







Patroni中的Citus
1. Citus
1.1 Citus介绍
Citus是一个非常实用的能够使PostgreSQL具有进行水平扩展能力的插件,或者说是一款以PostgreSQL插件形式部署的基于PostgreSQL的分布式HTAP数据库。本文简单说明Citus的高可用技术方案,并实际演示基于Patroni搭建Citus HA环境的步骤。
Citus是Postgres的开源扩展,用于分发数据和查询跨群集中的多个节点。因为Citus是一个扩展(而不是一个分叉) 当你使用Citus时,你也在使用Postgres。 您可以利用 最新的Postgres功能、工具和生态系统。
Citus将Postgres转换为分布式数据库,具有以下功能, 分片、分布式SQL引擎、引用表和分布式表。 Citus结合了并行性,在内存中保存更多数据, I/O带宽可以显著提高多租户的性能 SaaS应用程序、面向客户的实时分析仪表板和时间 系列工作负载。
1.2 Citus HA方案选型
Citus集群由一个CN节点和N个Worker节点组成。CN节点的高可用可以使用任何通用的PG 高可用方案,即为CN节点通过流复制配置主备2台PG机器;Worker节点的高可用除了可以像CN一样采用PG原生的高可用方案,还支持另一种多副本分片的高可用方案。
多副本高可用方案是Citus早期版本默认的Worker高可用方案(当时citus.shard_count默认值为2),这种方案部署非常简单,而且坏一个Worker节点也不影响业务。采用多副本高可用方案时,每次写入数据,CN节点需要在2个Worker上分别写数据,这也带来一系列不利的地方。
- 数据写入的性能下降
- 对多个副本的数据一致性的保障也没有PG原生的流复制强
- 存在功能上的限制,比如不支持Citus MX架构
因此,Citus的多副本高可用方案适用场景有限,Citus 官方文档上也说可能它只适用于append only的业务场景,不作为推荐的高可用方案了(在Citus 6.1的时候,citus.shard_count默认值从2改成了1)。
因此,建议Citus和CN和Worker节点都使用PG的原生流复制部署高可用。
1.3 Citus架构设计
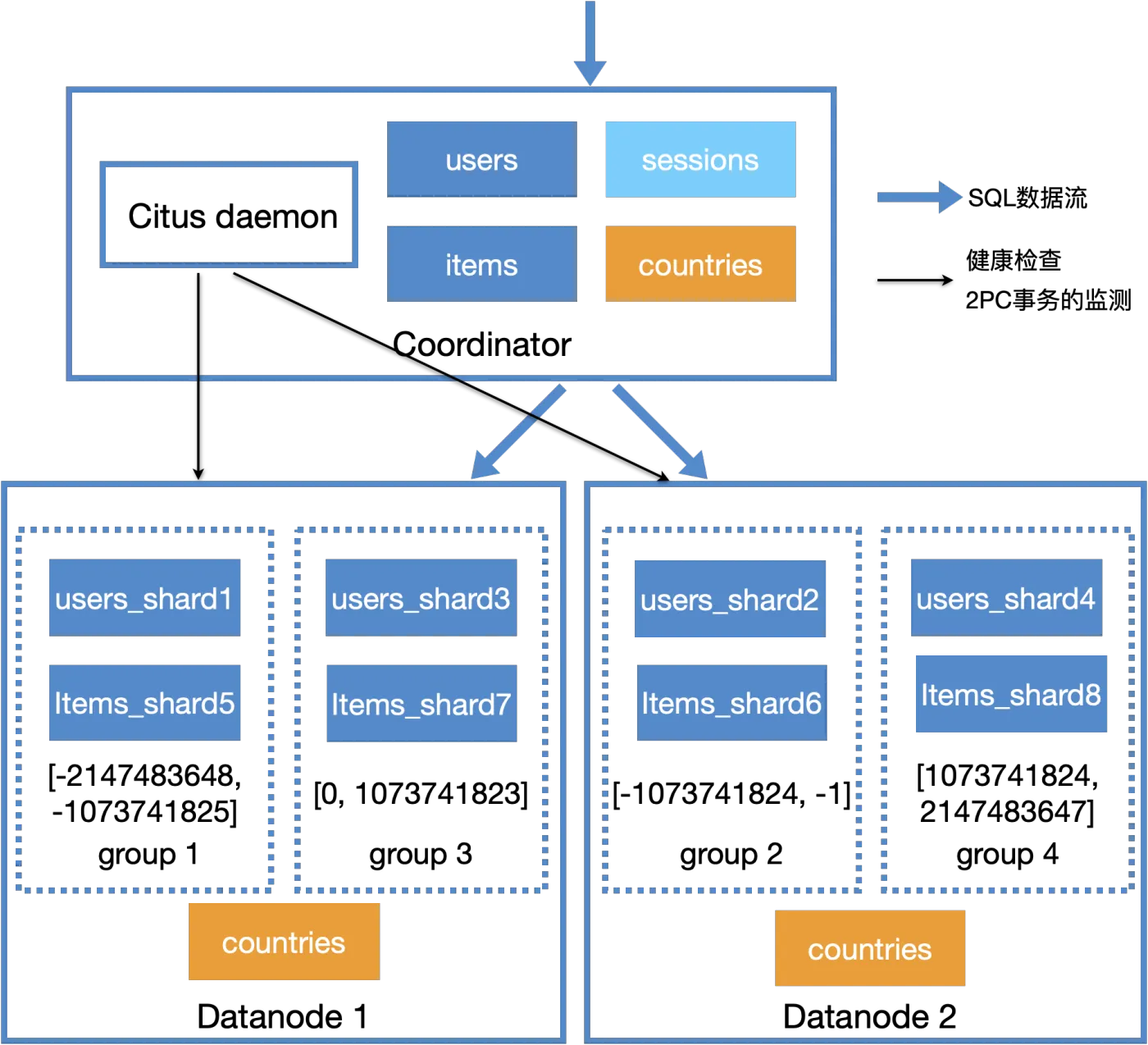
我们先来看下Citus整体的架构设计,值得说明的是:Citus架构中每个角色都是PG,没有其他中间件。
我们看下Citus架构中的组件构成:
- 整体架构分为:mCN+nDN
- CN:Coordinator节点,集群元数据、分布式计划
- 特点:轻计算,重网络IO
- Citus daemon:2PC事务的监测、恢复和清理
- DN:Datanode节点,存储实际的分片数据
- 特点:实际的计算和存储节点,可水平拓展
为了更深入地理解Citus的架构设计,我们会在接下来的章节中讨论Citus在各个方面的设计与取舍:
- Citus的分片方式、表和索引详见第3章;
- Citus的分布式SQL、执行计划、计算下推的原则,详见第4章;
- Citus的分布式事务实现及正确性保障、为何没有全局一致性读,详见第5章;
- Ciitus的集群管理,包括高可用和容灾、数据热点/数据倾斜、分布式的线性拓展、PITR。
1.4. Citus分片
1.4.1 Citus分片方式
不同的分片方式直接影响了数据的分布方式,Citus从应用实践出发,提供了最常用的两种分片方式:
-
hash分片:
采用一致性哈希原理,[-232,232-1]平均分成n个区间,hash_int32(key)计算具体区间。
hash分片比较常见于多租户场景、查询多围绕某列等场景,在这样的分布式结构中,最重要的就是sharding column的选择。一个好的sharding column可以很大程度解决数据分布不均匀、访问热点等问题。
sharding column的一般选择:Where、JOIN出现频率高的列,分布相对平均的列,例如:订单表、用户表以user_id做分片;SaaS多租户。
-
range分片:
分片范围由人工指定。
Citus对range分片的支持比较简单,需要人工指定每个分片的范围。相比TiDB,Citus的range分片没有自动分裂,节约了很大的运维成本。Citus也指明了range分片适用于时序数据,支持人工分裂某个区间。
Citus仅支持了常用的数据分片,推荐hash分片方式,官方称解决绝大多数问题。
1.4.2 Citus表和索引
Citus系统中存在三种表:
- Distributed tables:分片表,就是使用上述hash分片和range分片的表。
- Co-located table:分片方式相同的表称为亲和表。亲和表的集合成为组,通常一个分片的运维操作,指的都是一个组内的所有亲和表。
- Reference tables:参考表,每个DN上有表的全部数据,用于解决跨节点JOIN问题。
- Local tables:本地表,只存在于CN上(因为CN也是PG)。官方称Local table用来存储数据量不大的表,解决用户鉴权问题。笔者认为这是因为CN是PG,可以存储数据,本身意义不大。
Citus的索引:完全依赖PG的索引,没有全局的二级索引,没有全局的唯一、外键约束。
- Citus的唯一、外键约束,必须建立组合索引,组合索引的第一列必须是sharding column。
Citus主张把全局的约束下沉到各个DN上,这也与我们后面介绍的Citus倾向于做计算下推不谋而合。
Citus在分片、表、索引的设计都化繁为简,意在减轻用户在使用中的学习成本。
1.5 Citus分布式SQL
1.5.1 内核实现
Citus完全实现在PG的插件中,**对内核代码0改动,**既最大程度复用了PG原有的能力,又达到了代码的解耦,工程质量极高。具体实现见下图:
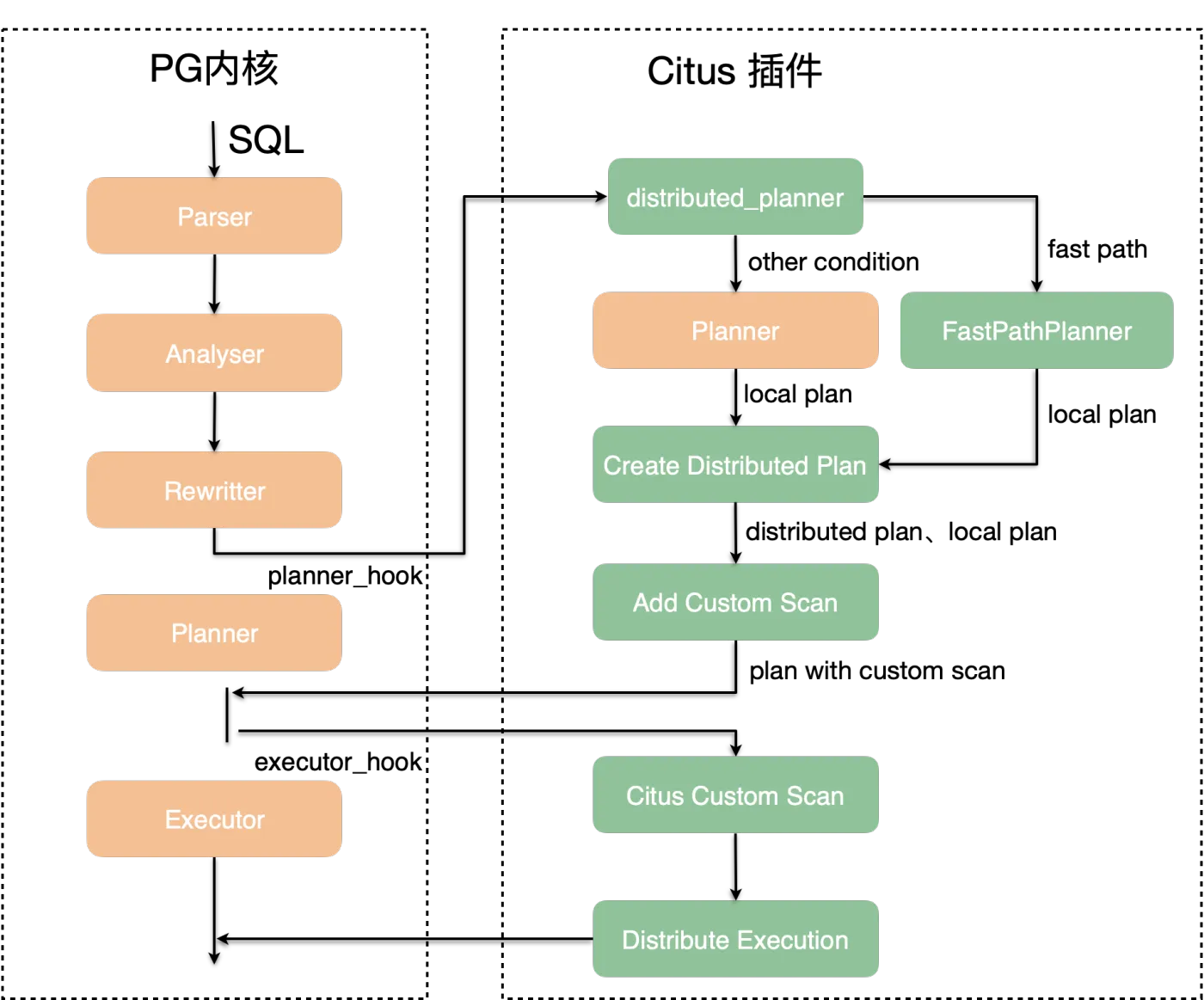
可以看出,Citus实现了planner_hook和executor_hook,使得所有的SQL都进入到Citus的执行逻辑中。
Citus借助PG提供的计划器和执行器的钩子函数,结合PG优化器,生成分布式执行计划:
- 计划器钩子(planner_hook)
- 输入:query tree、table sharding info
- 输出:plan with custom scan
- 在产生分布式计划的过程中,Citus会根据SQL的执行方式,判断属于以下哪种执行计划:
- local plan:计划只在CN或DN上执行
- distributed plan:计划在CN和DN上都会执行,依赖local plan
- 执行器钩子(excutor_hook)
- 根据planner_hook产生的分布式计划,执行SQL下发、结果聚合
具体而言,针对一条SQL,Citus会如下图所示,在CN进行解析,转发到DN上执行。
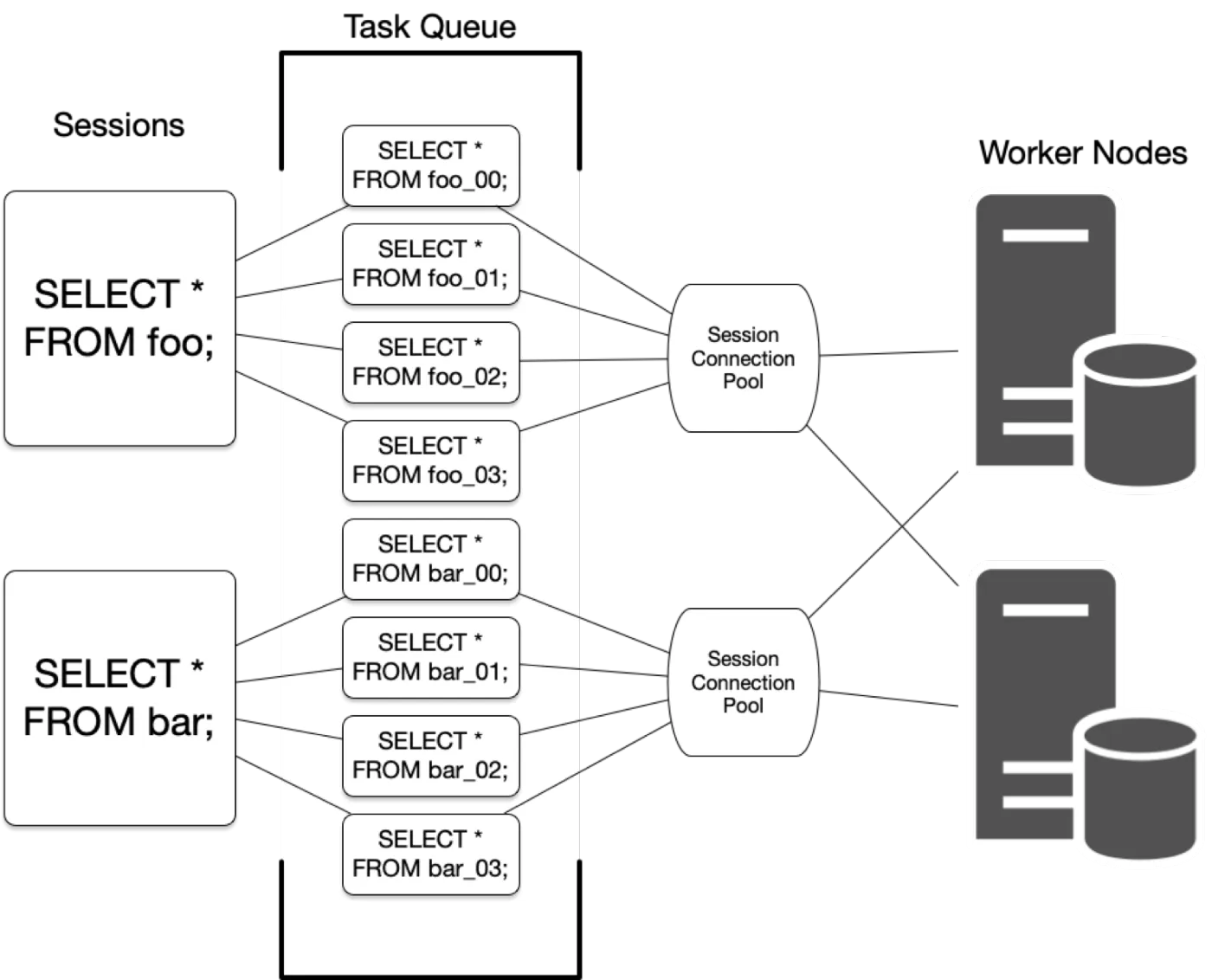
上图也说明了Citus的MPP能力,充分利用了DN的计算能力。
图中有几个细节:
- CN将SQL下发到DN
- select/update/delete/insert拆分成对应分片的SQL
- insert batch拆分为单个insert value,没有对同一个DN的insert聚合到一条SQL(缺点)
- CN与DN之间维护连接池
- session参数不转发:search_path、transaction_isolation
- prepare statement转换成普通SQL,因为无法保证prepare后的SQL都经过同一条连接(缺点)
1.5.2 分布式SQL执行
讲完了Citus分布式SQL的内核实现,那对于分布式的SQL,Citus具体是如何支持的呢?Citus将分布式的SQL从简单到复杂分为了以下4种:
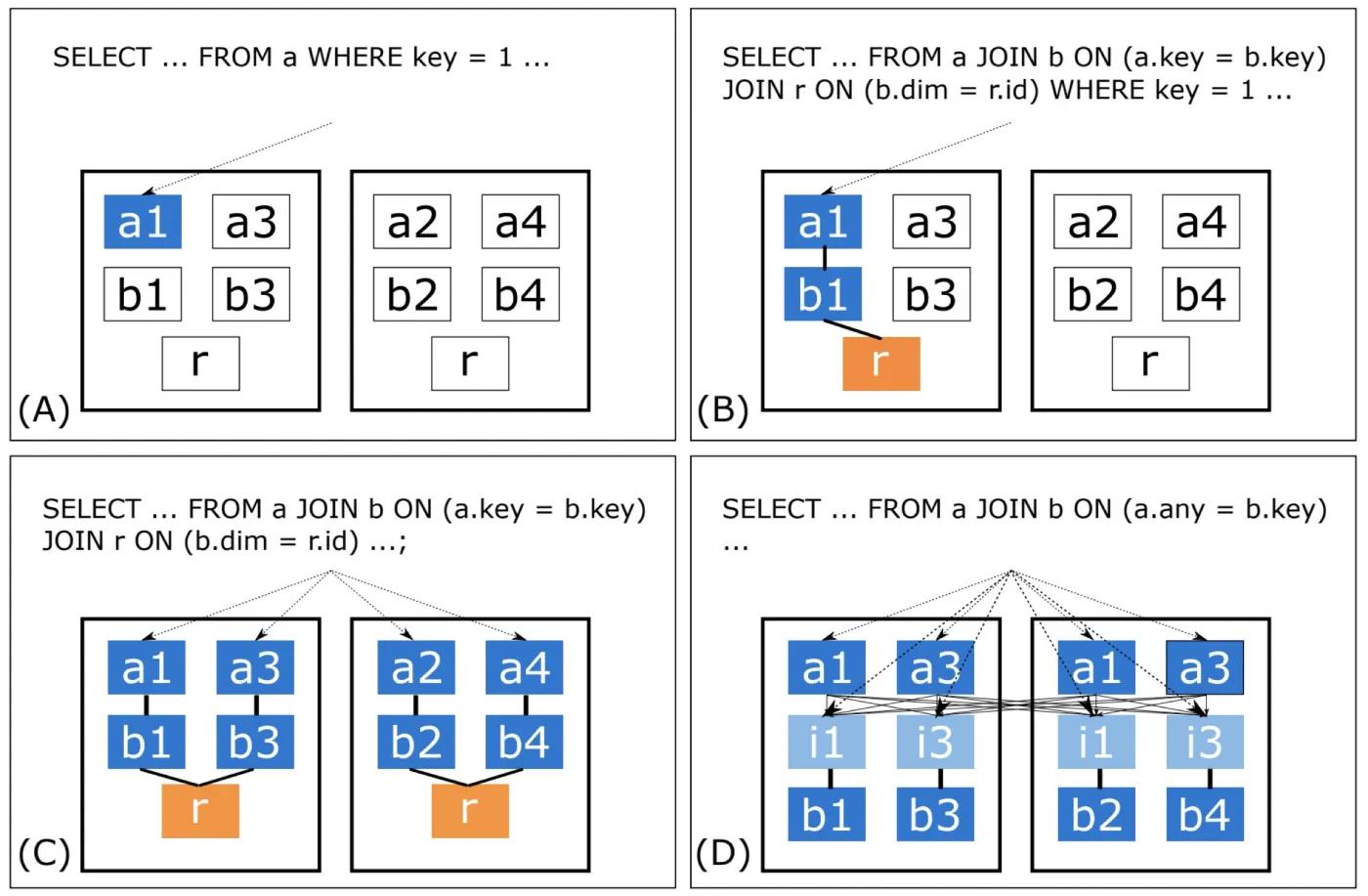
- 前3种SQL本质上还是在同分片中,没有跨节点,但是涵盖了分布式下很多场景的SQL。
- 第4种是真正意义上的分布式JOIN,查询方式可以概括为 —— 重分片:
-
a表重新分片(DN互联、不经过CN),以any为sharding column,保存结果到临时表i,此时i和b是亲和表(分片方式相同);
-
CN重新生成SQL: SELECT … FROM i JOIN b on ( i.any = b.key );
-
每个shard查询
本例只举例a.any = b.key的情况,a表要重分片;其实a.any1 = b.any2也是同理的,a、b两表都需要以各自的any字段进行一次重分片。
但第4种要经过大量的计算、中间结果,Citus虽然支持但并不鼓励这样做,默认关闭此类SQL的支持。
1.5.3 从SQL limitation深入理解分布式SQL执行计划
上文简单描述了分布式SQL的执行过程,下面我会从几个SQL limitation来深入讲述分布式执行计划,来看看Citus的取舍。
1.5.3.1 Correlated subqueries
t、t1:关联分片表;t2:非关联分片表;ref:参考表
select * from ref where not exists (select t.id from t); # 支持,distributed plan,子查询可以在DN执行
select * from ref where not exists (select t.id from t1 join ref on t.id = ref.id); # 支持,distributed plan,子查询可以在DN执行
select * from ref where not exists (select t.id from t where t.id = ref.id and t.shard_id=3); # 支持,local plan,子查询无需将结果返回CN
select * from ref where not exists (select t.id from t where ref.id = t.id); # 不支持,distributed plan,子查询无法在DN直接执行
表中列举了几个子查询的例子,distributed plan涉及CN和DN的共同计算,local plan代表只需要CN或DN计算。
- 1、2、3支持的原因是子查询可以单独在DN执行,而不需要中间和CN产生交互。
- 4 不支持的原因是子查询select t.id from t where ref.id = t.id无法直接在DN上执行,即使可以很简单的改写为select t.id from t,ref where ref.id = t.id,但Citus是直接将子查询下推到DN上,所以不支持。
1.5.3.2 Outer joins
t、t1:关联分片表;t2:非关联分片表;ref:参考表
select * from t1 left join t on t1.shard_id = t.shard_id; # 支持,亲和表 join on sharding column
select * from ref join t on ref.id = t.id; # 支持,参考表和分片表inner join
select * from t join t2 on t.id = t2.id; # 支持,非亲和表重分布
select * from ref left join t on ref.id = t.id; # 不支持,理论上重分布也可以支持,但不推荐
表中列举了几个JOIN的例子,1为亲和表间的outer join,2为参考表和分片表间的inner join,3为非亲和表间的inner join,这些都在Citus的支持之列。4是参考表和分片表的outer join,不支持的原因是Citus对outer join不会推荐重分布,更倾向于让SQL下推到DN上。而1失败是因为这个SQL在单个DN上的结果是错误的,需要DN之间的数据全集做outer join,所以报错。
虽然不支持,但提供了改写方法:with a as (select id from t) select * from ref left join a on ref.id = a.id;
乍一看这条SQL与上面4不是一样嘛?不急,仔细看看,这条使用了with字句,先把t表的ID全部拿出来放到CN上,已经拿到了DN之间的数据全集,那接下来的outer join就可以得到一个正确的结果。
1.5.3.3 Recursive CTEs
Recursive CTEs是PG的特色功能,简单例子1~100做累加,下一次的计算依赖上一次的计算结果。
t、t1:关联分片表;t2:非关联分片表;ref:参考表
WITH RECURSIVE a(n) AS ( VALUES (1) UNION ALL SELECT n+1 FROM a WHERE n < 1) SELECT * FROM t where id in (select n from a) and shard_id = 3; # 支持
WITH RECURSIVE a(n) AS ( VALUES (1) UNION ALL SELECT n+1 FROM a WHERE n < 1) SELECT * FROM t where id in (select n from a); # 不支持
1 和 2 的唯一区别就是 1 指定了sharding column,而2没有。
2 不支持的理由:Citus对recursive CTE限制比较苛刻,只允许在单个分片,避免CN参与大量的计算。
1.5.3.4 Grouping sets
Grouping sets是PG的特色功能,指聚合时对每个grouing sets中的列单独聚合。
t、t1:关联分片表;t2:非关联分片表;ref:参考表
select id, name, avg(shard_id) from t group by id, name; # 支持,group by多列最多在CN产生一次聚合
select id, name, avg(shard_id) from t group by grouping sets ((id), (name), ()); # 不支持,grouping sets会在CN产生多次聚合
1和2都是group by,2比1多了grouping sets,grouping sets的语义是对sets中的每一列做一次聚合。2不支持的理由:grouping sets n列,要将DN返回的结果,在CN上重新聚合n次。按照我们上面对Citus的理解,涉及到多次在CN上计算的SQL,都是不支持的。
改写方法:group by多列、或者grouping sets里只有一列。
1.5.4 Citus 分布式 SQL 总结
- 通过PG内核的hook实现,0代码侵入,复用PG能力。
- 以PG优化器为基础,推荐将分布式SQL转换到单机上运行,避免在CN上计算,倾向于做计算下推。
- 对比业界其他方案(TiDB、CockroachDB等),支持全部优化器算子,成熟度高。
1.6 Citus分布式事务
对于分布式数据库,绕不开的话题就是分布式事务。Citus对于分布式事务的实现,也是业界标配 —— 2PC。需要注意的是,Citus的分布式事务没有全局一致性读。Citus为什么要这样设计?具体实现又是怎样?且听我娓娓道来。
1.6.1 分布式事务的开始
对于分布式事务的开始,要经过以下步骤:
- 遇到第一条跨DN的SQL,标记为2PC
- SQL commit时发起2PC
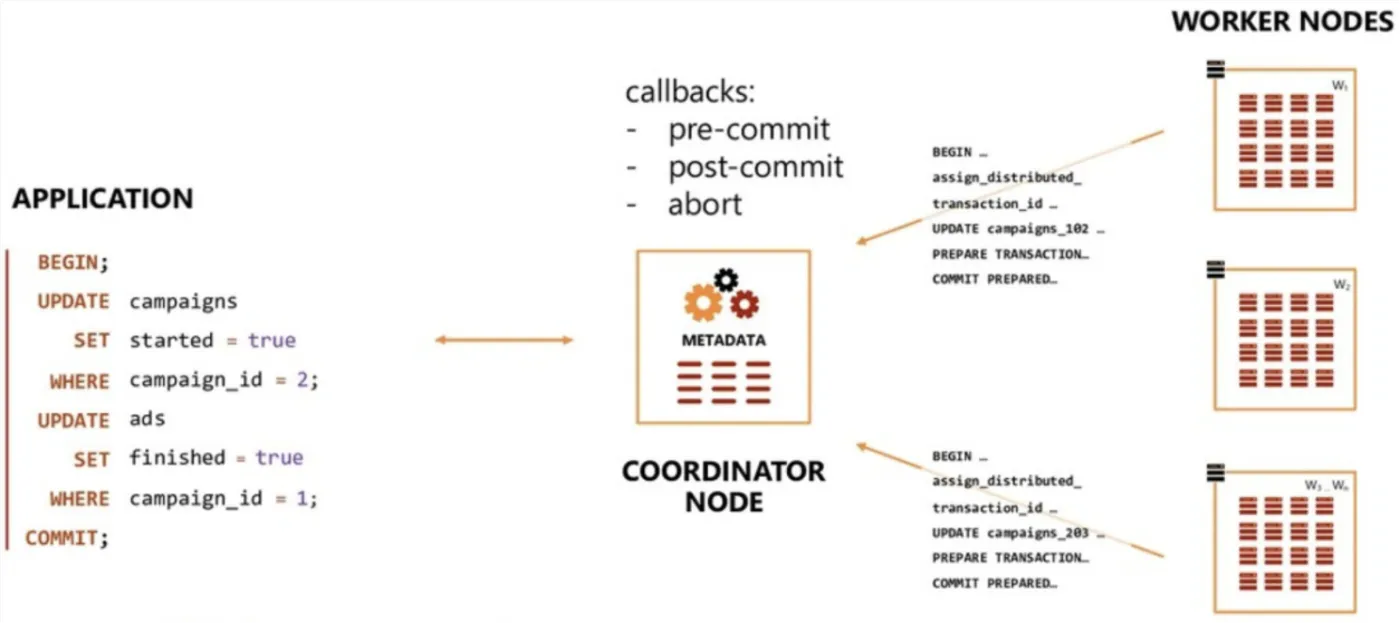
1.6.2 分布式事务的实现——2PC
2PC基本是分布式事务的标准做法了,基本流程包括两个阶段:prepare+commit。prepare成功,就可以认为此2PC事务成功。2PC的详细算法不在这里赘述,我们只关心Citus的实现。
1.6.2.1 2PC事务中的关键角色和表
介绍2PC事务前,先来介绍下决2PC事务中的关键角色和表。
前提:PG支持prepare/commit transaction,类比MySQL的xa prepare/commit,此为2PC在数据库的基础支持。
2PC的重要角色:
- CN节点:记录事务元信息,prepare/commit发起者
- CN daemon进程:2PC事务的恢复和回滚
2PC的重要表:
- CN上的表 pg_dist_transaction:记录DN和2PC事务ID
- DN上的表 pg_prepared_xacts:PG自带,记录已经prepare没有commit的事务,commit/rollback后会自动删除
有了以上两个表,CN daemon就能够在发生错误时,判断2PC事务到底应该提交还是回滚。
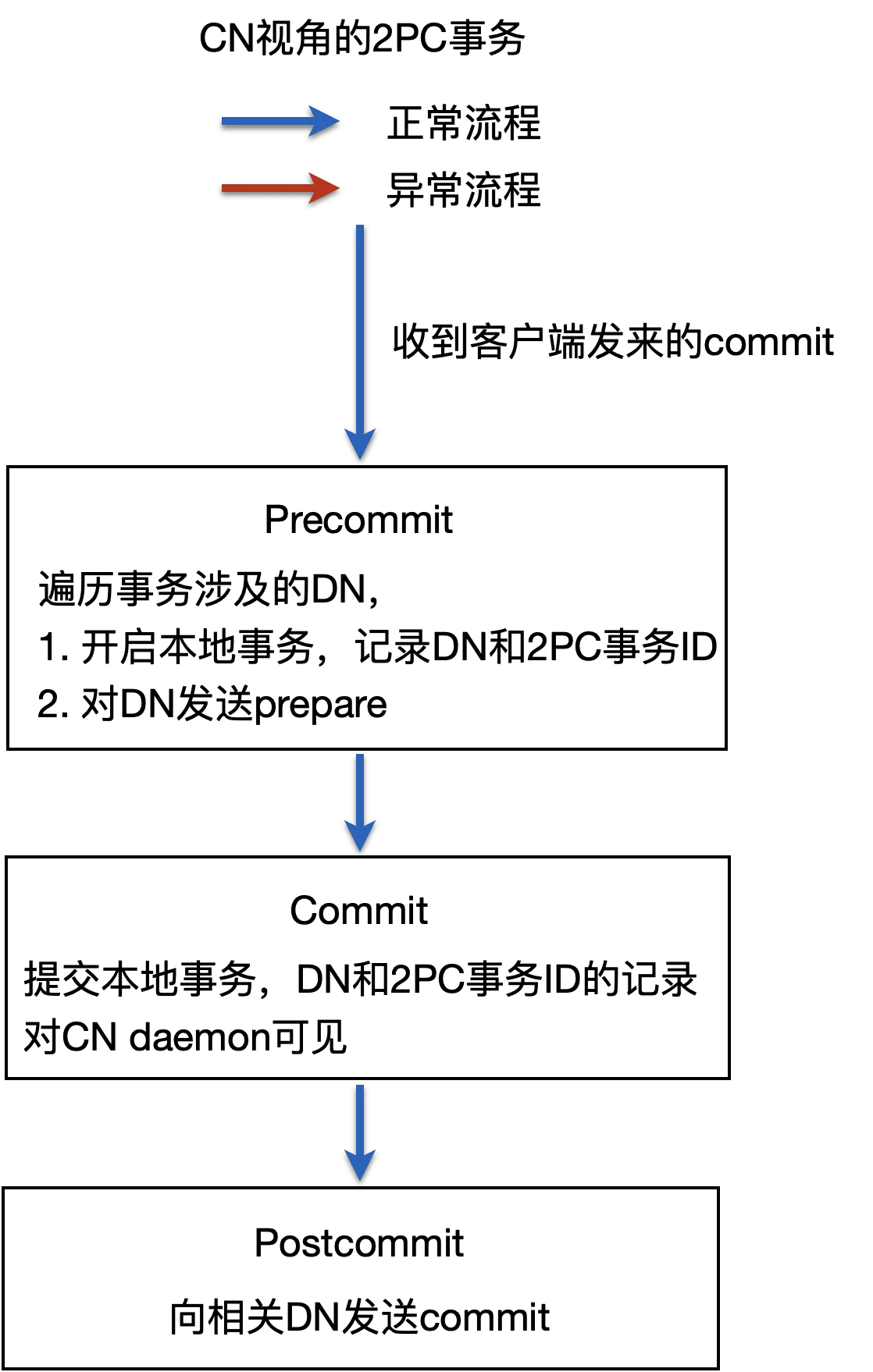
1.6.2.2 正常流程
先来看下正常流程,如下图所示流程。
1.6.2.3 异常流程
2PC事务的进行过程中,任何阶段都可能发生问题,导致2PC回滚或恢复。下图详细列举了任何阶段可能出现的问题,以及Citus是如何确保2PC事务的正确性。
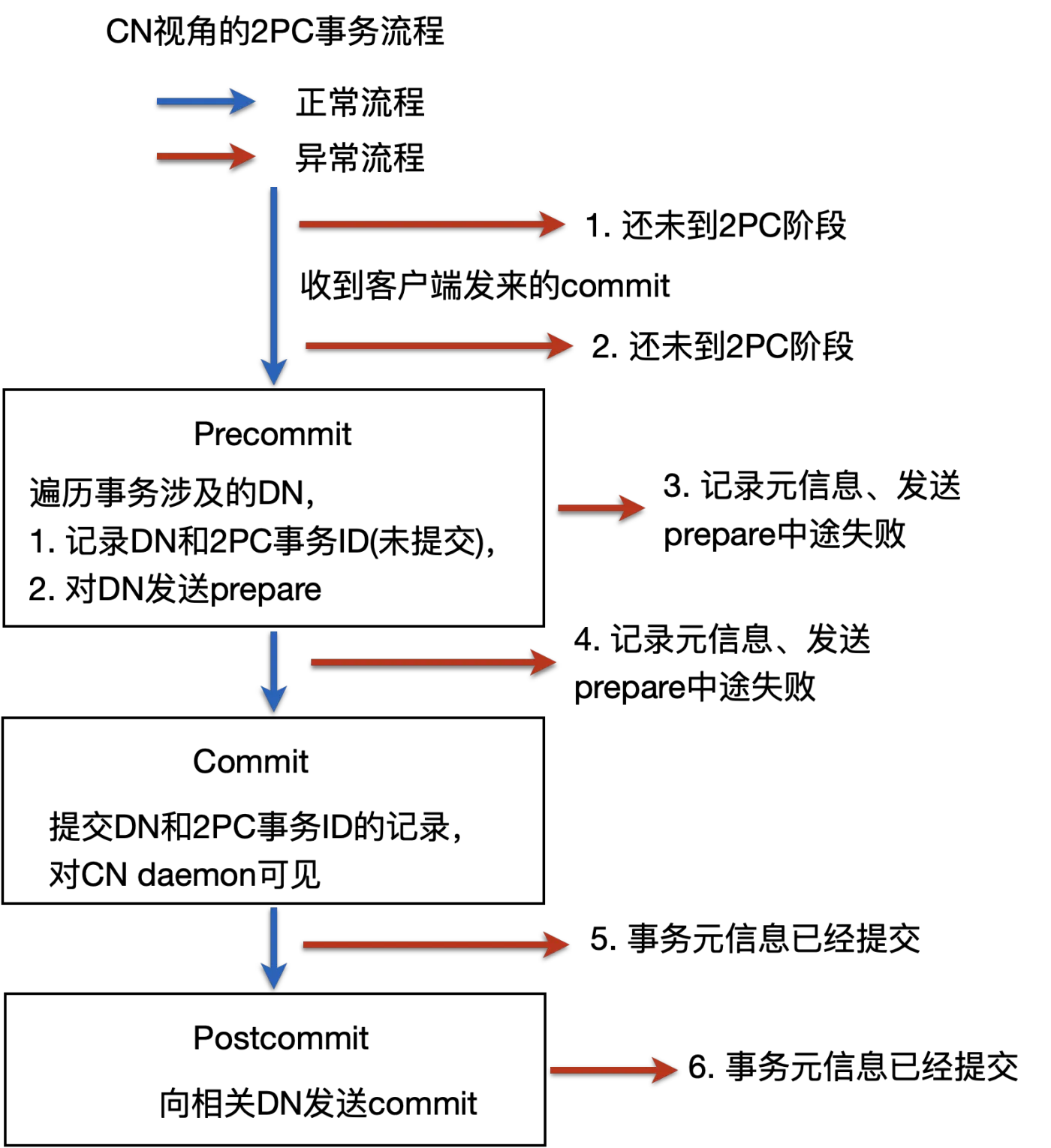
在解释图中的每个阶段之前,先重申下两个表的作用:
- CN上的表 pg_dist_transaction:记录DN和2PC事务ID。2PC开始时记录,但未提交对外不可见。prepare阶段成功后提交,对外可见。
- DN上的表 pg_prepared_xacts:PG自带,记录已经prepare没有commit的事务,commit/rollback后会自动删除。
我们按照图中的顺序,分别讲述每一个流程出现问题后,Citus如何处理。
- 1和2:事务没有commit,还未到2PC阶段,系统就崩溃了。
事务处理:2PC事务还未开始,系统恢复后需要回滚事务。
具体步骤:
- 若CN挂了,CN和DN的连接重置,CN与客户端的连接重置,未提交事务自动回滚,客户端收到connection reset。
- 若DN挂了,CN对存活DN发送rollback,对客户端返回ERROR
- 3和4:2PC事务正式开始,记录了2PC事务的元信息,包括2PC事务ID和参与2PC事务的DN节点。但还没对DN发起prepare,或者有一部分DN prepare了,系统就崩溃了。
事务处理:2PC事务没有全部prepare成功就崩溃了,系统恢复后需要回滚事务。CN daemon对比pg_dist_transaction和pg_prepared_xacts的记录差异,可以很容易得出在DN需要回滚的prepared transaction。
具体步骤:
- 若CN挂了,CN和DN的连接重置,CN与客户端的连接重置,未提交事务自动回滚,客户端收到connection reset。CN daemon清理DN上的prepared transaction。
- 若DN挂了,CN对存活DN发送rollback,对客户端返回ERROR。CN daemon清理DN上的prepared transaction。
- 5和6:2PC事务的prepare成功,2PC事务元信息已经提交(pg_dist_transaction表对外可见)。
事务处理:系统恢复后提交2PC事务。
具体步骤:
- 若CN挂了,CN与客户端连接重置,客户端收到connection reset,CN daemon提交DN上的prepared transaction。
- 若DN挂了,CN对客户端返回WARN,CN daemon提交DN上的prepared transaction。
(在上述实现中,pg_dist_tranaction表的访问很容易成为读写热点,为了不对其上锁,采用2次检测的方法。)
1.6.3 全局死锁检测
- 每个事务都有CNID、TXID的标识
- CN daemon周期性轮询所有DN的事务信息,构建全局的wait-for有向图,成环即死锁
1.6.4 小结
Citus在分布式事务上只支持一致性写,没有一致性读,这也与第4章不鼓励分布式JOIN交相呼应。Citus的分布式实践一直在化繁为简,减少用户的学习成本,将分布式的SQL、事务都规约到同一个shard,简单且实用。
1.7 Citus 集群管理:高可用和容灾、数据热点/数据倾斜、分布式的线性拓展、PITR
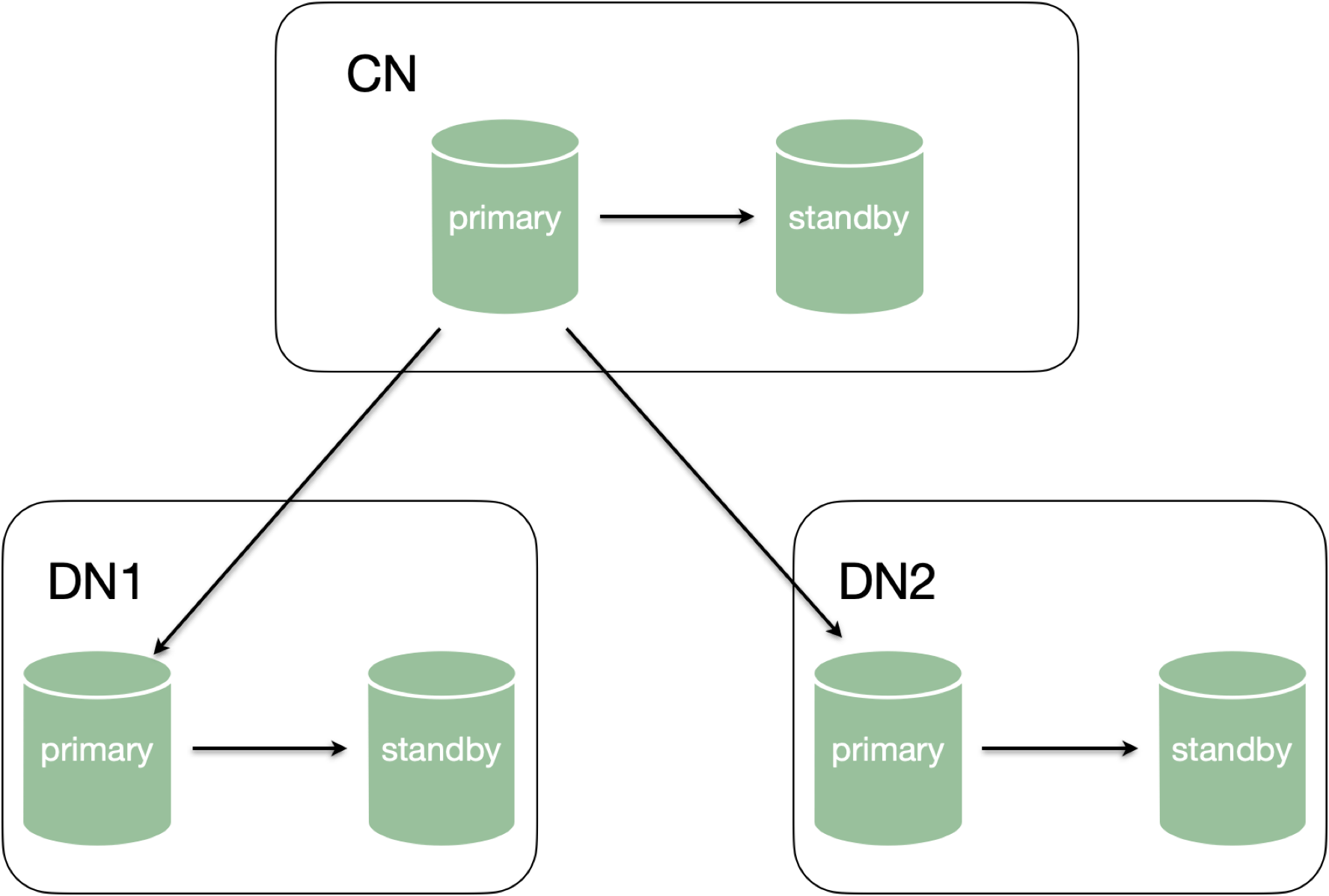
1.7.1 Citus的高可用和容灾
PG原生支持多副本复制,没有自选主能力。Citus选择复用PG原生的能力,Azure商业化最佳实践为:CN和DN节点使用主备强同步复制,保证高可用,主备部署在不同的AZ。
1.7.2 数据热点/数据倾斜、分布式线性拓展
分布式数据库解决了单机数据库的数据量、吞吐、并发、计算效率等问题,但数据分布方式的变化不可避免会带来新的问题,包括以下问题:数据热点问题(数据的访问集中在某些分片上)、数据倾斜问题(数据分布不均匀集中在某些分片上)、分布式线性扩展能力(CN、DN的线性拓展)等等。
接下来我们看看Citus如何解决这些问题。
1.7.2.1 分片迁移
解决数据热点/数据倾斜、分布式线性拓展的问题,最基础、也是最重要的能力就是数据迁移的能力。有了数据迁移,分布式数据库里的上述问题才能够解决。
数据迁移的单位是一个分片组,即所有sharding方式相同的表。我们先讲下分片迁移的实现原理,然后再介绍上述这些问题该如何解决。
分片迁移的原理其实就是迁移一个分片里的所有表+修改元数据,Citus提供了两个方案:
- 方案一:COPY table + 修改集群元信息表,这种方案将源表的数据以二进制流batch写入目标表,速度很快,但是全程禁写,只适合离线使用。
- 方案二:逻辑订阅 + 修改集群元信息表,迁移时先全量再增量,割接时迁移的表只读。这种方案是online的,可以在线上使用。
(修改集群元数据涉及到数据和缓存的一致性,Citus使用trigger+signal invalidate机制,实现很优雅,这里就不展开讲了)
上述方案在执行前会记录元信息,即使在运行中集群崩溃,重启后是可以继续的。
有了分片迁移的基础,下面我们再来讨论数据热点/数据倾斜、分布式线性拓展的问题解决方案。
1.7.2.2 数据热点/数据倾斜的解决方案
1. 分片分裂
某个分片的数据存在热点/倾斜,最简单也最实用的办法就是把热点/倾斜的数据拆出来,然后迁移到资源相对充裕的节点上。不同的分片方式(hash和range),会有不同的方案:
- hash分片:hash分片使用一致性哈希,分片分裂需要将原有的一个分片拆成三个分片(具体做法如下图)。这种情况适用于某个sharding column的数据过多,需要单独拿出来,例如多租户数据以user_id分片,某个user的数据量特别大,需要单独分裂出来。
- range分片:range分片的区间是人工指定,分片分裂也是将原有区间一分为二。例如数据以月份归档,1月1日1月31日的数据量太大,拆分为1月1日1月15日、1月16日~1月31日。这个case比较简单就不画图说明了。
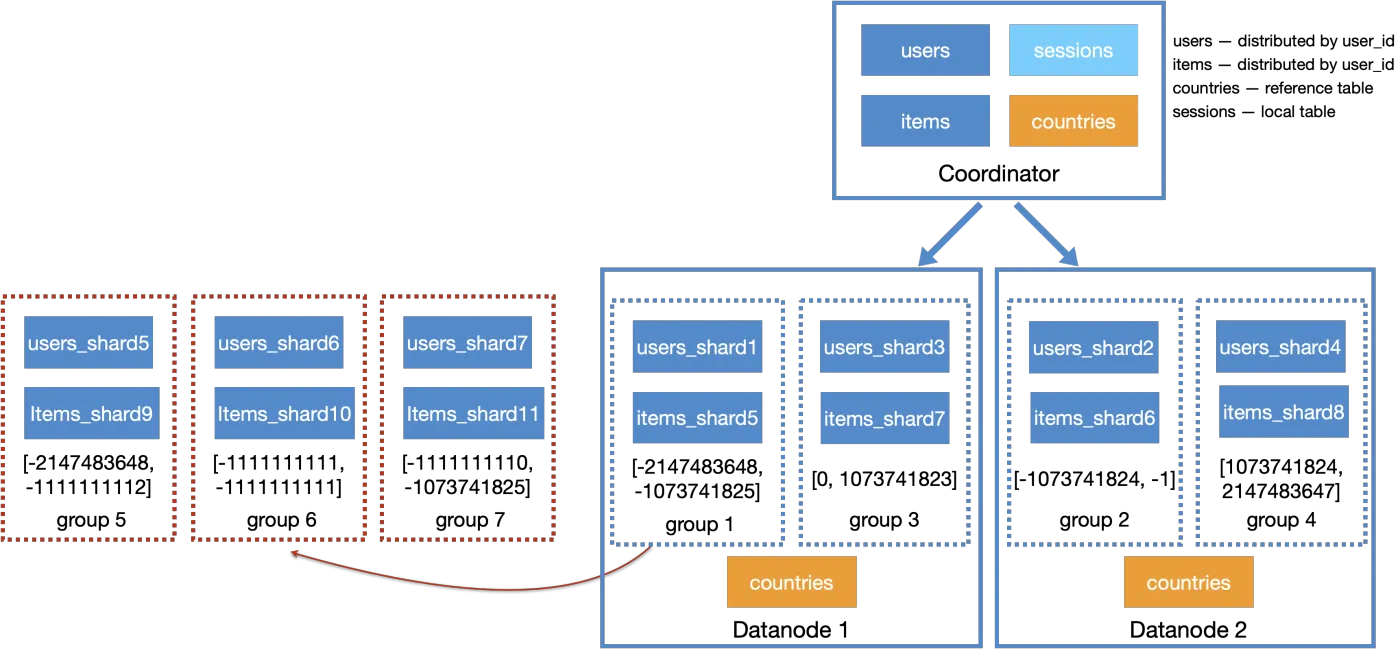
hash分片的分裂方式如上图所示,sharding column=135的数据量大,hash_int32(135) = -1111111111,所以要把group1分裂为group5、group6、group7。group为sharding column相同的所有亲和表构成的集合。最后使用分片迁移,将group6迁移到另一个资源充裕的节点。
2. schema change
对于一个分布式的表,sharding column的选择可谓是十分重要,直接决定了未来数据是否分布均匀。Citus也提供了修改sharding column的方式,例如用户表(user)当前以country_id(国家)分片,数据倾斜严重,改为以user_id分片。但是这种方式要阻塞在线的读写,不建议线上使用。
1.7.2.3 分布式线性拓展
随着业务的增长,数据量越来越大,TPS越来越高,往往需要添加更多的计算节点(CN)和存储节点(DN)。
1. CN的线性拓展
Citus提供了多CN的方式,包含一个master CN和多个普通CN节点,只有master CN才可以修改集群元信息,包括集群拓扑等。每个CN节点都可以接受客户端的DML SQL。
但Azure基于Citus的商业化实践里,只有单CN方式。一是这样管理比较简单,无论从用户使用还是后端运维。二是Azure认为CN不会成为计算瓶颈,CN节点的计算很轻量,Citus更倾向于将计算下推到DN上进行,这个从上述SQL Limitation也可以看出。
2. DN的线性拓展
新加一个DN节点,或者删除一个DN节点,都面临着数据的迁移。数据迁移的方式就是6.2.1介绍的分片迁移,强调下,数据迁移的单位是一个分片组,即所有sharding方式相同的表。
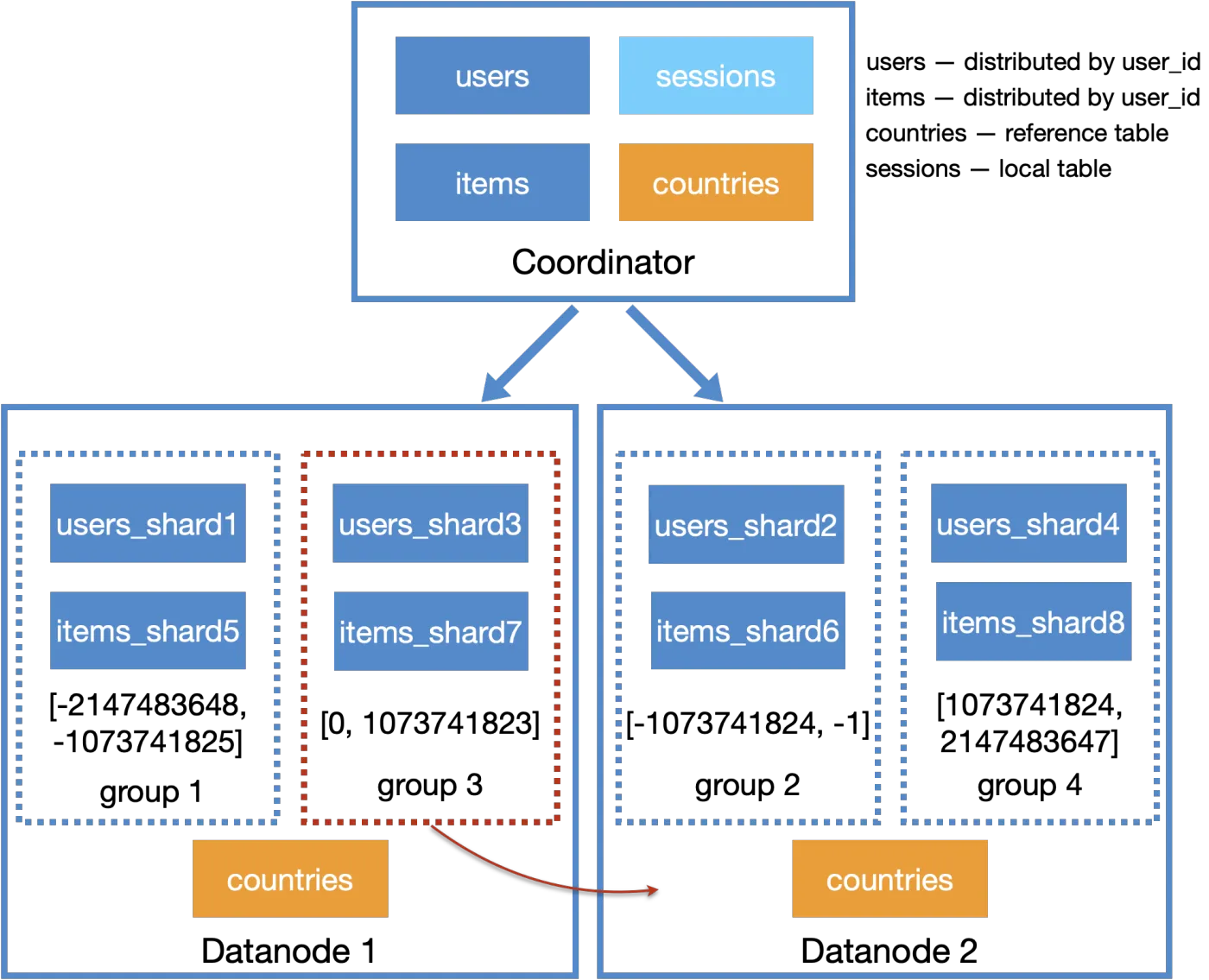
决定数据迁移的源端和目标端,是要有一定算法的。Citus提供了两种算法支持:
- by_shard_count:尽可能让每个DN上的分片数量相同。针对图中例子,会在group1/2/3/4中选择一个迁移到Datanode3,默认选择第一个也就是group 1。
- by_disk_size:尽可能让每个DN上的数据量相同。每个表的数据量直接使用了PG原生的统计信息。针对图中例子,会计算出哪些group迁移到Datanode 3后,每个datanode数据量相对平均。
总的流程如下:
- 根据设定的算法,计算哪些分片需要迁移和迁移的目标节点,写入集群元信息表。
- 根据步骤1的迁移元信息,进行数据迁移。迁移的单位是一个分片,多个分片任务可以并行。
1.7.3 Citus集群PITR
分布式数据库中的按时间点还原,需要将集群中每个节点的状态还原到同一时刻,不然容易造成状态不一致导致的失败。
Citus对此的解决方案是抢整个集群的Exclusive锁,该锁禁止了所有对集群的更改,包括集群元数据和用户数据,抢到锁后对所有节点创建restore point,此步骤与PG原生无异。创建restore point时指定超时时间,超过此时间整个过程失败,避免对在线写的阻塞。
所以我们可以看出,Citus创建还原点不能特别频繁,Azure商业化实践是每小时创建还原点。
1.8 分布式产品对比
1.8.1 服务端
| Citus | PG-XC/TDSQL/GoldenDB | YugabyteDB | CockroachDB/TiDB | |
|---|---|---|---|---|
| 实现方式 | PG插件 | PG内核 | PG内核 | KV on RocksDB + SQL |
| 全局一致性读 | 不支持 | GTM(类TSO) | HLC | HLC/TSO |
| 副本同步 | PG原生主备复制 | PG原生主备复制 | raft | raft |
| 数据分片 | hash/range | hash | hash/range | range |
| Schema change | 只读 | 只读 | 只读 | online |
| 列存 | 支持列存(append-only) | 不支持 | 不支持 | 支持 |
| 热点问题 | 分片分裂、修改分片column | 分片分裂 | 分片分裂 | 分片分裂 |
| 计算下推 | 支持 | 支持 | 支持 | 部分支持 |
1.8.2 客户端和中间件
| Citus | Sharding JDBC | MyCat | |
|---|---|---|---|
| 实现方式 | 服务端PG插件 | Java客户端 | 服务端proxy |
| 分布式事务 | MVCC(无全局MVCC) | MVCC(无全局MVCC) | MVCC(无全局MVCC) |
| 计算下推 | 全部支持 | 部分支持 | 部分支持 |
| 数据分片管理 | hash/range | 每个客户端都要维护hash/range规则 | hash/range |
| 分布式JOIN及优化 | 支持所有类型的JOIN | 不支持跨分片的JOIN | 只支持两表跨分片JOIN |
| 节点互联 | 支持 | 不支持 | 不支持 |
| 扩容 | shard migration | 每个客户端都要修改分片规则 | shard migration |
| 广播表 | 支持 | 支持 | 支持 |
| DDL | 基本全部支持 | 支持常用DDL | 支持常用DDL |
| 集群管理指令 | 丰富,通过SQL函数对客户透明 | 无 | 丰富,需要二次封装 |
1.9 总结
纵观Citus在分布式上的实现与取舍,可以看出并没有完成分布式数据库的所有功能,而是以用户场景为导向,致力于解决某些场景的问题。其在实现上有很多思路值得借鉴。总结如下:
- 插件化实现:PG能力复用和代码耦合达到了很高的平衡
- 最大程度复用PG已有能力
- 代码耦合度很低,可以快速适配新的PG大版本(对比GreenPlum)
- 以业务场景为导向,做分布式功能的取舍
- 舍弃了range的自动分裂
- 舍弃了全局一致性读
- Azure商业化舍弃了多CN,分布式SQL都倾向于做计算下推
2. patroni代码中实现的Citus配置
2.1 代码详情
2.1.1 postgresql/mpp/init.py
"""MPP 处理器的抽象类。
MPP 代表大规模并行处理(Massively Parallel Processing),而 Citus 属于这种架构。目前,Citus 是唯一支持的 MPP 集群。不过,我们可能会考虑将其他数据库(如 TimescaleDB、GPDB 等)适配到 Patroni 中。
"""
AbstractMPP类:作用是作为一个抽象基类,用于定义多节点处理(Multi-Processing Platform, MPP)相关的接口规范。__init__函数:初始化AbstractMPP类的实例,并保存传入的配置信息。is_enabled函数:检查 MPP(多处理平台或多点处理)是否已经启用。validate_config函数:验证传入的配置是否适用于 MPP(多处理平台或多点处理)。is_coordinator函数:检查当前节点是否是协调器节点。is_worker函数:检查当前节点是否是一个工作节点。_get_handler_cls函数:从当前对象的类及其子类中查找所有符合条件的处理器类,并通过迭代器返回这些类。get_handler_impl函数:从当前对象的类及其子类中查找所有符合条件的处理器类,并实例化第一个找到的类,返回其实例化的对象。
AbstractMPPHandler类:定义了一个抽象基类,这个类中通常会包含一些抽象方法,这些方法必须在具体的子类中被实现。通过定义这样一个抽象基类,可以强制所有继承自它的子类实现某些特定的方法或行为,从而确保这些子类具有一定的行为一致性。作为定义多节点拦截器的相关接口规范。__init__函数:初始化AbstractMPPHandler类的一个实例,并设置必要的成员变量。handle_event函数:处理来自工作节点的事件。sync_meta_data函数:在协调器节点上同步元数据。on_demote函数:在主节点被降级时执行特定的操作。schedule_cache_rebuild函数:在需要时调度缓存的重建。bootstrap函数:在新集群初始化时执行特定的操作。adjust_postgres_gucs函数:在当前 PostgreSQL 配置中调整 GUCs(Global User Configuration,全局用户配置)。ignore_replication_slot函数:在给定一个复制槽时决定是否应该忽略(保留)该复制槽而不进行移除。
Null类:提供一个AbstractMPP接口的虚拟实现。__init__函数:初始化Null类的实例。validate_config函数:对提供的配置进行验证。
NullHandler类:提供一个AbstractMPPHandler接口的虚拟实现。__init__函数:初始化NullHandler类的实例。handle_event函数:处理来自工作节点的事件。sync_meta_data函数:在协调器上同步元数据。on_demote函数:处理主节点被降级的情况。schedule_cache_rebuild函数:安排缓存的重建。bootstrap函数:在新集群初始化时执行一系列的设置操作。adjust_postgres_gucs函数:调整 PostgreSQL 数据库的运行时配置参数(GUCs)。ignore_replication_slot函数:判断提供的复制槽是否应该被忽略而不被删除。
iter_mpp_classes函数:从指定的配置中导入 MPP(多并行处理)模块,并返回一个迭代器,每个迭代器元素都是一个元组,包含模块的名称和导入的 MPP 类对象。get_mpp函数:根据提供的配置信息加载并实例化一个 MPP(多并行处理)模块。
2.1.1.1 类:AbstractMPP
- 定义一个名为
AbstractMPP的抽象基类(Abstract Base Class, ABC),它继承自abc.ABC。这表明AbstractMPC是一个抽象类,它的子类需要实现其定义的所有抽象方法。
class AbstractMPP(abc.ABC):
"""一个抽象类,应该传递给 :class:`AbstractDCS`。
.. note::
我们创建 :class:`AbstractMPP` 和 :class:`AbstractMPPHandler` 来解决初始化时的鸡生蛋还是蛋生鸡的问题。
当初始化 DCS 时,我们动态创建一个实现了 :class:`AbstractMPP` 的对象,稍后这个对象被用来实例化一个实现了 :class:`AbstractMPPHandler` 的对象。
"""
group_re: Any # re.Pattern[str]
AbstractMPP 类的具体作用是作为一个抽象基类,用于定义多节点处理(Multi-Processing Platform, MPP)相关的接口规范。该类被设计为与另一个抽象类 AbstractDCS 一起使用,以解决初始化时的依赖问题。
通过创建 AbstractMPP 和 AbstractMPPHandler 这两个抽象类,可以实现如下功能:
- 初始化时依赖问题的解决:在初始化 DCS(Distributed Coordination System,分布式协调系统)时,先创建一个实现了
AbstractMPP的对象,然后使用这个对象来实例化一个实现了AbstractMPPHandler的对象。这样就避免了初始化时的循环依赖问题。 - 接口定义:定义了 MPP 系统应该遵循的接口规范,确保所有继承
AbstractMPP的子类都提供一致的方法和属性。 - 动态创建对象:允许在运行时动态创建实现
AbstractMPP接口的对象,这有助于实现更灵活的系统架构设计。
2.1.1.1.1 __init__()
- 定义了一个名为
__init__的初始化方法,这是类AbstractMPP的构造函数。该方法接收一个参数config,类型为Dict[str, Union[str, int]],表示配置字典,键为字符串,值可以是字符串或整数类型。该方法的返回类型为None。
def __init__(self, config: Dict[str, Union[str, int]]) -> None:
""":class:`AbstractMPP` 类的初始化方法。
:param config: MPP 部分的配置信息。
"""
self._config = config
作用:
这个 __init__ 方法的具体作用是初始化 AbstractMPP 类的实例,并保存传入的配置信息。当创建 AbstractMPP 的子类实例时,会调用这个构造函数,并将配置信息存储在实例的 _config 属性中。
2.1.1.1.2 is_enabled()
- 定义了一个名为
is_enabled的实例方法,该方法返回一个布尔值(bool)。
def is_enabled(self) -> bool:
"""检查给定的 MPP 是否启用。
.. note::
我们只是检查 :attr:`_config` 对象是否为空,并且期望它仅在 :class:`Null` 的情况下为空。
:returns: 如果 MPP 启用则返回 ``True``,否则返回 ``False``。
"""
return bool(self._config)
作用:
is_enabled 方法的具体作用是检查 MPP(多处理平台或多点处理)是否已经启用。通过检查 _config 属性是否为空,可以判断 MPP 是否已经被配置并且准备好使用。如果 _config 包含任何配置信息,则认为 MPP 已启用;否则,认为 MPP 未启用。
2.1.1.1.3 validate_config()
- 定义了一个静态抽象方法
validate_config。这个方法是一个静态方法(@staticmethod),同时也是抽象方法(@abc.abstractmethod)。这意味着该方法不会访问类或实例的任何状态,但在子类中必须被实现。
@staticmethod
@abc.abstractmethod
def validate_config(config: Any) -> bool:
"""检查提供的配置是否适合给定的 MPP。
:param config: MPP 部分的配置信息。
:returns: 如果配置通过验证则返回 ``True``,否则返回 ``False``。
"""
作用:
validate_config 方法的具体作用是验证传入的配置是否适用于 MPP(多处理平台或多点处理)。该方法接收一个 config 参数,并返回一个布尔值,表示配置是否有效。
2.1.1.1.4 is_coordinator()
- 定义了一个名为
is_coordinator的实例方法,该方法返回一个布尔值(bool)。
def is_coordinator(self) -> bool:
"""检查当前节点是否正在协调器 PostgreSQL 集群中运行。
:returns: 如果 MPP 启用并且当前节点的组 ID 与 :attr:`coordinator_group_id` 匹配,则返回 ``True``,否则返回 ``False``。
"""
return self.is_enabled() and self.group == self.coordinator_group_id
方法体中返回一个布尔表达式的结果。该表达式由两部分组成:
self.is_enabled():调用is_enabled方法来检查 MPP 是否启用。self.group == self.coordinator_group_id:检查当前节点的组 ID (self.group) 是否等于协调器的组 ID (self.coordinator_group_id)。
作用:
is_coordinator 方法的具体作用是检查当前节点是否是协调器节点。协调器节点通常是分布式系统中的中心节点,负责协调其他节点的工作。在多处理平台(MPP)环境下,协调器节点负责任务的调度和其他节点的管理。
2.1.1.1.5 is_worker()
- 定义了一个名为
is_worker的实例方法,该方法返回一个布尔值(bool)。
def is_worker(self) -> bool:
"""检查当前节点是否作为 MPP 工作节点 PostgreSQL 集群运行。
:returns: 如果 MPP 启用并且已知当前节点不是作为协调器 PostgreSQL 集群运行,则返回 ``True``,否则返回 ``False``。
"""
return self.is_enabled() and not self.is_coordinator()
方法体中返回一个布尔表达式的结果。该表达式由两部分组成:
self.is_enabled():调用is_enabled方法来检查 MPP 是否启用。not self.is_coordinator():检查当前节点是否不是协调器节点。
只有当这两部分都为 True 时,整个表达式才为 True,否则为 False。
作用:
is_worker 方法的具体作用是检查当前节点是否是一个工作节点。在一个 MPP(多处理平台或多点处理)环境中,工作节点负责执行由协调器节点分配的任务。该方法通过判断 MPP 是否启用以及当前节点是否不是协调器节点来确定当前节点的角色。
2.1.1.1.6 _get_handler_cls()
- 定义了一个名为
_get_handler_cls的实例方法,该方法返回一个迭代器,其中每个元素都是AbstractMPPHandler的子类类型。
def _get_handler_cls(self) -> Iterator[Type['AbstractMPPHandler']]:
"""查找继承自当前对象类类型的处理器类。
:yields: 返回当前对象的处理器类。
"""
for cls in self.__class__.__subclasses__():
if issubclass(cls, AbstractMPPHandler) and cls.__name__.startswith(self.__class__.__name__):
yield cls
方法体中使用了一个 for 循环来遍历当前对象类的所有子类:
self.__class__.__subclasses__():获取当前对象所属类的所有直接子类。if issubclass(cls, AbstractMPPHandler) and cls.__name__.startswith(self.__class__.__name__):- 检查子类
cls是否继承自AbstractMPPHandler。 - 检查子类的名字是否以当前对象所属类的名字开头。
- 检查子类
yield cls:如果上述条件都满足,则通过yield关键字返回子类cls。
作用:
_get_handler_cls 方法的具体作用是从当前对象的类及其子类中查找所有符合条件的处理器类,并通过迭代器返回这些类。具体来说,该方法查找的是继承自当前对象类的子类,并且这些子类也继承自 AbstractMPPHandler,同时子类的名字以当前对象所属类的名字开头。
2.1.1.1.7 get_handler_impl()
- 定义了一个名为
get_handler_impl的实例方法,该方法接受一个postgresql参数,类型为Postgresql,并返回一个实现了AbstractMPPHandler接口的对象。
def get_handler_impl(self, postgresql: 'Postgresql') -> 'AbstractMPPHandler':
"""查找并实例化当前对象的处理器实现。
:param postgresql: 指向 :class:`Postgresql` 对象的引用。
:raises:
:exc:`PatroniException`: 如果没有找到处理器类,则抛出异常。
:returns: 实现了当前对象处理器的实例化类。
"""
for cls in self._get_handler_cls():
return cls(postgresql, self._config)
raise PatroniException(f'Failed to initialize {self.__class__.__name__}Handler object')
方法体中使用了一个 for 循环来遍历 _get_handler_cls 方法返回的所有类:
for cls in self._get_handler_cls()::遍历所有符合条件的处理器类。return cls(postgresql, self._config):如果找到了符合条件的类,就使用postgresql和_config参数实例化该类,并返回实例化的对象。raise PatroniException(f'Failed to initialize {self.__class__.__name__}Handler object'):如果循环结束都没有找到符合条件的类,则抛出PatroniException异常,表示初始化处理器对象失败。
作用:
get_handler_impl 方法的具体作用是从当前对象的类及其子类中查找所有符合条件的处理器类,并实例化第一个找到的类,返回其实例化的对象。具体来说,该方法查找的是继承自当前对象类的子类,并且这些子类也继承自 AbstractMPPHandler,同时子类的名字以当前对象所属类的名字开头。如果找到了这样的类,就使用传入的 postgresql 对象和 _config 配置信息来实例化该类,并返回实例化的对象。如果没有找到这样的类,则抛出异常。
