自动放弃事务的执行,这时候数据库的状态是没变化的,所以保证了一致性。 -
运行错误
发生运行错误可以保证数据库的一致性。
在发生运行错误的情况下,正确的命令会被成功执行,错误的命令会执行失败,虽然没法保证原子性,但是数据库确实从一个状态变为了另一个状态,所以这种情况也是能保证数据库的一致性的。 -
Redis 宕机
如果没开启 RDB 或者 AOF 做数据的持久化,也能保证一致性。
如果没开启持久化机制,Redis 宕机后重启数据全都没了,那么也是从一个一致性状态到了另一个一致性状态,这个没毛病。
如果开启了 RDB 没开启 AOF ,也能保证一致性。
因为 RDB 在事务执行期间是不会执行的,所以 Redis 宕机后重启恢复的数据也是恢复事务之前的数据,自然也就保持了数据库的一致性。
如果开启了 AOF 没开启 RDB ,也能保证一致性。
假设在 Redis 发生宕机时,事务操作还没被记录到 AOF 中,那么使用 AOF 日志恢复的数据库数据是一致的;如果部分事务操作已经被记录到 AOF 日志中了,那么使用 redis-check-aof 就可以清除事务中已经完成的操作,数据库恢复后也是一致的。
Redis 事务能保证隔离性吗?
Redis 使用单线程的方式来执行事务以及事务队列中的命令,并且服务器保证在执行事务期间不会让事务中断,因此 Redis 的事务总是以串行化的方式运行的,并且保证事务也是具有隔离性的。
Redis 事务能保证持久性吗?
如果没开启 RDB 或者 AOF 持久化,那无法保证事务的持久性,即使开启了持久化机制,也无法保证数据不丢失,所以也无法保证事务的持久性。
watch是什么锁
乐观锁
数据库和缓存如何保证一致性?先写缓存还是先写数据库
1、想要提高应用的性能,可以引入「缓存」来解决。记住这点,缓存主要是为了提高性能,所以一般不要去费力去做强一致性,我们追求最终一致性即可。下面大多数高并发下数据不一致的情况都可以分布式锁解决,但是严重影响性能。
2、引入缓存后,需要考虑缓存和数据库一致性问题,可选的方案有:「更新数据库 + 更新缓存」、「更新数据库 + 删除缓存」。但是无论哪种方案,都需要设置缓存过期时间兜底。
3、更新数据库 + 更新缓存方案,在「并发」场景下无法保证缓存和数据一致性,解决方案是加「分布锁」,但这种方案存在「缓存资源浪费」和「机器性能浪费」的情况。而且也无法保证原子性。
但是优点是缓存命中率高和实现简单。如果我们的业务对缓存命中率有很高的要求,我们可以采用「先更新数据库,再更新缓存」的方案,因为更新缓存并不会出现缓存未命中的情况。
4、采用「先删除缓存,再更新数据库」方案,在「并发」场景下依旧有不一致问题,解决方案是「延迟双删」,但这个延迟时间很难评估。而且也无法保证原子性。以及存在缓存击穿的情况。
5、采用「先更新数据库,再删除缓存」方案,通常情况下不会在高并发环境下出问题,为了保证两步都成功执行,需配合「消息队列」或「订阅变更日志」的方案来做,本质是通过「重试」的方式保证数据最终一致。
6、采用「先更新数据库,再删除缓存」,「读写分离 + 主从库延迟」也会导致缓存和数据库不一致,缓解此问题的方案是「延迟双删」,凭借经验发送「延迟消息」到队列中,延迟删除缓存,同时也要控制主从库延迟,尽可能降低不一致发生的概率。以及存在缓存击穿的情况。
7、旁路缓存策略,为了应对缓存穿透问题,可以⽤缓存空结果、布隆过滤器进⾏解决。
8、为了避免缓存击穿,如果删除的是热门数据,那么建议采用不直接删除,而是设置一个较短的生命周期。业务方在获取数据的时候,告诉它这是一个旧数据,是否使用由你来决定
9、原子操作一般来说 不太会失败 所以如果项目要求不是特别高 就算了
其他需要注意的问题:
- redis:k-v大小的合理设置:Redis key大小设计: 由于⽹络的⼀次传输MTU最⼤为1500字节,所以为了保证⾼效的性能,建议单个k-v⼤⼩不超过1KB,⼀次 ⽹络传输就能完成,避免多次⽹络交互;k-v是越⼩性能越好
- Redis 热key:(1) 当业务遇到单个读热key,通过增加副本来提⾼读能⼒或是⽤hashtag把key存多份在 多个分⽚中;(2)当业务遇到单个写热key,需业务拆分这个key的功能,属于设计不合理-当业务遇到热分片,即多个热key在同⼀个分片上导致单分片cpu⾼,可通过hashtag⽅式打散
- redis其他问题

- 机器故障问题
所以,最终推荐的策略是:
先更新数据库,再删除缓存。
首先缓存需要过期时间来兜底
其中,删除缓存用cannal+订阅binlog+延时队列来做。
同时 ,应用布隆过滤器来或者短时缓存空结果来解决缓存击穿问题,以及可以参考在删除的时候,如果判定这是一个热门数据,那么不直接删,而是将它的生命周期设置的更短些,比如 10 到 30 秒,然后业务方在调用的时候会表明这是一个脏数据。至于你要不要用,则交给业务方进行判断。
一些机制
缓存穿透、击穿、雪崩出现的原因与常用解决办法

缓存穿透(原本不存在) 还有一点就是 如果大量的key 要看看是不是非法请求,不然 一般不会出现这么多空的
缓存击穿:是先存在 后不存在
如果有大量的key需要设置同一时间过期,一般需要注意什么?
如果大量的key过期时间设置的过于集中,到过期的那个时间点,Redis可能会出现短暂的卡顿现象。严重的话会出现缓存雪崩,我们一般需要在时间上加一个随机值,使得过期时间分散一些。
电商首页经常会使用定时任务刷新缓存,可能大量的数据失效时间都十分集中,如果失效时间一样,又刚好在失效的时间点大量用户涌入,就有可能造成缓存雪崩
过期策略
定期删除+惰性删除
所谓定期删除,Redis会将所有设置了过期时间的key放入一个字典中,然后每隔一段时间从字典中随机一些key检查其是否过期,如果过期就删除。如果这次刚好超过25%的key过期,则重复。
注意,这里不是每隔100ms就遍历所有的设置过期时间的key,那样就是一场性能上的灾难。
实际上redis是每隔100ms随机抽取一些key来检查和删除的。
同时,为了保证不出现循环过度的情况,Redis还设置了扫描的时间上限,默认不会超过25ms。
惰性删除:在你获取某个key的时候,redis会检查一下 ,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。
内存淘汰机制
一般这几种
最近最少使用或者最近最不常用
设置了过期时间的key随机删除
设置了过期时间的key 删除最短的
大key的影响以及多大合适
由于redis单线程 可能会阻塞
redis-cli 的bigkeys 命令,可以帮助我们找到这些大key
删除大key用 unlink 命令(Redis 4.0+)因为该命令的删除过程是异步的,不会阻塞主线程。
key的大小多少合适
由于⽹络的⼀次传输MTU最⼤为1500字节,所以为了保证⾼效的性能,建议单个k-v⼤⼩不超过1KB,⼀次 ⽹络传输就能完成,避免多次⽹络交互;k-v是越⼩性能越好
keys和scan
使用keys指令可以扫出指定模式的key列表。
对方接着追问:如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
这个时候你要回答Redis关键的一个特性:Redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
不过,增量式迭代命令也不是没有缺点的:举个例子, 使用 SMEMBERS 命令可以返回集合键当前包含的所有元素, 但是对于 SCAN 这类增量式迭代命令来说, 因为在对键进行增量式迭代的过程中, 键可能会被修改, 所以增量式迭代命令只能对被返回的元素提供有限的保证 。
redis是单线程么
早期是 后面变成多线程
但是基础的读取设置key还是单线程 ,增加的线程主要处理类似快照 aof unlink大key等
为什么redis这么快
- 内存型
- 多路复用epoll机制
- Redis 采用单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题。
热key问题
在Redis这类分布式缓存系统中,热Key(Hot Key)是指在特定时间窗口内被大量并发访问的同一个键值对。简单来说,就是某个Key突然间"火"了,吸引了系统中大部分的访问流量。
典型热Key场景:
社交媒体热点事件:如明星官宣结婚、重大新闻爆发时的相关信息查询
大型活动直播:世界杯、奥运会等赛事实时数据
电商促销活动:双十一秒杀、限时抢购商品信息
游戏热点资源:新版本上线时的游戏道具、角色数据
技术层面影响:
服务器资源耗尽:单个Redis节点的CPU使用率飙升至100%
