




Flask介绍
Flask 是一款发布于2010年非常流行的 Python Web 框架。
特点
- 微框架、简洁,给开发者提供了很大的扩展性。
- Flask和相应的插件写得很好,用起来很爽。
- 开发效率非常高,比如使用 SQLAlchemy 的 ORM 操作数据库可以节省开发者大量书写 sql 的时间。
Flask 的灵活度非常之高,他不会帮你做太多的决策,很多都可以按照自己的意愿进行更改。
比如:
使用 Flask 开发数据库的时候,具体是使用 SQLAlchemy 还是 MongoEngine,选择权完全掌握在你自己的手中。
Flask 本身相当于一个内核,其他几乎所有的功能都要用到扩展(邮件扩展
Flask-Mail,用户认证Flask-Login,数据库Flask-SQLAlchemy),都需要用第三方的扩展来实现。Flask 没有默认使用的数据库,你可以选择
MySQL,也可以用NoSQL。其 WSGI 工具箱采用
Werkzeug(路由模块),模板引擎则使用Jinja2。这两个也是 Flask 框架的核心。
扩展列表:Flask扩展列表
- Flask-SQLalchemy:操作数据库;
- Flask-script:插入脚本;
- Flask-migrate:管理迁移数据库;
- Flask-Session:Session存储方式指定;
- Flask-WTF:表单;
- Flask-Mail:邮件;
- Flask-Bable:提供国际化和本地化支持,翻译;
- Flask-Login:认证用户状态;
- Flask-OpenID:认证;
- Flask-RESTful:开发REST API的工具;
- Flask-Bootstrap:集成前端Twitter Bootstrap框架;
- Flask-Moment:本地化日期和时间;
- Flask-Admin:简单而可扩展的管理接口的框架
Python安装Flask:
pip install flask第一个Flask小程序:
#从flask包中导入Flask类 from flask import Flask #创建一个Flask对象 app = Flask(__name__) #@app.route:是一个装饰器 #@app.route('/')就是将url中 / 映射到hello_world设个视图函数上面 #以后你访问我这个网站的 / 目录的时候 会执行hello_world这个函数,然后将这个函数的返回值返回给浏览器 @app.route('/') def hello_world(): return '百度' #启动这个WEB服务 if __name__ == '__main__': #默认为5000端口 app.run() #app.run(port=8000)运行后结果显示如下:

Flask使用
如何运行Flask程序:
一 通过对象运行:运行程序时,可以指定运行的主机IP地址,端口
app.run(host="0.0.0.0", port=5000) # 127.0.0.1参数解释
host
- 主机IP地址,可以不传
- 默认localhost
port
- 端口号,可以不传
- 默认5000
二 通过Python运行方式运行
app = Flask(__name__) @app.route("/") def index(): return "hello world" if __name__ == '__main__': app.run()提示:如果想在同一个局域网下的其他电脑访问自己电脑上的Flask网站,需要设置
host='0.0.0.0'才能访问得到三通过Flask自带命令运行:
app = Flask(__name__) @app.route("/") def index(): return "hello world" # 程序中不用再写app.run()注意:
命令行下,可以使用使用简写
可以通过
flask run --help获取帮助,即-h, --host TEXT The interface to bind to. -p, --port INTEGER The port to bind to. --reload / --no-reload Enable or disable the reloader. By default the reloader is active if debug is enabled. --debugger / --no-debugger Enable or disable the debugger. By default --help Show this message and exit.Flask中DEBUG模式
我们在代码中制作一个错误,启动并且访问:
@app.route('/') def hello_world(): a = 1 b = 0 c = a/b #报错 return 'Hello World!' if __name__ == '__main__': app.run()访问之后会得到这个结果:
控制台倒是给出了错误提示信息,但是我们希望在浏览器也能有相应的提示信息
这时我们就要开启DEBUG模式
一运行时传递参数:
app.run(debug = True)二通过
app.deubg参数设置app.debug = True app.run()
三通过修改配置参数configapp.config.update(DEBUG=True) # app.config['DEBUG'] = True app.run()四通过mapping加载
app.config.from_mapping({'DEBUG':True}) app.run()五通过配置对象设置
configclass Config: DEBUG = True app.config.from_object(config) app.run()六通过配置文件设置
config>config.py 编辑DEBUG = True
>config.json 编辑{"DEBUG":"True"}
>app.py编辑app.config.from_pyfile('config.py') app.config.from_json('config.json')七通过环境变量
app.config.from_envvar('DEBUG')Flask路径参数的使用
比如,有一个请求访问的接口地址为
/users/11001,其中11001实际上为具体的请求参数,表明请求11001号用户的信息。此时如何从url中提取出
11001的数据?@app.route('/users/<user_id>') def user_info(user_id): print(type(user_id)) return 'hello user{}'.format(user_id)其中 <user_id> ,尖括号是固定写法,语法为 , variable 默认的数据类型是字符串。
如果需要指定类型,则要写成 converter:variable ,其中 converter 就是类型名称,可以有以下几种:
- string:如果没有指定具体的数据类型,那么默认就是使用
string数据类型。- int:数据类型只能传递
int类型。- float:数据类型只能传递
float类型。- path:数据类型和
string有点类似,都是可以接收任意的字符串,但是path可以接收路径,也就是说可以包含斜杠。- uuid:数据类型只能接收符合
uuid的字符串。uuid是一个全宇宙都唯一的字符串,一般可以用来作为表的主键。- any:数据类型可以在一个
url中指定多个路径。例如:注意:若是数据与设置的类型不能匹配,则会返回
Not Found将上面的例子以整型匹配数据,可以如下使用:
@app.route('/users/<int:user_id>') def user_info(user_id): print(type(user_id)) return f'正在获取 ID {user_id} 的用户信息' @app.route('/users/<int(min=1):user_id>') def user_info(user_id): print(type(user_id)) return f'hello user {user_id}'Flask路径参数类型转换底层
问题:为什么路径参数可以直接识别数据类型?
提示
从
werkzeug.routing导入BaseConverter类 了解底层
int路径参数底层调用IntegerConverter类来作格式判断
float路径参数底层调用FloatConverter类来作格式判断
string路径参数底层调用StringConverter类来作格式判断如果遇到需要匹配提取
/sms_codes/1688888888中的手机号数据,Flask内置的转换器就无法满足需求,此时需要自定义转换器。定义方法:
1:创建转换器类,保存匹配时的正则表达式
注意:
regex名字是固定的from werkzeug.routing import BaseConverter class MobileConverter(BaseConverter): """ 手机号格式 """ regex = r'1[3-9]\d{9}'2:将自定义的转换器告知Flask应用
app = Flask(__name__) # 将自定义转换器添加到转换器字典中,并指定转换器使用时名字为: mobile app.url_map.converters['mobile'] = MobileConverter3:在使用转换器的地方定义使用
@app.route('/sms_codes/<mobile:mob_num>') def send_sms_code(mob_num): return 'send sms code to {}'.format(mob_num)to_python:在转换器类中,实现
to_python(self,value)方法,这个方法的返回值,将会传递到 view函数中作为参数to_url:在转换器类中,实现
to_url(self,values)方法,这个方法的返回值,将会在调用url_for函数的时候生成符合要求的URL形式。#需求2:查询多个模块的数据 #传统的思路实现 @app.route('/news_list/<modules>/') def news_list(modules): #modules是路径参数 print(modules) #http://127.0.0.1:5000/news_list/hots+enter/ #需要对modules进行拆分 lm = modules.split('+') print(lm) print(lm[0]) print(lm[1]) #拆分后需要去数据库 select * from news where nmodule= 'hots' ornmoudle= 'enter' return f'你要查询的模块是:{lm}' class LiConverter(BaseConverter): # 1.在转换器类中,实现to_python(self,value)方法,这个方法的返回值,将会传递到 view函数中作为参数。 def to_python(self, value): return value.split('+') #可以对value进行加工后再返回 # 2.在转换器类中,实现to_url(self,values)方法,这个方法的返回值,将会在调用url_for函数的时候生成符合要求的URL形式。 def to_url(self, value): # return "hello" #['hots','enter']---->hots+enter return "+".join(value) app.url_map.converters['li']=LiConverterPostMan的使用
Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。
官方网站:https://www.getpostman.com/
安装
Postman最早是作用chrome浏览器插件存在的,所以,你可以到chrome商店搜索下载安装,因为部分原因,所以,大家都会找别人共享的postman插件文件来安装。
Postman提供了独立的安装包,不再依赖于Chrome浏览器了。同时支持MAC、Windows和Linux,推荐你使用这种方式安装。
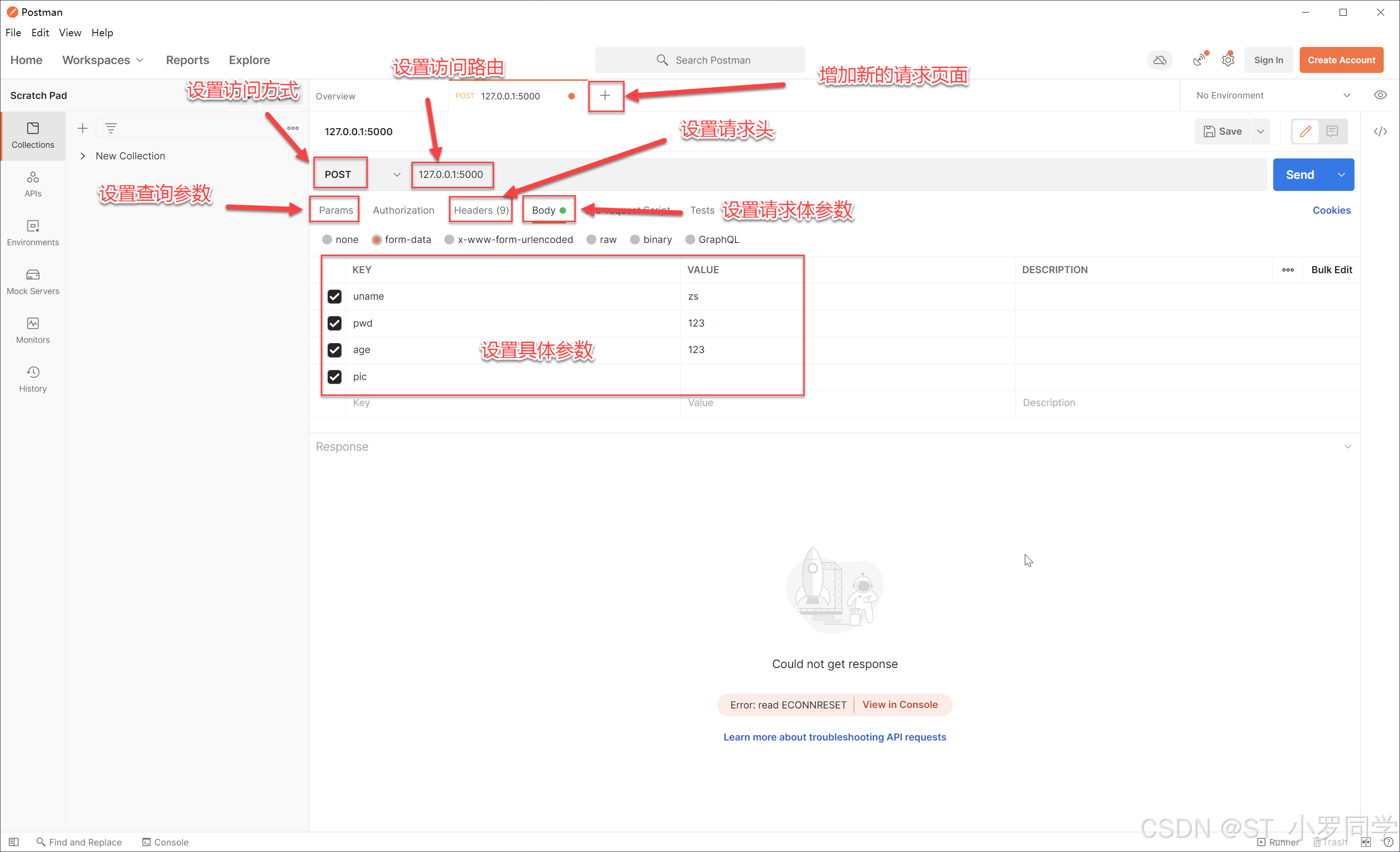
界面介绍:
查询参数的获取
给定一个网址:http://127.0.0.1:5000/test/?wd=python&ie=ok
这个网址中给了两个参数wd和ie
分别通过request.args.get()和request.values.get()两个方法获取参数值
如果你的这个页面的想要做
SEO优化,就是被搜索引擎搜索到,那么推荐使用第一种形式(path的形式)。如果不在乎搜索引擎优化,那么就可以使用第二种(查询字符串的形式)。
from flask import Flask,request app = Flask(__name__) @app.route('/') def index(): wd = request.args.get('wd') ie = request.values.get('ie') return f"Hello! {wd} == {ie}" if __name__ == '__main__': app.run(debug=True)还有一种请求体参数:
from flask import Flask,request app = Flask(__name__) @app.route('/',methods=['POST']) def index(): uname = request.form.get('uname') pwd = request.values.get('pwd') age = request.form.get('age') return f"Hello! {uname} == {pwd} == {age}" if __name__ == '__main__': app.run(debug=True)Flask上传文件
客户端上传图片到服务器,并保存到服务器中
from flask import request @app.route('/upload', methods=['POST']) def upload_file(): f = request.files['pic'] # with open('./demo.png', 'wb') as new_file: # new_file.write(f.read()) f.save('./demo.png') return '上传成功!'request其它参数的使用
属性 说明 类型 values 记录请求的数据,并转换为字符串 * form 记录请求中的表单数据 MultiDict args 记录请求中的查询参数 MultiDict cookies 记录请求中的cookie信息 Dict headers 记录请求中的报文头 EnvironHeaders method 记录请求使用的HTTP方法 GET/POST url 记录请求的URL地址 string files 记录请求上传的文件 * from flask import Flask,request app = Flask(__name__) @app.route('/args') def args(): cookies = request.cookies.get('uid') headers = request.headers.get('Content-Type') url = request.url method = request.method return f'上传成功!! {cookies} == {headers} =={url} == {method}' if __name__ =='__main__': app.run(debug=True)url_for函数的使用
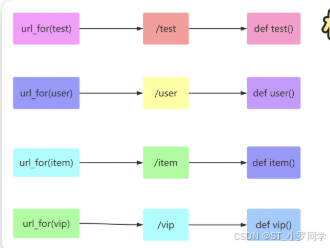
一般我们通过一个 URL就可以执行到某一个函数。如果反过来,我们知道一个函数,怎么去获得这个 URL呢?