2.1.1.2 类:AbstractMPPHandler
- 定义了一个名为
AbstractMPPHandler的类,它继承自AbstractMPP类。这表明AbstractMPPHandler是一个抽象类,并且它继承了AbstractMPP类的所有属性和方法。
class AbstractMPPHandler(AbstractMPP):
"""一个抽象类,定义了应该由实际的处理器实现的接口。"""
AbstractMPPHandler 类的具体作用是定义了一个抽象基类,这个类中通常会包含一些抽象方法,这些方法必须在具体的子类中被实现。通过定义这样一个抽象基类,可以强制所有继承自它的子类实现某些特定的方法或行为,从而确保这些子类具有一定的行为一致性。
2.1.1.2.1 __init__()
- 定义了一个名为
__init__的构造函数,该构造函数接收两个参数:postgresql和config,并返回None。
def __init__(self, postgresql: 'Postgresql', config: Dict[str, Union[str, int]]) -> None:
"""初始化方法用于 :class:`AbstractMPPHandler`。
:param postgresql: 指向 :class:`Postgresql` 对象的引用。
:param config: MPP 部分的配置信息。
"""
super().__init__(config)
self._postgresql = postgresql
作用:
__init__ 方法的具体作用是初始化 AbstractMPPHandler 类的一个实例,并设置必要的成员变量。具体来说:
-
初始化父类:
通过调用
super().__init__(config),初始化从父类继承的属性或执行父类构造函数中的逻辑。 -
设置成员变量:
将传入的
postgresql对象赋值给_postgresql成员变量,这样就可以在类的其他方法中访问这个对象。
2.1.1.2.2 handle_event()
- 定义了一个名为
handle_event的抽象方法,该方法接收两个参数:cluster和event,并返回None。
@abc.abstractmethod
def handle_event(self, cluster: Cluster, event: Dict[str, Any]) -> None:
"""处理来自工作节点的事件。
:param cluster: 当前从 DCS(分布式一致性存储)中已知的集群状态。
:param event: 需要处理的事件。
"""
作用:
handle_event 方法的具体作用是处理来自工作节点的事件。在分布式系统中,协调器节点通常需要处理来自工作节点的各种事件,如心跳消息、状态变更通知等。此方法定义了一个接口,要求任何实现该接口的类都需要提供具体的事件处理逻辑。
2.1.1.2.3 sync_meta_data()
- 定义了一个名为
sync_meta_data的抽象方法,该方法接收一个参数cluster,并返回None。
@abc.abstractmethod
def sync_meta_data(self, cluster: Cluster) -> None:
"""在协调器上同步元数据。
:param cluster: 当前从 DCS(分布式一致性存储)中已知的集群状态。
"""
作用:
sync_meta_data 方法的具体作用是在协调器节点上同步元数据。在分布式系统中,协调器节点通常负责维护集群的整体状态,并确保各个节点之间的元数据一致性。此方法定义了一个接口,要求任何实现该接口的类都需要提供具体的元数据同步逻辑。
2.1.1.2.4 on_demote()
- 定义了一个名为
on_demote的抽象方法,该方法没有参数,并且返回None。
@abc.abstractmethod
def on_demote(self) -> None:
"""降级处理程序。
当主节点被降级时被调用。
"""
作用:
on_demote 方法的具体作用是在主节点被降级时执行特定的操作。在分布式系统中,当一个节点成为主节点后,它通常负责处理客户端请求以及协调其他副本节点的状态。但是,在某些情况下,主节点可能会因为各种原因被降级为副本节点。此时,需要执行一系列操作来适应这种状态的变化。
2.1.1.2.5 schedule_cache_rebuild()
- 定义了一个名为
schedule_cache_rebuild的抽象方法,该方法没有参数,并且返回None。
@abc.abstractmethod
def schedule_cache_rebuild(self) -> None:
"""缓存重建处理程序。
当需要从数据库刷新其元数据缓存时调用此处理程序。
"""
作用:
schedule_cache_rebuild 方法的具体作用是在需要时调度缓存的重建。在分布式系统或数据库应用中,为了提高性能,通常会将常用的数据存储在内存缓存中。然而,缓存中的数据可能会变得过时,或者在某些情况下需要从数据库中重新加载最新数据到缓存中。此时就需要一个机制来触发缓存的刷新或重建。
2.1.1.2.6 bootstrap()
- 定义了一个名为
bootstrap的抽象方法,该方法没有参数,并且返回None。
@abc.abstractmethod
def bootstrap(self) -> None:
"""引导处理程序。
当新集群初始化时(通过 `initdb` 或者自定义的引导方法)调用此处理程序。
"""
作用:
bootstrap 方法的具体作用是在新集群初始化时执行特定的操作。在分布式系统或数据库集群中,初始化集群通常涉及多个步骤,如创建初始的数据库目录结构、配置文件、用户权限等。这个方法提供了一个接口,允许在集群初始化过程中执行必要的操作,以确保集群能够正确启动并准备好接受请求。
2.1.1.2.7 adjust_postgres_gucs()
- 定义了一个名为
adjust_postgres_gucs的抽象方法,该方法接收一个类型为Dict[str, Any]的参数parameters,并返回None。
@abc.abstractmethod
def adjust_postgres_gucs(self, parameters: Dict[str, Any]) -> None:
"""调整当前 PostgreSQL 配置中的 GUCs(运行时配置参数)。
:param parameters: 包含 GUCs 的字典,键为 GUC 名称,对应的值为当前 GUC 的值。
"""
作用:
adjust_postgres_gucs 方法的具体作用是在当前 PostgreSQL 配置中调整 GUCs(Global User Configuration,全局用户配置)。GUCs 是 PostgreSQL 中用于控制服务器行为的配置参数,它们可以在服务器启动时通过配置文件设置,也可以在服务器运行时动态调整。此方法定义了一个接口,要求任何实现该接口的类都需要提供具体的 GUCs 调整逻辑。
2.1.1.2.8 ignore_replication_slot()
@abc.abstractmethod
def ignore_replication_slot(self, slot: Dict[str, str]) -> bool:
"""检查提供的复制槽是否不应被移除。
.. note::
MPP 数据库可能会为其自身使用创建复制槽,例如使用逻辑复制在工作节点间迁移数据,我们不想突然删除它们。
:param slot: 包含复制槽设置的字典,如 `name`、`database`、`type` 和 `plugin`。
:returns: 如果复制槽不应被移除则返回 `True`,否则返回 `False`。
"""
作用:
ignore_replication_slot 方法的具体作用是在给定一个复制槽时决定是否应该忽略(保留)该复制槽而不进行移除。在多节点的数据库系统中,复制槽用于保存流复制的位置信息,以支持数据的连续复制。有时,系统内部会创建一些复制槽用于特殊用途,如数据迁移等,这些槽不应该被误删除。
2.1.1.3 类:Null
- 这一行定义了一个名为
Null的类,它继承自AbstractMPP类。这意味着Null类将会拥有AbstractMPP类的所有属性和方法,并且它是一个“空”实现,即它并不真正执行任何操作,而是作为占位符或默认实现存在。
class Null(AbstractMPP):
"""AbstractMPP 类的虚拟实现。"""
Null 类的具体作用是提供一个 AbstractMPP 接口的虚拟实现。在软件开发中,有时我们需要一个类来实现某个接口或抽象类,但它实际上不执行任何具体的操作。这种情况通常出现在以下几种场合:
- 测试:在单元测试中,有时候我们需要模拟某些类的行为,但又不需要真正的功能实现,这时就可以使用
Null对象来代替。 - 默认行为:在某些框架或库中,提供一个默认的实现,即使用户没有实现具体的功能,也能让程序正常运行。
- 占位符:在开发初期,可能还没有实现某些功能,但是架构已经设计好了,这时候可以用
Null类作为一个占位符,等待后续的实现。
2.1.1.3.1 __init__()
- 定义了一个名为
__init__的构造方法,这是 Python 类的一个特殊方法,用于初始化类的实例。这个方法没有参数(除了self),并且返回类型为None。
def __init__(self) -> None:
""":class:`Null` 类的初始化方法。"""
super().__init__({})
作用:
__init__ 方法的具体作用是初始化 Null 类的实例。当创建 Null 类的新实例时,这个方法会被自动调用,用于执行任何必要的初始化操作。在这个例子中,__init__ 方法主要做了两件事:
-
初始化父类:
调用父类的
__init__方法,并传入一个空字典。这意味着Null类继承自某个类,并且在初始化时需要执行父类的初始化逻辑。 -
不执行额外的初始化操作:
除了调用父类的初始化方法之外,
Null类的__init__方法本身没有执行任何额外的操作。
2.1.1.3.2 validate_config()
- 定义了一个名为
validate_config的静态方法,该方法接收一个类型为Any的参数config,并返回一个布尔值bool。
@staticmethod
def validate_config(config: Any) -> bool:
"""检查提供的配置是否适用于 :class:`Null`。
:returns: 总是返回 `True`。
"""
return True
作用:
validate_config 方法的具体作用是对提供的配置进行验证。在这个例子中,由于返回值总是 True,因此实际上这个方法并没有执行任何真正的验证逻辑,而只是一个占位符或默认实现。这种方法通常用于简化配置验证的过程,特别是在不需要复杂的配置检查逻辑的情况下。
2.1.1.4 类:NullHandler
- 这一行定义了一个名为
NullHandler的类,它继承自Null类和AbstractMPPHandler类。这意味着NullHandler类将会拥有Null类和AbstractMPPHandler类的所有属性和方法,并且它是一个“空”实现,即它并不真正执行任何操作,而是作为占位符或默认实现存在。
class NullHandler(Null, AbstractMPPHandler):
"""AbstractMPPHandler 类的虚拟实现。"""
NullHandler 类的具体作用是提供一个 AbstractMPPHandler 接口的虚拟实现。在软件开发中,有时我们需要一个类来实现某个接口或抽象类,但它实际上不执行任何具体的操作。这种情况通常出现在以下几种场合:
- 测试:在单元测试中,有时候我们需要模拟某些类的行为,但又不需要真正的功能实现,这时就可以使用
NullHandler类来代替。 - 默认行为:在某些框架或库中,提供一个默认的实现,即使用户没有实现具体的功能,也能让程序正常运行。
- 占位符:在开发初期,可能还没有实现某些功能,但是架构已经设计好了,这时候可以用
NullHandler类作为一个占位符,等待后续的实现。
2.1.1.4.1 __init__()
- 定义了一个名为
__init__的构造方法,这是 Python 类的一个特殊方法,用于初始化类的实例。这个方法接收两个参数:postgresql和config,并且返回类型为None。postgresql: 类型为'Postgresql'的对象引用。config: 类型为Dict[str, Union[str, int]]的字典,表示配置项,其中键为字符串,值可以是字符串或整数。
def __init__(self, postgresql: 'Postgresql', config: Dict[str, Union[str, int]]) -> None:
"""NullHandler 类的初始化方法。
:param postgresql: Postgresql 对象的引用。
:param config: MPP 部分的配置。
"""
AbstractMPPHandler.__init__(self, postgresql, config)
作用:
__init__ 方法的具体作用是初始化 NullHandler 类的实例。当创建 NullHandler 类的新实例时,这个方法会被自动调用,用于执行任何必要的初始化操作。在这个例子中,__init__ 方法主要做了两件事:
- 初始化父类:调用父类
AbstractMPPHandler的__init__方法,并传入postgresql和config参数。这意味着NullHandler类继承自AbstractMPPHandler类,并且在初始化时需要执行父类的初始化逻辑。 - 不执行额外的初始化操作:除了调用父类的初始化方法之外,
NullHandler类的__init__方法本身没有执行任何额外的操作。
2.1.1.4.2 handle_event()
- 定义了一个名为
handle_event的方法,它接收两个参数:cluster和event,并且返回类型为None。cluster: 类型为Cluster的对象,表示当前从分布式一致性存储(DCS)中已知的集群状态。event: 类型为Dict[str, Any]的字典,表示要处理的事件。
def handle_event(self, cluster: Cluster, event: Dict[str, Any]) -> None:
"""处理来自工作节点的事件。
:param cluster: 从 DCS 获取的当前已知的集群状态。
:param event: 要处理的事件。
"""
作用:
handle_event 方法的具体作用是处理来自工作节点的事件。在分布式系统中,各个节点之间通常需要相互通信来协调状态和执行操作。这个方法负责接收来自工作节点的事件,并根据当前集群的状态来处理这些事件。
2.1.1.4.3 sync_meta_data()
- 定义了一个名为
sync_meta_data的方法,它接收一个参数cluster,并且返回类型为None。cluster: 类型为Cluster的对象,表示当前从分布式一致性存储(DCS)中已知的集群状态。
def sync_meta_data(self, cluster: Cluster) -> None:
"""在协调器上同步元数据。
:param cluster: 从 DCS 获取的当前已知的集群状态。
"""
作用:
sync_meta_data 方法的具体作用是在协调器上同步元数据。在分布式系统中,元数据通常是指描述数据的数据,例如数据库表的结构、索引信息、权限设置等。在某些场景下,这些元数据需要在整个集群中保持一致,因此需要一个机制来同步这些元数据。
2.1.1.4.4 on_demote()
- 定义了一个名为
on_demote的方法,它没有接收任何参数,并且返回类型为None。
def on_demote(self) -> None:
"""降级处理程序。
当主节点被降级时被调用。
"""
作用:
on_demote 方法的具体作用是处理主节点被降级的情况。在分布式系统或集群环境中,通常有一个主节点负责协调事务和其他重要操作。当主节点因为某种原因无法继续担任主节点的角色时,它会被降级为从节点或其他角色。此时,on_demote 方法就会被调用,以便执行一些必要的处理步骤,如清理资源、更新状态信息等。
2.1.1.4.5 schedule_cache_rebuild()
- 定义了一个名为
schedule_cache_rebuild的方法,它没有接收任何参数,并且返回类型为None。
def schedule_cache_rebuild(self) -> None:
"""缓存重建处理程序。
被调用以通知处理器需要从数据库刷新其元数据缓存。
"""
作用:
schedule_cache_rebuild 方法的具体作用是安排缓存的重建。在很多应用场景中,系统会维护一个缓存来存储频繁访问的数据,以提高性能。然而,缓存中的数据可能会随着时间推移变得过时,或者在某些特定情况下(如数据库中的数据发生了变化),需要更新缓存中的数据。此时,schedule_cache_rebuild 方法就会被调用,以便执行缓存重建的操作。
2.1.1.4.6 bootstrap()
- 定义了一个名为
bootstrap的方法,它没有接收任何参数,并且返回类型为None。
def bootstrap(self) -> None:
"""引导处理程序。
当新集群被初始化(通过 `initdb` 或者自定义的引导方法)时被调用。
"""
作用:
bootstrap 方法的具体作用是在新集群初始化时执行一系列的设置操作。在分布式系统中,当创建一个新的集群时,需要执行一系列的初始化步骤来确保集群能够正常运行。这些步骤可能包括但不限于配置文件的准备、数据库的初始化、元数据的设置等。
2.1.1.4.7 adjust_postgres_gucs()
- 定义了一个名为
adjust_postgres_gucs的方法,它接收一个参数parameters,并且返回类型为None。parameters: 类型为Dict[str, Any]的字典,表示要调整的 PostgreSQL 配置参数(GUCs),其中键为 GUC 名称,值为对应的当前 GUC 值。
def adjust_postgres_gucs(self, parameters: Dict[str, Any]) -> None:
"""调整当前 PostgreSQL 配置中的 GUCs(Global User Configuration)。
:param parameters: 字典形式的 GUCs,其中键为 GUC 名称,对应的值为当前 GUC 的值。
"""
作用:
adjust_postgres_gucs 方法的具体作用是调整 PostgreSQL 数据库的运行时配置参数(GUCs)。在 PostgreSQL 中,GUCs 是一组可以动态更改的配置选项,它们控制着数据库服务器的行为。这些配置选项可以在服务器启动时通过配置文件设置,也可以在服务器运行时通过 SQL 命令进行更改。此方法接收一个包含要调整的 GUC 及其当前值的字典,并执行相应的调整操作。
2.1.1.4.8 ignore_replication_slot()
- 定义了一个名为
ignore_replication_slot的方法,它接收一个参数slot,并且返回类型为bool。slot: 类型为Dict[str, str]的字典,表示复制槽(replication slot)的设置,如名称、数据库、类型和插件等。
def ignore_replication_slot(self, slot: Dict[str, str]) -> bool:
"""检查提供的复制槽(slot)是否存在数据库中并且不应被删除。
.. note::
MPP 数据库可能会为了自身使用而创建复制槽,例如使用逻辑复制在工作节点之间迁移数据,我们不希望突然删除它们。
:param slot: 包含复制槽设置的字典,如 `name`、`database`、`type` 和 `plugin`。
:returns: 总是返回 `False`。
"""
return False
作用:
ignore_replication_slot 方法的具体作用是判断提供的复制槽是否应该被忽略而不被删除。在 PostgreSQL 数据库中,复制槽用于持久化流复制或逻辑复制的位置信息。这些槽记录了复制的位置,并且在某些情况下(如 MPP 数据库中),这些复制槽可能是系统为了实现某些功能(如数据迁移)而创建的。因此,在删除复制槽之前,我们需要确定这个复制槽是否可以安全地被删除。
2.1.1.5 iter_mpp_classes()
- 定义了一个名为
iter_mpp_classes的函数,它接收一个可选参数config,并且返回类型为Iterator[Tuple[str, Type[AbstractMPP]]]。config: 类型为Optional[Union['Config', Dict[str, Any]]]的可选参数,表示配置信息,其中可能包含作为键的 MPP 名称。如果提供了配置信息,则仅尝试导入配置中定义的 MPP 模块;如果没有提供,则尝试导入任何支持的 MPP 模块。
def iter_mpp_classes(
config: Optional[Union['Config', Dict[str, Any]]] = None
) -> Iterator[Tuple[str, Type[AbstractMPP]]]:
"""尝试导入给定配置中存在的 MPP 模块。
:param config: 配置信息,其中可能包含作为键的 MPP 名称。如果提供了配置信息,则仅尝试导入配置中定义的 MPP 模块。否则,如果为 ``None``,则尝试导入任何支持的 MPP 模块。
:yields: 元组,每个元组包含模块的 ``name`` 和导入的 MPP 类对象。
"""
if TYPE_CHECKING: # pragma: no cover
assert isinstance(__package__, str)