网络带宽瓶颈:大量请求涌向同一个节点,导致网络拥塞
连接池耗尽:客户端连接资源被快速消耗
缓存穿透加剧:热Key失效时可能导致大量请求击穿缓存,直接冲击数据库
业务层面影响:
用户体验恶化:响应时间延长,甚至请求超时
功能性宕机:特定功能无法访问(如微博明星相关内容无法查看)
连锁反应:一个组件的问题可能导致整个系统的级联故障
业务损失:电商平台在促销高峰期的性能问题可能直接转化为销售损失
如何发现:
- 打点 日志 中间层等分析
- redis 4+自带的 hotkeys命令 使用该方案的前提条件是 Redis Server 的 maxmemory-policy 参数设置为 LFU 算法
- MONITOR 命令是 Redis 提供的一种实时查看 Redis 的所有操作的方式,可以用于临时监控 Redis 实例的操作情况,包括读写、删除等操作。由于该命令对 Redis 性能的影响比较大,因此禁止长时间开启 MONITOR。在发生紧急情况时,我们可以选择在合适的时机短暂执行 MONITOR 命令并将输出重定向至文件,在关闭 MONITOR 命令后通过对文件中请求进行归类分析即可找出这段时间中的 hotkey。
- 开源项目 比如 京东零售的 hotkey 这个项目不光支持 hotkey 的发现,还支持 hotkey 的处理。
- 公有云的 Redis 分析服务
如何解决
- 首先是提前预判,以及业务拆分这个key的功能
- 读写分离:主节点处理写请求,从节点处理读请求。
- 使用 Redis Cluster:将热点数据分散存储在多个 Redis 节点上。
- 将一个Key拆分成多个子Key 在通过String routeKey = originalKey + “:” + (userId % 10);类似这样访问
- 二级缓存:hotkey 采用二级缓存的方式进行处理,将 hotkey 存放一份到语言的缓存种 比如go java
- 前端缓存层
- 浏览器缓存:利用HTTP缓存机制(Cache-Control、ETag等)减少请求
- CDN就近缓存:将静态资源和热点数据缓存在离用户最近的节点
- App本地缓存:移动应用中实现本地数据缓存和定时更新机制
- 限流与排队机制
- 告警以及自动处理机制 比如自动扩容等
redis高级应用
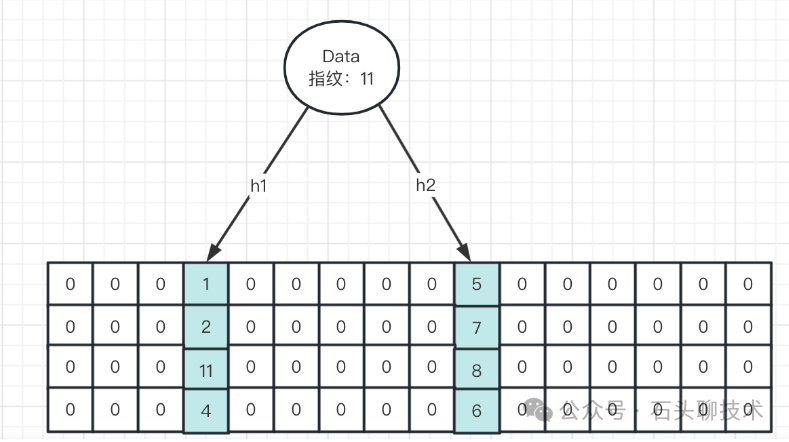
布隆过滤器主要用来判断,某个数据存不存在
HyperLogLog用来做 统计 , 没法确认某个数据在不在
bitmap即可统计也可确定数据在不在,但是占用空间较大,支支持数字类型。当仅用于统计,且数量大于12*1024*8 约等于十万的时候,建议考虑hyperlog
redis search
redis json
TimeSeries 时间序列
Redis Cell限流 露牌桶算法
Redis s2geo
布谷鸟过滤器:Bloom Filter 可能存在误报并且无法删除元素
Redis ML 推荐系统
常见数据结构的使用场景是什么
若有修改 同步到对应博客中
String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
List 类型的应用场景:可以实现栈 队列 以及 消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
Hash 类型:缓存对象、购物车等。
Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、共同感兴趣的tag、抽奖活动等。
Zset 类型:排序场景,比如排行榜、电话和姓名排序等。以及延时队列
Redis 后续版本又支持四种数据类型,它们的应用场景如下:
BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
缓存数据量很大,大到内存放不下,怎么解决?
这个题目不要问什么答什么 怎么解决那就只有扩容和落盘呗
首先是 关注为什么大?
然后缓存 有没有设置有效时间?
有效时间是否合理?
看看大key
设置淘汰策略 毕竟淘汰一些数据 总比不能用了好 而且有这个时间让我们去应对 比如扩容 查看为什么大等
redis的底层结构?(如果有更改 同步到那篇文章中)
底层数据类型
-
SDS
O(1)复杂度获取字符串长度
二进制安全
不会发生缓冲区溢出
减少内存重分配 :预分配与惰性空间释放
节省内存空间——结构体不进行字节对齐 -
链表
双向无环链表。缺点是不连续无法很好的利用cpu缓存。
因此redis的list在数据量少的情况下会用压缩列表作为底层实现,但是存在性能问题,后面又更新了quicklist到listpack以更新实现
而且占用空间 因为每个都要前节点和后节点 -
压缩列表
适用于节点数量很少的场景
类似vchar 长度可变的数组 但是会遇到连锁更新的性能雪崩问题 -
哈希表
哈希冲突 开放地址法和拉链法 以及升级哈希函数
两个散列表 后面一个是用来rehash的
负载因子 已存节点数量/哈希表大小
Rehash条件 触发 rehash 操作的条件,主要有两个: -
当负载因子大于等于 1 ,并且 Redis 没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。
-
当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作。
渐进式rehash -
整数集合
升级操作 维持有序性 但是不能降级 -
跳跃表
链表加多级索引的结构,就是跳跃表
Redis 则采用一种巧妙的方法是,跳表在创建节点的时候,随机生成每个节点的层数,并没有严格维持相邻两层的节点数量比例为 2 : 1 的情况。
具体的做法是,跳表在创建节点时候,会生成范围为[0-1]的一个随机数,如果这个随机数小于 0.25(相当于概率 25%),那么层数就增加 1 层,然后继续生成下一个随机数,直到随机数的结果大于 0.25 结束,最终确定该节点的层数。 -
listpack——对压缩列表的升级
它最大特点是 listpack 中每个节点不再包含前一个节点的长度了
listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。 -
Quicklist
其实 quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,它将 linkedList 按段切分,每一段使用listpack来紧凑存储,多个 listpack之间使用双向指针串接起来。
对象与底层数据结构的对应
对象与底层数据结构的对应最新7.2版本
-
string
- int:字符串长度 ≤ 20字节且能转成整数
- embstr:字符串长度 ≤ 44字节
- raw:字符串长度 > 44字节
其中:embstr和raw都是由SDS动态字符串构成的。唯一区别是:raw是分配内存的时候,redisobject和 sds 各分配一块内存,而embstr是redisobject和raw在一块儿内存中。
-
list
- inset:元素都为整数 且节点数量 ≤ 512
- listpack:元素数量 ≤ 512个且元素大小 ≤ 64字节
- quicklist:元素数量 > 512个或元素大小 > 64字节
-
hash
- listpack:节点数量 ≤ 512且元素大小 ≤ 64字节
- hashtable:节点数量 > 512或元素大小 > 64字节
-
set
- intset:整数时
- listpack:元素有一个不为整数,且节点数量 ≤ 128且元素大小 ≤ 64字节
- hashtable:元素有一个不为整数,且节点数量 > 128或元素大小 > 64字节
set类型的数据,首先会使用listpack结构当 set 达到一定的阈值时,才会自动转换为hashtable。
添加listpack结构是为了提高内存利用率和操作效率,因为 hashtable 的空间开销和碰撞概率都比 较高。 -
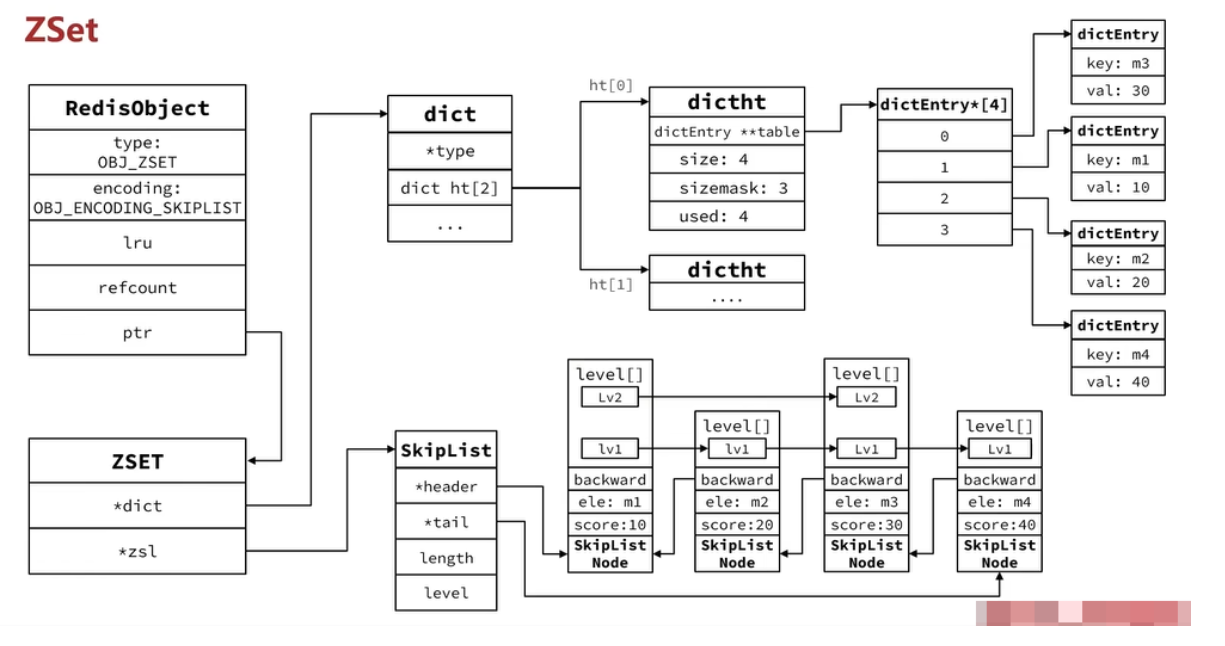
zset
- listpack:子节点数量 ≤ 128且元素大小 ≤ 64字节
- skiplist+hashtable:子节点数量 > 128或元素大小 > 64字节
-
bitmap
- sds
-
hyperlog
- Dense
- Sparse
-
Geospatial
- zet
hash如何使用listpack存储?
zset如何用到listpack?