url_for函数就可以帮我们实现这个功能。注意
url_for 函数可以接收1个及以上的参数,他接收函数名作为第一个参数
如果还出现其他的参数,则会添加到 URL 的后面作为查询参数。
@app.route('/post/list/<page>/') def my_list(page): return 'my list' @app.route('/') def hello_world(): return url_for('my_list',page=2,num=8) # return "/post/list/2?num=8"问题:为什么选择
url_for而不选择直接在代码中拼 URL 的原因有两点
- 将来如果修改了 URL ,但没有修改该 URL 对应的函数名,就不用到处去替换URL 了
- url_for() 函数会转义一些特殊字符和 unicode 字符串,这些事情 url_for 会自动的帮我们
@app.route('/login/') def login(): return 'login' @app.route('/') def hello_world(): return url_for('login', next='/') # /login/?next=/ # 会自动的将/编码,不需要手动去处理。 # url=/login/?next=%2F技巧:在定义url的时候,一定要记得在最后加一个斜杠。
1. 如果不加斜杠,那么在浏览器中访问这个url的时候,如果最后加了斜杠,那么就访问不到。这样用户体验不太好。
2. 搜索引擎会将不加斜杠的和加斜杠的视为两个不同的url。而其实加和不加斜杠的都是同一个url,那么就会给搜索引擎造成一个误解。加了斜杠,就不会出现没有斜杠的情况。
Flask重定向
永久性重定向:
http 的状态码是 301,多用于旧网址被废弃了要转到一个新的网址确保用户的访问
比如:你输入 www.jingdong.com 的时候,会被重定向到 www.jd.com ,
因为 jingdong.com 这个网址已经被废弃了,被改成 jd.com
所以这种情况下应该用永久重定向
暂时性重定向:
http 的状态码是 302,表示页面的暂时性跳转。
比如:访问一个需要权限的网址,如果当前用户没有登录,应该重定向到登录页面,
这种情况下,应该用暂时性重定向。
flask重定向是通过
redirect(location,code=302)这个函数来实现的, location表示需要重定向到的 URL, 应该配合之前讲的 url_for() 函数来使用, code 表示采用哪个重定向,默认是 302 也即 暂时性重定向, 可以修改成 301 来实现永久性重定向案例:
from flask import Flask,request,url_for,redirect app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello World!' @app.route('/login/') def login(): return '这是登录页面' #falsk中重定向 @app.route('/profile/') def proflie(): if request.args.get('name'): return '个人中心页面' else: # return redirect(url_for('login')) return redirect(url_for('login'),code=302) if __name__ == '__main__': app.run(debug=True)flask响应_响应内容
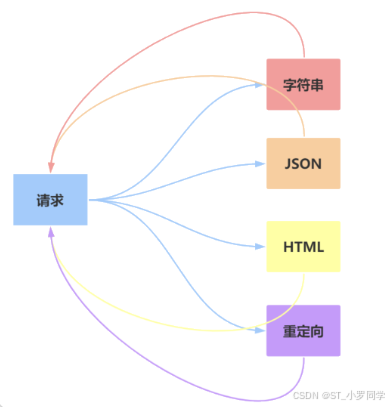
返回字符串:
from flask import redirectd @app.route('/return_str') def return_str(): return "你好,少年"返回JSON:
from flask import jsonify app.config['JSON_AS_ASCII'] = False @app.route('/return_json1') def return_json1(): json_dict = { "msg_int": 10, "msg_str": "你好,少年" } return jsonify(json_dict) @app.route('/return_json2') def return_json2(): json_dict = { "msg_int": 10, "msg_str": "你好,少年" } return json_dict元组方式
可以返回一个元组,元组中必
from flask import Response @app.route('/return_str') def return_str(): return Response("你好,少年")须至少包含一个项目,且项目应当由
(response, status)、(response, headers)或者(response, status, headers)组成。status的值会重载状态代码,headers是一个由额外头部值组成的列表 或字典status 值会覆盖状态代码, headers 可以是一个列表或字典,作为额外的消息标头值。
@app.route('/demo1') def demo1(): # return '状态码为 666', 666 # return '状态码为 666', 666, [('baidu', 'Python')] return '状态码为 666', 666, {'baidu': 'Python'}响应-自定义响应
一:创建Response
from flask import Response @app.route('/return_str') def return_str(): return Response("你好,少年")二:make_response方式
@app.route('/demo2') def demo2(): resp = make_response('make response测试') resp.headers['baidu'] = 'Python' resp.status = '404 not found' return resp
Flask中Jinja2的使用
from flask import Flask,render_template,request app = Flask(__name__) @app.route('/') def index(): return render_template('index.html') @app.route('/login') def login(): user = request.args.get('user') return render_template('index.html',user = user) if __name__ =='__main__': app.run(debug=True)思考 : 网站如何向客户端返回一个漂亮的页面呢?
提示 :
- 漂亮的页面需要
html、css、js.- 可以把这一堆字段串全都写到视图中, 作为
HttpResponse()的参数,响应给客户端问题
- 视图部分代码臃肿, 耦合度高
- 这样定义的字符串是不会出任何效果和错误的
- 效果无法及时查看.有错也不容易及时发现
解决问题
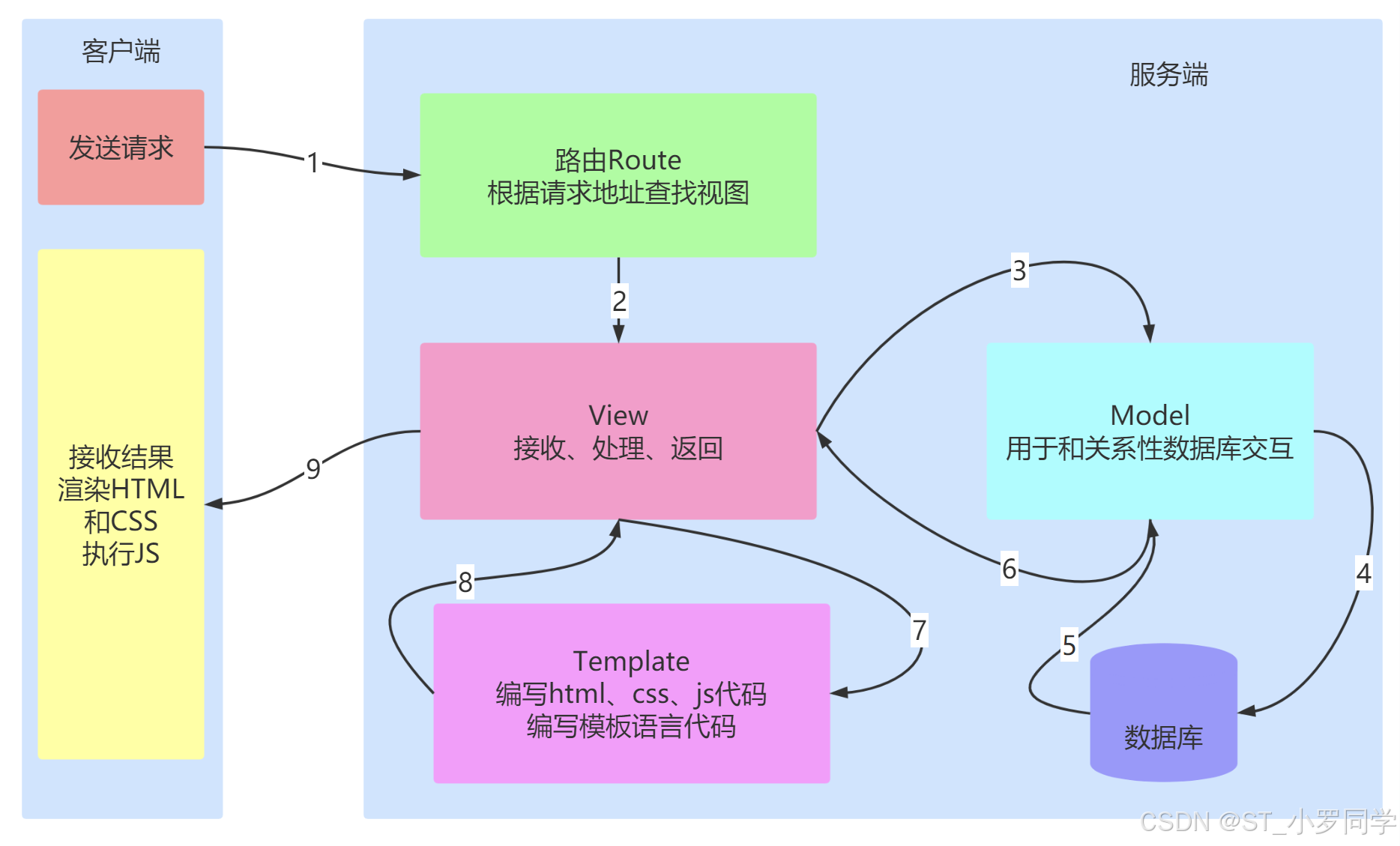
模板 Template
MVT设计模式中的T,TemplateM全拼为Model,与MVC中的M功能相同,负责和数据库交互,进行数据处理。
V全拼为View,与MVC中的C功能相同,接收请求,进行业务处理,返回应答。
T全拼为Template,与MVC中的V功能相同,负责封装构造要返回的html。
即:
在 Flask中,配套的模板是 Jinja2,Jinja2的作者也是Flask的作者。这个模板非常的强大,并且执行效率高。
template使用步骤
创建模板
- 在
应用同级目录下创建模板文件夹templates. 文件夹名称固定写法.- 在
templates文件夹下, 创建应用同名文件夹. 例,Book- 在
应用同名文件夹下创建网页模板文件. 例 :index.html设置模板查找路径
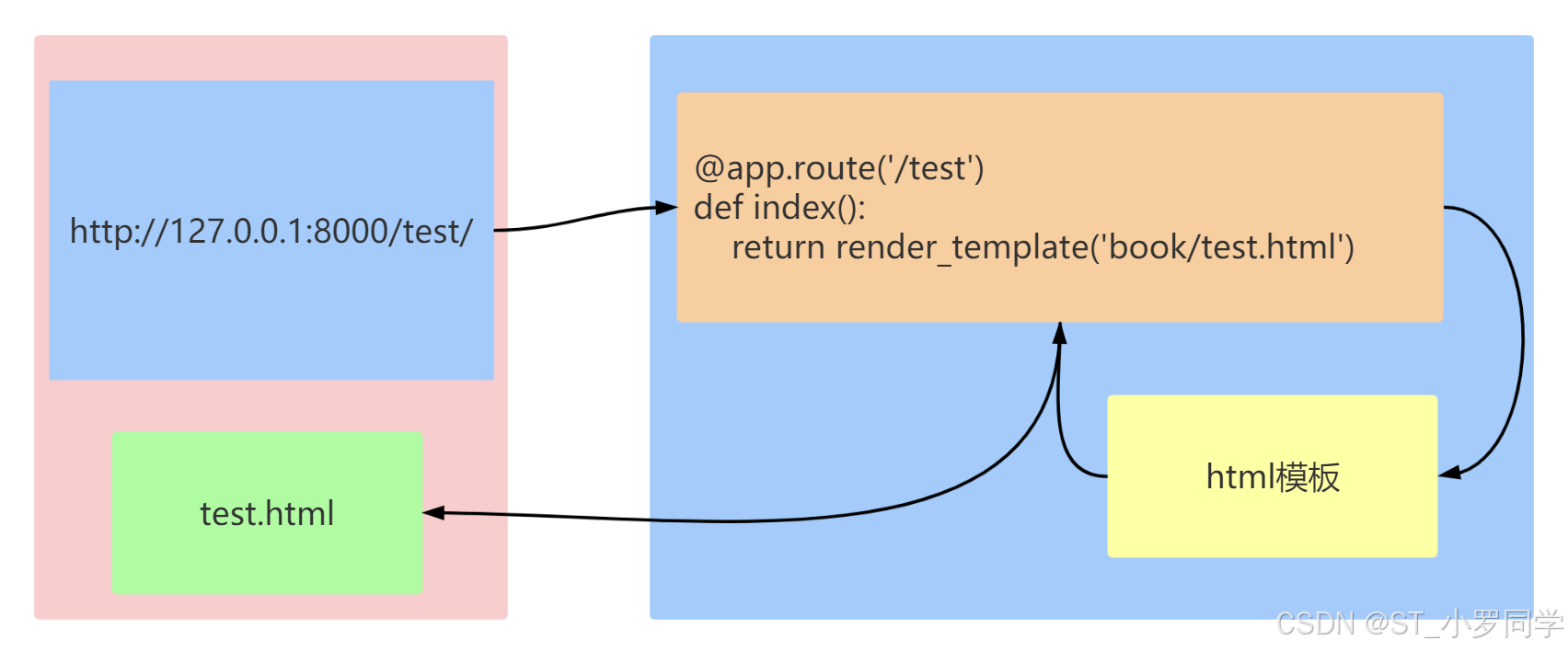
模板处理数据
from flask import Flask,render_template app = Flask(__name__) @app.route('/test') def index(): return render_template('index.html')template模板-传参
在使用
render_template渲染模版的时候,可以传递关键字参数(命名参数)。
案例:
from flask import Flask,render_template app = Flask(__name__) @app.route('/') def hello_world(): return render_template('index.html',uname='baidu')index.html代码:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>baidu</title> </head> <body> 从模版中渲染的数据 <br> {{ uname}} </body> </html>小技巧:
如果你的参数项过多,那么可以将所有的参数放到一个字典中,然后在传这个字典参数的时候,使用两个星号,将字典打散成关键字参数(也叫命名参数)
即:获取方式是:
{{childrens.name}}或者{{childrens['name']}}@app.route('/') def hello_world(): context = { 'uname': 'momo', 'age': 18, 'country': 'china', 'childrens': { 'name': 'mjz', 'height': '62cm' } } return render_template('index.html',**context)模板中使用url_for函数
模版中也可使用
url_for,和后台视图函数中的url_for使用起来基本是一模一样的。在模板中使用函数,需要在函数 左右两边加上2个
{}例如:
{{ url_for(func) }}注意:无论是 路径参数 还是 查询式参数 都可以直接传递
@app.route('/accounts/login/<name>/') def login(name): print(name) return '通过URL_FOR定位过来的!!!'html代码:
<a href="{{ url_for('login',p1='abc',p2='ddd',name='baidu') }}">登录</a>Flask过滤器介绍
有时候我们想要在模版中对一些变量进行处理,那么就必须需要类似于Python中的函数一样,可以将这个值传到函数中,然后做一些操作。
在模版中,过滤器相当于是一个函数,把当前的变量传入到过滤器中,然后过滤器根据自己的功能,再返回相应的值,之后再将结果渲染到页面中
@app.route('/') def hello_world(): return render_template('index.html',postion=-1)<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>LTY</title> </head> <body> <h3>过滤器的基本使用</h3> <p>位置的绝对值为[未使用过滤器]:{{ postion}}</p> <p>位置的绝对值为[使用过滤器]:{{ postion|abs}}</p> </body> </html>Jinja模板自带过滤器
过滤器是通过管道符号
|使用的,例如:{ name|length }}将返回name的长度。过滤器相当于是一个函数,把当前的变量传入到过滤器中,然后过滤器根据自己的功能,再返回相应的值,之后再将结果渲染到页面中。
Jinja2中内置了许多过滤器https://jinja.palletsprojects.com/en/3.0.x/templates/#filters
过滤器名 解释 举例 abs(value) 返回一个数值的绝对值 -1|abs int(value) 将值转换为int类型 float(value) 将值转换为float类型 string(value) 将变量转换成字符串 default(value,default_value,boolean=false) 如果当前变量没有值,则会使用参数中的值来代替。如果想使用python的形式判断是否为false,则可以传递boolean=true。也可以使用or来替换 name|default('xiaotuo') safe(value) 如果开启了全局转义,那么safe过滤器会将变量关掉转义 content_html|safe escape(value)或e 转义字符,会将<、>等符号转义成HTML中的符号 content|escape或content|e。 first(value) 返回一个序列的第一个元素 names|firstformat(value,*arags,**kwargs) 格式化字符串 {{ "%s"-"%s"|format('Hello?',"Foo!") }}输出 Hello?-Fool!last(value) 返回一个序列的最后一个元素。示例: names|lastlength(value) 返回一个序列或者字典的长度。示例: names|lengthjoin(value,d='+') 将一个序列用d这个参数的值拼接成字符串 lower(value) 将字符串转换为小写 upper(value) 将字符串转换为小写 replace(value,old,new) 替换将old替换为new的字符串 truncate(value,length=255,killwords=False) 截取length长度的字符串 striptags(value) 删除字符串中所有的HTML标签,如果出现多个空格,将替换成一个空格 trim 截取字符串前面和后面的空白字符 wordcount(s) 计算一个长字符串中单词的个数