yield from iter_classes(__package__, AbstractMPP, config)
作用:
iter_mpp_classes 函数的具体作用是从指定的配置中导入 MPP(多并行处理)模块,并返回一个迭代器,每个迭代器元素都是一个元组,包含模块的名称和导入的 MPP 类对象。这个函数主要用于在系统初始化期间加载支持的 MPP 模块,并使得可以通过模块名称来访问这些 MPP 类。
2.1.1.6 get_mpp()
- 定义了一个名为
get_mpp的函数,它接收一个参数config,并且返回类型为AbstractMPP。config: 类型为Union['Config', Dict[str, Any]]的参数,表示配置对象或字典,包含 Patroni 配置信息。
def get_mpp(config: Union['Config', Dict[str, Any]]) -> AbstractMPP:
"""尝试从已知的可用实现中加载并实例化一个 MPP 模块。
:param config: 包含 Patroni 配置信息的对象或字典。
:returns: 成功加载的 MPP 或者回退到 :class:`Null`。
"""
for name, mpp_class in iter_mpp_classes(config):
if mpp_class.validate_config(config[name]):
return mpp_class(config[name])
return Null()
作用:
get_mpp 函数的具体作用是根据提供的配置信息加载并实例化一个 MPP(多并行处理)模块。在分布式系统或集群环境中,MPP 模块可能是指特定于某个数据库版本或集群类型的组件,它们负责处理与集群相关的特定任务,比如故障恢复、数据同步等。此函数会首先尝试根据配置信息找到合适的 MPP 类,然后实例化该类并返回其实例。如果没有找到合适的 MPP 类,则返回一个 Null 对象。
2.1.2 postgresql/mpp/citus.py
PgDistNode类:封装了pg_dist_node表中的一行记录,并提供了对这一行记录中各个字段的访问。__init__函数:初始化一个PgDistNode对象,并设置其属性。__hash__函数:定义一个哈希函数,该函数能够为PgDistNode对象生成一个唯一的哈希码。__eq__函数:定义一个比较函数,该函数用于判断两个PgDistNode实例是否相等。__str__函数:定义一个字符串表示形式,该表示形式用于以易读的方式展示PgDistNode对象的所有关键属性。__repr__函数:定义一个“官方”字符串表示形式,这个表示形式通常是为了解释器或开发人员而设计的,用于提供尽可能准确的字符串表示,以便在调试时能更好地理解对象的状态。is_primary函数:判断当前PgDistNode对象是否代表的是一个处于 “primary” 状态的节点。as_tuple函数:提供一个包含PgDistNode对象关键属性的元组,这个元组可以用来方便地进行对象之间的比较,尤其是在需要比较两个PgDistGroup对象的情况下。
PgDistGroup类:提供一种管理 Citus 分布式数据库中节点组的方法。__init__函数:初始化一个PgDistGroup对象,并根据传入的参数设置其初始状态。equals函数:比较两个PgDistGroup对象是否完全相同。primary函数:在当前PgDistGroup对象中查找并返回代表 “primary” 节点的PgDistNode对象。get函数:在当前PgDistGroup对象中查找与给定PgDistNode对象相等的实际PgDistNode对象。transition函数:计算当前PgDistGroup对象相对于旧的PgDistGroup对象的变化,并生成一系列PgDistNode对象,这些对象描述了如何从旧拓扑结构过渡到新拓扑结构。
PgDistTask类:表示pg_dist_node表中特定groupid的当前或期望状态的任务。__init__函数:初始化一个PgDistTask对象,该对象似乎用于处理分布式数据库系统中的某些任务。wait函数:让调用它的线程等待,直到PgDistTask对象关联的事件被设置。wakeup函数:通知等待线程,与PgDistTask对象关联的任务已经被处理完毕。__eq__函数:定义如何判断两个PgDistTask对象是否相等。__ne__函数:定义如何判断两个PgDistTask对象是否不相等。
Citus类:Citus信息管理。validate_config函数:验证传入的config是否符合预期的格式,以确保它可以正确地用于某个特定的MPP(大规模并行处理)系统,这里是citus。
CitusHandler类:处理Citus集群的接口或框架。__init__函数:初始化一个新的CitusHandler实例。schedule_cache_rebuild函数:调度缓存的重建。on_demote函数:在接收到节点降级(demotion)的通知时,清理与当前节点相关的所有任务和缓存信息。query函数:在CitusHandler类中执行SQL查询,并处理可能发生的异常。load_pg_dist_group函数:从数据库的pg_dist_node表中读取节点信息,并将这些信息放入本地缓存中。sync_meta_data函数:在每次心跳循环中,同步集群中的元数据信息,确保本地缓存中的pg_dist_node信息与集群视图保持一致。find_task_by_groupid函数:在任务列表中查找具有指定groupid的任务,并返回该任务的索引位置pick_task函数:在任务列表中选择一个任务,并返回该任务的索引及其本身。update_node函数:在Citus集群中更新或添加节点,并处理节点的移除。update_group函数:在Citus集群中更新指定组内的节点状态。process_task函数:在Citus集群中处理与节点状态相关的任务,并根据任务类型管理事务。process_tasks函数:在Citus集群中持续处理任务列表中的任务,并根据任务处理的结果更新缓存或开启事务。run函数:启动一个循环来持续处理任务,并管理事务的状态。_add_task函数:在任务列表中添加或替换任务,并根据任务的状态决定是否进行操作。_pg_dist_node函数:从连接字符串中解析出PostgreSQL分布式节点的相关信息,并创建一个PgDistNode对象。add_task函数:根据提供的事件类型、组ID、集群信息等参数创建一个PgDistTask对象,并向系统中添加该任务。handle_event函数:处理来自集群的事件,并根据事件类型采取相应的行动。bootstrap函数:初始化新集群时进行一系列的设置工作。adjust_postgres_gucs函数:对PostgreSQL的全局配置参数进行调整,以适应Citus分布式数据库的特定需求。ignore_replication_slot函数:判断一个复制槽是否应该被保留而不是被移除。
2.1.2.1 类:PgDistNode
- 定义了一个名为
PgDistNode的类,它代表了pg_dist_node表中的一行记录。
class PgDistNode:
"""代表 "pg_dist_node" 表中的一行记录。
.. note::
不同于 "noderole",``role`` 的可能值有 "primary"、"secondary" 和 "demoted"。
最后一个值用于通过在 "nodename" 后面附加 "-demoted" 后缀来暂停协调器到工作节点的客户端连接。
数据库中的实际 "noderole" 仍然是 "primary"。
:ivar host: "nodename" 值
:ivar port: "nodeport" 值
:ivar role: "noderole" 值
:ivar nodeid: "nodeid" 值
"""
PgDistNode 类的具体作用是封装了 pg_dist_node 表中的一行记录,并提供了对这一行记录中各个字段的访问。在 Greenplum for PostgreSQL 或类似的多节点并行处理数据库系统中,pg_dist_node 表用于存储集群中各个节点的信息。这个类可以帮助开发者更方便地管理和操作这些节点的信息。
2.1.2.1.1 __init__()
- 定义了一个名为
__init__的构造函数,它接收四个参数,并且返回类型为None。host: 类型为str的参数,表示节点的主机名(“nodename”)。port: 类型为int的参数,表示节点的端口号(“nodeport”)。role: 类型为str的参数,表示节点的角色(“noderole”)。nodeid: 类型为Optional[int]的参数,默认值为None,表示节点在pg_dist_node表中的行 ID。
def __init__(self, host: str, port: int, role: str, nodeid: Optional[int] = None) -> None:
"""基于给定的参数创建一个 :class:`PgDistNode` 对象。
:param host: Citus 协调器或工作节点的 "nodename"。
:param port: Citus 协调器或工作节点的 "nodeport"。
:param role: "noderole" 的值。
:param nodeid: "pg_dist_node" 表中的行 ID。
"""
self.host = host
self.port = port
self.role = role
self.nodeid = nodeid
作用:
__init__ 构造函数的具体作用是初始化一个 PgDistNode 对象,并设置其属性。这个构造函数接收节点的主机名、端口号、角色以及可选的行 ID,并将这些值分别赋给对象的相应属性。这样就可以创建一个表示集群中单个节点的 PgDistNode 对象,并且可以方便地访问节点的相关信息。
- 节点信息初始化:在创建一个
PgDistNode对象时,需要初始化节点的基本信息,如主机名、端口、角色等。 - 集群管理:在管理分布式数据库集群时,可以使用这个构造函数来创建表示集群中各个节点的
PgDistNode对象。 - 状态跟踪:在跟踪集群中节点的状态变化时,可以通过创建
PgDistNode对象来记录节点的信息。
2.1.2.1.2 __hash__()
- 定义了一个名为
__hash__的方法,它没有参数,并且返回类型为int。
def __hash__(self) -> int:
"""定义一个哈希函数,以便将 :class:`PgDistNode` 对象放入类似于集合的 :class:`PgDistGroup` 对象中。
.. note::
我们在这里使用 (:attr:`host`, :attr:`port`) 元组,因为这是 "pg_dist_node" 表上的唯一约束之一。
:attr:`role` 值在这里无关紧要,因为节点可能会更改其角色。
"""
return hash((self.host, self.port))
作用:
__hash__ 方法的具体作用是定义一个哈希函数,该函数能够为 PgDistNode 对象生成一个唯一的哈希码。这个哈希码用于支持 PgDistNode 对象在类似于集合的数据结构(如 set 或 PgDistGroup)中的唯一性检查。通过这个哈希函数,可以保证即使两个 PgDistNode 对象的角色不同,只要它们具有相同的主机名和端口号,就会被认为是同一个节点的实例,从而可以在集合中唯一存在。
2.1.2.1.3 __eq__()
- 定义了一个名为
__eq__的方法,它接收一个参数other,并且返回类型为bool。other: 类型为Any的参数,表示另一个对象,该对象将与当前PgDistNode实例进行比较。
def __eq__(self, other: Any) -> bool:
"""定义一个比较函数。
:returns: 如果两个实例之间的 :attr:`host` 和 :attr:`port` 相同,则返回 ``True``。
"""
return isinstance(other, PgDistNode) and self.host == other.host and self.port == other.port
作用:
__eq__ 方法的具体作用是定义一个比较函数,该函数用于判断两个 PgDistNode 实例是否相等。在本方法中,两个实例被认为相等的标准是它们的 host 和 port 属性必须完全相同。这个方法使得 PgDistNode 实例可以在集合(如 set)中使用,因为在集合中要求元素是唯一的,而 __eq__ 方法正是用来判断两个元素是否相等的关键。
2.1.2.1.4 __str__()
- 定义了一个名为
__str__的方法,它没有参数,并且返回类型为str。
def __str__(self) -> str:
return ('PgDistNode(nodeid={0},host={1},port={2},role={3})'
.format(self.nodeid, self.host, self.port, self.role))
作用:
__str__ 方法的具体作用是定义一个字符串表示形式,该表示形式用于以易读的方式展示 PgDistNode 对象的所有关键属性。当需要将 PgDistNode 对象转换为字符串时,例如在调试或者日志记录时,会调用这个方法。返回的字符串包括了节点的 nodeid、host、port 和 role 这些属性的值,使得开发人员和其他用户能够清晰地了解节点的状态。
2.1.2.1.5 __repr__()
- 定义了一个名为
__repr__的方法,它没有参数,并且返回类型为str。
def __repr__(self) -> str:
return str(self)
作用:
__repr__ 方法的具体作用是定义一个“官方”字符串表示形式,这个表示形式通常是为了解释器或开发人员而设计的,用于提供尽可能准确的字符串表示,以便在调试时能更好地理解对象的状态。在 Python 中,__repr__ 方法的返回值应当是一个字符串,该字符串应该能够用来重新创建这个对象。
2.1.2.1.6 is_primary()
- 定义了一个名为
is_primary的方法,它没有参数,并且返回类型为bool。
def is_primary(self) -> bool:
"""检查此对象是否代表了对应组中的 "primary"。
:returns: 如果此对象代表 "primary",则返回 ``True``。
"""
return self.role in ('primary', 'demoted')
作用:
is_primary 方法的具体作用是判断当前 PgDistNode 对象是否代表的是一个处于 “primary” 状态的节点。虽然 role 可能的值包括 'primary'、'secondary' 和 'demoted',但是在实际的数据库集群中,一个被标记为 'demoted' 的节点在逻辑上仍然被视为 “primary”,只是暂时不能接受新的客户端连接。因此,这个方法考虑到了 demoted 这种特殊情况,将其也视为 “primary”。
2.1.2.1.7 as_tuple()
- 定义了一个名为
as_tuple的方法,它接收一个可选的布尔参数include_nodeid,默认值为False,并且返回类型为一个元组Tuple[str, int, str, Optional[int]]。
def as_tuple(self, include_nodeid: bool = False) -> Tuple[str, int, str, Optional[int]]:
"""辅助方法,用于比较两个 :class:`PgDistGroup` 对象。
.. note::
*include_nodeid* 在单元测试中被设置为 ``True``。
:param include_nodeid: 在执行比较时是否应考虑 :attr:`nodeid`。
:returns: 包含 :attr:`host`, :attr:`port`, :attr:`role`,以及可选的 :attr:`nodeid` 的 :class:`tuple` 对象。
"""
return self.host, self.port, self.role, (self.nodeid if include_nodeid else None)
作用:
as_tuple 方法的具体作用是提供一个包含 PgDistNode 对象关键属性的元组,这个元组可以用来方便地进行对象之间的比较,尤其是在需要比较两个 PgDistGroup 对象的情况下。通过这个方法,可以根据需要选择是否包含 nodeid 属性来进行比较。通常情况下,nodeid 可能不会影响两个节点是否被认为是相同的节点,但在某些特定场景下(如单元测试),可能需要考虑 nodeid 的影响。
2.1.2.2 类:PgDistGroup
- 定义了一个名为
PgDistGroup的类,它继承自Set[PgDistNode]。这意味着PgDistGroup将是一个类似于集合的对象,其元素类型为PgDistNode。
class PgDistGroup(Set[PgDistNode]):
"""一个类似于 :class:`set` 的对象,代表 "pg_dist_node" 表中的一个 Citus 组。
此类实现了用于比较拓扑的方法,并在必要时以“安全”的方式从旧拓扑过渡到新拓扑:
* 注册新的主节点/从节点
* 替换消失的从节点为新增加的从节点
* 故障转移(failover)和切换(switchover)
通常至少会注册一个 :class:`PgDistNode` 对象(``primary``)。
除此之外,可能还有一个或多个 ``secondary`` 节点。
:ivar failover: 是否应在 :func:`transition` 方法调用后更新 ``primary`` 行。
:ivar groupid: 来自 "pg_dist_node" 的 "groupid"。
"""
PgDistGroup 类的具体作用是提供一种管理 Citus 分布式数据库中节点组的方法。它不仅是一个类似于集合的对象,可以用来存储 PgDistNode 实例(代表数据库中的各个节点),而且还可以通过一系列方法来管理这些节点的状态,包括注册新的节点、替换丢失的节点以及处理故障转移和切换等操作。这些功能对于保持分布式数据库系统的稳定性和可用性至关重要。
2.1.2.2.1 __init__()
-
定义了一个构造函数
__init__,它接收两个参数:groupid: 类型为int的参数,表示来自 “pg_dist_node” 表的groupid。nodes: 类型为Optional[Collection[PgDistNode]]的参数,默认值为None,表示属于某个groupid的PgDistNode对象集合。
构造函数的返回类型为
None。
def __init__(self, groupid: int, nodes: Optional[Collection[PgDistNode]] = None) -> None:
"""根据给定的参数创建一个 :class:`PgDistGroup` 对象。
:param groupid: 来自 "pg_dist_node" 的 `groupid`。
:param nodes: 属于某个 *groupid* 的 :class:`PgDistNode` 对象集合。
"""
self.failover = False
self.groupid = groupid
if nodes:
self.update(nodes)
作用:
__init__ 方法的具体作用是初始化一个 PgDistGroup 对象,并根据传入的参数设置其初始状态。构造函数接收一个 groupid 并可选地接收一个 PgDistNode 对象的集合。如果提供了 nodes 参数,则会将这些节点添加到当前 PgDistGroup 对象中。构造函数还初始化了 failover 属性为 False,意味着在创建对象时,默认情况下不需要进行故障转移。
2.1.2.2.2 equals()
-
定义了一个名为
equals的方法,它接收两个参数:other: 类型为PgDistGroup的对象,表示要与当前对象进行比较的另一个对象。check_nodeid: 类型为bool的参数,默认值为False,表示在比较时是否要同时考虑PgDistNode.nodeid属性。
该方法返回类型为
bool的结果。
def equals(self, other: 'PgDistGroup', check_nodeid: bool = False) -> bool:
"""比较两个 :class:`PgDistGroup` 对象。
:param other: 要与之进行比较的对象。
:param check_nodeid: 是否除了比较 :attr:`PgDistNode.host`、:attr:`PgDistNode.port` 和 :attr:`PgDistNode.role` 外,还要比较 :attr:`PgDistNode.nodeid`。
:returns: 如果两个 :class:`PgDistGroup` 对象完全相同,则返回 ``True``。
"""
return self.groupid == other.groupid\
and set(v.as_tuple(check_nodeid) for v in self) == set(v.as_tuple(check_nodeid) for v in other)
作用:
equals 方法的具体作用是比较两个 PgDistGroup 对象是否完全相同。这个方法首先比较两个对象的 groupid 是否一致,然后通过调用每个 PgDistNode 对象的 as_tuple 方法来生成一个元组表示,并根据 check_nodeid 参数决定是否包含 nodeid 属性。如果 groupid 相同并且两个对象包含的 PgDistNode 对象的元组表示也完全相同(即使不考虑 nodeid 属性),那么这两个 PgDistGroup 对象就被认为是完全相同的。
2.1.2.2.3 primary()