同理 前面存key 后面score即可
zet也要用到hashtable ?
如果单纯使用字典,查询时的效率很高是O(1),但执行类似ZRANGE、ZRNK时,排序性能低。每次排序需要在内存上对字典进行排序一次,同时消耗了额外的O(n)内存空间
如果单纯使用跳跃表,查询性能又会从O(1)上升到了O(logN)
所以Redis集合了两种数据结构,同时这两种数据结构通过指针来共享变量也不会浪费内存。
为什么RedisZset用跳表实现而不是红黑树?B+树?
为什么不用红黑树?
1 相比红黑树而言实现简单
跳表基于多层链表实现,通过概率算法动态生成索引层级,没有左旋右旋等操作,逻辑理解上更为简单。而红黑树需要复杂的平衡操作(旋转)来维护结构,代码实现复杂度较高,理解门槛更高。
2 范围查询更高效
范围查询跳表可以通过O(ogn)的时间复杂度定位起点,然后在原始的链表中往后遍历即可。红黑树从结构上不支持范围查询。
3 结构更灵活
跳表的层数和节点结构是动态的,可以基于概率分布调整层数,灵活的适应不同的数据量(数据量大层级可以多一些,小的话层级少一些)。
红黑树则无法调整。
4 空间效率:虽然红黑树通常在空间效率上优于跳表,但跳表的空间开销在实际应用中通常是可接受的。此外,Redis中的跳表通过使用压缩列表(ziplist)和其他技术优化了内存使用。
为什么不用B+树?
B+树节点更新比较复杂,涉及页合并和分裂,会导致额外的计算。
B+树节点理论上占用内存也比跳表节点大。因为控制层级的情况下,大部分跳表节点仅需维护自身的值和一个指针(可能还有一个回退指针,redis的实现有回退指针),而B+树是多叉树,一个节点需要多指针,且节点内部还有若干指针。每个元素在叶子节点有一份完整数据内容,在非叶子节点还需要存储键的数据,所以内存开销相比跳表大。
B+树其实更适合磁盘存储,特别是大规模存储数据。因为B+树完整数据都存储在叶子节点中,而非叶子节点只起到索引作用,这样内存中就能存放更多的索引,便于海量数据的快速检索。
咆哮位图、布隆过滤器、hyporlog底层


HyperLogLog 是一种基数估算算法。所谓基数估算,就是估算在一批数据中,不重复元素的个数有多少。12K就可以计算接近 2^64 个不同元素的基数 但是最少也要用12k内存
HyperLogLog 在添加元素时,会通过Hash函数,将元素转为64位比特串,例如输入5,便转为101(省略前面的0,下同)。这些比特串就类似于一次抛硬币的伯努利过程。比特串中,0 代表了抛硬币落地是反面,1 代表抛硬币落地是正面,如果一个数据最终被转化了 10010000,那么从低位往高位看,我们可以认为,这串比特串可以代表一次伯努利过程,首次出现 1 的位数为5,就是抛了5次才出现正面。
- 伯努利过程
- 分桶
- 调和平均数
- 修正因子
持久化ROB和AOF
Redis是怎么持久化的?服务主从数据怎么交互的?
RDB做镜像全量持久化,AOF做增量持久化。
RDB会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据。
AOF是命令追加模式,但是日志文件会比较大,超过特定大小会触发AOF重写机制
redis有三种模式,ROB模式,AOF模式,以及后来添加的ROB+AOF模式。
最后这种模式下,AOF上半部分是ROB,下半部分是AOF。
ROB的save和bgsave用哪个?如何保证数据同步?原理?
bgsave不会阻塞。
你给出两个词汇就可以了,fork和cow。fork是指redis通过创建子进程来进行RDB操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
AOF重写机制?
两个缓冲区,一个用来重写。一个用来追加新的命令
AOF刷盘设置?如果突然机器掉电会怎样?
取决于AOF日志sync属性的配置,如果不要求性能,在每条写指令时都sync一下磁盘,就不会丢失数据。但是在高性能的要求下每次都sync是不现实的,一般都使用定时sync,比如1s1次,这个时候最多就会丢失1s的数据。
同时开启RDB和AOF的注意事项:
同时开启了AOF和RDB持久化,那么在Redis宕机重启之后,会加载一个持久化文件,官方默认选择AOF文件.
先开启了RDB,再次开启AOF,如果RDB执行了持久化,那么RDB文件中的内容会被AOF覆盖掉,建议同时开启.
Redis 持久化时,对过期键会如何处理的?
Redis 持久化文件有两种格式:RDB(Redis Database)和 AOF(Append Only File),下面我们分别来看过期键在这两种格式中的呈现状态。
RDB 文件分为两个阶段,RDB 文件生成阶段和加载阶段。
- RDB 文件生成阶段:从内存状态持久化成 RDB(文件)的时候,会对 key 进行过期检查,过期的键「不会」被保存到新的 RDB 文件中,因此 Redis 中的过期键不会对生成新 RDB 文件产生任何影响。
- RDB 加载阶段:RDB 加载阶段时,要看服务器是主服务器还是从服务器,分别对应以下两种情况:
如果 Redis 是「主服务器」运行模式的话,在载入 RDB 文件时,程序会对文件中保存的键进行检查,过期键「不会」被载入到数据库中。所以过期键不会对载入 RDB 文件的主服务器造成影响;
如果 Redis 是「从服务器」运行模式的话,在载入 RDB 文件时,不论键是否过期都会被载入到数据库中。但由于主从服务器在进行数据同步时,从服务器的数据会被清空。所以一般来说,过期键对载入 RDB 文件的从服务器也不会造成影响。
AOF 文件分为两个阶段,AOF 文件写入阶段和 AOF 重写阶段。
- AOF 文件写入阶段:当 Redis 以 AOF 模式持久化时,如果数据库某个过期键还没被删除,那么 AOF 文件会保留此过期键,当此过期键被删除后,Redis 会向 AOF 文件追加一条 DEL 命令来显式地删除该键值。