defalut过滤器:<body> <h1>default过滤器</h1> 过滤前的昵称数据是:{{nick_name}}<br> 过滤后的昵称数据是:{{nick_name | default('用户1',boolean=true)}}<br> 过滤后的昵称数据是:{{nick_name or '用户2'}}<br> </body>转义字符:
<body> <h1>转义字符过滤器</h1> <!-- 模板中默认 做了转义字符的效果 --> 转义前的数据是:{{ info | safe }} <!-- 不转义:不将特殊字符转换成 <类似的数据 --> {% autoescape true %} <!-- false代表不再转义特殊字符 / true 转义特殊字符 <--> {{info }} <!-- 转义:将特殊字符转换成 <类似的数据 --> {% endautoescape %} </body>其它过滤器:
<body> <h1>其它过滤器</h1> 绝对值:{{ -6 | abs }}<br> 小数: {{ 6 | float }}<br> 字符串:{{ 6 | string }}<br> 格式化:{{'%s--%s' | format('我','你')}}<br> 长度:{{'我是九,你是三,除了你,还是你' |length}}<br> 最后一个:{{'我是九,你是三,除了你,还是你' |last}}<br> 第一个:{{'我是九,你是三,除了你,还是你' |first}}<br> 统计次数: {{'我是九,你是三,除了你,还是你' | wordcount }}<br> 替换:{{'===我是九,你是三,除了你,还是你====' |replace('我是九,你是三,除了你,还是你','拿着,这个无限额度的黑卡,随便刷')}} </body>小提示:jinja2模板 默认全局开启了自动转义功能
safe过滤器:可以关闭一个字符串的自动转义
escape过滤器:对某一个字符串进行转义
autoescape标签,可以对他包含的代码块关闭或开启自动转义
{% autoescape true/false %}代码块{% endautoescape %}自定义内容过滤器
只有当系统提供的过滤器不符合需求后,才须自定义过滤器
过滤器本质上就是一个函数。
如果在模版中调用这个过滤器,那么就会将这个变量的值作为第一个参数传给过滤器这个函数,
然后函数的返回值会作为这个过滤器的返回值。
需要使用到一个装饰器:
@app.template_filter('过滤器名称')#将模版设置为自动加载模式 app.config['TEMPLATES_AUTO_RELOAD']=True @app.template_filter('cut') def cut(value): value=value.replace("我是九你是三,除了你还是你",'你不用多好,我喜欢就好') return value<p>使用自定义过滤器:{{新闻内容值|cut}}</p>自定义时间过滤器
from datetime import datetime #需求:操作发布新闻 与现在的时间间隔 @app.template_filter('handle_time') def handle_time(time): """ time距离现在的时间间隔 1. 如果时间间隔小于1分钟以内,那么就显示“刚刚” 2. 如果是大于1分钟小于1小时,那么就显示“xx分钟前” 3. 如果是大于1小时小于24小时,那么就显示“xx小时前” 4. 如果是大于24小时小于30天以内,那么就显示“xx天前” 5. 否则就是显示具体的时间 2030/10/20 16:15 """ if isinstance(time, datetime): now = datetime.now() timestamp = (now - time).total_seconds() if timestamp < 60: return "刚刚" elif timestamp >= 60 and timestamp < 60 * 60: minutes = timestamp / 60 return "%s分钟前" % int(minutes) elif timestamp >= 60 * 60 and timestamp < 60 * 60 * 24: hours = timestamp / (60 * 60) return '%s小时前' % int(hours) elif timestamp >= 60 * 60 * 24 and timestamp < 60 * 60 * 24 * 30: days = timestamp / (60 * 60 * 24) return "%s天前" % int(days) else: return time.strftime('%Y/%m/%d %H:%M') else: return time<p>发布时间:{{新闻创建时间|handle_time}}</p>Jinja2流程控制-选择结构
所有的控制语句都是放在
{% ... %}中,并且有一个语句{% endxxx %}来进行结束!if:if语句和python中的类似,可以使用
>,<,<=,>=,==,!=来进行判断,也可以通过and,or,not,()来进行逻辑合并操作<h1>选择结构</h1> {% if uname == 'company_A' %} <p>A公司</p> {% endif %} {% if uname == 'company_A' %} <p>A公司</p> {% else %} <p>B公司</p> {% endif %} {% if uname == 'company_A' %} <p>A公司</p> {% elif uname == 'company_B'%} <p>B公司</p> {% else %} <p>其他公司</p> {% endif %} {% if age >= 18 %} <p>{{ age }}岁,成年人,可以通宵打游戏</p> {% else %} <p>{{ age }}岁,未成年人,可以通宵学习</p> {% endif %}@app.route('/') def index(): uname = 'company_A' return render_template('index2.html',uname = uname)案例练习:
Python代码:
from flask import Flask,render_template,request app = Flask(__name__) @app.route('/') def index(): return render_template('index.html') @app.route('/login') def login(): user = request.args.get('user') return render_template('index.html',user = user) if __name__ =='__main__': app.run(debug=True)template代码:
<body> <span>中国大陆</span> {% if not user %} <a href="{{url_for('login',user='吕布')}}">亲,请登录</span></a> <span>免费注册</span> {% else %} <span>{{ user }}</span> {% endif %} <span>手机淘宝</span> </body>Jinja2流程控制-循环结构
for...in...for循环可以遍历任何一个序列包括列表、字典、元组。并且可以进行反向遍历,以下将用几个例子进行解释:{% for x in range(1,10) %} <tr> {% for y in range(1,x + 1) %} <td>{{y}}*{{x}}={{ x*y }}</td> {% endfor %} </tr> {% endfor %}// 列表 <ul> {% for user in users%} <li>{{ user}}</li> {% endfor %} </ul>// 遍历字典 <tr> {% for key in person.keys() %} <td>{{ key}}</td> {% endfor %} </tr> <tr> {% for val in person.values() %} <td>{{ val}}</td> {% endfor %} </tr> <tr> {% for item in person.items() %} <td>{{ item}}</td> {% endfor %} </tr> <tr> {% for key,value in person.items() %} <td>{{ value}}</td> {% endfor %} </tr>如果序列中没有值的时候,进入else
反向遍历用过滤器 reverse:
<ul> {% for user in users|reverse %} <li>{{ user}}</li> {% else %} <li>没有任何用户</li> {% endfor %} </ul>并且Jinja中的for循环还包含以下变量,可以用来获取当前的遍历状态:
变量 描述 loop.index 当前迭代的索引(从1开始) loop.index0 当前迭代的索引(从0开始) loop.first 是否是第一次迭代,返回True或False loop.last 是否是最后一次迭代,返回True或False loop.length 7序列的长度 总结
在
jinja2中的for循环,跟python中的for循环基本上是一模一样的,也是for...in...的形式。并且也可以遍历所有的序列以及迭代器,唯一不同的是,jinja2中的for循环没有break和continue语句宏的使用
模板中的宏跟python中的函数类似,可以传递参数,但是不能有返回值
可以将一些经常用到的代码片段放到宏中,然后6把一些不固定的值抽取出来当成一个变量
提示:实际开发中,不会把宏在一个页面内定义 并直接使用,一般把宏定义放到一个专门的文件夹中,方便进行统一管理,之后,哪一个页面需要使用某个宏,需要导入宏才能使用
定义宏:
{% macro input(name,value="",type="text") %} <input type="{{type}}" name="{{name}}" value="{{value}}"> {% endmacro %}使用宏:
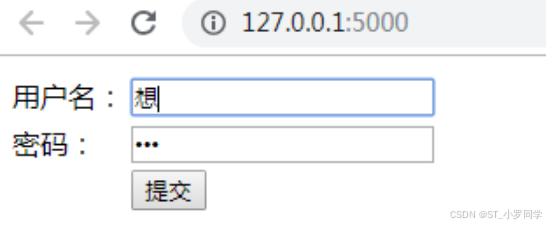
<table> <tr> <td>用户名:</td> <td>{{ input('username')}}</td> </tr> <tr> <td>密码:</td> <td> {{ input('pwd',type='password') }} </td> </tr> <tr> <td></td> <td>{{ input(value='提交',type='submit') }}</td> </tr> </table>访问结果:
导入宏方式:
1 from '宏文件的路径' import 宏的名字 [as xxx]。
{% from "users/users.html" import input as inp %}2 import "宏文件的路径" as xxx [with context]
{% import "users/users.html" as usr with context %}注意
1. 宏文件路径,不要以相对路径去寻找,都要以
templates作为绝对路径去找2. 如果想要在导入宏的时候,就把当前模版的一些参数传给宏所在的模版,那么就应该在导入的时候使用
with context导入模板include
这个标签相当于是直接将指定的模版中的代码复制粘贴到当前位置。
include标签,如果想要使用父模版中的变量,直接用就可以了,不需要使用with context。
include的路径,也是跟import一样,直接从templates根目录下去找,不要以相对路径去找。<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>SXT</title> </head> <body> <!--通过include 引入头部log信息--> {% include "common/head.html" %} <div> 这是首页内容 {{ major }} </div> <hr> <!--通过include 引入底部版权信息--> {% include "common/footer.html" %} </body> </html>set与with标签
set的使用:在模版中,可以使用
set语句来定义变量一旦定义了这个变量,那么在后面的代码中,都可以使用这个变量,就类似于Python的变量定义是一样的
<!--set语句来定义变量,之后,那么在后面的代码中,都可以使用这个变量--> {% set uname='lty'%} <p>用户名:{{ uname }}</p>with语句:
with语句定义的变量,只能在with语句块中使用,超过了这个代码块,就不能再使用了<!--with语句来定义变量,只有在指定区域 才能使用这个变量--> {% with classroom='python202'%} <p>班级:{{ classroom }}</p> {% endwith %}注意:关于定义的变量,
with语句也不一定要跟一个变量,可以定义一个空的with语句,需要在指定的区域才能使用的情况,可以set与with组合使用。{% with %} {% set pname='李思思' %} <p>娱乐县县长:{{ pname }}</p> {% endwith %}静态资源statics的引入
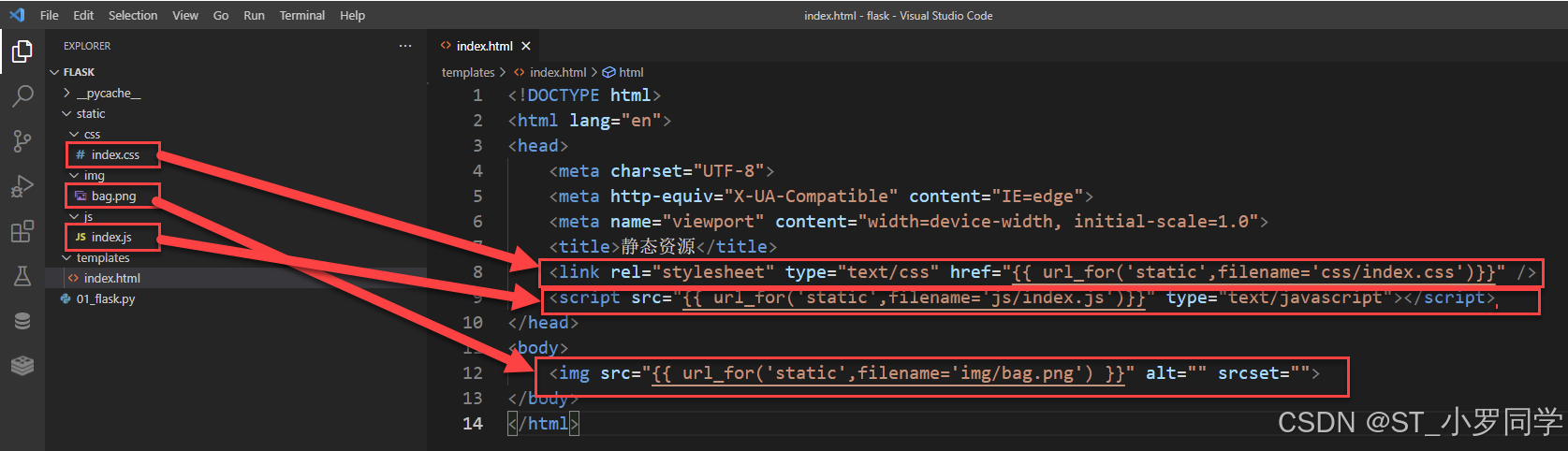
静态文件:css文件 js文件 图片文件等文件
加载静态文件使用的是
url_for函数。然后第一个参数需要为static,第二个参数需要为一个关键字参数filename='路径'。注意:路径查找,要以当前项目的
static目录作为根目录{{ url_for("static",filename='xxx') }}
模板继承
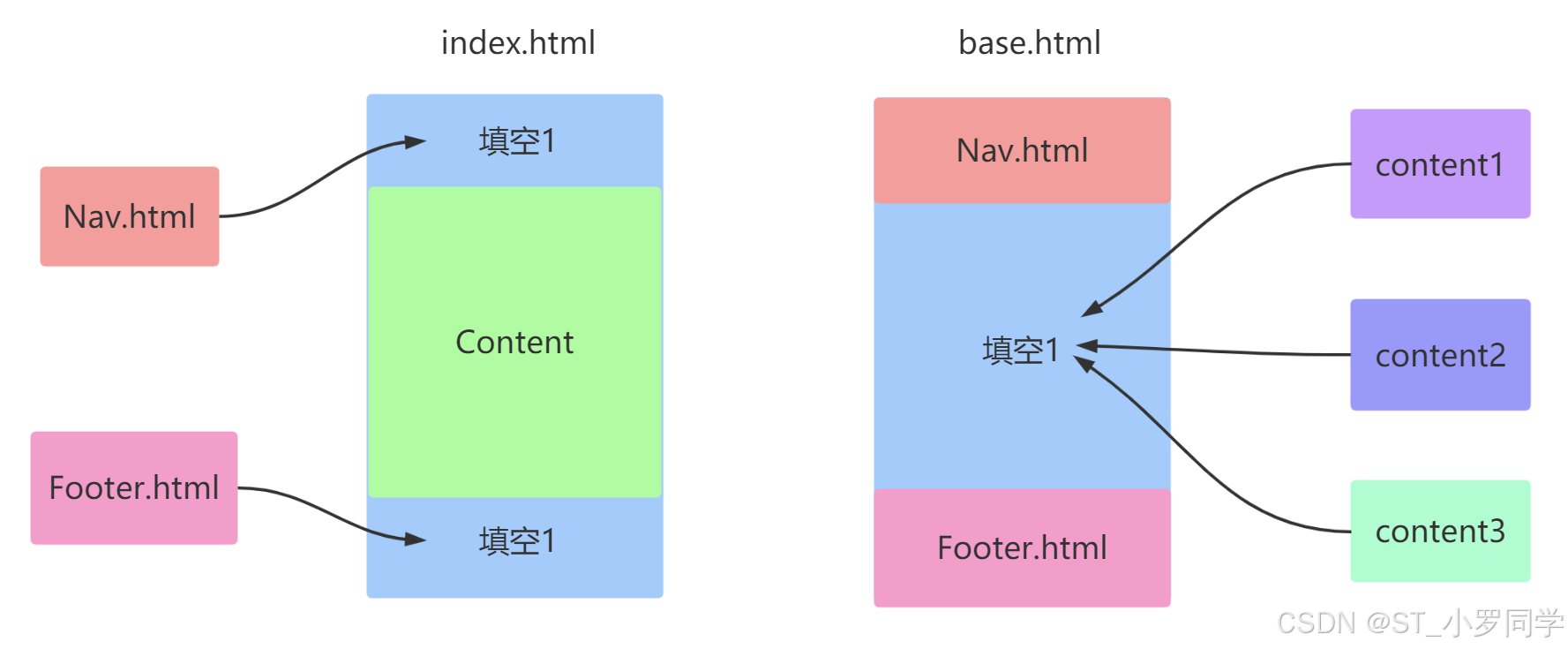
为什么需要模版继承?
模版继承可以把一些公用的代码单独抽取出来放到一个父模板中以后子模板直接继承就可以使用了。这样可以重复的利用代码,并且以后修改起来也比较方便
模版继承语法:使用
