




一、概念
大小端描述存储多字节数据在计算机内存中的字节顺序的概念(只是字节顺序,不是二进制顺序)
二、什么是大、小端
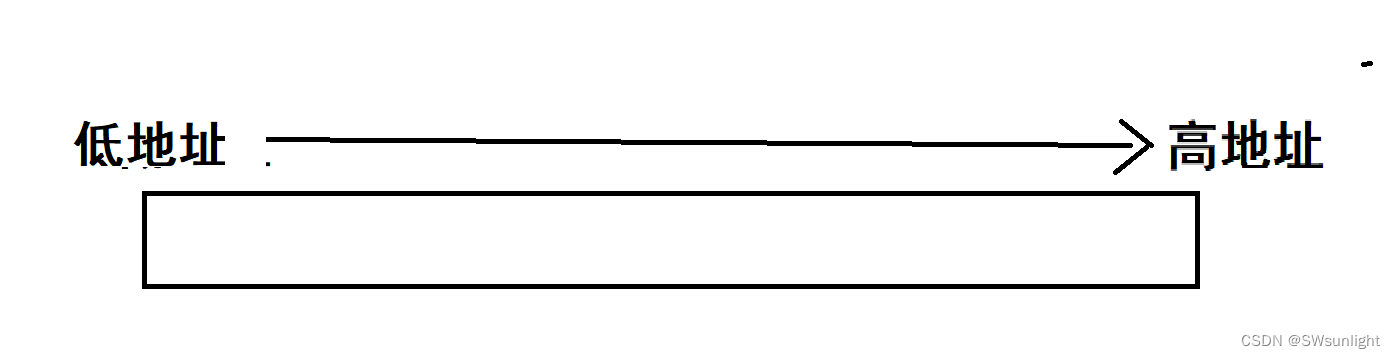
1、地址存放:
由低地址到高地址:
 2、高位与低位:
2、高位与低位:
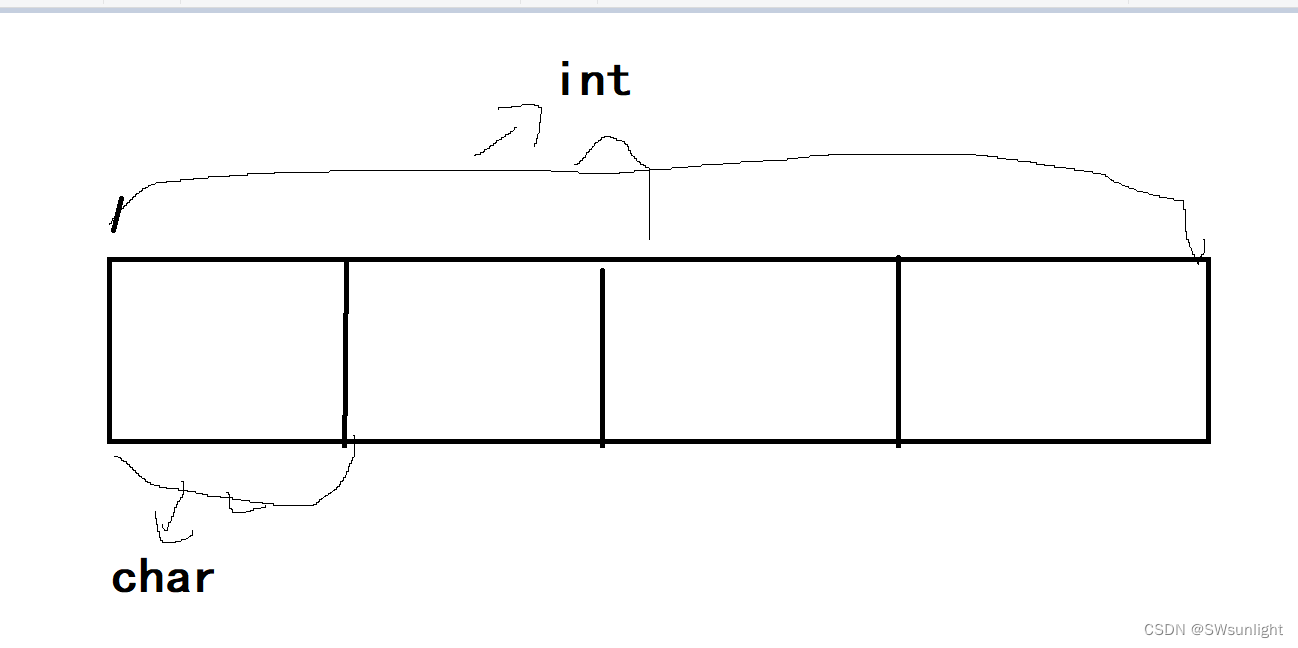
看下图就是,1是百万位 属于高位 7是个位属于低位
3、大小端概念:
大端字节序存储: 将一个数据的低位字节放在高地址处,高位字节放在低地址处;

小端字节序存储: 将一个数据的高位字节放在高地址处,低位字节放在低地址处;