- AOF 重写阶段:执行 AOF 重写时,会对 Redis 中的键值对进行检查,已过期的键不会被保存到重写后的 AOF 文件中,因此不会对 AOF 重写造成任何影响。
集群的面试题
Redis 主从、哨兵、集群工作原理?三种部署方式的区别?
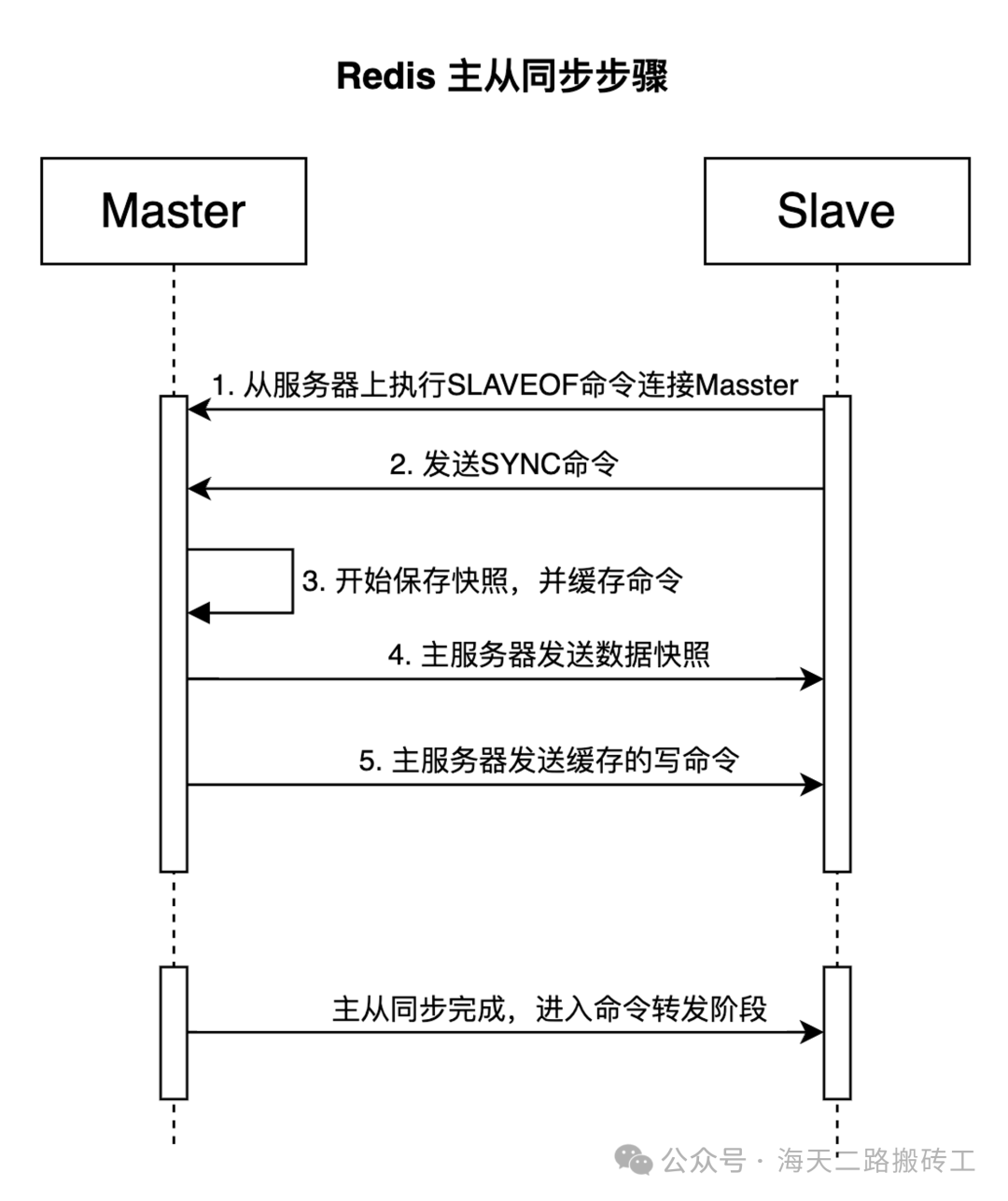
主从模式
- 第一次是rob快照同步 后面aof模式
- 可以从库再设置从库
- 如果连接意外断开,会判断 进行增量同步还是全量同步
哨兵一般推荐三个及以上的奇数个,否则可能会因为自身网络问题而产生误判
而且在主从切换的过程中,还需要在哨兵集群中选出一个 leader,让 leader 来执行主从切换。
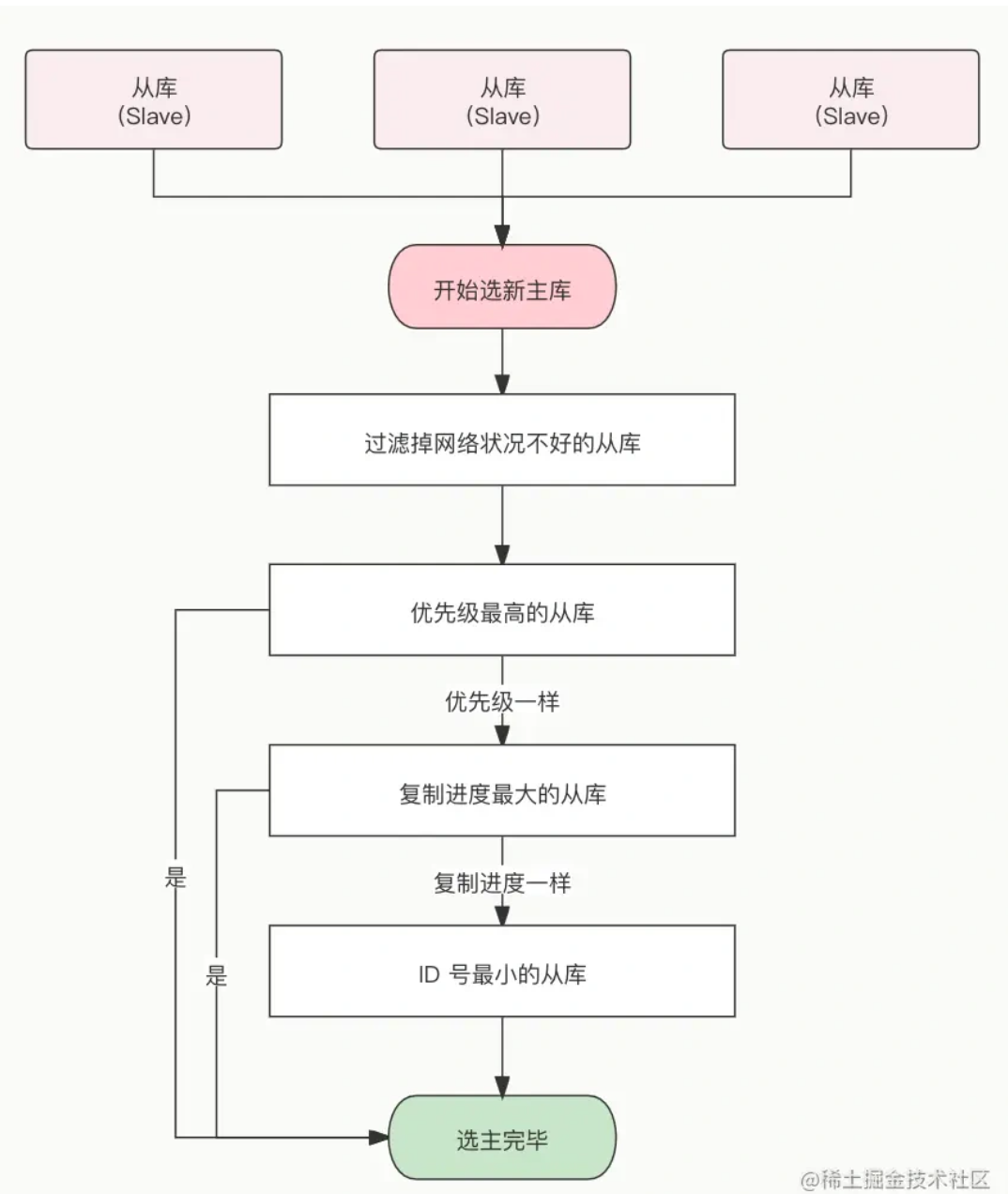
分区模式
- 范围分区
- 哈希分区 一般用哈希
分区的不足
redis的一些特性在分区方面表现的不是很好:
涉及多个key的操作通常是不被支持的。举例来说,当两个set映射到不同的redis实例上时,你就不能对这两个set执行交集操作。
涉及多个key的redis事务不能使用。
当使用分区时,数据处理较为复杂,比如你需要处理多个rdb/aof文件,并且从多个实例和主机备份持久化文件。
增加或删除容量也比较复杂。redis集群大多数支持在运行时增加、删除节点的透明数据平衡的能力,但是类似于客户端分区、代理等其他系统则不支持这项特性。然而,一种叫做presharding的技术对此是有帮助的。
脑裂问题 以及如何解决
可能丢数据
通过设置两个参数解决
- 主节点必须要有至少 x 个从节点连接,如果小于这个数,主节点会禁止写数据。
- 主从数据复制和同步的延迟不能超过 x 秒,如果超过,主节点会禁止写数据。
注意和zookeeper 的区别
Redis主从节点时长连接还是短连接?
长连接
怎么判断 Redis 某个节点是否正常工作?
Redis 判断节点是否正常工作,基本都是通过互相的 ping-pong 心态检测机制,如果有一半以上的节点去 ping 一个节点的时候没有 pong 回应,集群就会认为这个节点挂掉了,会断开与这个节点的连接。
Redis 主从节点发送的心态间隔是不一样的,而且作用也有一点区别:
Redis 主节点默认每隔 10 秒对从节点发送 ping 命令,判断从节点的存活性和连接状态,可通过参数repl-ping-slave-period控制发送频率。
Redis 从节点每隔 1 秒发送 replconf ack{offset} 命令,给主节点上报自身当前的复制偏移量,目的是为了:
实时监测主从节点网络状态;
上报自身复制偏移量, 检查复制数据是否丢失, 如果从节点数据丢失, 再从主节点的复制缓冲区中拉取丢失数据。
主从复制架构中,过期key如何处理?
主节点处理了一个key或者通过淘汰算法淘汰了一个key,这个时间主节点模拟一条del命令发送给从节点,从节点收到该命令后,就进行删除key的操作。
Redis 是同步复制还是异步复制?
Redis 主节点每次收到写命令之后,先写到内部的缓冲区,然后异步发送给从节点。
主从复制中两个 Buffer(replication buffer 、repl backlog buffer)有什么区别?
replication buffer 、repl backlog buffer 区别如下:
出现的阶段不一样:
- repl backlog buffer 是在增量复制阶段出现,一个主节点只分配一个 repl backlog buffer;
- replication buffer 是在全量复制阶段和增量复制阶段都会出现,主节点会给每个新连接的从节点,分配一个 replication buffer;
这两个 Buffer 都有大小限制的,当缓冲区满了之后,发生的事情不一样:
- 当 repl backlog buffer 满了,因为是环形结构,会直接覆盖起始位置数据;
- 当 replication buffer 满了,会导致连接断开,删除缓存,从节点重新连接,重新开始全量复制。
如何应对主从数据不一致?
为什么会出现主从数据不一致?
主从数据不一致,就是指客户端从从节点中读取到的值和主节点中的最新值并不一致。
之所以会出现主从数据不一致的现象,是因为主从节点间的命令复制是异步进行的,所以无法实现强一致性保证(主从数据时时刻刻保持一致)。
具体来说,在主从节点命令传播阶段,主节点收到新的写命令后,会发送给从节点。但是,主节点并不会等到从节点实际执行完命令后,再把结果返回给客户端,而是主节点自己在本地执行完命令后,就会向客户端返回结果了。如果从节点还没有执行主节点同步过来的命令,主从节点间的数据就不一致了。
如何如何应对主从数据不一致?
第一种方法,尽量保证主从节点间的网络连接状况良好,避免主从节点在不同的机房。
第二种方法,可以开发一个外部程序来监控主从节点间的复制进度。具体做法:
Redis 的 INFO replication 命令可以查看主节点接收写命令的进度信息(master_repl_offset)和从节点复制写命令的进度信息(slave_repl_offset),所以,我们就可以开发一个监控程序,先用 INFO replication 命令查到主、从节点的进度,然后,我们用 master_repl_offset 减去 slave_repl_offset,这样就能得到从节点和主节点间的复制进度差值了。
如果某个从节点的进度差值大于我们预设的阈值,我们可以让客户端不再和这个从节点连接进行数据读取,这样就可以减少读到不一致数据的情况。不过,为了避免出现客户端和所有从节点都不能连接的情况,我们需要把复制进度差值的阈值设置得大一些。
主从切换如何减少数据丢失?