- 定义了一个名为
primary的方法,它没有参数,并且返回类型为Optional[PgDistNode],表示返回值可能是PgDistNode对象,也可能为None。
def primary(self) -> Optional[PgDistNode]:
"""查找并返回代表 "primary" 的 :class:`PgDistNode` 对象。
:returns: 代表 "primary" 的 :class:`PgDistNode` 对象,如果没有找到则返回 ``None``。
"""
return next(iter(v for v in self if v.is_primary()), None)
作用:
primary 方法的具体作用是在当前 PgDistGroup 对象中查找并返回代表 “primary” 节点的 PgDistNode 对象。如果没有找到任何 “primary” 节点,则返回 None。
2.1.2.2.4 get()
- 定义了一个名为
get的方法,它接收一个类型为PgDistNode的参数value,并返回类型为Optional[PgDistNode]的结果。
def get(self, value: PgDistNode) -> Optional[PgDistNode]:
"""在集合中执行查找实际值的操作。
.. note::
这是必要的,因为 :class:`PgDistNode` 中的 :func:`__hash__` 和 :func:`__eq__` 方法已被重定义,
实际上它们只检查 :attr:`PgDistNode.host` 和 :attr:`PgDistNode.port` 属性。
:param value: 我们要查找的键。
:returns: 从这个 :class:`PgDistGroup` 对象中查找的实际 :class:`PgDistNode` 值,如果没有找到则返回 ``None``。
"""
return next(iter(v for v in self if v == value), None)
作用:
get 方法的具体作用是在当前 PgDistGroup 对象中查找与给定 PgDistNode 对象相等的实际 PgDistNode 对象。由于 PgDistNode 类的 __hash__ 和 __eq__ 方法可能只基于 host 和 port 属性进行比较,因此 get 方法可以确保即使在 PgDistNode 对象的其他属性(如 nodeid)不同的情况下,也能找到具有相同 host 和 port 的实际节点。如果没有找到这样的节点,则返回 None。
2.1.2.2.5 transition()
- 定义了一个名为
transition的方法,它接收一个类型为PgDistGroup的参数old,并返回一个Iterator[PgDistNode]。
def transition(self, old: 'PgDistGroup') -> Iterator[PgDistNode]:
"""比较当前拓扑结构与旧拓扑结构,并产生转换以将旧拓扑结构转变为新拓扑结构。
.. note::
实际产生的对象是 :class:`PgDistNode`,它将传递给 :meth:`CitusHandler.update_node` 以在一个事务中执行所有转换。
除了产生事务之外,此方法还会填充在旧拓扑结构和新拓扑结构中都存在的节点的 :attr:`PgDistNode.nodeid` 属性。
Citus 强加了一些简单的规则/约束,必须遵循:
- 只有当元数据同步到所有已注册的 "优先级" 时,才能添加/删除节点。
- "pg_dist_node" 表中的 "primary" 行始终保留 nodeid(除非它被删除,但 Patroni 不支持此操作)。
- "nodename" 和 "nodeport" 在 "pg_dist_node" 表的所有行中必须唯一。这意味着每次想要更改现有节点的 nodeid(例如,将其从 secondary 更改为 primary)时,我们应该先写入一些其他的 "nodename"/"nodeport" 到当前行。
- 更新 "broken" 节点总是有效,并且元数据会在提交后异步同步。
遵循这些规则,下面是 node1(primary,nodeid=4)和 node2(secondary,nodeid=5)之间切换的一个例子。
.. code-block:: SQL
BEGIN;
SELECT citus_update_node(4, 'node1-demoted', 5432);
SELECT citus_update_node(5, 'node1', 5432);
SELECT citus_update_node(4, 'node2', 5432);
COMMIT;
:param old: 给定 :attr:`groupid` 的 "pg_dist_node" 中注册的最后一个已知拓扑结构。
:yields: 必须在 "pg_dist_node" 中更新/添加/删除的 :class:`PgDistNode` 对象。
"""
# 将 old 对象的 failover 属性赋值给当前对象的 failover 属性
self.failover = old.failover
# 获取当前对象中的 primary 节点,并断言它不是 None;获取旧对象中的 primary 节点
new_primary = self.primary()
assert new_primary is not None
old_primary = old.primary()
# 计算已经消失的节点
gone_nodes = old - self - {old_primary}
# 计算新增的节点
added_nodes = self - old - {new_primary}
# 如果旧拓扑中没有 primary 节点
if not old_primary:
# 我们在组中还没有任何节点,现在我们要添加一个
yield new_primary
# 如果旧拓扑和新拓扑中的 primary 是同一个节点
elif old_primary == new_primary:
new_primary.nodeid = old_primary.nodeid
# 通过暂停客户端连接来控制切换。
# 通过更新主行并在事务中添加hostname = '${host}-demoted'来实现。
if old_primary.role != new_primary.role:
self.failover = True
yield new_primary
# 如果旧拓扑和新拓扑中的 primary 不是同一个节点
elif old_primary != new_primary:
self.failover = True
new_primary_old_node = old.get(new_primary)
old_primary_new_node = self.get(old_primary)
# 在故障转移之前,已将新的主服务器注册为辅助服务器
if new_primary_old_node:
new_node = None
# 旧的主服务器已经消失,并且添加了一些新的辅助服务器。
# 我们可以使用升级后的备份行添加新的备份。
if not old_primary_new_node and added_nodes:
new_node = added_nodes.pop()
new_node.nodeid = new_primary_old_node.nodeid
yield new_node
# 通知_maybe_register_old_primary_as_secondary不应该重新注册旧的主服务器
old_primary.role = 'secondary'
# 在相反的情况下,我们需要将主记录更改为“${host}-demoted:${port}”。
# 之前我们可以把它的host:port放到提升的secondary行。
elif old_primary.role == 'primary':
old_primary.role = 'demoted'
yield old_primary
# 旧的主行已经消失,提升的辅助行还没有被使用。
if not old_primary_new_node and not new_node:
# 我们必须“添加”消失的主要到提升的次要行,
# 因为元数据未同步时,无法删除nodes。
old_primary_new_node = PgDistNode(old_primary.host, old_primary.port, new_primary_old_node.role)
self.add(old_primary_new_node)
# 用旧的初级而不是升级的次级
if old_primary_new_node:
old_primary_new_node.nodeid = new_primary_old_node.nodeid
yield old_primary_new_node
# 用新信息更新主记录
new_primary.nodeid = old_primary.nodeid
yield new_primary
# 新的主服务器从未注册为备用服务器,并且有备用服务器已经消失。
# 自当元数据没有同步时,nodes不能被删除,我们必须暂时“添加”回旧的主节点。
if not new_primary_old_node and gone_nodes:
# 当主服务器消失时,我们正在进行受控切换。
# 如果有任何已经消失的节点不能用于新的次要节点,我们将会重新使用
# 使用其中一个临时“添加”旧的主服务器作为辅助服务器。
if not old_primary_new_node and old_primary.role == 'demoted' and len(gone_nodes) > len(added_nodes):
old_primary_new_node = PgDistNode(old_primary.host, old_primary.port, 'secondary')
self.add(old_primary_new_node)
# 使用一个消失的次要服务器将旧主服务器的host:port放在那里。
if old_primary_new_node:
old_primary_new_node.nodeid = gone_nodes.pop().nodeid
yield old_primary_new_node
# 从旧拓扑中填充新拓扑中的备用节点id
# 填充新拓扑结构中 standby 节点的 nodeid 属性,从旧拓扑结构中获取
old_replicas = {v: v for v in old if not v.is_primary()}
for n in self:
if not n.is_primary() and not n.nodeid and n in old_replicas:
n.nodeid = old_replicas[n].nodeid
# 重用已用备用节点的节点来“添加”新的备用节点
# 重用消失的 standby 节点的 nodeid 来“添加”新的 standby 节点,并产生相应的 PgDistNode 对象
while gone_nodes and added_nodes:
a = added_nodes.pop()
a.nodeid = gone_nodes.pop().nodeid
yield a
# 添加或删除节点的操作在所有Citus组的主节点上执行。
# 如果我们知道主服务器被更新了(self。故障转移为True),这自动意味着
# 添加/删除节点调用将失败,整个事务将中止。因此
# 如果我们知道主服务器刚刚更新,我们将放弃添加/删除备用服务器的操作。
# 不一致将自动解决下一个Patroni心跳循环。
# 删除已删除的剩余节点,但仅在元数据同步的情况下(self。failover为False)。
for g in gone_nodes:
if not self.failover:
# 如果我们期望元数据同步,则删除节点
yield PgDistNode(g.host, g.port, '')
else:
# 否则,将这些节点添加到新拓扑中
self.add(g)
# 向元数据添加新节点,但仅在元数据同步(self。failover为False)。
# 在元数据同步的情况下(self.failover 为 False)向元数据中添加新节点,并产生相应的 PgDistNode 对象
for a in added_nodes:
if not self.failover:
# 如果我们希望元数据同步,则添加节点
yield a
else:
# 否则将它们从新拓扑中移除
self.discard(a)
- 将 old 对象的 failover 属性赋值给当前对象的 failover 属性。
- 获取当前对象中的 primary 节点,并断言它不是 None;再获取旧对象中的 primary 节点(调用
primary函数)。 - 计算已经消失的节点。
- 计算新增的节点。
- 如果旧拓扑中没有 primary 节点:
- 在组中还没有任何节点,现在要添加一个(返回当前对象的primary节点)。
- 如果旧拓扑和新拓扑中的 primary 是同一个节点:
- 更新其 nodeid 属性。如果角色发生变化,则标记为 failover 并产生主节点的 PgDistNode 对象。
- 如果旧拓扑和新拓扑中的 primary 不是同一个节点,则标记为 failover,并根据不同情况产生相应的 PgDistNode 对象:
- 旧的主服务器已经消失,并且添加了一些新的辅助服务器,可以使用升级后的备份行添加新的备份并且通知_maybe_register_old_primary_as_secondary 不应该重新注册旧的主服务器。
- 在相反的情况下,我们需要将主记录更改为“${host}-demoted:${port}”,之前我们可以把它的host:port放到提升的secondary行
- 旧的主行已经消失,提升的辅助行还没有被使用,我们必须“添加”消失的主要到提升的次要行,因为元数据未同步时,无法删除 nodes 。
- 用旧的初级而不是升级的次级。
- 用新信息更新主记录。
- 新的主服务器从未注册为备用服务器,并且有备用服务器已经消失,当元数据没有同步时,nodes 不能被删除,我们必须暂时“添加”回旧的主节点。
- 使用其中一个临时“添加”旧的主服务器作为辅助服务器。
- 使用一个消失的次要服务器将旧主服务器的 host:port 放在那里。
- 填充新拓扑结构中 standby 节点的 nodeid 属性,从旧拓扑结构中获取。
- 重用消失的 standby 节点的 nodeid 来“添加”新的 standby 节点,并产生相应的 PgDistNode 对象。
- 处理添加或删除节点的情况,并根据 failover 的状态决定是否产生删除节点的 PgDistNode 对象:
- 如果我们期望元数据同步,则删除节点。
- 否则,将这些节点添加到新拓扑中。
- 处理向元数据中添加新节点的情况,并根据 failover 的状态决定是否产生添加节点的 PgDistNode 对象:
- 如果我们希望元数据同步,则添加节点。
- 否则将它们从新拓扑中移除。
作用:
transition 方法的具体作用是计算当前 PgDistGroup 对象相对于旧的 PgDistGroup 对象的变化,并生成一系列 PgDistNode 对象,这些对象描述了如何从旧拓扑结构过渡到新拓扑结构。生成的 PgDistNode 对象可以用来更新数据库中的 pg_dist_node 表,以反映拓扑结构的变化。
这个方法会根据 Citus 的约束条件进行一系列的检查和调整,包括但不限于:
- 确保元数据同步到所有注册的优先级。
- 保持
primary节点的nodeid。 - 确保
nodename和nodeport在pg_dist_node表中唯一。 - 在事务中更新损坏的节点。
此外,该方法还会填充新旧拓扑结构中都存在的节点的 nodeid 属性,并处理 standby 节点的 nodeid 重用问题。
2.1.2.3 类:PgDistTask
- 定义了一个名为
PgDistTask的类,它是PgDistGroup的子类。
class PgDistTask(PgDistGroup):
"""一个 "任务",代表提供的 *groupid* 在 "pg_dist_node" 中的当前或期望的状态。
:ivar group: "pg_dist_node" 中的 "groupid"。
:ivar event: 导致创建此任务的 "事件"。
可能的值:"before_demote","before_promote","after_promote"。
:ivar timeout: 如果任务导致启动了事务,则是一个事务超时。
:ivar cooldown: 对 ``citus_update_node()`` 内置函数调用的冷却时间。
:ivar deadline: 允许回滚事务的时间(以 Unix 秒为单位)。
"""
PgDistTask 类的作用是表示 pg_dist_node 表中特定 groupid 的当前或期望状态的任务。它扩展了 PgDistGroup 类的功能,增加了与任务相关的属性如 event, timeout, cooldown, deadline 等,这些属性用于记录与任务相关的信息,比如是什么事件触发了这个任务的创建,事务的超时时间,调用特定函数前的冷却时间等。
此类可用于自动化任务处理,特别是在需要根据特定事件来调整集群状态的时候。例如,在节点提升或降级前后可能需要执行某些操作,此时可以创建一个 PgDistTask 对象来管理这些操作,并确保它们在适当的时间内完成。
2.1.2.3.1 __init__()
- 定义了一个名为
__init__的构造函数,它会在创建一个PgDistTask对象时被调用。构造函数接收五个参数:groupid、nodes、event、timeout和cooldown,并返回None。
def __init__(self, groupid: int, nodes: Optional[Collection[PgDistNode]], event: str,
timeout: Optional[float] = None, cooldown: Optional[float] = None) -> None:
"""创建一个 PgDistTask 对象,基于给定的参数。
参数说明:
groupid:来自 "pg_dist_node" 的组 ID。
nodes:属于该 groupid 的一组 PgDistNode 对象的集合。
event:导致创建此任务的“事件”。
timeout:如果任务导致启动一个事务,则为事务超时。
cooldown:用于 citus_update_node() UDF 调用的冷却时间值。
"""
super(PgDistTask, self).__init__(groupid, nodes)
# 正在尝试更改或更改给定行的事件。
# 取值:before_demote, before_promote, after_promote
self.event = event
# 如果事务已经启动,我们需要在截止日期之前COMMIT/ROLLBACK
self.timeout = timeout
self.cooldown = cooldown or 10000 # 10s by default
self.deadline: float = 0
# pg_dist_node中的所有更改都在Patroni上序列化
# side通过在线程中执行它们。就是这条线
#请求一个更改,有时需要等待一个结果。
# 例如,我们想在降级之前暂停客户端连接worker,完成后通知调用线程。
self._event = Event()
作用:
这个构造函数的作用是初始化一个PgDistTask对象,该对象似乎用于处理分布式数据库系统中的某些任务。它接收一组节点和相关的信息,如组ID、事件类型等,并为这些信息创建对应的属性。此外,它还处理事务超时和冷却时间,并设置一个用于线程间同步的事件对象。
2.1.2.3.2 wait()
- 定义了一个名为
wait的方法,它是一个实例方法,没有返回值。
def wait(self) -> None:
"""等待直到该任务被专用线程处理完毕."""
self._event.wait()
作用:
这个wait方法的作用是让调用它的线程等待,直到PgDistTask对象关联的事件被设置。通常用于多线程环境中,当一个线程启动了一个任务处理过程后,可以通过调用wait方法来等待任务完成。只有当任务处理线程完成了任务并且设置了事件标志时,wait方法才会返回,从而允许等待线程继续执行。
2.1.2.3.3 wakeup()
- 定义了一个名为
wakeup的方法,它是一个实例方法,没有返回值。
def wakeup(self) -> None:
"""通知创建任务的线程,任务已被处理。"""
self._event.set()
作用:
这个wakeup方法的作用是通知等待线程,与PgDistTask对象关联的任务已经被处理完毕。通常在一个多线程环境中,当任务处理线程完成了任务处理后,它可以调用wakeup方法来设置事件标志。一旦设置,任何因调用wait方法而阻塞的线程将被解除阻塞,从而可以继续其后续的执行流程。
2.1.2.3.4 __eq__()
- 定义了一个名为
__eq__的特殊方法,它是一个实例方法,接受一个任意类型的对象other作为参数,并返回一个布尔值。
def __eq__(self, other: Any) -> bool:
return isinstance(other, PgDistTask) and self.event == other.event\
and super(PgDistTask, self).equals(other)
作用:
这个__eq__方法的作用是定义如何判断两个PgDistTask对象是否相等。当使用==运算符比较两个PgDistTask对象时,会调用此方法。要使两个对象相等,必须满足以下条件:
other必须是PgDistTask的实例;- 两个对象的
event属性必须相等; - 调用父类的