extends语句,来指明继承的父模板。父模板的路径,也是相对于templates文件夹下的绝对路径{% extends "base.html" %}block语法:一般在父模版中,定义一些公共的代码。子模板可能要根据具体的需求实现不同的代码。这时候父模版就应该有能力提供一个接口,让子模板来实现。从而实现具体业务需求的功能。
父模板:
{% block block的名字 %} {% endblock %}子模板:
{% block block的名字 %} 子模板中的代码 {% endblock %}调用父模版代码block中的代码 默认情况下,子模板如果实现了父模版定义的block。那么子模板block中的代码就会覆盖掉父模板中的代码。如果想要在子模板中仍然保持父模板中的代码,那么可以使用
{{ super( ) }}来实现父模板:
{% block block_body %} <p style="background-color: blue">我是 父模版block_body处的内容</p> {% endblock %}子模板:
{% block block_body%} {{ super() }} <p style="background-color: green">我是 子模版block_body处的内容</p> {% endblock %}调用另外一个block中的代码:如果想要在另外一个模版中使用其他模版中的代码。那么可以通过
{{ self.其他block名字() }}就可以了{% block title %} lty页面 {% endblock %} {% block block_body%} {{ self.title() }} <p style="background-color: green">我是子模版block_body处的内容</p> {% endblock %}注意:
1. 子模板中的代码,第一行,应该是
extends2. 子模板中,如果要实现自己的代码,应该放到block中。如果放到其他地方,那么就不会被渲染
Flask视图入门
add_url_rule
add_url_rule(rule,endpoint=None,view_func=None)这个方法用来添加url与视图函数的映射。如果没有填写
endpoint,那么默认会使用view_func的名字作为endpoint。以后在使用url_for的时候,就要看在映射的时候有没有传递endpoint参数,如果传递了,那么就应该使用endpoint指定的字符串,如果没有传递,那么就应该使用view_func的名字。def my_list(): return "我是列表页" app.add_url_rule('/list/',endpoint='lty',view_func=my_list)app.route原理剖析:这个装饰器底层,其实也是使用
add_url_rule来实现url与视图函数映射的。案例:
from flask import Flask,url_for app = Flask(__name__) @app.route('/',endpoint='index') def index(): print(url_for('show')) print(url_for('index')) return "Hello" def show_me(): return "这个介绍信息!!" # endpoint 没有设置,url_for中就写函数的名字,如果设置了,就写endpoint的值 app.add_url_rule('/show_me',view_func=show_me,endpoint='show') # @app.route 底层就是使用的 add_url_rule if __name__ =='__main__': app.run(debug=True)类视图的使用
之前我们接触的视图都是函数,所以一般简称函数视图。其实视图也可以基于类来实现,类视图的好处是支持继承,但是类视图不能跟函数视图一样,写完类视图还需要通过
app.add_url_rule(url_rule,view_func)来进行注册。标准类视图使用步骤
1. 标准类视图,必须继承自
flask.views.View2. 必须实现
dispatch_request方法,以后请求过来后,都会执行这个方法。这个方法的返回值就相当于是之前的视图函数一样。也必须返回Response或者子类的对象,或者是字符串,或者是元组。3. 必须通过
app.add_url_rule(rule,endpoint,view_func)来做url与视图的映射。view_func这个参数,需要使用类视图下的as_view类方法类转换:ListView.as_view('list')。4. 如果指定了
endpoint,那么在使用url_for反转的时候就必须使用endpoint指定的那个值。如果没有指定endpoint,那么就可以使用as_view(视图名字)中指定的视图名字来作为反转。案例:
from flask import Flask,url_for from flask.views import View app= Flask(__name__) @app.route('/') def index(): # print(url_for('mylist')) print(url_for('my')) return 'Hello' class ListView(View): def dispatch_request(self): return '返回了一个List的内容!!' # app.add_url_rule('/list',view_func=ListView.as_view('mylist')) app.add_url_rule('/list',endpoint='my',view_func=ListView.as_view('mylist')) # 用于测试 with app.test_request_context(): print(url_for('my')) if __name__ =='__main__': app.run(debug=True)类视图的好处:
1.可以继承,把一些共性的东西抽取出来放到父视图中,子视图直接拿来用就可以了。
2.但是也不是说所有的视图都要使用类视图,这个要根据情况而定。视图函数用得最多。
from flask import Flask,jsonify from flask.views import View app = Flask(__name__) # 需求:返回的结果都必须是json数据 class BaseView(View): def get_data(self): raise NotImplementedError def dispatch_request(self): return jsonify(self.get_data()) class JsonView(BaseView): def get_data(self): return {'uname':'吕布','age':20} class Json2View(BaseView): def get_data(self): return [ {'name':'CSGO','lua':'Python'}, {'name':'CSGO2','lua':'Python'}, ] app.add_url_rule('/base',view_func=BaseView.as_view('base')) app.add_url_rule('/json',view_func=JsonView.as_view('json')) app.add_url_rule('/json2',view_func=Json2View.as_view('json2')) if __name__ =='__main__': app.run(debug=True)案例:
from flask import Flask,render_template from flask.views import View app = Flask(__name__) class BaseView(View): def __init__(self): self.msg = { 'main':'CSGO又更新了!!123' } class LoginView(BaseView): def dispatch_request(self): my_msg = '神奇的登录功能' self.msg['my_msg'] = '神奇的登录功能' # return render_template('login.html',msg= self.msg.get('main'),my_msg = my_msg) return render_template('login.html',**self.msg) class RegisterView(BaseView): def dispatch_request(self): self.msg['my_msg'] = '快捷的注册功能' # return render_template('register.html',msg= self.msg.get('main'),my_msg = my_msg) return render_template('register.html',**self.msg) app.add_url_rule('/login',view_func= LoginView.as_view('login')) app.add_url_rule('/register',view_func= RegisterView.as_view('register')) if __name__ == '__main__': app.run(debug=True)基于调度方法的类视图
1.基于方法的类视图,是根据请求的
method来执行不同的方法的。如果用户是发送的get请求,那么将会执行这个类的get方法。如果用户发送的是post请求,那么将会执行这个类的post方法。其他的method类似,比如delete、put2. 这种方式,可以让代码更加简洁。所有和
get请求相关的代码都放在get方法中,所有和post请求相关的代码都放在post方法中。就不需要跟之前的函数一样,通过request.method == 'GET'案例:HTML
<form action="/login/" method="post"> <table> <tr> <td>账号:</td> <td><input type="text" name="uname"></td> </tr> <tr> <td>密码:</td> <td><input type="password" name="pwd"></td> </tr> <tr> <td></td> <td><input type="submit" value="立即登录"></td> </tr> <tr> <td colspan="2"> {# <font color="red">{{ error }}</font>#} {# 优化写法 :判断 #} {% if error %} <font color="red">{{ error }}</font> {% endif %} </td> </tr> </table> </form>Python:
#定义一个基于方法调度的 类视图 class LoginView(views.MethodView): def get(self): return render_template('login.html') def post(self): #模拟实现 #拿到前端页面传过来的 账号 和密码 去数据库做查询操作 查询到 (跳转主页面) ,反之跳转到login.html页面并给出错误提示信息 uname = request.form['uname'] pwd = request.form['pwd'] if uname=="sxt" and pwd =="123": return render_template('index.html') else: return render_template('login.html',error="用户名或者密码错误") # 注册类视图 app.add_url_rule('/login/', view_func=LoginView.as_view('my_login'))改进1:
class LoginView(views.MethodView): def get(self,error=None): return render_template('login.html',error=error) def post(self): #模拟实现 #拿到前端页面传过来的 账号 和密码 去数据库做查询操作 查询到 (跳转主页面) ,反之跳转到login.html页面并给出错误提示信息 uname = request.form['uname'] pwd = request.form['pwd'] if uname=="lty007" and pwd =="123": return render_template('index.html') else: return self.get(error="用户名或者密码错误") # 注册类视图 app.add_url_rule('/login/',view_func=LoginView.as_view('my_login'))改进2:基于调度方法的类视图, 通常get()方法处理get请求,post()方法处理post请求,为了便于管理,不推荐post方法和get方法互相调用
class LoginView(views.MethodView): def __jump(self,error=None): return render_template('login.html', error=error) def get(self, error=None): return self.__jump() def post(self): # 模拟实现 #拿到前端页面传过来的 账号 和密码 去数据库做查询操作 查询到 (跳转主页面) ,反之跳转到login.html页面并给出错误提示信息 uname = request.form['uname'] pwd = request.form['pwd'] if uname == "lty007" and pwd == "123": return render_template('index.html') else: return self.__jump(error="用户名或者密码错误") # 注册类视图 app.add_url_rule('/login/',view_func=LoginView.as_view('my_login'))视图装饰器的使用