主从切换过程中,产生数据丢失的情况有两种:
- 异步复制同步丢失
- 集群产生脑裂数据丢失
我们不可能保证数据完全不丢失,只能做到使得尽量少的数据丢失。
减少异步复制的数据丢失的方案
对于 Redis 主节点与从节点之间的数据复制,是异步复制的,当客户端发送写请求给主节点的时候,客户端会返回 ok,接着主节点将写请求异步同步给各个从节点,但是如果此时主节点还没来得及同步给从节点时发生了断电,那么主节点内存中的数据会丢失。
Redis 配置里有一个参数 min-slaves-max-lag,表示一旦所有的从节点数据复制和同步的延迟都超过了 min-slaves-max-lag 定义的值,那么主节点就会拒绝接收任何请求。
假设将 min-slaves-max-lag 配置为 10s 后,根据目前 master->slave 的复制速度,如果数据同步完成所需要时间超过10s,就会认为 master 未来宕机后损失的数据会很多,master 就拒绝写入新请求。这样就能将 master 和 slave 数据差控制在10s内,即使 master 宕机也只是这未复制的 10s 数据。
那么对于客户端,当客户端发现 master 不可写后,我们可以采取降级措施,将数据暂时写入本地缓存和磁盘中,在一段时间(等 master 恢复正常)后重新写入 master 来保证数据不丢失,也可以将数据写入 kafka 消息队列,等 master 恢复正常,再隔一段时间去消费 kafka 中的数据,让将数据重新写入 master 。
其他零散
redis缓存和本地缓存,可以用本地缓存么
答了可以但不建议,然后面试官反问维护redis的成本呢
以及 热key 可以二级缓存
redis管道功能
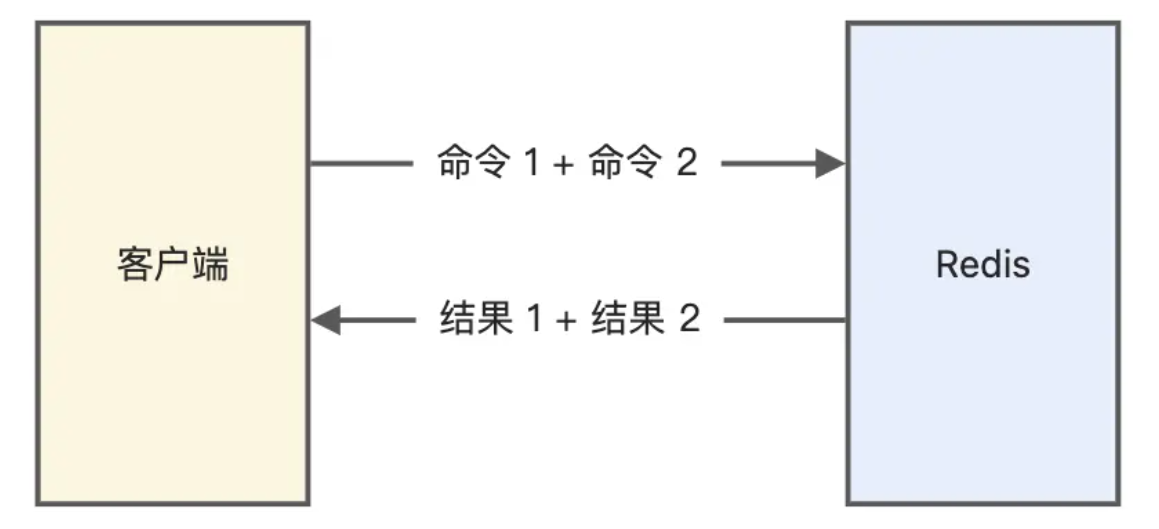
管道是客户端提供的功能 而非服务端
中间件
orm
orm通用问题
orm框架的优缺点
mybatis
goorm
消息队列
2、项目里用了Kafka,那聊一下RocketMQ和Kafka的区别;
3、介绍一下Kafka集群、副本、选举;
、Kafka 基本工作原理?
2、Kafka 为何高吞吐?
3、Kafka 消息的可靠性、顺序性是如何实现的的?
4、Kafka 的 ISR 机制?
5、Kafka 与其他 MQ 的对比与选择
kafka相关知识(顺序消费,高可用,重复消费),rabbitmq和kafka不同
rabbitmq做过哪些东西?是1个生产者对多个消费者吗?
一个完整的链路中,因为消息队列异步的业务,如何做链路追踪?
es
工作中,你们的ES和Mysql之间是怎么用的;
分布式
分布式就不多说了,什么 base 理论,raft 协议都需要知道。另外就是分布式锁、分布式事务相关的一些知识,大家用到过的可以讲讲,比较加分,没用到过的面试官一般也不会问到。
.go-micro微服务架构的水平部署及代码实现。
如何使用micro.
如何进行服务发现。
Rpc 远程调用的流程
项目中的 SPI 机制,介绍一下原理以及你做了哪些改进
一致性哈希的原理,虚拟结点
项目中的序列化方案,为什么序列化,你都了解哪些常用的序列化方法。
MQ 的原理,你知道哪些 MQ,各自有什么特点,什么时候需要用 MQ
http与grpc的区别
微服务注册与发现以及健康检查
protobuf的使用问题
用etcd做了什么,怎么实现的?
服务发现用的什么协议/etcd服务器和程序如何通信?tcp协议
分布式一致性是什么?介绍-下raft协议
cap理论
-
C:Consistency即一致性,
-
A:Availability
即可用性,所有的节点都保持高可用性。详细点说,这里的能够提供正常服务必须满足两个条件:- 必须在合理时间内给出相应
- 系统内只要正常的节点都要能够做出响应,返回结果。这里包含两种情况:
- 如果系统内的某个节点或者是某些节点宕机了,但是其他的正常节点可以在合理的时间内做出响应
- 节点正常,但是节点上的数据有问题,比如不是最新数据,如果有请求达到这个节点上了,依然不能拒绝请求,要正常返回这个旧数据
也就是说,任何没有发生故障的服务必须在有限的时间内返回合理的结果集。
-
P:Partiton tolerance
即分区容忍性,这里的分区是指网络意义上的分区。由于网络是不可靠的,系统在网络分区(如节点间通信中断)时仍能继续运行。由于分布式系统中网络故障不可避免,P是必须满足的特性。
CAP原理是说 CAP最多只能同时满足两个 不能同时满足3个 特别是A和C
为什么只能同时满足CAP中的两个呢?
以A\B两个节点同步数据举例,由于P的存在,那么可能AB同步数据出现问题。
如果选择AP,由于A的数据未能正确同步到B,所以AB数据不一致,无法满足C。
如果选择CP,那么B就不能提供服务,就无法满足A。
zookeeper
为什么选用 Zookeeper 作为注册中心,注册中心作用是什么
注册中心要解决什么问题?
- 服务注册:实例上线时登记自己的地址(如192.168.1.1:8080)
- 服务发现:消费者快速找到可用服务列表
- 健康监测:自动剔除故障节点
- 配置管理:统一管理服务元数据(如权重、版本)
可以利⽤Zookeeper的临时顺序节点和watch机制来实现注册中⼼的⾃动注册和发现,另外Zookeeper中的 数据都是存在内存中的,并且Zookeeper底层采⽤了nio,多线程模型,所以Zookeeper的性能也是⽐较⾼的,以及用了zab协议保证一致性。所以可以⽤来作为注册中⼼。但是如果考虑到注册中⼼应该是注册可⽤性的话,那么Zookeeper 则不太合适,因为Zookeeper是CP的,它注重的是⼀致性,所以集群数据不⼀致时,集群将不可⽤,所以⽤Redis、Eureka、Nacos来作为注册中⼼将更合适。
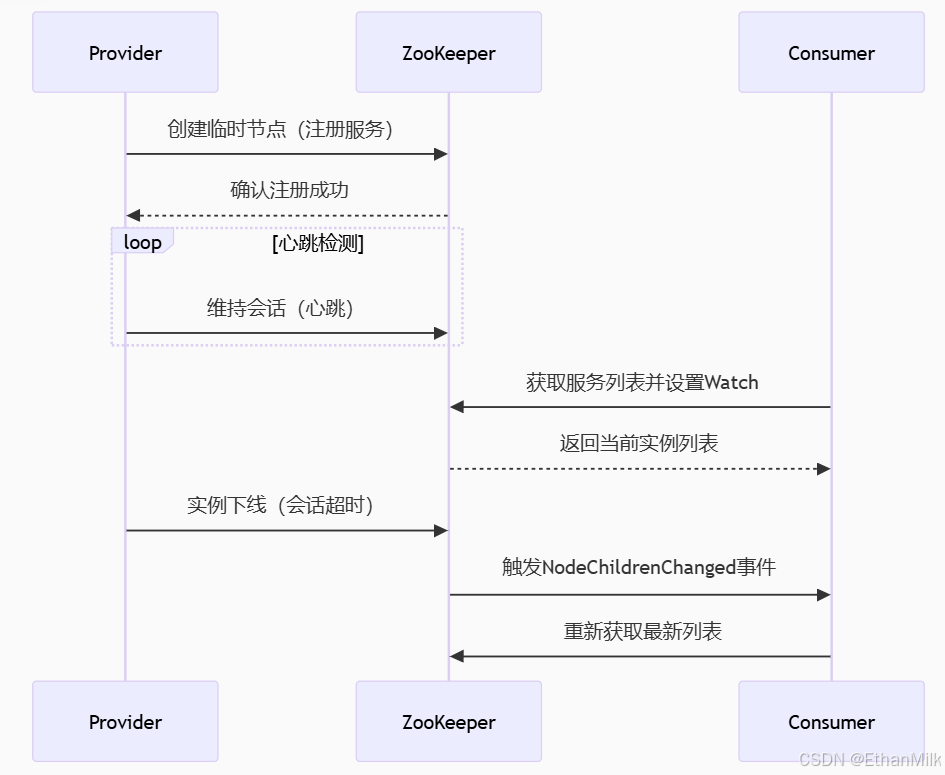
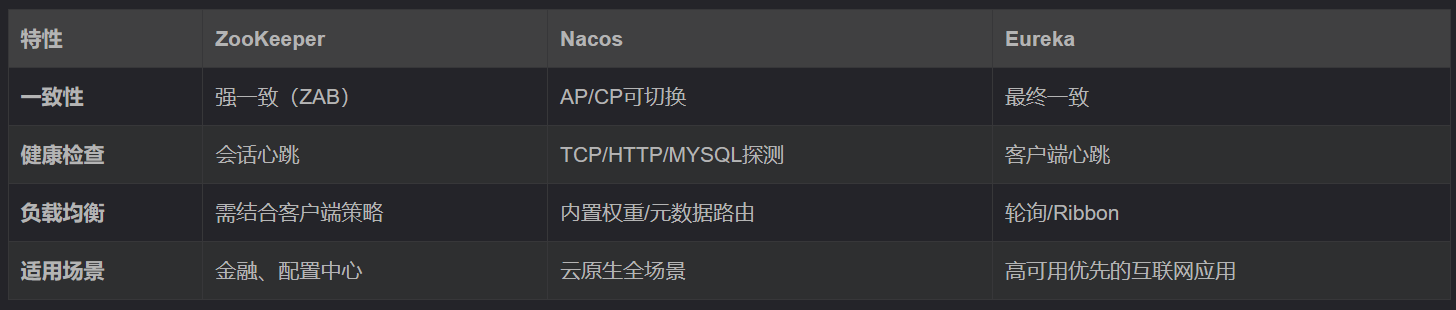
Zookeeper 作为注册中心,假如崩溃了怎么办?这里开始连环问了
三个角色 master folower 还有观察者
zab协议 原子广播(只有master写 半数、zxid、proposal、两阶段写)和崩溃恢复机制(半数选举 zxid最大的)
你提到了 Zookeeper 的一致性,它是如何保证的? 是强一致性吗?