equals方法来比较其他属性也必须返回True。
需要注意的是,最后一行中的super(PgDistTask, self).equals(other)调用的equals方法并不是Python标准库中的方法,可能是自定义的或者是继承自某个特定父类的方法。如果父类没有提供equals方法,则此代码会导致属性错误(AttributeError)。在这种情况下,你需要确保父类中确实定义了这样的方法,或者修改比较逻辑以适应实际情况。
2.1.2.3.5 __ne__()
- 定义了一个名为
__ne__的特殊方法,它是一个实例方法,接受一个任意类型的对象other作为参数,并返回一个布尔值。
def __ne__(self, other: Any) -> bool:
return not self == other
作用:
这个__ne__方法的作用是定义如何判断两个PgDistTask对象是否不相等。当使用!=运算符比较两个PgDistTask对象时,会调用此方法。该方法通过取反__eq__方法的结果来决定两个对象是否不相等。如果__eq__方法返回True(即对象相等),那么__ne__方法返回False;反之,如果__eq__方法返回False(即对象不相等),那么__ne__方法返回True。
2.1.2.4 类:Citus
- 这一行定义了一个名为
Citus的类,它继承自AbstractMPP类。
class Citus(AbstractMPP):
group_re = re.compile('^(0|[1-9][0-9]*)$')
2.1.2.4.1 validate_config()
- 定义了一个名为
validate_config的静态方法,它接受一个类型为Union[Any, Dict[str, Union[str, int]]]的参数config,并返回一个布尔值。
@staticmethod
def validate_config(config: Union[Any, Dict[str, Union[str, int]]]) -> bool:
"""检查提供的配置是否适用于给定的MPP。
config: citus MPP部分的配置。
返回值:如果配置通过验证则返回True,否则返回False。
"""
return isinstance(config, dict) \
and isinstance(config.get('database'), str) \
and parse_int(config.get('group')) is not None
作用:
这个validate_config静态方法的作用是验证传入的config是否符合预期的格式,以确保它可以正确地用于某个特定的MPP(大规模并行处理)系统,这里是citus。具体来说,该方法检查以下几点:
config是否为字典类型;- 字典中是否有键
'database',并且它的值是否为字符串; - 字典中是否有键
'group',并且它的值是否可以被转换为整数。
如果所有条件都满足,则返回True,表示配置有效;如果有任何条件不满足,则返回False,表示配置无效。这种方法常用于配置文件的验证,确保在程序运行前配置项是正确的,从而避免由于配置错误而导致的问题。
2.1.2.5 类:CitusHandler
- 定义了一个名为
CitusHandler的类,它继承自Citus、AbstractMPPHandler和Thread三个基类。这意味着CitisHandler将会拥有这三个类的所有属性和方法,并且可以作为一个线程来运行。
class CitusHandler(Citus, AbstractMPPHandler, Thread):
"""定义处理底层Citus集群的接口。"""
这个CitusHandler类的作用是定义了一个处理Citus集群的接口或框架。它结合了Citus类、AbstractMPPHandler抽象类以及Thread类的功能。具体来说:
- 继承自
Citus类:意味着CitusHandler将会继承Citus类的所有特性和行为,Citus类很可能是针对Citus数据库集群的一些特定功能和配置的封装。 - 继承自
AbstractMPPHandler类:AbstractMPPHandler可能是一个抽象基类,定义了处理大规模并行处理(MPP)系统的基本方法和行为。CitusHandler需要实现这些抽象方法来完成具体的处理逻辑。 - 继承自
Thread类:使得CitusHandler可以作为一个独立的线程来运行,这意味着它可以并发地执行任务而不阻塞主程序流。这对于需要异步处理数据库集群任务的场景非常有用。
通过组合这些特性,CitusHandler可以作为一个强大的工具来管理Citus集群,同时利用多线程提高处理效率。此类的设计目的是为了提供一种标准化的方式,使得开发人员可以更容易地编写代码来管理和操作Citus集群,同时利用并发执行的能力来优化性能。
2.1.2.5.1 __init__()
def __init__(self, postgresql: 'Postgresql', config: Dict[str, Union[str, int]]) -> None:
""""初始化一个新的CitusHandler实例。
postgresql: PostgreSQL节点。
config: citus MPP配置部分。
"""
# 初始化了线程相关的属性
Thread.__init__(self)
AbstractMPPHandler.__init__(self, postgresql, config)
self.daemon = True
if config:
self._connection = postgresql.connection_pool.get(
'citus', {'dbname': config['database'],
'options': '-c statement_timeout=0 -c idle_in_transaction_session_timeout=0'})
self._pg_dist_group: Dict[int, PgDistTask] = {} # pg_dist_node缓存:{groupid: PgDistTask()}
self._tasks: List[PgDistTask] = [] # 请求修改pg_dist_group,每个任务都是一个‘ PgDistTask ’
self._in_flight: Optional[PgDistTask] = None # 对事务中正在更改的“PgDistTask”的引用
self._schedule_load_pg_dist_group = True # 标记应该从数据库中查询“pg_dist_group”
self._condition = Condition() # 保护_pg_dist_group、_tasks、_in_flight和_schedule_load_pg_dist_group
# 安排缓存重建
self.schedule_cache_rebuild()
作用:
这个构造函数的作用是初始化一个新的CitusHandler实例。它主要负责以下几件事:
- 初始化线程相关的属性;
- 设置守护线程标志;
- 获取数据库连接;
- 初始化与处理Citus集群相关的属性和数据结构;
- 创建一个条件锁对象用于多线程环境下的同步;
- 安排缓存重建。
通过这些步骤,构造函数确保了CitusHandler实例具备了处理与Citus集群相关的任务所需的资源和状态。这使得CitusHandler可以在多线程环境下安全地管理和更新与集群相关的数据。
2.1.2.5.2 schedule_cache_rebuild()
- 定义了一个名为
schedule_cache_rebuild的方法,它是一个实例方法,没有返回值。
def schedule_cache_rebuild(self) -> None:
"""缓存重建处理器。
被调用以通知处理器需要从数据库刷新其元数据缓存。
"""
with self._condition:
self._schedule_load_pg_dist_group = True
作用:
这个schedule_cache_rebuild方法的作用是调度缓存的重建。具体来说:
- 设置标志:该方法将
_schedule_load_pg_dist_group标志设置为True,表示需要从数据库重新加载元数据缓存。这意味着当调用该方法时,它告诉CitusHandler实例需要更新其内部的缓存信息。 - 保证线程安全:通过使用
with self._condition来确保对_schedule_load_pg_dist_group标志的修改是在一个互斥的上下文中进行的。这意味着如果有多个线程试图同时修改这个标志,只有一个线程能进入这个上下文,其他线程需要等待当前线程完成修改并释放锁之后才能进入。
通过这种方式,schedule_cache_rebuild方法确保了:
- 在需要的时候可以及时触发缓存的刷新;
- 在多线程环境中对共享资源(如标志)的访问是线程安全的;
- 当缓存需要更新时,能够有效地通知处理逻辑去执行相应的操作。
2.1.2.5.3 on_demote()
- 定义了一个名为
on_demote的方法,它是一个实例方法,没有返回值。
def on_demote(self) -> None:
with self._condition:
self._pg_dist_group.clear()
empty_tasks: List[PgDistTask] = []
self._tasks[:] = empty_tasks
self._in_flight = None
作用:
这个on_demote方法的作用是在接收到节点降级(demotion)的通知时,清理与当前节点相关的所有任务和缓存信息。具体来说:
- 清理缓存:清空
_pg_dist_group字典,该字典用于缓存pg_dist_node的相关信息。这意味着所有与节点相关的缓存数据都被清除,以反映节点状态的变化。 - 清空任务队列:将
self._tasks列表清空,表示不再有任何待处理的任务。这是因为节点降级后,之前的任务可能不再适用或需要重新评估。 - 设置事务状态:将
self._in_flight设置为None,表示当前没有正在进行的事务处理任务。这是因为节点降级后,任何未完成的事务都需要被取消或重新处理。
通过这种方式,on_demote方法确保了:
- 在节点降级时,与当前节点相关的所有任务和缓存信息都被清理干净;
- 在多线程环境中对共享资源(如缓存字典和任务列表)的访问是线程安全的;
- 节点状态变化后,能够及时清理旧的状态信息,防止旧状态影响新的操作。
2.1.2.5.4 query()
- 定义了一个名为
query的方法,它是一个实例方法,接受一个SQL字符串sql和可变数量的参数params,返回一个包含多个元组的列表,每个元组代表查询结果中的一行。
def query(self, sql: str, *params: Any) -> List[Tuple[Any, ...]]:
# 捕获执行SQL查询过程中可能出现的异常
try:
logger.debug('query(%s, %s)', sql, params)
# 调用self._connection对象的query方法,执行SQL查询,并传递参数。返回查询结果
return self._connection.query(sql, *params)
except Exception as e:
logger.error('Exception when executing query "%s", (%s): %r', sql, params, e)
# 关闭了数据库连接,以防异常导致连接处于不稳定状态
self._connection.close()
# 表示当前没有正在进行的事务处理任务
with self._condition:
self._in_flight = None
# 调用schedule_cache_rebuild方法,安排缓存的重建。这意味着在发生异常后,需要重新加载元数据缓存
self.schedule_cache_rebuild()
raise e
作用:
这个query方法的作用是在CitusHandler类中执行SQL查询,并处理可能发生的异常。具体来说:
- 执行SQL查询:使用
self._connection连接执行给定的SQL语句和参数,并返回查询结果。 - 异常处理:
- 记录执行查询时出现的异常,并关闭数据库连接。
- 清除正在进行的任务标志
_in_flight,以确保状态的一致性。 - 安排缓存重建,以便在异常恢复后重新加载元数据。
- 重新抛出异常:确保异常不会被静默忽略,并传递给调用者进行进一步处理。
通过这种方式,query方法不仅执行了SQL查询,还提供了异常处理机制,确保了在查询失败时系统的稳定性和一致性。
2.1.2.5.5 load_pg_dist_group()
- 定义了一个名为
load_pg_dist_group的方法,它是一个实例方法,返回一个布尔值。
def load_pg_dist_group(self) -> bool:
"""从pg_dist_node表中读取数据并放入本地缓存。"""
# 创建了一个上下文管理器
with self._condition:
if not self._schedule_load_pg_dist_group:
return True
# 表示本次加载操作之后,不需要再次加载数据
self._schedule_load_pg_dist_group = False
# 尝试执行SQL查询,从pg_dist_node表中获取所有节点的信息。查询结果存储在rows变量中
try:
rows = self.query('SELECT groupid, nodename, nodeport, noderole, nodeid FROM pg_catalog.pg_dist_node')
except Exception:
return False
pg_dist_group: Dict[int, PgDistTask] = {}
# 开始遍历查询结果中的每一行
for row in rows:
# 检查当前行的groupid是否已经在pg_dist_group字典中存在
if row[0] not in pg_dist_group:
# 这一行将当前行的节点信息添加到对应的PgDistTask对象中
pg_dist_group[row[0]] = PgDistTask(row[0], nodes=set(), event='after_promote')
pg_dist_group[row[0]].add(PgDistNode(*row[1:]))
# 再次使用with语句和self._condition对象创建了一个上下文管理器,确保对_pg_dist_group的修改是在一个原子操作中完成的
with self._condition:
self._pg_dist_group = pg_dist_group
return True
- 创建了一个上下文管理器,实现原子化操作。
- 修改属性 _schedule_load_pg_dist_group 为 false,表示本次加载操作之后,不需要再次加载数据。
- 尝试执行SQL查询,从pg_dist_node表中获取所有节点的信息。
- 开始遍历查询结果中的每一行:
- 检查当前行的groupid是否已经在pg_dist_group字典中存在。
- 这一行将当前行的节点信息添加到对应的PgDistTask对象中。
- 检查当前行的groupid是否已经在pg_dist_group字典中存在。
- 再次使用with语句和self._condition对象创建了一个上下文管理器,确保对_pg_dist_group的修改是在一个原子操作中完成的。
sync_meta_data函数:在每次心跳循环中,同步集群中的元数据信息,确保本地缓存中的pg_dist_node信息与集群视图保持一致。
- 检查当前节点是否是协调器节点。
- 使用with语句和self._condition对象创建了一个上下文管理器,确保对线程状态的修改是在一个原子操作中完成的。
- 调用add_task方法,向任务列表中添加一个任务,用于同步协调器节点的信息。
- 开始遍历cluster对象中的所有工作节点:
- 获取当前工作节点的领导者信息。
- 检查领导者是否有效,并且其连接URL不为空,以及领导者角色为master或primary,并且状态为running。
- 调用add_task方法,向任务列表中添加一个任务,用于同步当前工作节点的领导者信息。
作用:
这个load_pg_dist_group方法的作用是从数据库的pg_dist_node表中读取节点信息,并将这些信息放入本地缓存中。具体来说:
- 检查加载标志:首先检查
_schedule_load_pg_dist_group标志,确定是否需要加载数据。如果不需要加载,则直接返回True。 - 执行SQL查询:如果需要加载数据,则执行SQL查询,从
pg_dist_node表中获取所有节点的信息。 - 处理查询结果:遍历查询结果中的每一行,构建
pg_dist_group字典,将每个组ID对应的所有节点信息存储在PgDistTask对象中。 - 更新本地缓存:将构建好的
pg_dist_group字典赋值给_pg_dist_group,更新本地缓存。 - 返回结果:如果加载成功,返回
True;如果加载过程中发生异常,返回False。
通过这种方式,load_pg_dist_group方法确保了:
- 在需要时从数据库加载最新的节点信息;
- 将加载的信息存储在本地缓存中,供后续操作使用;
- 在多线程环境中对共享资源的访问是线程安全的。
2.1.2.5.6 sync_meta_data()
- 定义了一个名为
sync_meta_data的方法,它是一个实例方法,接受一个Cluster类型的对象cluster作为参数,并且没有返回值。
def sync_meta_data(self, cluster: Cluster) -> None:
"""在每次心跳循环中维护来自协调器领导者的pg_dist_node。
我们不能总是依赖来自工作节点的REST API调用来维护pg_dist_node,因此至少在每次心跳循环中,我们确保注册在self._pg_dist_group缓存中的工作者与DCS中的集群视图一致,通过创建任务的方式如同从REST API中所做的那样。"""
# 检查当前节点是否是协调器节点
if not self.is_coordinator():
return
# 使用with语句和self._condition对象创建了一个上下文管理器,确保对线程状态的修改是在一个原子操作中完成的
with self._condition:
if not self.is_alive():
self.start()
# 调用add_task方法,向任务列表中添加一个任务,用于同步协调器节点的信息
self.add_task('after_promote', CITUS_COORDINATOR_GROUP_ID, cluster,
self._postgresql.name, self._postgresql.connection_string)
# 开始遍历cluster对象中的所有工作节点
for groupid, worker in cluster.workers.items():
# 获取当前工作节点的领导者信息
leader = worker.leader
# 检查领导者是否有效,并且其连接URL不为空,以及领导者角色为master或primary,并且状态为running
if leader and leader.conn_url\
and leader.data.get('role') in ('master', 'primary') and leader.data.get('state') == 'running':
# 调用add_task方法,向任务列表中添加一个任务,用于同步当前工作节点的领导者信息
self.add_task('after_promote', groupid, worker, leader.name, leader.conn_url)
作用:
这个sync_meta_data方法的作用是在每次心跳循环中,同步集群中的元数据信息,确保本地缓存中的pg_dist_node信息与集群视图保持一致。具体来说:
-
检查协调器身份:首先检查当前节点是否是协调器节点。如果不是协调器,则不执行同步操作。
-
启动线程:如果线程尚未运行,则启动线程。
-
同步协调器信息:向任务列表中添加一个任务,用于同步协调器节点的信息。
-
遍历工作节点:遍历集群中的所有工作节点,对于每个工作节点:
- 检查其领导者是否有效且状态正确;
- 向任务列表中添加一个任务,用于同步当前工作节点的领导者信息。
通过这种方式,sync_meta_data方法确保了:
- 协调器节点定期同步其缓存中的
pg_dist_node信息; - 工作节点的领导者信息被正确同步;
- 在多线程环境中对共享资源的访问是线程安全的;
- 即使工作节点无法通过REST API报告其状态,协调器节点也能确保集群视图的一致性。
2.1.2.5.7 find_task_by_groupid()
- 定义了一个名为
find_task_by_groupid的方法,它是一个实例方法,接受一个整数groupid作为参数,并返回一个可选的整数(Optional[int]),表示找到的任务在任务列表中的索引位置,如果没有找到则返回None。
def find_task_by_groupid(self, groupid: int) -> Optional[int]:
# 使用enumerate函数遍历self._tasks列表。enumerate函数返回一个迭代器,其中每个元素是一个元组,包含当前元素的索引和值
for i, task in enumerate(self._tasks):
if task.groupid == groupid:
return i
作用:
这个find_task_by_groupid方法的作用是在任务列表中查找具有指定groupid的任务,并返回该任务的索引位置。具体来说:
- 遍历任务列表:使用
enumerate遍历self._tasks列表中的每个任务,并获取任务的索引和实际任务对象。 - 查找任务:检查每个任务的
groupid属性是否与传入的groupid相等。 - 返回索引:如果找到匹配的任务,则返回该任务在任务列表中的索引位置。
如果在整个任务列表中都没有找到匹配的任务,该方法将返回None。
2.1.2.5.8 pick_task()
-
定义了一个名为
pick_task的方法,它是一个实例方法,返回一个元组,包含一个可选的整数(任务索引)和一个可选的PgDistTask对象。def pick_task(self) -> Tuple[Optional[int], Optional[PgDistTask]]: """返回一个元组(i, task),其中i是任务在self._tasks列表中的索引。 选择任务的优先级顺序如下: 1.如果已经有事务在进行中,选择一个将改变已经受影响的工作节点主节点的任务。 2.如果需要更改协调器地址,则选择一个组ID为0的任务(协调器总是在组ID 0中)。 3.选择最老的任务(即self._tasks列表中的第一个任务)。 """ with self._condition: if self._in_flight: i = self.find_task_by_groupid(self._in_flight.groupid) else: while True: i = self.find_task_by_groupid(CITUS_COORDINATOR_GROUP_ID) # set_coordinator if i is None and self._tasks: i = 0 if i is None: break task = self._tasks[i] # 检查当前任务是否与缓存版本的pg_dist_group匹配 if task == self._pg_dist_group.get(task.groupid): self._tasks.pop(i) # 没什么可做的,因为pg_dist_group的缓存版本已经匹配了 else: break # 根据i是否为None来确定task的值 task = self._tasks[i] if i is not None else None # 返回一个元组,包含任务索引i和任务对象task return i, task
作用:
这个pick_task方法的作用是在任务列表中选择一个任务,并返回该任务的索引及其本身。具体来说:
- 检查事务状态:首先检查是否有事务正在进行中。如果有,则选择一个将改变已经受影响的工作节点主节点的任务。
- 选择协调器任务:如果没有事务在进行中,但需要更改协调器地址,则选择组ID为0的任务。
- 选择最老的任务:如果以上两种情况都不满足,则选择最老的任务(即
self._tasks列表中的第一个任务)。 - 处理匹配情况:如果找到的任务与缓存版本的
pg_dist_group匹配,则从任务列表中移除此任务。 - 返回结果:最终返回一个元组,包含任务的索引和任务对象。
通过这种方式,pick_task方法确保了:
- 根据优先级选择合适的任务进行处理;
- 处理过程中对共享资源的访问是线程安全的;
- 移除已匹配的任务,避免重复处理。
2.1.2.5.9 update_node()
- 定义了一个名为
update_node的方法,它是一个实例方法,接受一个整数groupid、一个PgDistNode类型的对象node以及一个可选的浮点数cooldown(默认值为10000),并且没有返回值。
def update_node(self, groupid: int, node: PgDistNode, cooldown: float = 10000) -> None:
# 检查node的角色是否不在'primary'、'secondary'或'demoted'这几个选项之中
if node.role not in ('primary', 'secondary', 'demoted'):
# 如果node的角色不属于上述三种之一,则执行SQL命令来移除节点,参数为节点的主机名和端口号
self.query('SELECT pg_catalog.citus_remove_node(%s, %s)', node.host, node.port)
# 检查node是否已经有了一个nodeid(节点ID)
elif node.nodeid is not None:
# 根据node的角色决定是否在主机名后面加上'-demoted'标记
host = node.host + ('-demoted' if node.role == 'demoted' else '')
# 执行SQL命令来更新节点的信息,参数为节点ID、主机名、端口和冷却时间(cooldown)
self.query('SELECT pg_catalog.citus_update_node(%s, %s, %s, true, %s)',
node.nodeid, host, node.port, cooldown)
# 检查node的角色是否不是'demoted'
elif node.role != 'demoted':
# 如果node的角色不是'demoted',则执行SQL命令来添加节点,并且将返回的节点ID赋值给node.nodeid
node.nodeid = self.query("SELECT pg_catalog.citus_add_node(%s, %s, %s, %s, 'default')",
node.host, node.port, groupid, node.role)[0][0]
作用:
这个update_node方法的作用是在Citus集群中更新或添加节点,并处理节点的移除。具体来说:
- 检查节点角色:
- 如果节点的角色不是
'primary'、'secondary'或'demoted',则执行移除节点的操作。 - 如果节点已经有
nodeid,则根据节点的角色更新节点信息。 - 如果节点的角色不是
'demoted',则执行添加节点的操作。
- 如果节点的角色不是
- 执行相应的SQL命令:
- 移除节点:如果节点的角色不是常见的几种角色,则调用
citus_remove_node函数来移除节点。 - 更新节点:如果节点有
nodeid,则调用citus_update_node函数来更新节点信息,并传入冷却时间参数。 - 添加节点:如果节点的角色不是
'demoted',则调用citus_add_node函数来添加节点,并获取新节点的ID。
- 移除节点:如果节点的角色不是常见的几种角色,则调用
通过这种方式,update_node方法确保了:
- 根据节点的不同状态执行适当的集群管理操作(添加、更新或移除);
- 使用SQL函数来与Citus集群交互,确保集群的状态与本地缓存保持一致;
- 对节点状态进行适当的处理,确保集群的健康运行。
2.1.2.5.10 update_group()
- 定义了一个名为
update_group的方法,它是一个实例方法,接受一个PgDistTask类型的对象task和一个布尔值transaction作为参数,并且没有返回值。
def update_group(self, task: PgDistTask, transaction: bool) -> None:
# 获取当前组的状态
current_state = self._in_flight\
or self._pg_dist_group.get(task.groupid)\
or PgDistTask(task.groupid, set(), 'after_promote')
# 获取需要转换的状态列表,并将其转换为一个列表
transitions = list(task.transition(current_state))
# 是否有需要执行的状态转换
if transitions:
# 如果transaction为False且需要执行的状态转换超过一个,则开始一个新的事务
if not transaction and len(transitions) > 1:
self.query('BEGIN')
# 这一行遍历所有的状态转换,并调用update_node方法来更新每个节点的状态
for node in transitions:
self.update_node(task.groupid, node, task.cooldown)
# 如果transaction为False且需要执行的状态转换超过一个,则在所有节点更新完成后提交事务,并将failover标志设置为False
if not transaction and len(transitions) > 1:
task.failover = False
self.query('COMMIT')
作用:
这个update_group方法的作用是在Citus集群中更新指定组内的节点状态。具体来说:
- 获取当前组状态:根据当前事务状态或者缓存中的状态获取当前组的状态。
- 计算状态转换:通过调用
task对象的transition方法来计算需要执行的状态转换。 - 执行状态转换:
- 如果需要执行的状态转换多于一个,并且事务模式未启用(
transaction为False),则开始一个新的事务。 - 遍历所有需要的状态转换,并调用
update_node方法来更新每个节点的状态。 - 如果需要执行的状态转换多于一个,并且事务模式未启用(
transaction为False),则在所有节点更新完成后提交事务,并将failover标志设置为False。
- 如果需要执行的状态转换多于一个,并且事务模式未启用(
通过这种方式,update_group方法确保了:
- 在更新组内节点状态时,根据当前的状态和任务需求执行正确的状态转换。
- 支持批量操作的事务管理,如果有多于一个的状态转换需要执行,并且事务模式未启用,则会自动开启并提交事务。
- 更新节点状态时,使用
update_node方法来确保与Citus集群的交互正确无误。
这种方法可以有效地管理Citus集群中的节点状态变更,并且通过事务控制来保证批量操作的一致性和完整性。
2.1.2.5.11 process_task()
- 定义了一个名为
process_task的方法,它是一个实例方法,接受一个PgDistTask类型的对象task作为参数,并返回一个布尔值。
def process_task(self, task: PgDistTask) -> bool:
"""更新pg_dist_group表中的一行,可选地在一个事务中进行。
如果我们降级工作节点,或者在没有事务进行的情况下准备提升另一个工作节点之前,会开始一个新的事务。当切换/故障转移完成时,事务会被提交。
注:事务的最大生命周期在本方法之外进行控制。
注:对self._in_flight的读取访问不受保护,因为我们知道它不能在我们的线程之外被改变。
参数:task是一个引用PgDistTask对象的实例,代表要更新或创建的一行。
返回:如果行被成功创建或更新,或者正在进行的事务被提交,则返回True,表明self._pg_dist_group缓存应该被更新;如果开启了新的事务,则返回False。
"""
# 检查task的事件类型是否为'after_promote'
if task.event == 'after_promote':
# 调用update_group方法来更新组,并传递当前是否有事务正在进行的标志
self.update_group(task, self._in_flight is not None)
# 如果当前有事务正在进行,则提交事务
if self._in_flight:
self.query('COMMIT')
task.failover = False
return True
else: # 这一行处理事件类型为'before_demote'或'before_promote'的情况
# 如果task设置了超时时间,则计算任务的截止时间
if task.timeout:
task.deadline = time.time() + task.timeout
# 如果当前没有事务正在进行,则开始一个新的事务
if not self._in_flight:
self.query('BEGIN')
# 调用update_group方法来更新组,并明确指示这是一个事务性的操作
self.update_group(task, True)
return False
作用:
这个process_task方法的作用是在Citus集群中处理与节点状态相关的任务,并根据任务类型管理事务。具体来说:
- 处理
after_promote事件:- 如果事件类型为
'after_promote',则更新组状态。 - 如果当前有事务正在进行,则提交事务。
- 设置
failover标志为False,并返回True,表示任务已完成,缓存应更新。
- 如果事件类型为
- 处理
before_demote或before_promote事件:- 如果事件类型为before_demote
或before_promote`,则:- 如果任务设置了超时时间,则计算任务的截止时间。
- 如果当前没有事务正在进行,则开始一个新的事务。
- 更新组状态,并明确指示这是一个事务性的操作。
- 返回
False,表示开启了新的事务。
- 如果事件类型为before_demote
通过这种方式,process_task方法确保了:
- 根据不同的事件类型正确处理节点状态的更新。
- 在需要时开始和提交事务,以保证数据的一致性和完整性。
- 通过返回值来指示缓存更新的需求或事务的状态变化。
2.1.2.5.12 process_tasks()
- 定义了一个名为
process_tasks的方法,它是一个实例方法,没有返回值。
def process_tasks(self) -> None:
# 这一行开始一个无限循环,用于持续处理任务,直到满足退出条件为止
while True:
# 对‘ _in_flight ’的读访问不受保护,因为我们知道它不能在线程外更改。
if not self._in_flight and not self.load_pg_dist_group():
break
# 这一行调用pick_task方法来选择一个任务,并获取该任务的索引i和任务对象task
i, task = self.pick_task()
if not task or i is None:
break
# 这一行尝试调用process_task方法来处理选择的任务,并获取是否需要更新缓存的标志
try:
update_cache = self.process_task(task)
except Exception as e:
logger.error('Exception when working with pg_dist_node: %r', e)
update_cache = None
with self._condition:
if self._tasks:
# 这一行检查如果需要更新缓存,则将处理后的任务对象写入_pg_dist_group字典
if update_cache:
self._pg_dist_group[task.groupid] = task
# 检查如果update_cache为False,则表示开启了新的事务,并将当前任务设置为正在进行的事务_in_flight。否则,将_in_flight设置为None
if update_cache is False: # 指示process_tasks已启动事务的指示器
self._in_flight = task
else:
self._in_flight = None
# 检查如果任务列表中的任务ID与当前处理的任务ID相同,则从任务列表中移除该任务
if id(self._tasks[i]) == id(task):
self._tasks.pop(i)
task.wakeup()
作用:
这个process_tasks方法的作用是在Citus集群中持续处理任务列表中的任务,并根据任务处理的结果更新缓存或开启事务。具体来说:
- 加载
pg_dist_group信息:如果当前没有事务正在进行,并且加载pg_dist_group信息失败,则退出处理流程。 - 选择任务:从任务列表中选择一个任务,并获取其索引和任务对象。
- 处理任务:
- 尝试处理选择的任务,并获取是否需要更新缓存的标志。
- 如果处理任务过程中发生异常,则记录错误日志,并将缓存更新标志设置为
None。
- 更新缓存或开启事务:
- 如果需要更新缓存,则将处理后的任务对象写入
_pg_dist_group字典。 - 如果缓存更新标志为
False,则表示开启了新的事务,并将当前任务设置为正在进行的事务_in_flight。 - 如果缓存更新标志为
True或其他值,则将_in_flight设置为None。
- 如果需要更新缓存,则将处理后的任务对象写入
- 移除已处理的任务:从任务列表中移除已处理的任务。
- 唤醒等待线程:调用任务对象的
wakeup方法,唤醒等待该任务完成的其他线程或进程。
通过这种方式,process_tasks方法确保了:
- 持续处理任务列表中的任务,直到没有任务可供处理或加载
pg_dist_group信息失败。 - 在处理任务过程中,根据需要更新缓存或开启事务,并确保线程安全。
- 在任务处理完成后,移除已处理的任务,并唤醒等待该任务完成的其他线程或进程。
2.1.2.5.13 run()
- 定义了一个名为
run的方法,它是一个实例方法,没有返回值。
def run(self) -> None:
while True:
try:
with self._condition:
# 检查是否需要加载pg_dist_group信息
if self._schedule_load_pg_dist_group:
timeout = -1
# 检查是否有事务正在进行(_in_flight不为None)
elif self._in_flight:
timeout = self._in_flight.deadline - time.time() if self._tasks else None
# 检查任务列表是否为空
else:
timeout = -1 if self._tasks else None
# 检查timeout是否为None或大于0。如果是,则调用wait方法,等待指定的时间或直到被唤醒
if timeout is None or timeout > 0:
self._condition.wait(timeout)
# 检查是否有事务正在进行,并且timeout小于或等于0
elif self._in_flight:
logger.warning('Rolling back transaction. Last known status: %s', self._in_flight)
self.query('ROLLBACK')
self._in_flight = None
# 调用process_tasks方法来处理任务列表中的任务
self.process_tasks()
except Exception:
logger.exception('run')
作用:
这个run方法的作用是启动一个循环来持续处理任务,并管理事务的状态。具体来说:
- 设置超时时间:
- 如果需要加载
pg_dist_group信息,则设置timeout为-1。 - 如果有事务正在进行,则根据事务的截止时间设置
timeout。 - 如果没有事务正在进行,则根据任务列表是否为空设置
timeout。
- 如果需要加载
- 等待或回滚事务:
- 如果
timeout为None或大于0,则等待指定的时间或直到被唤醒。 - 如果
timeout小于或等于0且有事务正在进行,则回滚事务,并记录一条警告日志。
- 如果
- 处理任务:
- 调用
process_tasks方法来处理任务列表中的任务。
- 调用
- 异常处理:
- 捕获在运行过程中可能发生的任何异常,并记录异常信息。
通过这种方式,run方法确保了:
- 在等待新的任务时,能够合理地设置等待时间。
- 在超时或任务列表为空时,能够及时回滚事务。
- 持续处理任务列表中的任务,并确保在处理过程中线程安全。
- 记录运行过程中的异常信息,便于调试和问题排查。
这个方法通常会被用作一个后台线程的入口点,负责持续监控和处理任务,确保集群状态的一致性和完整性。
2.1.2.5.14 _add_task()
- 定义了一个名为
_add_task的方法,它是一个实例方法,接受一个PgDistTask类型的对象task作为参数,并返回一个布尔值。
def _add_task(self, task: PgDistTask) -> bool:
with self._condition:
# 查找是否存在具有相同groupid的任务
i = self.find_task_by_groupid(task.groupid)
# “PgDistNode。timeout ' == None是sync_meta_data()调度的指示符。
if task.timeout is None:
# 我们不想覆盖从REST API创建的已经存在的任务。
# 检查如果已有任务是由REST API创建的(即timeout不为None),则不覆盖现有任务
if i is not None and self._tasks[i].timeout is not None:
return False
# 从REST API创建的任务有一点竞争条件-在成员之前进行调用
# 在DCS中更新了key。因此,有可能:func: ‘ sync_meta_data ’会尝试创建一个任务
#基于过时的“state”/“role”值。为了解决这个问题,我们引入了一个人工超时。
#只有当达到超时时间时,才可以从sync_meta_data()调度新任务
if self._in_flight and self._in_flight.groupid == task.groupid and self._in_flight.timeout is not None\
and self._in_flight.deadline > time.time():
return False