简言之,python装饰器就是用于拓展原来函数功能的一种函数,这个函数的特殊之处在于它的返回值也是一个函数,使用python装饰器的好处就是在不用更改原函数的代码前提下给函数增加新的功能。
一:在视图函数中使用自定义装饰器,那么自己定义的装饰器必须放在
app.route下面。否则这个装饰器就起不到任何作用。
案例1:查看设置个人信息时,只有检测到用户已经登录了才能查看,若没有登录,则无法查看并给出提示信息
//定义装饰器 def login_required(func): @wraps(func) def wrapper(*arg,**kwargs): uname = request.args.get('uname') pwd = request.args.get('pwd') if uname == 'zs' and pwd == '123': logging.info(f'{uname}:登录成功') return func(*arg,**kwargs) else: logging.info(f'{uname}:尝试登录,但没成功') return '请先登录' return wrapper//使用装饰器 @app.route('/settings/') @login_requierd def settings(): return '这是设置界面'二:在类视图中使用装饰器,需要重写类视图的一个类属性
decorators,这个类属性是一个列表或者元组都可以,里面装的就是所有的装饰器。案例2:查看设置个人信息时,只有检测到用户已经登录了才能查看,若没有登录,则无法查看并给出提示信息
class ProfileView(views.View): decorators = [login_requierd] def dispatch_request(self): return '这是个人中心界面' app.add_url_rule('/profile/',view_func=ProfileView.as_view('profile'))Blueprint蓝图的介绍
在Flask中,使用蓝图Blueprint来分模块组织管理。
蓝图实际可以理解为是存储一组视图方法的容器对象,其具有如下特点:
- 一个应用可以具有多个Blueprint
- 可以将一个Blueprint注册到任何一个未使用的URL下比如
“/user”、“/goods”- Blueprint可以单独具有自己的模板、静态文件或者其它的通用操作方法,它并不是必须要实现应用的视图和函数的
- 在一个应用初始化时,就应该要注册需要使用的Blueprint
注意:Blueprint并不是一个完整的应用,它不能独立于应用运行,而必须要注册到某一个应用中。
使用方式:
1.创建一个蓝图对象
user_bp=Blueprint('user',__name__)2.在这个蓝图对象上,
@user_bp.route('/') def user_profile(): return 'user_profile'3.在应用对象上注册这个蓝图对象
app.register_blueprint(user_bp)单文件蓝图:可以将创建蓝图对象与定义视图放到一个文件中
import logging from flask.blueprints import Blueprint from flask import Flask app = Flask(__name__) logging.basicConfig(level=logging.INFO) @app.route('/') def index(): logging.info('输出了Hello!!') return 'Hello' user = Blueprint('user', __name__) @user.route('/user') def index(): return '用户模板' app.register_blueprint(user) if __name__ =='__main__': app.run(debug=True)指定蓝图的url前缀:在应用中注册蓝图时使用
url_prefix参数指定app.register_blueprint(user_bp, url_prefix='/user') app.register_blueprint(goods_bp, url_prefix='/goods')蓝图的目录结构
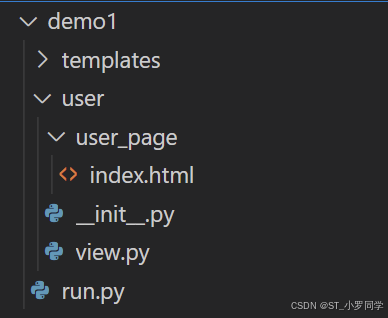
为了让项目代码更加清晰,可以通过将代码分在不同的文件里进行管理
根据功能模块:对于一个打算包含多个文件的蓝图,通常将创建蓝图对象放到Python包的
__init__.py文件中--------- project # 工程目录 |------ main.py # 启动文件 |------ user #用户蓝图 | |--- __init__.py # 此处创建蓝图对象 | |--- view.py | |--- ... |------ goods # 商品蓝图 | |--- __init__.py | |--- ... |...根据技术模块:
--------- project # 工程目录 |------ main.py # 启动文件 |------ view #用户蓝图 | |--- user.py # 此处创建蓝图对象 | |--- item.py | |--- view.py | |--- ... |...# main.py from flask import Flask import logging app = Flask(__name__) logging.basicConfig(level=logging.INFO) @app.route('/') def index(): logging.info('输出了Hello!!') return 'Hello' from user import user app.register_blueprint(user) if __name__ =='__main__': app.run(debug=True) # __init__.py from flask.blueprints import Blueprint user = Blueprint('user', __name__) from user import view # view.py from user import user @user.route('/user') def index(): return '用户模板'蓝图中模版文件
寻找规则
如果项目中的templates文件夹中有相应的模版文件,就直接使用了。
如果项目中的templates文件夹中没有相应的模版文件,那么就到在定义蓝图的时候指定的路径中寻找。
- 并且蓝图中指定的路径可以为相对路径,相对的是当前这个蓝图文件所在的目录
因为这个蓝图文件是在user/view.py,那么就会到blueprints这个文件夹下的user_page文件夹中寻找模版文件。
常规:蓝图文件在查找模版文件时,会以templates为根目录进行查找
user_bp = Blueprint('user',__name__,url_prefix='/user',template_folder='user_page')注意
个性化coder喜欢在【创建蓝图对象的时候】 指定 模版文件的查找路径,如下
news_bp =Blueprint('news',__name__,url_prefix='/news',template_folder='news_page')只有确定templates目录下没有对应的 html文件名的时候,才会去蓝图文件指定的目录下查找,指定才会生效
若templates目录下,有一个与蓝图文件指定的目录下同名的一个 html文件时,优先走templates目录下的东西
蓝图中静态文件
蓝图内部静态文件:蓝图对象创建时不会默认注册静态目录的路由。需要我们在创建时指定
static_folder参数。下面的示例将蓝图所在目录下的static_admin目录设置为静态目录user=Blueprint("user",__name__,static_folder='user_static') app.register_blueprint(admin,url_prefix='/user')<body> <h1>模板静态文件</h1> <video src="/user/user_static/aaa.mp4" autoplay width="50%" loop="loop" muted='muted'></video> </body>也可通过
static_url_path改变访问路径user = Blueprint('user',__name__,template_folder='user_page',static_folder='user_static',static_url_path='/static') app.register_blueprint(user,url_prefix='/user')<body> <h1>模板静态文件</h1> <video src="/user/static/aaa.mp4" autoplay width="50%" loop="loop" muted='muted'></video> </body>总结
【掌握】查找方式1:查找静态文件时,正常情况下,会以static为根目录进行查找
<link href="{{ url_for('user.static',filename='news_list.css') }}" rel="stylesheet" type="text/css">【了解】查找方式2:查找静态文件时,非正常情况下,需要用url_for('蓝图的名字.static'),然后会去蓝图对象在创建时指定的静态文件夹目录下 去查找静态文件
user_bp = Blueprint('user',__name__,url_prefix='/user',static_folder='user_statics') <link href="{{ url_for('user.static',filename='user.css') }}" rel="stylesheet" type="text/css">蓝图url_for函数
如果使用蓝图,那么以后想要反转蓝图中的视图函数为url,就应该在使用url_for的时候指定这个蓝图名字。app类中、模版中、同一个蓝图类中都是如此。否则就找不到这个endpoint
html文件中:
<a href="{{ url_for('user.user_list')}}">新闻列表 OK写法</a> {# <a href="{{ url_for('user_list')}}">新闻列表 no Ok写法</a>#}python文件中:
from flask import Blueprint,render_template,url_for user_bp =Blueprint('news',__name__,url_prefix='/user',template_folder='user_page',static_folder='user_static') @user_bp.route('/list/') def user_list(): #如下写法:才找得到 url_for('蓝图名称.方法名') print(url_for('user.user_list'))#/user/list/ print(url_for('user.user_detail')) #/user/detail/ return render_template('user_list.html') @user_bp.route('/detail/') def user_detail(): return '用户详情页面'蓝图子域名实现
蓝图实现子域名:
1. 使用蓝图技术。
2. 在创建蓝图对象的时候,需要传递一个
subdomain参数,来指定这个子域名的前缀。cms_bp= Blueprint('cms',__name__,subdomain='cms')3. 需要在主app文件中,需要配置app.config的SERVER_NAME参数。例如:
app.config['SERVER_NAME']='baidu.com:5000'4. 在windows:
C:\Windows\System32\drivers\etc下,找到hosts文件,然后添加域名与本机的映射。Linux:/etc/hosts注意
- ip地址不能有子域名
- localhost也不能有子域名
Flask高级
Cookie的介绍
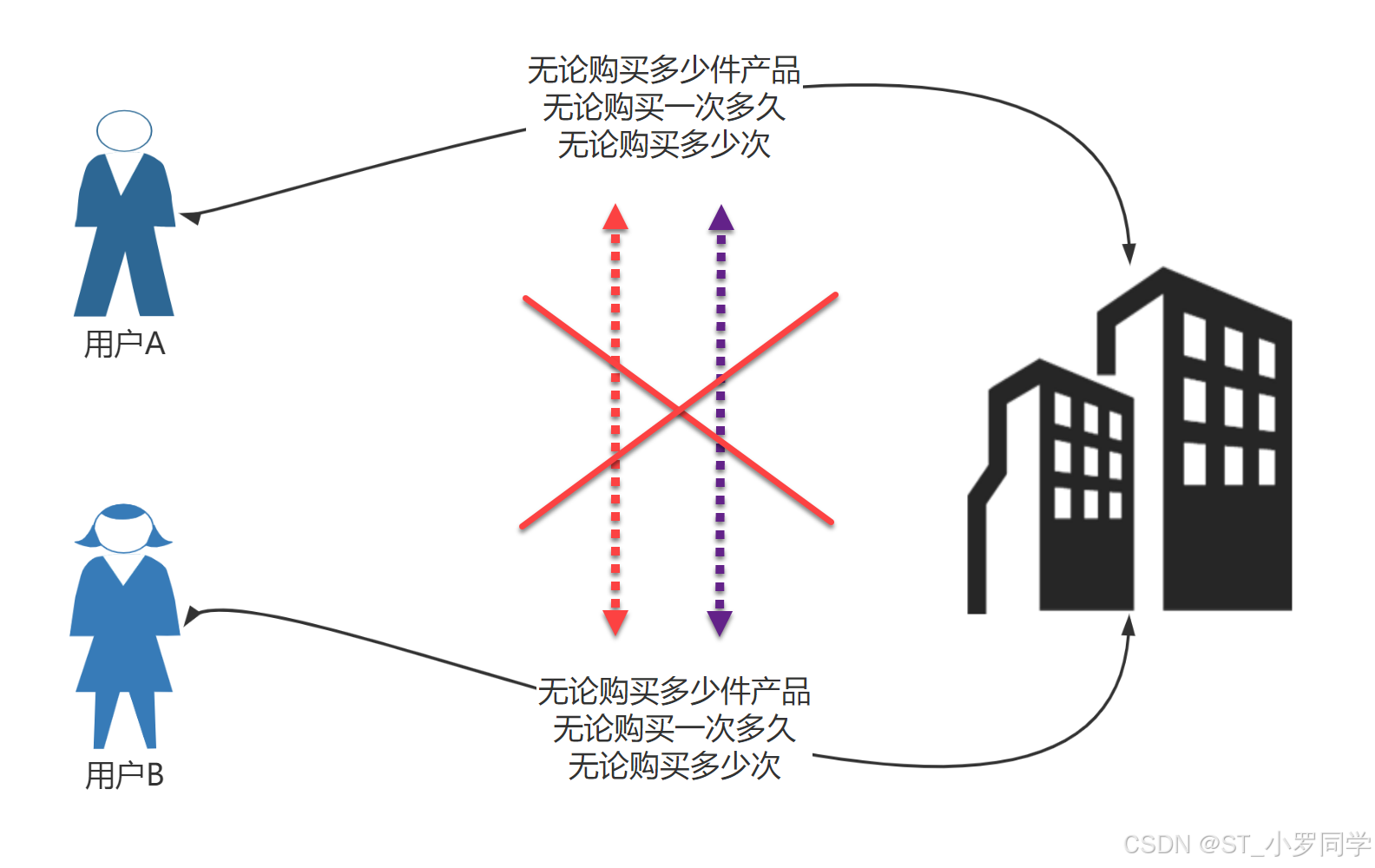
例如,用户A在超市购买的任何商品都应该放在A的购物车内,不论是用户A什么时间购买的,这都是属于同一个会话的,不能放入用户B或用户C的购物车内,这不属于同一个会话。
而Web应用程序是使用HTTP协议传输数据的。HTTP协议是无状态的协议。一旦数据交换完毕,客户端与服务器端的连接就会关闭。再次交换数据需要建立新的连接,这就意味着服务器无法从连接上跟踪会话。
即用户A购买了一件商品放入购物车内,当再次购买商品时服务器已经无法判断该购买行为是属于用户A的会话还是用户B的会话了。因此,必须引入一种机制,让服务器记住用户。
Cookie就是这样的一种机制。它可以弥补HTTP协议无状态的不足。在Session出现之前,基本上所有的网站都采用Cookie来跟踪会话。
由于HTTP是一种无状态的协议,服务器单从网络连接上无从知道客户身份。怎么办呢?就给客户端们颁发一个通行证吧,每人一个,无论谁访问都必须携带自己通行证。这样服务器就能从通行证上确认客户身份了。这就是Cookie的工作原理。
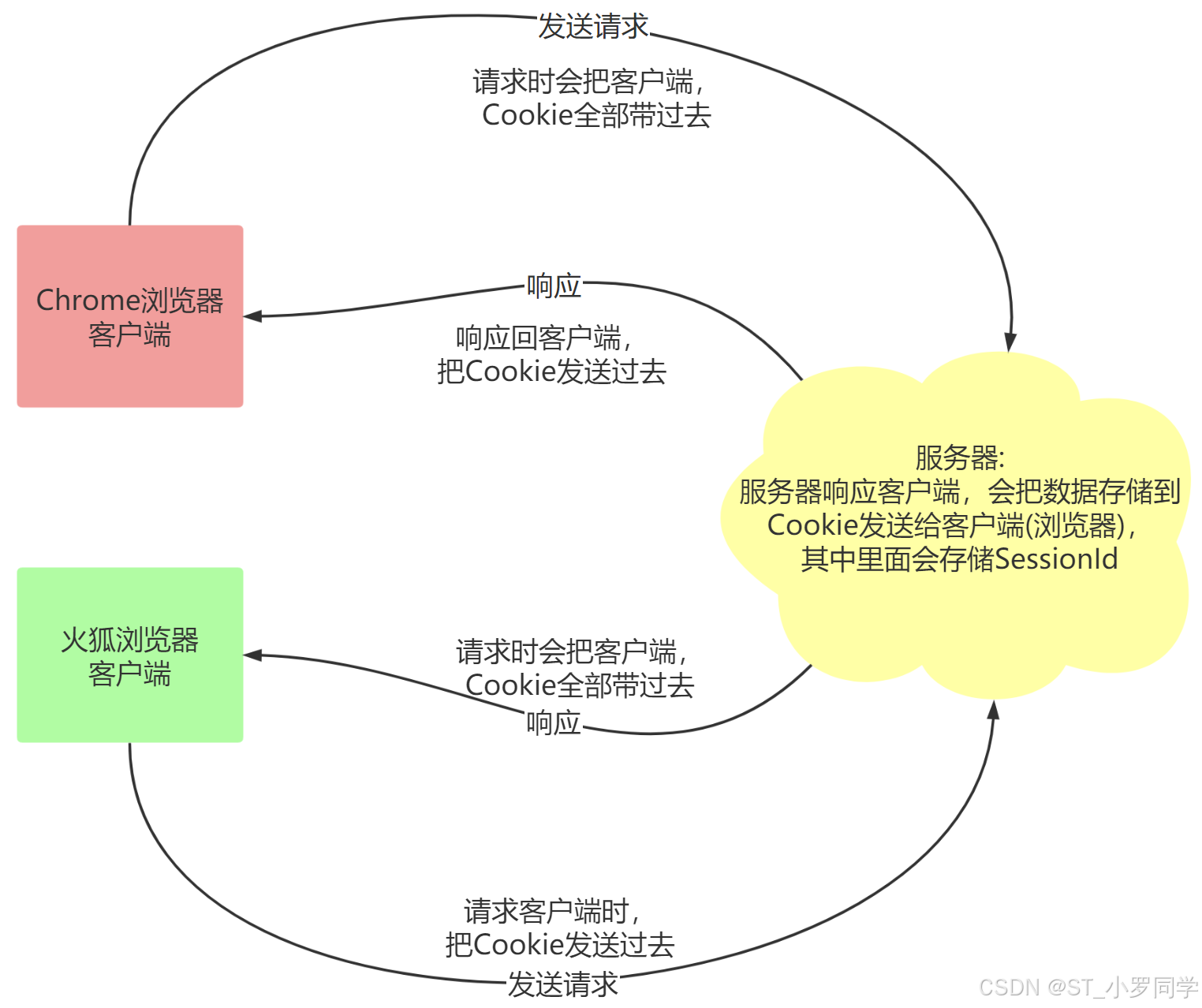
Cookie实际上是一小段的文本信息。客户端请求服务器,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。
当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户状态。服务器还可以根据需要修改Cookie的内容。
注意
浏览器对cookie数量和大小有限制的!如果超过了这个限制,你的信息将丢失。
不同的浏览器存储的Cookie的数量不同!
