



1:为什么构建数据仓库
数据仓库的主要目的就是为了解耦合
数仓的构建方便了数据的开发和重复开发的成本,将数据仓库分层次管理可以更高效更便洁的使用现有的数据,快速的完成开发工作。
2:传统数据仓库的分层
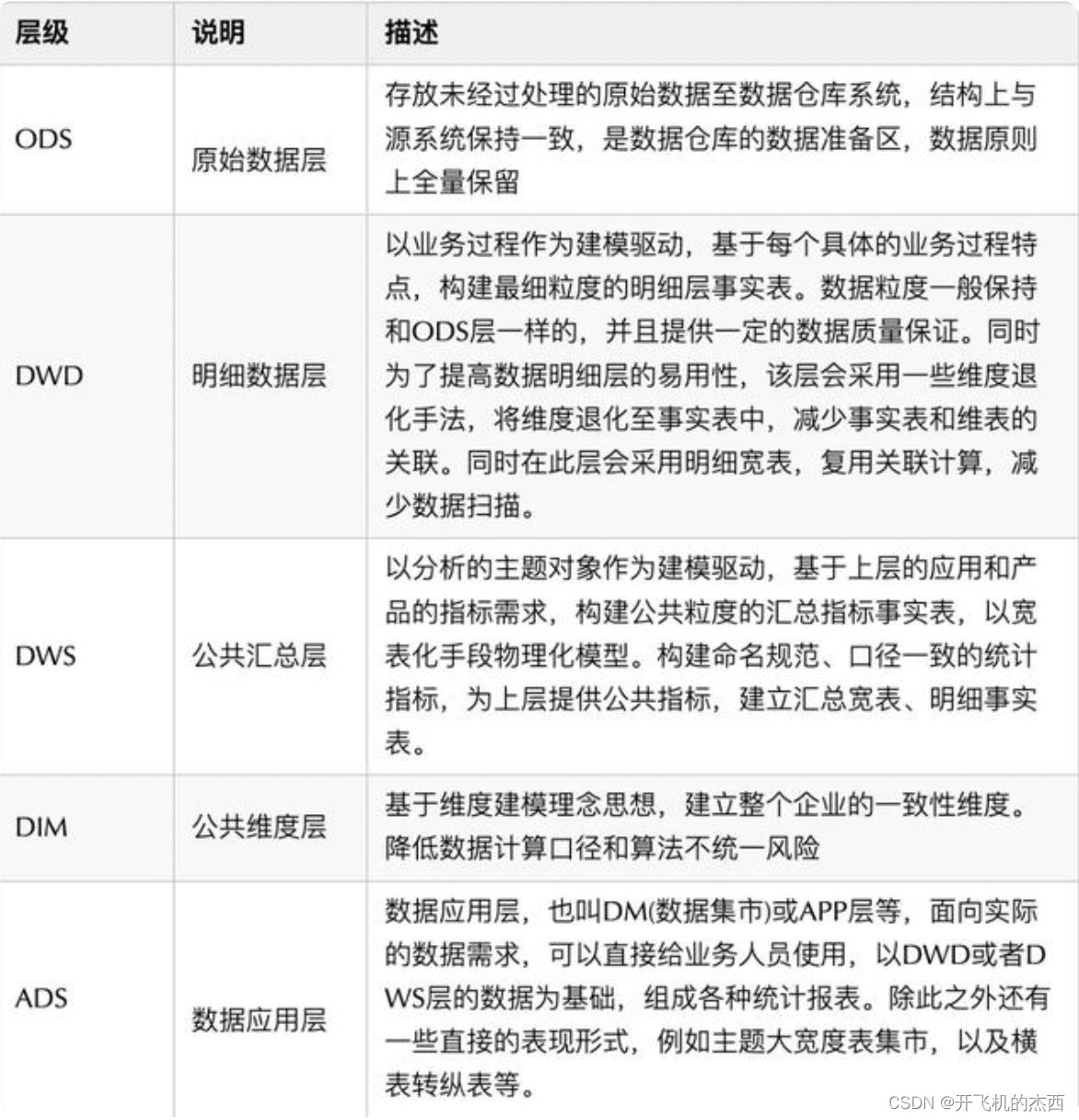
当然我们在实际的开发过程中经常需要依据业务开发的具体情况来配置我们数据仓库的层级,有的项目中我们将ods层进行拆分出ods和odsp层次,在ods中就是我们常说的贴源表的构建,基本和各个系统中接入的数据保持一致,而在odsp层中我们通常会对原始数据进行脱敏处理和脏数据的处理工作(当然这部分工作也可以放到dwd层来完成)
我们在dwd层通常称之为数据明细层,他是以具体的业务作为驱动来进行每个业务中最小粒度的事实表数据的构建,但是并不是意味着dwd层只是存储了事实表的内容,实际上在dwd层中我们也引入了相关的宽表的概念,所谓宽表从字面意义上的理解就是字段比较多的表我们称之为宽表,但是实际上宽表可以划分为汇总宽表和明细宽表,我们将业务相关的指标(事实表中的计算数据),维度,属性等内容通过关联关系合并到同一张表中就构成了一张宽表,宽表的特点就是大而杂,他的缺点就是有许多的冗余数据的产生并且不遵循三范式的规定,但是正因为他的数据全面而且繁多,我们在具体的业务过程中需要获取哪些类型的数据可以直接从宽表中进行获取,而在dwd层中我们常说的宽表个人认为实际上是明细宽表的概念,区别于明细宽表和汇总宽表可以是否有聚合操作作为分类的依据,有聚合操作的汇总表称之为汇总宽表,没有进行汇总操作的表称之为明细宽表,而在dwd层中常说的明细宽表是没有进行汇总之后的表。总而言之,dwd层是依据具体的业务流程作为驱动,依据流程展示出所有最细粒度的事实行为的展示,允许维度退化和一些明细宽表的冗余,为上层提供支持。
在DWS层中我们不再以某个业务作为具体的驱动,而是取而代之以具体的分析主题作为建模驱动,基于上层的应用和产品具体指标的需求,构建公共粒度的汇总指标表,其中来源的数据多为DWD层的数据,这个汇总表的数据可以直接提供出去进行透出,也可以为上层模型提供支持,所以这里我认为此层级的主要工作为汇总计算。
在ADS层主要针对的是应用层,我们可能需要对DWS层的数据进行进一步的加工处理,对汇总计算出的结果进行进一步的优化,数据的结果要符合具体应用的需求,直观的提供给业务人员进行使用。
3:总结
数仓建模本身就是一种仁者见仁智者见智的东西,对此我觉得没有一个统一的规范,不同的公司之间,同一个公司的不同部门之间都可能存在数仓构建的差异,但是我们只需要牢记,针对数据仓库我们要始终紧跟业务进行驱动,将繁杂汇总的数据进行拆分细化,再从细化的各个数据中组合拼接出我们具体需要的内容,这个过程也正是数仓构建的魅力所在,当然要牢记维度建模的相应原则构建出OLAP模型下优秀的企业公司数仓。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