最终一致性 而非强一致性
写入一致性 而读取不一定 但是能够保证 读取不会读到客户端中的老数据
zab协议 原子广播(只有master写 半数、zxid、proposal、两阶段写)和崩溃恢复机制(半数选举 zxid最大的)
有可能会出现数据不一致的问题吗?
还是会存在的,我们可以分成3个场景来描述这个问题。
查询不一致
因为Zookeeper是过半成功即代表成功,假设我们有5个节点,如果123节点写入成功,如果这时候请求访问到4或者5节点,那么有可能读取不到数据,因为可能数据还没有同步到4、5节点中,也可以认为这算是数据不一致的问题。
解决方案可以在读取前使用sync命令。
leader未发送proposal宕机
这也就是数据同步说过的问题。
leader刚生成一个proposal,还没有来得及发送出去,此时leader宕机,重新选举之后作为follower,但是新的leader没有这个proposal。
这种场景下的日志将会被丢弃。
leader发送proposal成功,发送commit前宕机
如果发送proposal成功了,但是在将要发送commit命令前宕机了,如果重新进行选举,还是会选择zxid最大的节点作为leader,因此,这个日志并不会被丢弃,会在选举出leader之后重新同步到其他节点当中。
选举的过程,这里问的很详细
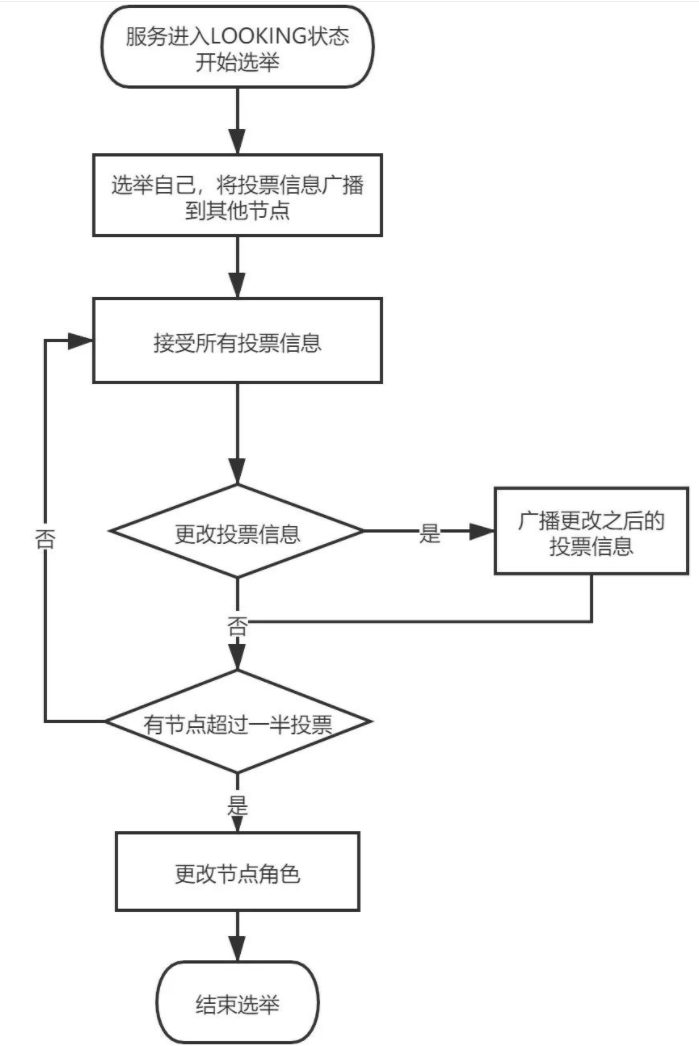
服务在启动或者和leader失联之后服务状态转为LOOKING;
Zookeeper 如何应对网络分区的,脑裂问题了解吗,如何解决?
脑裂(split-brain)是指在分布式系统中,因网络分区或其他故障导致系统被切割成两个或多个相互独立的子系统,每个子系统可能独立选举出自己的领导节点。这一现象在依赖中心领导节点(如Elasticsearch的Master节点或ZooKeeper的Leader节点)的集群环境中尤为常见。当这种情况发生时,原本应该由单一领导节点控制的集群突然出现了多个领导者,导致数据不一致和操作冲突。
脑裂的直接后果是数据一致性的丧失
通过心跳机制判断是否正常
一般设置为奇数,过半原则保证不会有两个leader产生。如果不过半则选举不出来leader。
仲裁机制则通过引入一个外部决策者来帮助解决集群内部的领导权争议。这个外部决策者可以是一个独立的服务或系统,它根据预设的规则来判断哪个节点应当担任领导者。
如果有2个节点,那么只要挂掉1个节点,集群就不可用了。此时,集群对的容忍度为0;
如果有3个节点,那么挂掉1个节点,还有剩下2个正常节点,超过半数,可以重新选举,正常服务。此时,集群的容忍度为1;
如果有4个节点,那么挂掉1个节点,剩下3个,超过半数,可以重新选举。但如果再挂掉1个,只剩下2个,就无法正常选举和服务了。此时,集群的容忍度为1;
假如我同一时间有大量服务发布,你提到了 Zookeeper 只有主节点负责写, 怎么解决?假如主节点崩溃了,新选举出的主节点仍然没办法面对我的大流量,也崩溃了,如何解决?
虽然 ZK 是以 PC 闻名的,如果 Leader 挂了,在重新选举这段时间服务将变得不可用。
但是客户端有自己的缓存,注册中心挂了也影响不大。况且,官方测试,重新选举 Leader 的时间不会超过 200 ms。因此,这一点上来说,影响确实不是很大。
唯一存在影响的就是,因为只有 Leader 一个结点才可以写,当我们新服务大面积发布的时候,有可能导致高并发流量打到 Leader 上导致宕机。这是真正存在的问题
解决这个问题两个思路,批量发布,或者使用消息队列,削峰
Zookeeper是如何保证数据一致性的?
Zookeeper通过ZAB原子广播协议来实现数据的最终顺序一致性,他是一个类似2PC两阶段提交的过程。
由于Zookeeper只有Leader节点可以写入数据,如果是其他节点收到写入数据的请求,则会将之转发给Leader节点。
主要流程如下:
Leader收到请求之后,将它转换为一个proposal提议,并且为每个提议分配一个全局唯一递增的事务ID:zxid,然后把提议放入到一个FIFO的队列中,按照FIFO的策略发送给所有的Follower
Follower收到提议之后,以事务日志的形式写入到本地磁盘中,写入成功后返回ACK给Leader
Leader在收到超过半数的Follower的ACK之后,即可认为数据写入成功,就会发送commit命令给Follower告诉他们可以提交proposal了
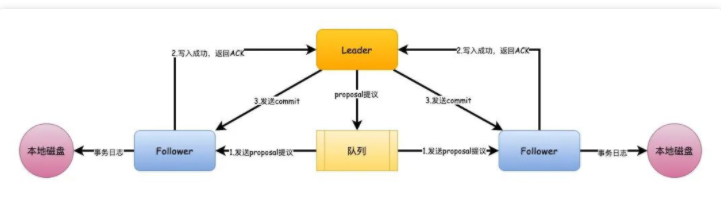
ZAB包含两种基本模式,崩溃恢复和消息广播。
整个集群服务在启动、网络中断或者重启等异常情况的时候,首先会进入到崩溃恢复状态,此时会通过选举产生Leader节点,当集群过半的节点都和Leader状态同步之后,ZAB就会退出恢复模式。之后,就会进入消息广播的模式。
Zookeeper如何进行Leader选举的?