尽量保证cookie的数量以及相应的大小。cookie个数最好 < 20~30个;cookie大小最好 < 4K
Flask设置Cookie
设置cookie是在Response的对象上设置。
flask.Response对象有一个set_cookie方法,可以通过这个方法来设置cookie信息。key,value形式设置信息from flask import Flask, make_response app = Flask(__name__) @app.route('/cookie') def set_cookie(): resp = make_response('set cookie ok') resp.set_cookie('uname', 'companies') return resp在Chrome浏览器中查看cookie的方式:
方式1:借助于 开发调式工具进行查看
方式2:在Chrome的设置界面->高级设置->内容设置->所有cookie->找到当前域名下的cookie。
from flask import request @app.route('/get_cookie') def get_cookie(): resp = request.cookies.get('uname') return resp方式1:通过
Response对象.delete_cookie,指定cookie的key,就可以删除cookie了。from flask import request @app.route('/delete_cookie') def delete_cookie(): response = make_response('hello world') response.delete_cookie('uname') return response
方式2:在客户端浏览器人为的删除(清除浏览器浏览历史记录后,很多网站之前免密登录的都不好使了)
Cookie的有效期
默认的过期时间:如果没有显示的指定过期时间,那么这个cookie将会在浏览器关闭后过期。
max_age:以秒为单位,距离现在多少秒后cookie会过期。
expires:为datetime类型。这个时间需要设置为格林尼治时间,相对北京时间来说 会自动+8小时
如果max_age和expires都设置了,那么这时候以max_age为标准。
注意
max_age在IE8以下的浏览器是不支持的。
expires虽然在新版的HTTP协议中是被废弃了,但是到目前为止,所有的浏览器都还是能够支持,所以如果想要兼容IE8以下的浏览器,那么应该使用expires,否则可以使用max_age。
from flask import Flask,Response app = Flask(__name__) @app.route('/') def index(): return 'Hello!!' @app.route('/create_cookie/defualt/') def create_cookie1(): resp = Response('通过默认值,设置cookie有效期') # 如果没有设置有效期,默认会在浏览器关闭的时候,让cookie过期 resp.set_cookie('uname',' baidu') return resp @app.route('/create_cookie/max_age/') def create_cookie2(): resp = Response('通过max_age,设置cookie有效期') # max_age以秒为单位设置cookie的有效期 age = 60*60*2 resp.set_cookie('uname','companies',max_age=age) return resp from datetime import datetime @app.route('/create_cookie/expires/') def create_cookie3(): resp = Response('通过expires,设置cookie有效期') # expires 以指定时间为cookie的有效期 # 16+8 == 24 tmp_time = datetime(2021, 11, 11,hour=18,minute=0,second=0) resp.set_cookie('uname','python',expires=tmp_time) return resp from datetime import timedelta @app.route('/create_cookie/expires2/') def create_cookie4(): resp = Response('通过expires,设置cookie有效期') # expires 以指定时间为cookie的有效期 tmp_time = datetime.now() + timedelta(days=2) resp.set_cookie('uname','python_sql',expires=tmp_time) return resp @app.route('/create_cookie/exp_max/') def create_cookie5(): resp = Response('通过expires与max_age,设置cookie有效期') # expires 与max_age同时设置了,会以max_age为准 tmp_time = datetime.now() + timedelta(days=2) resp.set_cookie('uname','python_sql',expires=tmp_time,max_age = 60*60*2) return resp if __name__ == '__main__': app.run(debug=True)Session的介绍
Session和Cookie的作用有点类似,都是为了存储用户相关的信息,都是为了解决http协议无状态的这个特点。
不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上。
客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。
客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了。
注意
不同的语言,不同的框架,有不同的实现。
虽然底层的实现不完全一样,但目的都是让服务器端能方便的存储数据而产生的。
Session的出现,是为了解决cookie存储数据不安全的问题的。
如果说Cookie机制是通过检查客户身上的“通行证”来确定客户身份的话,
那么Session机制就是通过检查服务器上的“客户明细表”来确认客户身份。
Session相当于程序在服务器上建立的一份客户档案,客户来访的时候只需要查询客户档案表就可以了。
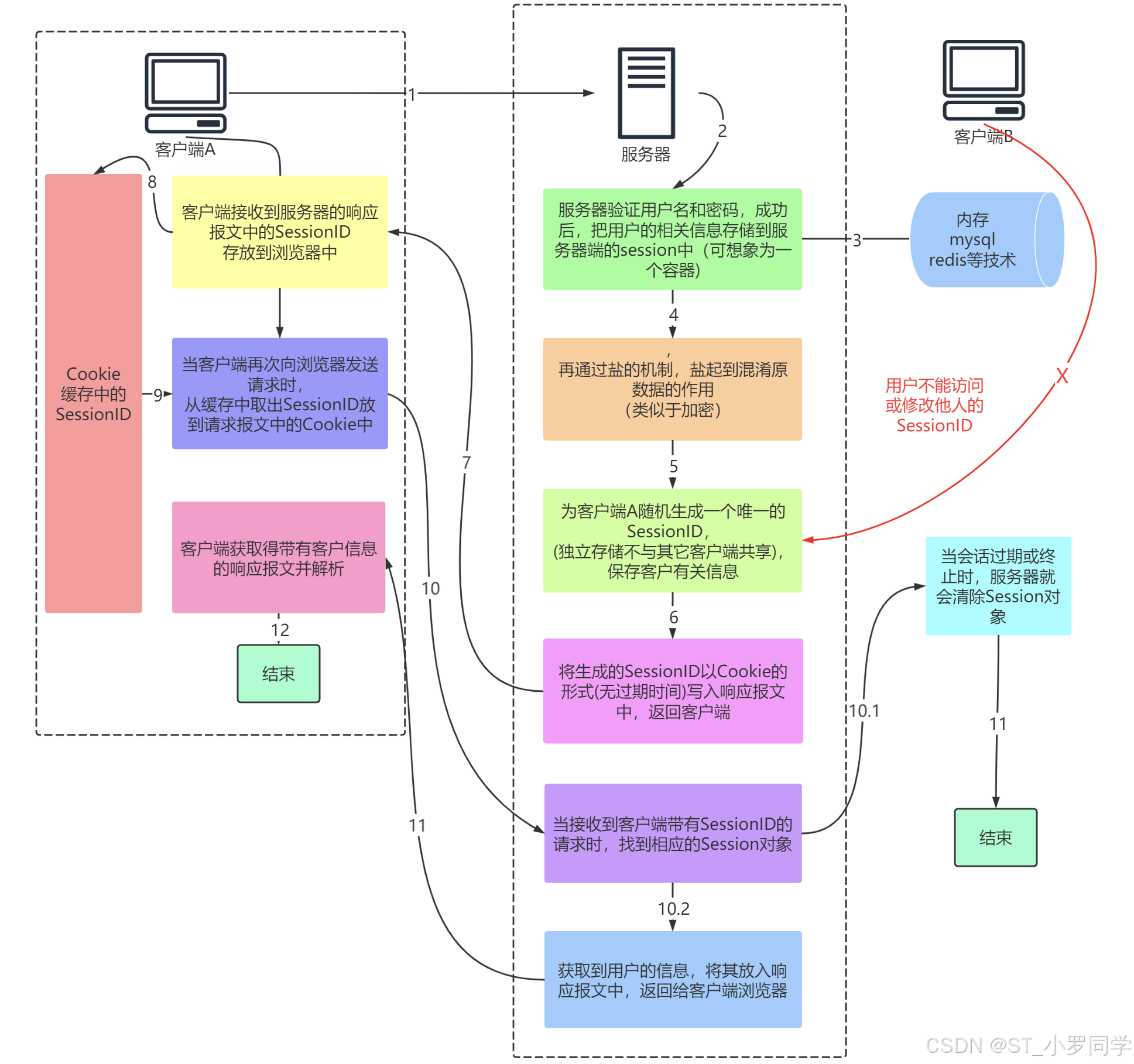
Session的跟踪机制
Flask框架中,session的跟踪机制跟Cookie有关,这也就意味着脱离了Cookie,session就不好使了。
因为session跟踪机制跟cookie有关,所以,要分服务器端和客户端分别起到什么功能来理解。
session工作过程
存储在服务器的数据会更加的安全,不容易被窃取。
但存储在服务器也有一定的弊端,就是会占用服务器的资源,但现在服务器已经发展至今,一些session信息还是绰绰有余的。
问题
(面试题)若客户端禁用了浏览器的Cookie功能,session功能想继续保留,该咋整?给出你的实现思路(能代码实现最好)
解决方案
URL地址携带SessionID
Flask中使用Session
需要先设置SECRET_KEY
class DefaultConfig(object): SECRET_KEY = 'fih9fh9eh9gh2' app.config.from_object(DefaultConfig) 或者直接设置 app.secret_key='xihwidfw9efw'设置、修改:
from flask import session @app.route('/set_session/') def set_session(): session['username'] = 'companies' return 'set session ok'读取
@app.route('/get_session/') def get_session(): username = session.get('username') return 'get session username {}'.format(username)删除
@app.route('/del_session/') def delete_session(): #删除指定的key的session # session.pop('uname') #删除session中的所有的key 【删除所有】 session.clear() return '删除成功'Flask设置Session的有效期
如果没有设置session的有效期。那么默认就是浏览器关闭后过期。
如果设置session.permanent=True,那么就会默认在31天后过期。
如果不想在31天后过期,按如下步骤操作
- session.permanent=True
- 可以设置
app.config['PERMANENT_SESSION_LIFETIME'] = timedelta(hour=2)在两个小时后过期。from flask import Flask,session from datetime import timedelta app = Flask(__name__) app.secret_key = 'sdfdfdsfsss' app.config['PERMANENT_SESSION_LIFETIME'] = timedelta(days=2) @app.route('/') def index(): return 'Hello!!' @app.route('/set_session/') def set_session(): # 设置session的持久化,默认是增加了31天 session.permanent = True session['uname'] = '10001' return '设置一个Session的信息' @app.route('/get_session/') def get_session(): # 如果服务器关闭掉了,session的有效期,依然是之前系统保存日期 # 如果secret_key设置是一个固定的值,那么服务器重启不会影响session的有效器 # 如果secret_key设置不是一个固定的值,那么服务器之前设置的session将全部过期 return session.get('uname') if __name__ == '__main__': app.run(debug=True)案例:Session实现免登录效果