4、例子:
int redd(void)
{
int a = 1;
//取出a的地址,转变为char* 再解引用,char* 的访问权限为1,访问一个字节
return *(char*)&a;
}
int main()
{
int ret = redd();
if (ret == 0)
{
printf("大端\n");
}
else
{
printf("小端\n");
}
return 0;
}
举个例子:以vs编译器为例,在这里先创造一个int型变量;
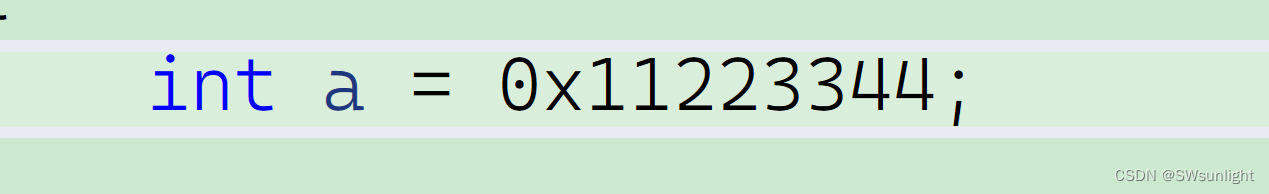
在vs中便于观察在内存中是以16进制展示(内部原理还是二进制,进行计算也由二进制来实现)
这个就是取a的地址,发现是小端字节序存储;

三、如果碰到一个题目:请问这个编译器是大端还是小端字节序存储?
方法一:建立函数通过对地址的解引用来判断
如下:a = 1 的二进制变成十六进制是这样的——>
图1:
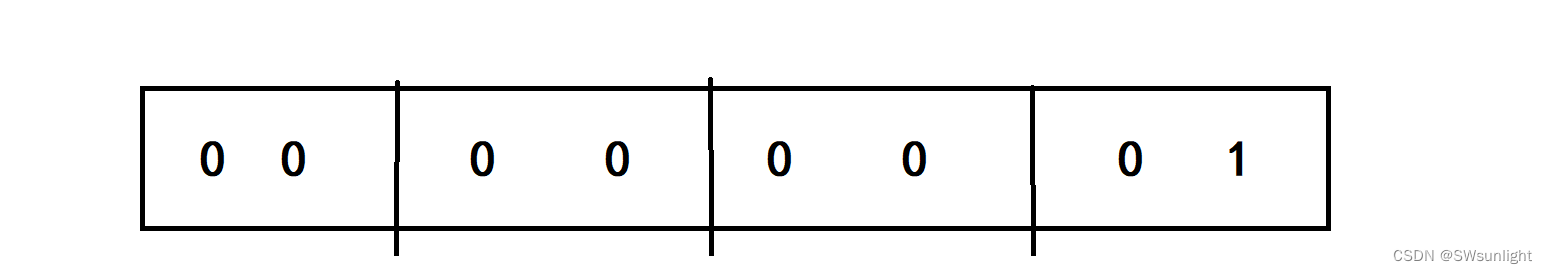
若是大端就是上面这个图,如果是小端 就是下面的图——>
图2:
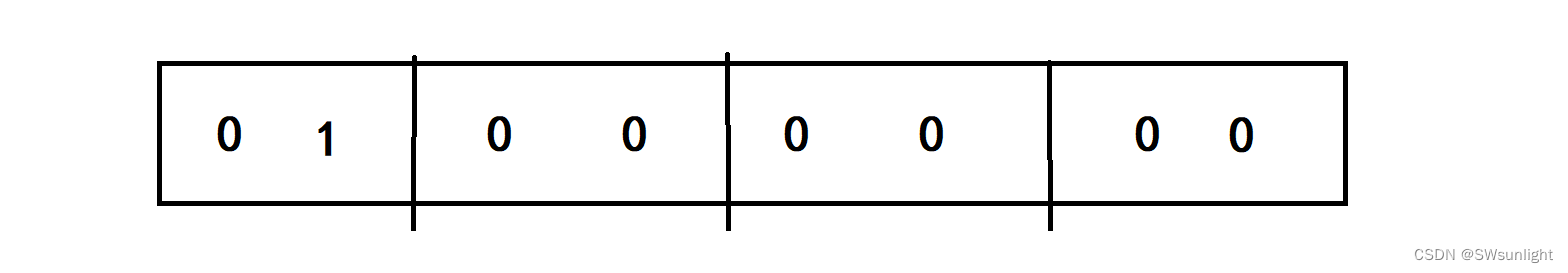
我们将a的地址解引用,再强转变为 char* 的地址,访问的就是第一个字节的地址,若是返回的是1就是图2,返回的是0就是图1
代码如下:
int redd(void)
{
int a = 1;
//取出a的地址,转变为char* 再解引用,char* 的访问权限为1,访问一个字节,解引用就是第一个字节的内容
return *(char*)&a;
}
int main()
{
int ret = redd();
if (ret == 0)
{
printf("大端\n");
}
else
{
printf("小端\n");
}
return 0;
}
方法二:联合体来确定
因为联合体是多个对象共用一个内存,所以更改一个数的值,其他值也会发生改变(是不是像极了高中地理的一句话:牵一动而发动全身)
int redd(void)
{
union Un {
char a;
int i;
}u;
//将i赋值为1 十六进制 00 00 00 01;
//小端:01 00 00 00
//大端:00 00 00 01
u.i = 1;
//返回char 的 a
return u.a;
}
int main()
{
int ret = redd();
if (ret == 0)
{
printf("大端\n");
}
else
{
printf("小端\n");
}
return 0;
}
若是 小端就是1 大端就是0

















 1602
1602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