Leader的选举可以分为两个方面,同时选举主要包含事务zxid和myid,节点主要包含LEADING\FOLLOWING\LOOKING3个状态。
- 服务启动期间的选举
- 服务运行期间的选举(leader节点宕机)
服务启动期间的选举
首先,每个节点都会对自己进行投票,然后把投票信息广播给集群中的其他节点
节点接收到其他节点的投票信息,然后和自己的投票进行比较,首先zxid较大的优先,如果zxid相同那么则会去选择myid更大者,此时大家都是LOOKING的状态
投票完成之后,开始统计投票信息,如果集群中过半的机器都选择了某个节点机器作为leader,那么选举结束
最后,更新各个节点的状态,leader改为LEADING状态,follower改为FOLLOWING状态
服务运行期间的选举
如果开始选举出来的leader节点宕机了,那么运行期间就会重新进行leader的选举。
leader宕机之后,非observer节点都会把自己的状态修改为LOOKING状态,然后重新进入选举流程
生成投票信息(myid,zxid),同样,第一轮的投票大家都会把票投给自己,然后把投票信息广播出去
接下来的流程和上面的选举是一样的,都会优先以zxid,然后选择myid,最后统计投票信息,修改节点状态,选举结束
主从架构下,leader 崩溃,数据一致性怎么保证?
leader 崩溃之后,集群会选出新的 leader,然后就会进入恢复阶段,新的 leader 具有所有已经提交的提议,因此它会保证让 followers 同步已提交的提议,丢弃未提交的提议(以 leader 的记录为准),这就保证了整个集群的数据一致性。
选举 leader 的时候,整个集群无法处理写请求的,如何快速进行 leader 选举?
这是通过 Fast Leader Election 实现的,leader 的选举只需要超过半数的节点投票即可,这样不需要等待所有节点的选票,能够尽早选出 leader。
nginx
负载均衡如何实现 是什么
后端接口通用
RESTful 风格API
比较简单地说就是:
- url反应请求资源 比如
/departments/123/employees表示部门 123 下的员工资源 - 通过不同的请求方法 体现不一样的动作 CRUD get、post新建、put更新、delete删除
JSON-RPC风格api
以后用到再说吧
限流算法
固定窗口法
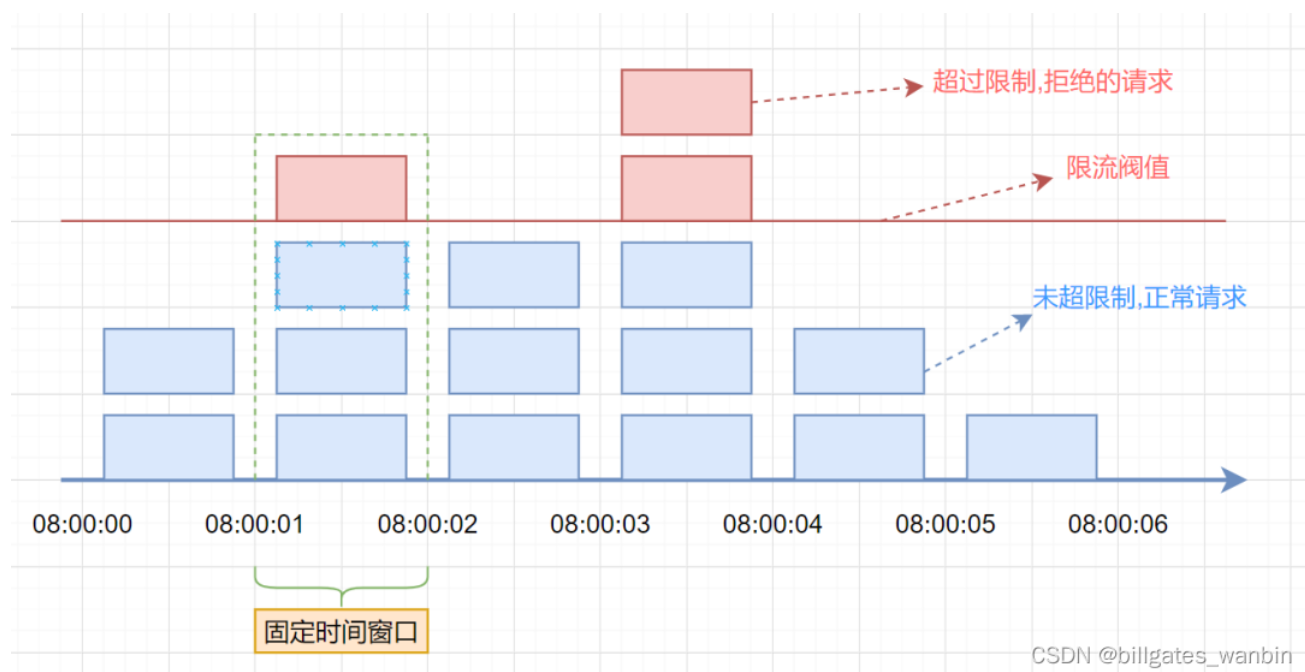
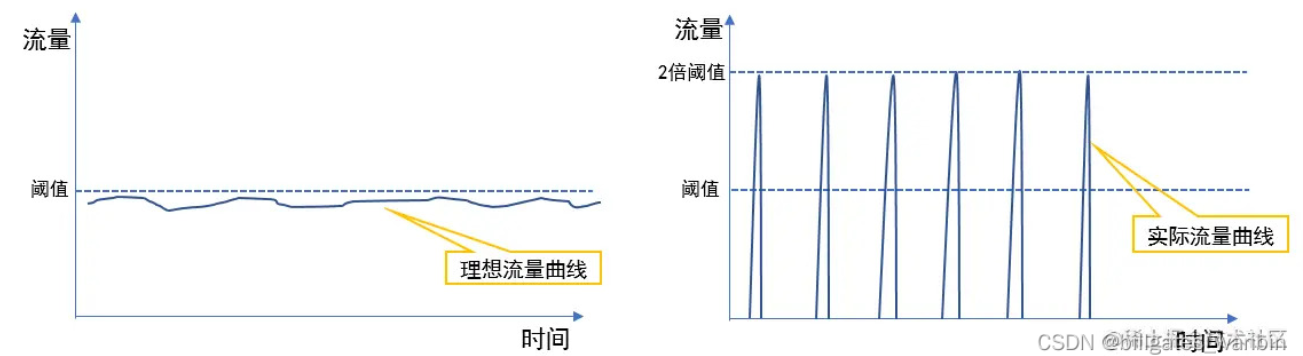
- 流量不够平滑(“突刺现象”),无法充分利用资源。
- 无法应对流量更突发的场景,比如前1秒就有1000个请求打进来
- 一段时间内(不超过时间窗口)系统服务不可用,系统资源无法充分利用。一旦流量进入速度有所波动,要么计数器会被提前计满,导致这个周期内剩下时间段的请求被限制。要么就是计数器计不满,导致资源无法充分利用。
- 限流措施某些情况起不到效果,更加极端的临界场景:在第一个时间窗口的后一秒来了1000个请求,在下一时间窗口的第一秒来了100个请求,这样在10秒之内就产生了200个请求,而这种场景限流措施并没有起到效果。
滑动窗口法
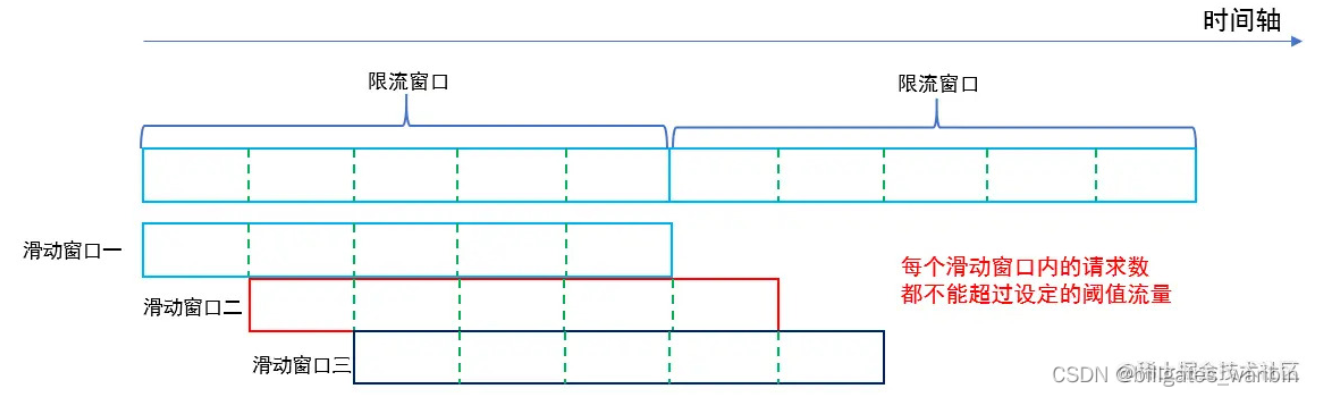
- 滑动窗口能够解决固定窗口第二个问题,而无法解决第一个问题
- 时间比较上精度越高,越消耗空间资源
漏桶算法
- 一个桶作为请求的容器,请求来了之后放入桶中
- 桶下面有一个洞,以匀速流出(处理请求)
- 桶放满的时候丢弃请求
- 当短时间内有大量的突发请求时,某些情况下,比如即便此时服务器没有任何负载或者网络没有任何的不畅通,每个请求也都得在队列中等待一段时间才能被响应。
漏桶算法和消息队列思想有点像,削峰填谷。经过漏洞这么一过滤,请求就能平滑的流出,看起来很像很挺完美的?实际上它的优点也即缺点。
面对突发请求,服务的处理速度和平时是一样的,这其实不是我们想要的,在面对突发流量我们希望在系统平稳的同时,提升用户体验即能更快的处理请求,而不是和正常流量一样,循规蹈矩的处理
看看,之前滑动窗口说流量不够平滑,现在太平滑了又不行,难搞啊。
对于很多场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。
令牌桶算法
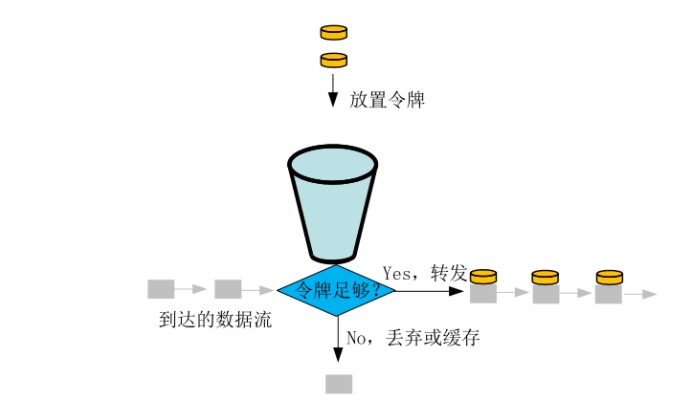
漏桶是漏 令牌桶是放
总结:令牌桶算法是比较科学,机制更全面的一个限流算法,放入令牌的速度是一定的,如果短时间有大量请求,令牌桶中的令牌可以支持一下全部用完,这样就解决了漏桶算法的缺点。
计数器算法
计数器算法是使用计数器在周期内累加访问次数,当达到设定的限流值时,触发限流策略。下一个周期开始时,进行清零,重新计数。
缺点和之前的固定窗口法一样。假设定时器60秒,第一秒1个请求,最后一秒突然很多个请求,然后下一秒又很多个。只是相对固定时间法以用户第一次访问的时间为基准而已。
LINUX
怎样对某个文件关键字出现字数排序
inux査看多少个连接是已建立的
natstat-napt|grep"ESTABLISHED"wc -
如何在一个目录下查找文件里某个单词
find /path/to/directory -type f -exec grep -Hn 'pattern' {} \;
linux 如何查看进程状态?