<!-- login.html --> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <form action="/login/" method="post"> <table> <tr> <td>账号:</td> <td><input type="text" name="uname"></td> </tr> <tr> <td>密码:</td> <td><input type="password" name="pwd"></td> </tr> <tr> <td></td> <td><input type="submit" value="立即登录"></td> </tr> <tr> <td colspan="2"> {% if msg %} <span color="red">{{ msg }}</span> {% endif %} </td> </tr> </table> </form> </body> </html><!-- index.html --> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <h1>个人信息</h1> </body> </html>from flask import Flask, session, request,redirect,url_for,views,render_template app = Flask(__name__) # 定义一个基于方法调度的 类视图 class LoginView(views.MethodView): def __jump(self,msg=None): return render_template('login.html',msg = msg) def get(self): msg = request.args.get('msg') return self.__jump(msg) def post(self): uname = request.form.get('uname') pwd = request.form.get('pwd') if uname == "lty007" and pwd == "123": session['uname'] = uname return render_template('index.html') else: return self.__jump(msg="用户名或者密码错误") @app.route('/index/') def index(): uname = session.get('uname') if uname: return '这个是主页!!!' return redirect(url_for('login',msg='请先登录')) # 注册类视图 app.add_url_rule('/login/', view_func=LoginView.as_view('login')) if __name__ == '__main__': app.secret_key = 'xihwidfw9efw' app.run(debug=True)TreadLocal对象
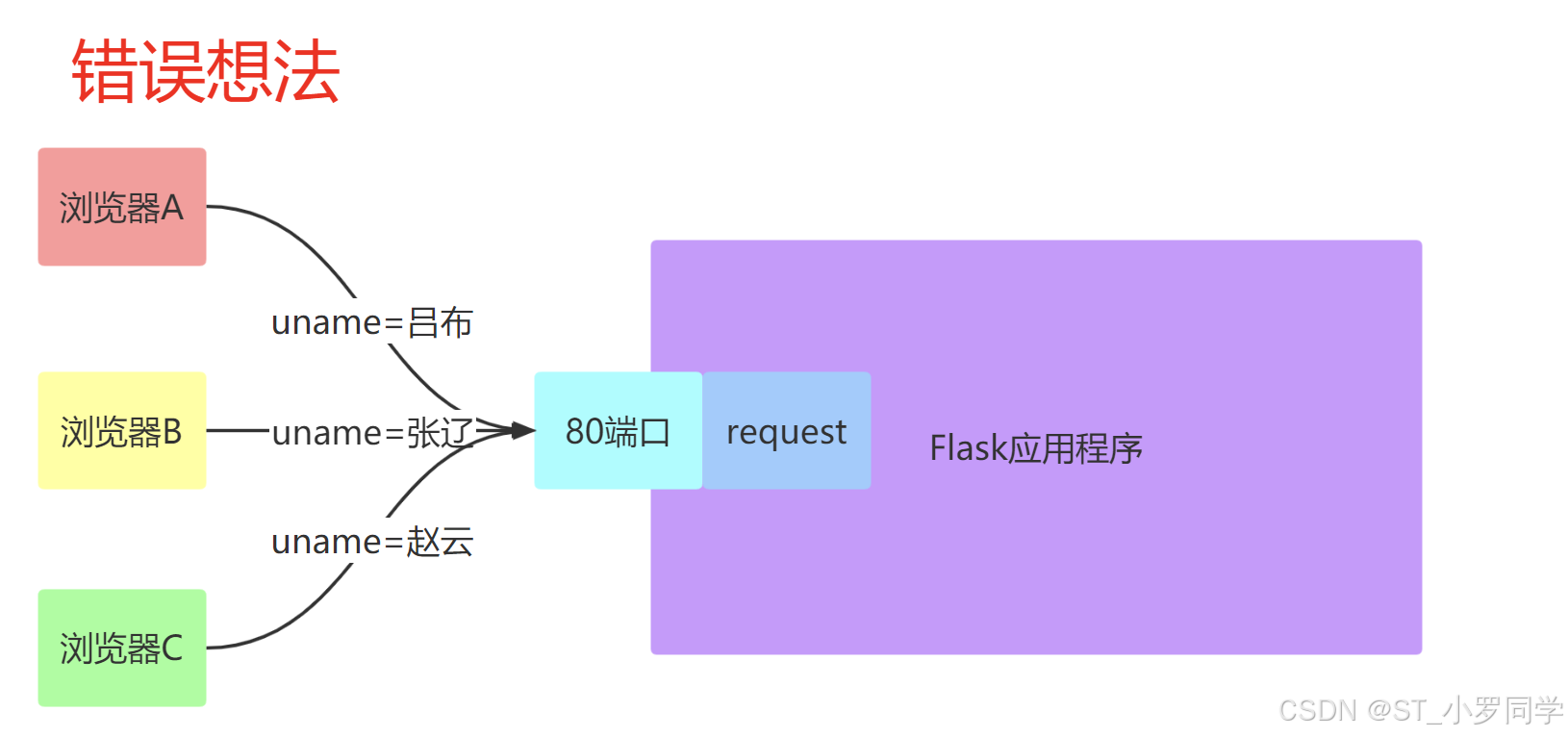
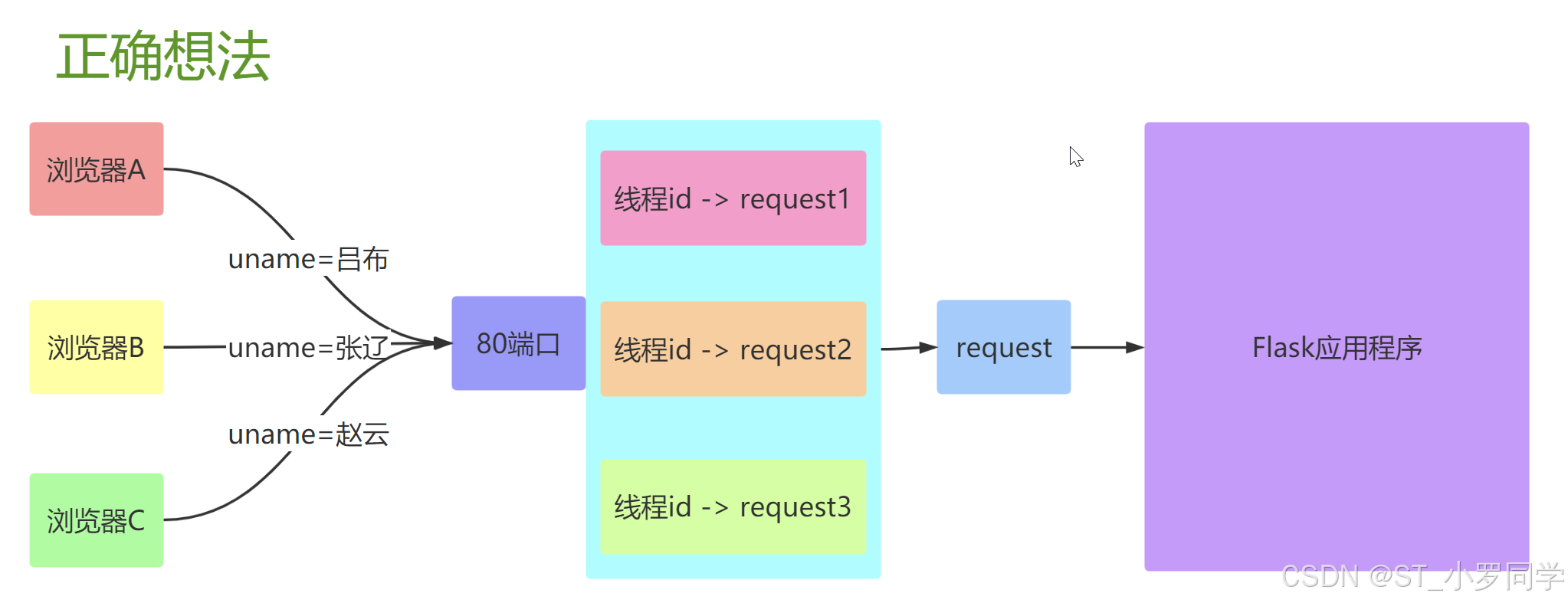
需求
- 要实现并发效果, 每一个请求进来的时候我们都开启一个进程, 这显然是不合理的, 于是就可以使用线程
- 那么线程中数据互相不隔离,存在修改数据的时候数据不安全的问题
Local对象:在Flask中,类似于
request对象,其实是绑定到了一个werkzeug.local.Local对象上。这样,即使是同一个对象,那么在多个线程中都是隔离的。类似的对象还有session对象。from werkzeug.local import Local #flask=werkzeug + sqlalchemy + jinja2ThreadLocal变量Python提供了ThreadLocal 变量,它本身是一个全局变量,但是每个线程却可以利用它来保存属于自己的私有数据,这些私有数据对其他线程也是不可见的。
from threading import Thread,local local =local() local.request = '具体用户的请求对象' class MyThread(Thread): def run(self): local.request = 'baidu' print('子线程:',local.request) mythread = MyThread() mythread.start() mythread.join() print('主线程:',local.request)from werkzeug.local import Local local = Local() local.request = '具体用户的请求对象' class MyThread(Thread): def run(self): local.request = 'baidu' print('子线程:',local.request) mythread = MyThread() mythread.start() mythread.join() print('主线程:',local.request)只要满足绑定到"local"或"Local"对象上的属性,在每个线程中都是隔离的,那么他就叫做
ThreadLocal对象,也叫'ThreadLocal'变量。Flask中的应用上下文
上下文(感性的理解)
每一段程序都有很多外部变量,只有像add这种简单的函数才是没有外部变量的。 一旦一段程序有了外部变量,这段程序就不完整,不能独立运行。为了能让这段程序可以运行,就要给所有的外部变量一个一个设置一些值。就些值所在的集合就是叫上下文。
并且上下文这一概念在中断任务的场景下具有重大意义,其中任务在被中断后,处理器保存上下文并提供中断处理,因些在这之后,任务可以在同一个地方继续执行。(上下文越小,延迟越小)
举例
运行的Flask项目,每一个路由映射的内容片段,都不可以单独拿出来使用。
当获取到了APP_Context以后,就可以直接通过程序映射的地址访问逻辑,并且可以重复使用。
上下文的一个典型应用场景就是用来缓存一些我们需要在发生请求之前或者要使用的资源。举个例子,比如数据库连接。当我们在应用上下文中来存储东西的时候你得选择一个唯一的名字,这是因为应用上下文为 Flask 应用和扩展所共享。
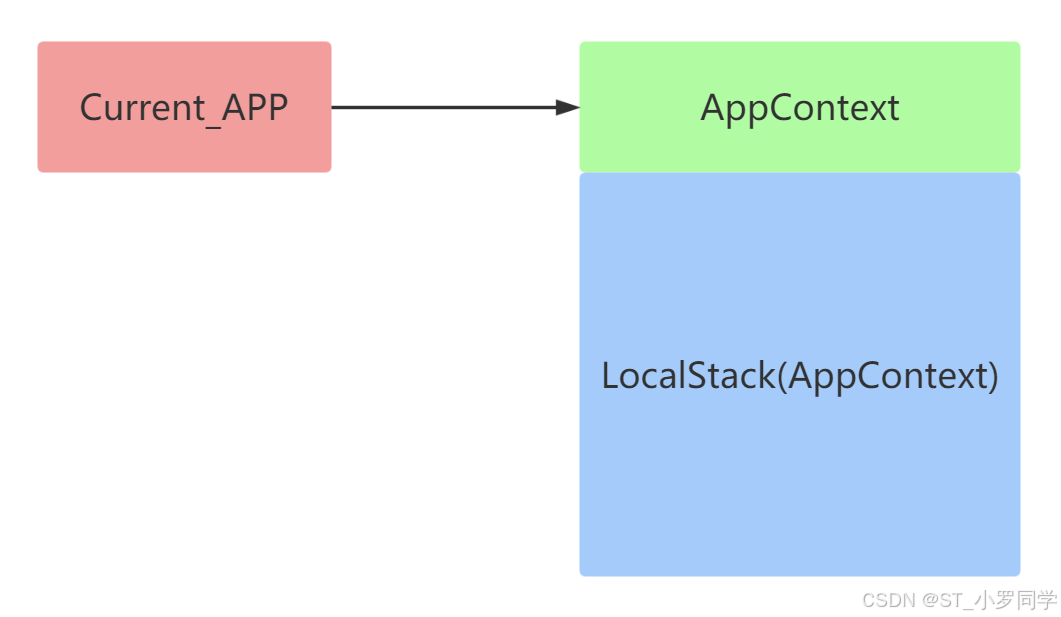
应用上下文:
应用上下文是存放到一个
LocalStack的栈中。和应用app相关的操作就必须要用到应用上下文比如:通过
current_app获取当前的这个app名字。注意
在视图函数中,不用担心应用上下文的问题。因为视图函数要执行,那么肯定是通过访问url的方式执行的,那么这种情况下,Flask底层就已经自动的帮我们把应用上下文都推入到了相应的栈中。
如果想要在视图函数外面执行相关的操作,比如: 获取当前的app名称,那么就必须要手动推入应用上下文
第一种方式:便于理解的写法
from flask import Flask,current_app app = Flask(__name__) #app上下文 app_context = app.app_context() app_context.push() print(current_app.name) @app.route('/') def hello_world(): print(current_app.name) #获取应用的名称 return 'Hello World!' if __name__ == '__main__': app.run(debug=True)第二种方式:用with语句
from flask import Flask,current_app app = Flask(__name__) #app上下文 #换一种写法 with app.app_context(): print(current_app.name) @app.route('/') def hello_world(): print(current_app.name) #获取应用的名称 return 'Hello World!' if __name__ == '__main__': app.run(debug=True)Flask中的请求上下文
请求上下文:
请求上下文也是存放到一个
LocalStack的栈中。和请求相关的操作就必须用到请求上下文,比如使用
url_for反转视图函数。注意
在视图函数中,不用担心请求上下文的问题。因为视图函数要执行,那么肯定是通过访问url的方式执行的,那么这种情况下,Flask底层就已经自动的帮我们把应用上下文和请求上下文都推入到了相应的栈中。
注意
如果想要在视图函数外面执行相关的操作,比如反转url,那么就必须要手动推入请求上下文:
底层代码执行说明:
1. 推入请求上下文到栈中,会首先判断有没有应用上下文
2. 如果没有那么就会先推入应用上下文到栈中
3. 然后再推入请求上下文到栈中
from flask import Flask,url_for app = Flask(__name__) @app.route('/') def index(): url = url_for('test_url') return f'Hello!==={url}' @app.route('/test/') def test_url(): return '这个是为了测试请求上下文' # RuntimeError: Attempted to generate a URL without the application context being pushed. # This has to be executed when application context is available. # with app.app_context(): # url = url_for('test_url') # print(url) # RuntimeError: Application was not able to create a URL adapter for request independent URL generation. # You might be able to fix this by setting the SERVER_NAME config variable. with app.test_request_context(): url = url_for('test_url') print(url) if __name__ == '__main__': app.run(debug = True)总结:为什么上下文需要放在栈中?