ps或者top命令
如何杀掉进程
ps -ef | grep <进程名> // 查找进程的PID
kill <PID> // 终止进程 如果强制删除需要加-9参数
如何查看线程状态?
在 ps 和 top 命令加一下参数,就能看到线程状态了:
top -H
ps -eT | grep <进程名或线程名>
如何查看网络连接情况?
可以通过 netstat 命令来查看网络连接的情况,比如下面,我通过 命令:
netstat -napt
怎么查看哪个端口被哪个进程占用?
可以通过 lsof 或者 netstate 命令查看,比如查看 80 端口。
lsof :
lsof -i :80
netstate:
netstat -napt | grep 80
怎么修改文件权限
chmod 比如
chmod 400 file.txt
top 命令和 free 命令有什么区别
top还会显示cpu等信息 free是专门查看内存的
假如cpu跑到100%,你的解决思路是什么?
思路如下:
先通过 top 命令,定位到占用 cpu 高的进程
然后通过 ps -T -p<> <进程ID> 命令找到进程中占用比较高的线程
然后通过 jstack 命令去查看该线程的堆栈信息
根据输出的堆栈信息,去项目中定位代码,看是否发生了死循环而导致cpu跑到100%
负载和cpu利用率区别
负载值一般不超过cpu核数的1-1.5倍,如果超过1.5倍,那就要重视,此时会严重影响系统。
负载包含了等待io 所以 对于io密集 负载高 而cpu占用低
free命令的内存区别
used:已经使用的内存。
free:可用的空闲内存。
available:可用的内存,这包括了操作系统缓存,这个值更能代表实际可用内存。
如果 Swap 空间使用过多(例如,接近 Swap total),说明物理内存不足。
DOCKER
docker了解吗-之前经常用,镜像源被封了没怎么用
说下怎样进入运行容器
怎样build镜像
和虚拟机区别
K8S
是干啥的
Kubernetes的网络模型?
怎样让一个Service的流量不均摊到每个Pod?
金丝雀
项目
面试中如何介绍自己的项目
项目中必备问题:
1.整体介绍一下项目
2.介绍一下项目架构
3.项目中遇到什么问题,怎么解决的
4.项目中某个技术点,业界是怎么做的
5.项目中某个技术还有没有其他解决方案,你为什么使用这种解决方案
6.项目中的技术是怎么使用的
从哪些方面介绍自己的项目
1.项目背景和大体的需求
2.技术栈与项目大体架构
3.在项目中的角色与贡献
项目困难
项目亮点
迭代器 生成器
场景题
3、项目聊的很深,甚至面试官理解业务后还出了针对原项目的场景题怎么保证发送并发情况下发送多个邮件导致的邮件攻击问题如果因为网络问题导致邮件发送失败会怎么处理?(如何知道邮件发送失败了)
如何设计一个朋友圈
场景分析
朋友圈系统的核心功能围绕着用户分享、互动和信息流的消费展开,主要场景包括:
-
发布动态:用户可以发布文字、图片、视频等动态。
-
浏览动态:用户可以看到自己的动态、好友的动态以及公共话题的动态。
-
互动反馈:点赞、评论、分享等互动行为。
-
隐私设置:控制谁能看到自己的动态。
-
话题和标签:动态可以打上话题和标签,方便分类和搜索。
-
推荐系统:根据用户兴趣推荐相关内容。
-
通知系统:当用户收到互动反馈时,能够收到通知。
特点分析
1.数据展示范围,朋友(包括自己)发送的图文数据 朋友很多
2.数据展示顺序,按时间倒排
3.热点数据,2天内 再往前就很少看了
数据存储
为了支持上述功能,数据存储需要考虑:
-
用户信息:存储用户的基本资料、好友列表和隐私设置。
-
动态数据:存储动态的文本、图片、视频链接、发布时间、话题标签等。
-
互动数据:点赞、评论、分享的信息,以及互动的时间戳。
-
推荐数据:用户兴趣模型和推荐算法产生的数据。
-
通知数据:记录未读通知,以便推送。
为了提高性能和扩展性,可以采用:
-
分布式数据库:如Cassandra或MongoDB,用于存储用户信息和动态数据。
-
缓存:如Redis,用于存储热点数据,如热门动态和用户信息。
-
文件存储:如Amazon S3或阿里云OSS,用于存储图片和视频文件。
实现
首先需要分库分表
哈希分片策略
根据用户ID进行哈希计算,将好友关系表、动态发布表等垂直拆分为多张子表,分散到不同数据库实例中。例如:
-- 按用户ID取模分片
table_index = user_id % 1024
但是这样就不好用in操作了?
冷热数据分离
近两天的存在redis里 比如用户看了朋友圈后 就生成一个缓存 加好友啊之类的删除缓存、以及当某人访问了xxx的朋友圈首页 就~~
近3个月动态保存在热数据库(如MySQL集群)
历史数据迁移至冷存储(如HBase)
好友数量很多 再去筛选最新发布 还要按时间 查询如何优化?
分布式缓存:用户动态Feed流预存至Redis,采用ZSET结构按时间排序7
ZADD user:123_feed 1620000000 "动态ID1"
索引优化
在动态发布表建立 联合索引(用户ID + 发布时间)
对好友关系表添加 覆盖索引(user_id, friend_id, relation_type)
预生成Feed流
用户发布动态后,通过消息队列(如Kafka)异步触发以下流程:
提取目标好友列表
将动态ID批量插入好友的Feed流缓存
业务层优化
分组查询策略
按标签分组(如家人、同事)查询动态,优先加载高频分组数据35:
优先查询"密友"分组动态
hot_groups = get_user_hot_groups(user_id)
动态分级加载
首屏加载最近24小时动态(50条)
下滑时异步加载更早数据
读写分离
主库处理动态发布、点赞等写操作
从库集群处理动态浏览、好友列表查询
容灾与限流
降级策略
当查询响应时间>500ms时:
返回缓存中的静态化动态快照
关闭非核心功能(如动态位置显示)7
限流机制
对Feed流查询接口实施令牌桶限流(QPS≤5000/实例)
系统扩展
-
水平扩展:通过增加服务器节点,使用负载均衡分散请求。
-
微服务架构:将系统拆分为用户服务、动态服务、互动服务等多个微服务,各自独立部署和扩展。
-
弹性伸缩:根据实时流量自动调整资源,如使用Kubernetes。
-
数据库分片:将数据分散到多个数据库实例,提高读写性能。
-
异步处理:使用消息队列(如RabbitMQ、Kafka)处理数据的异步写入和通知发送。
视频文件上传到文件服务器和业务服务器的差异?
首先 业务服务器有多个 那么上产可能多个地方
如果我们业务服务器上传 那就要做很多处理 比如集中存储啊 位置维护啊 备份啊等等
那这不就是 相当于把业务服务器变成了文件服务器?而且还需要我们自己动手 写很多代码
所以 这种需求 应该文件服务器专门的 这样可能还能用很多开源实现 避免我们过度自己造轮子 而且降低了耦合
设计模式
单例模式
工厂模式 简单工厂 工厂 抽象工厂
门面模式
建造者模式(生成器模式)
迭代器模式
其他 不好分类
多线程分块上传、断点续传如何实现
字节序
网络序和主机序了解过吗(不知道)
我发送一个数据包出去,我的二进制数据包子节序怎么转换的,对方接收到之后如何转化的(不知
道)
CSP和共享变量通信有什么区别吗
jwt失效怎么办
一致性哈希知道么
atomic应用场景以及五种操作方法
CAP理论 为什么满足1个 就不能满足另外2个
面向对象编程的三大核心概念和5大基本原则
项目中etcd用来干什么的?
etcd是一个分布式的键值存储系统,主要用于分布式系统中的配置管理、服务发现和分布式锁等功能。
在配置管理方面,它可以存储系统的各种配置信息,多个服务可以从etcd中获取配置,并且当配置发生变化时,etcd可以通知相关的服务。在服务发现中,服务可以将自己的信息(如IP地址、端口等)注册到etcd中,其他服务可以通过查询etcd来发现可用的服务。对于分布式锁,etcd可以通过其原子操作等特性来实现分布式环境下的互斥锁,保证在多个节点访问共享资源时的一致性。
非力扣简单代码题
用Golang的channel实现并发控制,两个goroutine交替打印奇偶数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