1. 应用上下文:Flask底层是基于werkzeug,werkzeug是可以包含多个app的,所以这时候用一个栈来保存。如果你在使用app1,那么app1应该是要在栈的顶部,如果用完了app1,那么app1应该从栈中删除。方便其他代码使用下面的app。
2. 如果在写测试代码,或者离线脚本的时候,我们有时候可能需要创建多个请求上下文,这时候就需要存放到一个栈中了。使用哪个请求上下文的时候,就把对应的请求上下文放到栈的顶部,用完了就要把这个请求上下文从栈中移除掉。
Flask中的全局对象G
保存为全局对象g对象的好处:
g对象是在整个Flask应用运行期间都是可以使用的。并且也跟request一样,是线程隔离的。
这个对象是专门用来存储开发者自己定义的一些数据,方便在整个Flask程序中都可以使用。
一般使用就是,将一些经常会用到的数据绑定到上面,以后就直接从g上面取就可以了,而不需要通过传参的形式,这样更加方便。
g对象使用场景:有一个工具类utils.py 和 用户办理业务:
def funa(uname): print(f'funa {uname}') def funb(uname): print(f'funb {uname}') def func(uname): print(f'func {uname}')用户办理业务
from flask import Flask,request from utils import funa,funb,func app = Flask(__name__) #Flask_线程隔离的g对象使用详解 @app.route("/profile/") def my_profile(): #从url中取参 uname = request.args.get('uname') #调用功能函数办理业务 funa(uname) funb(uname) func(uname) #每次都得传参 麻烦,引入g对象进行优化 return "办理业务成功" if __name__ == '__main__': app.run(debug=True)优化工具类utils.py
from flask import g def funa(): print(f'funa {g.uname}') def funb(): print(f'funb {g.uname}') def func(): print(f'func {g.uname}')优化用户办理业务
from flask import Flask,request,g from utils import funa,funb,func app = Flask(__name__) #Flask_线程隔离的g对象使用详解 @app.route("/profile/") def my_profile(): #从url中取参 uname = request.args.get('uname') #调用功能函数办理业务 # funa(uname) # funb(uname) # func(uname) #每次都得传参 麻烦,引入g对象进行优化 g.uname = uname funa() funb() func() return "办理业务成功" if __name__ == '__main__': app.run(debug=True)Flask_钩子函数介绍
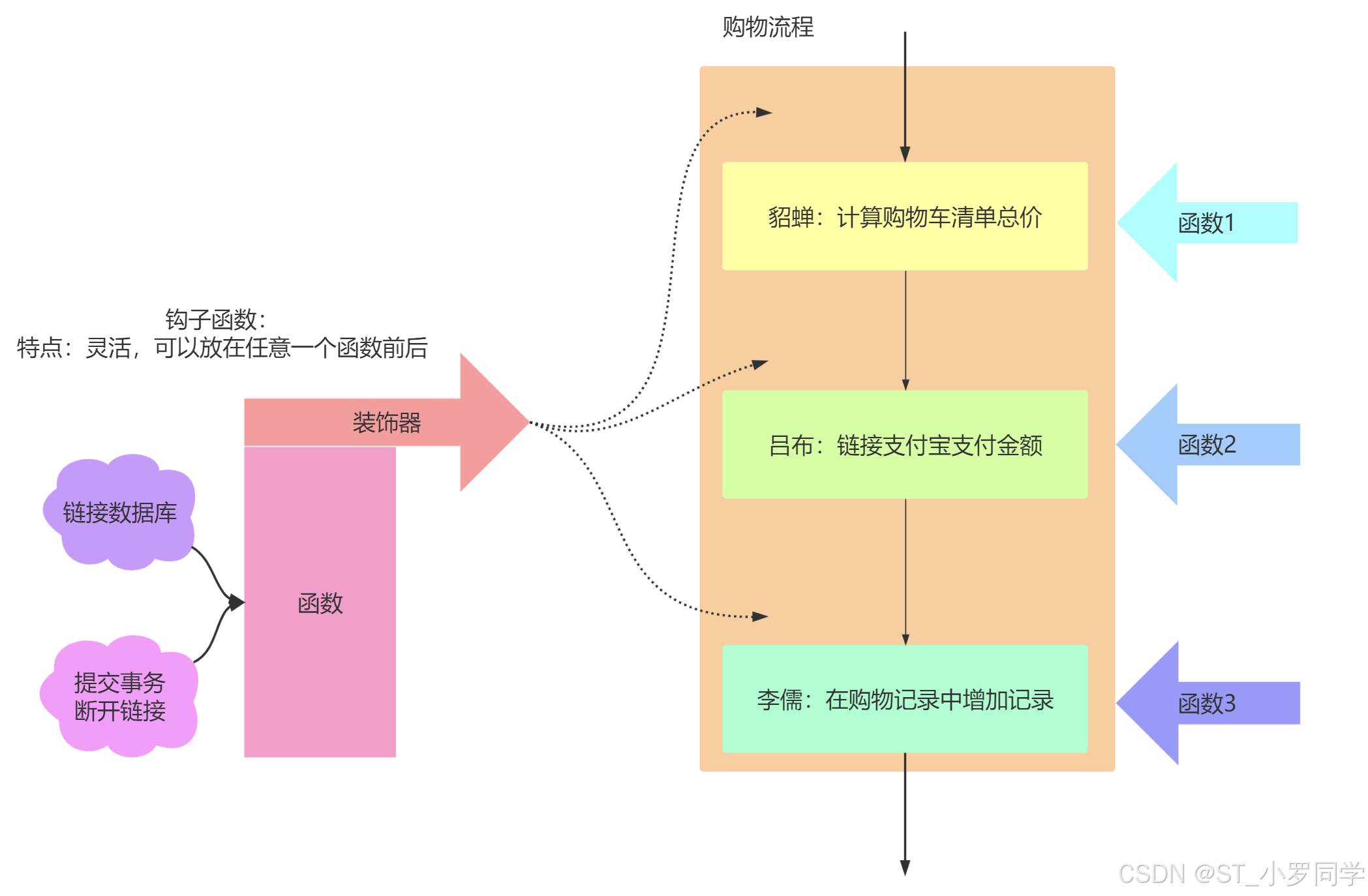
钩子函数概念
在Flask中钩子函数是使用特定的装饰器装饰的函数。
为什么叫做钩子函数呢,是因为钩子函数可以在正常执行的代码中,插入一段自己想要执行的代码。那么这种函数就叫做钩子函数。
常见的钩子函数
before_first_request:处理项目的第一次请求之前执行。
@app.before_first_request def first_request(): print('first time request')before_request:在每次请求之前执行。通常可以用这个装饰器来给视图函数增加一些变量。请求已经到达了Flask,但是还没有进入到具体的视图函数之前调用。一般这个就是在视图函数之前,我们可以把一些后面需要用到的数据先处理好,方便视图函数使用。
@app.before_request def before_request(): if not hasattr(g,'glo1'): setattr(g,'glo1','想要设置的')teardown_appcontext:不管是否有异常,注册的函数都会在每次请求之后执行。
@app.teardown_appcontext def teardown(exc=None): if exc is None: db.session.commit() else: db.session.rollback() db.session.remove()template_filter:在使用Jinja2模板的时候自定义过滤器。
@app.template_filter("upper") def upper_filter(s): return s.upper()context_processor:上下文处理器。使用这个钩子函数,必须返回一个字典。这个字典中的值在所有模版中都可以使用。这个钩子函数的函数是,如果一些在很多模版中都要用到的变量,那么就可以使用这个钩子函数来返回,而不用在每个视图函数中的
render_template中去写,这样可以让代码更加简洁和好维护。@app.context_processor def context_processor(): if hasattr(g,'user'): return {"current_user":g.user} else: return {}errorhandler:errorhandler接收状态码,可以自定义返回这种状态码的响应的处理方法。在发生一些异常的时候,比如404错误,比如500错误,那么如果想要优雅的处理这些错误,就可以使用
errorhandler来出来。@app.errorhandler(404) def page_not_found(error): return 'This page does not exist',404before_first_request和before_request详解
before_first_request:处理项目的第一次请求之前执行。
from flask import Flask,request app = Flask(__name__) @app.route('/') def hello_world(): print("hi") return "hello world " @app.before_first_request def first_request(): print('hello world') if __name__ == '__main__': app.run(debug=True)before_request:在每次请求之前执行。通常可以用这个装饰器来给视图函数增加一些变量。
请求已经到达了Flask,但是还没有进入到具体的视图函数之前调用。
一般这个就是在视图函数之前,我们可以把一些后面需要用到的数据先处理好,方便视图函数使用。
from flask import Flask,g,session app = Flask(__name__) app.config['SECRET_KEY'] = 'skidhfikshighsd' @app.route('/login/') def login(): print('运行代码 222222222') print('Hello!!!!') session['uname'] = '吕布' return f'Hello' @app.route('/home/') def home(): print('运行代码 3333333333') if hasattr(g, 'uname'): return f'用户已登录!用户名是:{g.uname}' return '用户没有登录!' @app.before_request def before_request(): print('运行代码 111111111111') uname = session.get('uname') if uname: g.uname = uname print('这个是每次请求时,需要执行的逻辑!!!') # 需求: 判断用户是否登录,如果登录了,就返回用户的信息,如果没有登录就返回None if __name__ == '__main__': app.run(debug = True)钩子函数context_processor详解
context_processor:上下文处理器。使用这个钩子函数,必须返回一个字典。这个字典中的值在所有模版中都可以使用。
使用场景
这个钩子函数的功能是,如果一些在很多模版中都要用到的变量,那么就可以使用这个钩子函数来返回,而不用在每个视图函数中的
render_template中去写,这样可以让代码更加简洁和好维护。from flask import Flask,request,session,current_app,url_for,g,render_template import os app = Flask(__name__) app.config['SECRET_KEY']=os.urandom(24) #加盐 混淆原数据的作用 @app.route('/') def hello_world(): print("hi") session['uname']="baidu" # return "hello world " return render_template("index.html") @app.route('/li') def mylist(): print("mylist") # print("直接取出",g.user) if hasattr(g,"user"): print("条件取出", g.user) # return "hello world " return render_template('list.html') @app.before_request def before_request(): # print('在视图函数执行之前执行的钩子函数') # 场景:若用户已经登录了,验证时把用户名放入session中,之后取出来,放入钩子函数,以后访问的视图函数中可直接取出来使用 uname = session.get('uname') print(uname) if uname: g.user = uname @app.context_processor def context_processor(): if hasattr(g,'user'): return {"current_user":g.user} else: return {} if __name__ == '__main__': app.run(debug=True)钩子函数errorhandler详解
errorhandler:
在发生一些异常的时候,比如404错误,比如500错误, 那么如果想要优雅的处理这些错误,就可以使用
errorhandler来出来。需要注意几点:
- 在errorhandler装饰的钩子函数下,记得要返回相应的状态码。
- 在errorhandler装饰的钩子函数中,必须要写一个参数,来接收错误的信息,如果没有参数,就会直接报错。
- 使用
flask.abort可以手动的抛出相应的错误,比如开发者在发现参数不正确的时候可以自己手动的抛出一个400错误。常见的500错误处理
from flask import Flask,g,render_template,abort app =Flask(__name__) @app.route('/') def index(): print(g.uname) return 'Hello!' @app.errorhandler(500) def server_error(error): # server_error() takes 0 positional arguments but 1 was given return render_template('500.html'),500 # 状态码虽然可以不写,但是推荐写上,这样可以告诉服务器是哪个错误 # return render_template('500.html') if __name__ =="__main__": # app.run(debug=True) app.run()常见的404错误处理
from flask import Flask,g,render_template,abort app =Flask(__name__) @app.route('/') def index(): print(g.uname) return 'Hello!' @app.errorhandler(404) def server_error(error): return render_template('404.html'),404 if __name__ =="__main__": # app.run(debug=True) app.run()Flask中的abort函数可以手动的抛出相应的错误(如400)
from flask import Flask,g,render_template,abort app =Flask(__name__) @app.route('/') def index(): print(g.uname) return 'Hello!' @app.errorhandler(404) def server_error(error): return render_template('404.html'),404 @app.route('/home/') def home(): abort(404) if __name__ =="__main__": # app.run(debug=True) app.run()Flask_信号机制
大白话来说,类似于两方属于敌对关系时,某人在敌对方阵营进行交谈,一旦遇到特殊情况,某人便会发送信号,他的同伙接收(监听)到他发的信号后,同伙便会做出一系列的应对策略(进攻|撤退)。
flask中的信号使用的是一个第三方插件,叫做blinker。通过pip list看一下,如果没有安装,通过以下命令即可安装blinker
pip install blinker自定义信号步骤
自定义信号可分为3步来完成。
第一是创建一个信号,第二是监听一个信号,第三是发送一个信号。
以下将对这三步进行讲解:
- 创建信号:定义信号需要使用到blinker这个包的Namespace类来创建一个命名空间。比如定义一个在访问了某个视图函数的时候的信号。示例代码如下:
# Namespace的作用:为了防止多人开发的时候,信号名字冲突的问题 from blinker import Namespace mysignal = Namespace() signal1 = mysignal.signal('信号名称')- 监听信号:监听信号使用signal1对象的connect方法,在这个方法中需要传递一个函数,用来监听到这个信号后做该做的事情。示例代码如下:
def func1(sender,uname): print(sender) print(uname) signal1.connect(func1)- 发送信号:发送信号使用signal1对象的send方法,这个方法可以传递一些其他参数过去。示例代码如下:
signal1.send(uname='momo')from flask import Flask from blinker import Namespace app = Flask(__name__) #【1】信号机制 3步走 # Namespace:命名空间 #1.定义信号 sSpace = Namespace() fire_signal = sSpace.signal('发送信号火箭') #2.监听信号 def fire_play(sender): print(sender) print("start play") fire_signal.connect(fire_play) #3.发送一个信号 fire_signal.send() if __name__ == '__main__': app.run(debug=True)Flask信号使用场景_存储用户登录日志
信号使用场景
定义一个登录的信号,以后用户登录进来以后就发送一个登录信号,然后能够监听这个信号
在监听到这个信号以后,就记录当前这个用户登录的信息,用信号的方式,记录用户的登录信息即登录日志
编写一个signals.py文件创建登录信号
from blinker import Namespace from datetime import datetime from flask import request,g namespace = Namespace() #创建登录信号 login_signal = namespace.signal('login') def login_log(sender): # 用户名 登录时间 ip地址 now = datetime.now() ip = request.remote_addr log_data = "{uname}*{now}*{ip}".format(uname=g.uname, now=now, ip=ip) with open('login_log.txt','a') as f: f.write(log_data + "\n") f.close() #监听信号 login_signal.connect(login_log)使用信号存储用户登录日志
from flask import Flask,request,g from signals import login_signal app = Flask(__name__) @app.route('/login/') def login(): # 通过查询字符串的形式来传递uname这个参数 uname = request.args.get('uname') if uname: g.uname = uname # 发送信号 login_signal.send() return '登录成功!' else: return '请输入用户名!' if __name__ == '__main__': app.run(debug=True)



















 2317
2317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