# 覆盖相同工作组的现有任务
# 检查如果存在具有相同groupid的任务,并且新任务与现有任务不同,则覆盖现有任务,并通知等待的线程
if i is not None:
if task != self._tasks[i]:
logger.debug('Overriding existing task: %s != %s', self._tasks[i], task)
self._tasks[i] = task
self._condition.notify()
return True
# 如果Worker节点状态与缓存的‘ pg_dist_group ’不同,则将任务添加到列表中
elif self._schedule_load_pg_dist_group or task != self._pg_dist_group.get(task.groupid)\
or self._in_flight and task.groupid == self._in_flight.groupid:
logger.debug('Adding the new task: %s', task)
self._tasks.append(task)
self._condition.notify()
return True
return False
作用:
这个_add_task方法的作用是在任务列表中添加或替换任务,并根据任务的状态决定是否进行操作。具体来说:
- 检查任务来源:
- 如果任务是由
sync_meta_data方法调度的(timeout为None),则检查是否有由REST API创建的任务(timeout不为None),如果有,则不进行任何操作。 - 如果有事务正在进行,并且其
groupid与当前任务相同,并且该事务具有有效期限且未超时时,则不进行任何操作。
- 如果任务是由
- 覆盖现有任务:
- 如果存在具有相同
groupid的任务,并且新任务与现有任务不同,则覆盖现有任务,并通知等待的线程。
- 如果存在具有相同
- 添加新任务:
- 如果需要加载
pg_dist_group信息,或者任务状态与缓存的pg_dist_group不同,或者当前有事务正在处理且其groupid与当前任务相同,则将新任务添加到任务列表,并通知等待的线程。
- 如果需要加载
通过这种方式,_add_task方法确保了:
- 只有在必要时才会添加或覆盖任务,避免不必要的操作。
- 通过引入人工超时机制解决竞争条件的问题。
- 通过线程安全的方式管理和通知等待的线程,确保多线程环境下的正确性。
2.1.2.5.15 _pg_dist_node()
- 定义了一个名为
_pg_dist_node的静态方法,它接受两个参数:一个字符串role和一个字符串conn_url,并返回一个PgDistNode对象或None。
@staticmethod
def _pg_dist_node(role: str, conn_url: str) -> Optional[PgDistNode]:
try:
r = urlparse(conn_url)
# 检查解析后的URL是否包含有效的主机名(hostname)
if r.hostname:
return PgDistNode(r.hostname, r.port or 5432, role)
except Exception as e:
logger.error('Failed to parse connection url %s: %r', conn_url, e)
作用:
这个_pg_dist_node静态方法的作用是从连接字符串中解析出PostgreSQL分布式节点的相关信息,并创建一个PgDistNode对象。具体来说:
- 解析连接URL:使用Python标准库中的
urlparse函数来解析输入的连接字符串。 - 创建
PgDistNode对象:- 如果解析后的URL包含有效的主机名,则创建一个
PgDistNode对象,并使用解析得到的主机名、端口(如果没有提供,默认为5432)和角色来初始化该对象。 - 如果解析过程中出现任何异常,则记录错误日志,并返回
None。
- 如果解析后的URL包含有效的主机名,则创建一个
通过这种方式,_pg_dist_node方法确保了:
- 连接字符串可以被正确解析成所需的组件。
- 创建的
PgDistNode对象包含了正确的主机名、端口和角色信息。 - 如果解析过程中出现问题,可以通过错误日志来诊断问题,并且不会因为异常而导致程序崩溃。
2.1.2.5.16 add_task()
-
这一行定义了一个名为
add_task的方法,它是一个实例方法,接受以下参数:event: 字符串类型,表示事件类型。groupid: 整型,表示组ID。cluster:Cluster类型的对象,表示集群信息。leader_name: 字符串类型,表示领导者节点的名字。leader_url: 字符串类型,表示领导者节点的连接URL。timeout: 可选的浮点数,表示任务的超时时间,默认为None。cooldown: 可选的浮点数,表示冷却时间,默认为None。
方法返回一个
PgDistTask对象或None。
def add_task(self, event: str, groupid: int, cluster: Cluster, leader_name: str, leader_url: str,
timeout: Optional[float] = None, cooldown: Optional[float] = None) -> Optional[PgDistTask]:
# 据事件类型确定主节点的角色
primary = self._pg_dist_node('demoted' if event == 'before_demote' else 'primary', leader_url)
if not primary:
return
# 创建一个PgDistTask对象
task = PgDistTask(groupid, {primary}, event=event, timeout=timeout, cooldown=cooldown)
# 遍历集群的所有成员
for member in cluster.members:
secondary = self._pg_dist_node('secondary', member.conn_url)\
if member.name != leader_name and not member.noloadbalance and member.is_running and member.conn_url\
else None
if secondary:
task.add(secondary)
# 调用私有方法_add_task来添加任务
return task if self._add_task(task) else None
作用:
这个add_task方法的作用是根据提供的事件类型、组ID、集群信息等参数创建一个PgDistTask对象,并向系统中添加该任务。具体来说:
- 创建主节点:
- 根据事件类型确定主节点的角色,并使用领导者节点的连接URL创建一个
PgDistNode对象。
- 根据事件类型确定主节点的角色,并使用领导者节点的连接URL创建一个
- 创建任务对象:
- 使用组ID、主节点、事件类型、超时时间和冷却时间来创建一个
PgDistTask对象。
- 使用组ID、主节点、事件类型、超时时间和冷却时间来创建一个
- 添加次级节点:
- 遍历集群的所有成员,并对于每一个符合条件的非领导者节点,创建一个次级节点的
PgDistNode对象,并将其添加到任务对象的次级节点集合中。
- 遍历集群的所有成员,并对于每一个符合条件的非领导者节点,创建一个次级节点的
- 添加任务:
- 调用私有方法
_add_task来尝试向系统中添加创建好的任务对象。如果添加成功,则返回该任务对象;如果添加失败,则返回None。
- 调用私有方法
通过这种方式,add_task方法确保了:
- 正确创建包含主节点和次级节点的任务对象。
- 根据任务类型和集群状态正确构建任务对象。
- 通过调用
_add_task方法来管理任务的添加逻辑,并根据结果返回相应的值。
2.1.2.5.17 handle_event()
- 定义了一个名为
handle_event的方法,它是一个实例方法,接受两个参数:一个Cluster类型的对象cluster和一个字典类型的对象event,并且没有返回值。
def handle_event(self, cluster: Cluster, event: Dict[str, Any]) -> None:
# 检查当前线程是否还活着
if not self.is_alive():
return
# 从集群的工人(workers)字典中通过事件中的group键获取对应的工人对象
worker = cluster.workers.get(event['group'])
# 检查获取到的工人对象是否有效
if not (worker and worker.leader and worker.leader.name == event['leader'] and worker.leader.conn_url):
return logger.info('Discarding event %s', event)
# 调用add_task方法来添加一个新的任务
task = self.add_task(event['type'], event['group'], worker,
worker.leader.name, worker.leader.conn_url,
event['timeout'], event['cooldown'] * 1000)
if task and event['type'] == 'before_demote':
task.wait()
作用:
这个handle_event方法的作用是处理来自集群的事件,并根据事件类型采取相应的行动。具体来说:
- 检查线程状态:
- 如果当前线程已经结束,则直接返回,不再处理事件。
- 验证事件的有效性:
- 从集群的工人字典中获取对应组的工人对象。
- 验证工人对象、工人领导者及其连接URL的有效性。如果无效,则记录一条信息日志,并丢弃事件。
- 添加任务:
- 如果事件有效,则调用
add_task方法来添加一个新的任务,并获取任务对象。
- 如果事件有效,则调用
- 等待任务完成:
- 如果任务对象不为空并且事件类型为
'before_demote',则等待任务完成。
- 如果任务对象不为空并且事件类型为
通过这种方式,handle_event方法确保了:
- 只有在线程仍然活跃时才处理事件。
- 仅处理有效的事件,无效的事件将被记录并丢弃。
- 根据事件类型正确处理任务的添加和等待。特别是对于
'before_demote'类型的事件,会等待任务完成后再继续执行。
2.1.2.5.18 bootstrap()
- 定义了一个名为
bootstrap的方法,它是一个实例方法,没有返回值。
def bootstrap(self) -> None:
"""引导处理器。
当新集群初始化时(通过initdb或自定义引导方法)被调用
"""
# 创建了一个字典conn_kwargs
conn_kwargs = {**self._postgresql.connection_pool.conn_kwargs,
'options': '-c synchronous_commit=local -c statement_timeout=0'}
# 查当前配置的数据库名称是否与PostgreSQL默认使用的数据库名称不同
if self._config['database'] != self._postgresql.database:
conn = connect(**conn_kwargs)
# 尝试创建一个新的数据库
try:
with conn.cursor() as cur:
cur.execute('CREATE DATABASE {0}'.format(
quote_ident(self._config['database'], conn)).encode('utf-8'))
# 捕获在创建数据库过程中可能发生的编程错误
except ProgrammingError as exc:
if exc.diag.sqlstate == '42P04': # DuplicateDatabase
logger.debug('Exception when creating database: %r', exc)
else:
raise exc
finally:
conn.close()
# 更新conn_kwargs,使其连接到刚刚创建的数据库或已经存在的目标数据库
conn_kwargs['dbname'] = self._config['database']
# 使用更新后的conn_kwargs连接到目标数据库
conn = connect(**conn_kwargs)
# 尝试创建Citus扩展,如果扩展已存在则跳过创建
try:
with conn.cursor() as cur:
cur.execute('CREATE EXTENSION IF NOT EXISTS citus')
# 从超级用户配置中提取密码、SSL证书和SSL密钥,并插入到pg_dist_authinfo表中,以便在分布式环境中进行身份验证
superuser = self._postgresql.config.superuser
params = {k: superuser[k] for k in ('password', 'sslcert', 'sslkey') if k in superuser}
if params:
cur.execute("INSERT INTO pg_catalog.pg_dist_authinfo VALUES"
"(0, pg_catalog.current_user(), %s)",
(self._postgresql.config.format_dsn(params),))
# 如果当前节点是协调者(coordinator),则使用当前节点的连接字符串来设置协调者的主机地址
if self.is_coordinator():
r = urlparse(self._postgresql.connection_string)
cur.execute("SELECT pg_catalog.citus_set_coordinator_host(%s, %s, 'primary', 'default')",
(r.hostname, r.port or 5432))
finally:
conn.close()
-
创建了一个字典conn_kwargs。
-
查当前配置的数据库名称是否与PostgreSQL默认使用的数据库名称不同。
- 尝试创建一个新的数据库。
-
更新conn_kwargs,使其连接到刚刚创建的数据库或已经存在的目标数据库。
-
使用更新后的conn_kwargs连接到目标数据库。
-
尝试创建Citus扩展,如果扩展已存在则跳过创建。
- 从超级用户配置中提取密码、SSL证书和SSL密钥,并插入到pg_dist_authinfo表中,以便在分布式环境中进行身份验证。
- 如果当前节点是协调者(coordinator),则使用当前节点的连接字符串来设置协调者的主机地址。
作用:
这个bootstrap方法的作用是在初始化新集群时进行一系列的设置工作。具体来说:
- 创建数据库:
- 如果当前配置的数据库名称与PostgreSQL默认使用的数据库名称不同,则创建一个新的数据库。
- 安装Citus扩展:
- 连接到目标数据库,并安装Citus扩展,如果扩展已存在则跳过安装。
- 配置身份验证信息:
- 从超级用户的配置中提取必要的认证信息,并插入到
pg_dist_authinfo表中。
- 从超级用户的配置中提取必要的认证信息,并插入到
- 设置协调者节点:
- 如果当前节点是协调者节点,则设置协调者的主机地址。
通过这种方式,bootstrap方法确保了:
- 新集群初始化时,能够正确创建数据库、安装必要的扩展、配置身份验证信息以及设置协调者节点的信息。
- 提供了一种安全的方式来创建数据库,并且在创建数据库时进行了SQL注入防护。
- 在分布式环境中,为身份验证提供了必要的配置。
2.1.2.5.19 adjust_postgres_gucs()
- 定义了一个名为
adjust_postgres_gucs的方法,它是一个实例方法,接受一个字典类型的参数parameters,表示要调整的PostgreSQL全局配置参数(GUCs),并且没有返回值。
def adjust_postgres_gucs(self, parameters: Dict[str, Any]) -> None:
"""调整当前PostgreSQL配置中的全局配置参数(GUCs)。
参数parameters是一个字典,键为GUC名称,对应的值为当前GUC的值。
"""
# Citus扩展必须位于shared_preload_libraries的首位
shared_preload_libraries = list(filter(
lambda el: el and el != 'citus',
map(str.strip, parameters.get('shared_preload_libraries', '').split(',')))
) # pyright: ignore [reportUnknownArgumentType]
parameters['shared_preload_libraries'] = ','.join(['citus'] + shared_preload_libraries)
# 如果没有显式设置,Citus将max_prepared_transactions覆盖为max_connections*2
# 从parameters字典中获取shared_preload_libraries的值,并对其进行处理
if parameters['max_prepared_transactions'] == 0:
parameters['max_prepared_transactions'] = parameters['max_connections'] * 2
# Citus中的重分片使用逻辑复制实现
parameters['wal_level'] = 'logical'
# 有时Citus需要连接到本地postgresql。我们会像帕特罗尼那样做。
parameters['citus.local_hostname'] = self._postgresql.connection_pool.conn_kwargs.get('host', 'localhost')
作用:
这个adjust_postgres_gucs方法的作用是对PostgreSQL的全局配置参数进行调整,以适应Citus分布式数据库的特定需求。具体来说:
- 调整
shared_preload_libraries:- 确保
citus扩展位于shared_preload_libraries列表的第一位。
- 确保
- 设置
max_prepared_transactions:- 如果没有显式设置
max_prepared_transactions,则将其设置为max_connections的两倍。
- 如果没有显式设置
- 设置
wal_level:- 设置
wal_level为logical,以支持逻辑复制,这对于Citus的重分区功能至关重要。
- 设置
- 设置
citus.local_hostname:- 设置本地PostgreSQL服务器的主机名,以便Citus在需要连接本地PostgreSQL时能够正确连接。
通过这种方式,adjust_postgres_gucs方法确保了:
- PostgreSQL的配置参数符合Citus分布式数据库的要求。
- 支持Citus特有的功能,如重分区等。
- 在需要时能够正确连接到本地的PostgreSQL服务器。
2.1.2.5.20 ignore_replication_slot()
- 定义了一个名为
ignore_replication_slot的方法,它是一个实例方法,接受一个字典类型的参数slot,表示要检查的复制槽(replication slot)的设置,并返回一个布尔值。
def ignore_replication_slot(self, slot: Dict[str, str]) -> bool:
"""检查提供的复制槽是否不应该从数据库中移除。
注意:
MPP(大规模并行处理)数据库可能会为自身用途创建复制槽,例如使用逻辑复制在工作节点之间迁移数据,我们不希望突然删除这些复制槽。
参数slot是一个包含复制槽设置的字典,如name、database、type和plugin。
返回值:如果复制槽不应被移除,则返回True,否则返回False。
"""
# 检查当前节点是否为主节点(primary),复制槽的类型是否为logical,以及复制槽所在的数据库是否为目标数据库
if self._postgresql.is_primary() and slot['type'] == 'logical' and slot['database'] == self._config['database']:
# 匹配复制槽的名称
m = CITUS_SLOT_NAME_RE.match(slot['name'])
return bool(m and {'move': 'pgoutput', 'split': 'citus'}.get(m.group(1)) == slot['plugin'])
return False
作用:
这个ignore_replication_slot方法的作用是判断一个复制槽是否应该被保留而不是被移除。具体来说:
- 检查当前节点是否为主节点:
- 如果不是主节点,则直接返回
False,表示可以移除复制槽。
- 如果不是主节点,则直接返回
- 检查复制槽类型是否为逻辑类型:
- 如果复制槽类型不是逻辑类型,则直接返回
False。
- 如果复制槽类型不是逻辑类型,则直接返回
- 检查复制槽所在的数据库是否为目标数据库:
- 如果复制槽不在目标数据库中,则直接返回
False。
- 如果复制槽不在目标数据库中,则直接返回
- 检查复制槽名称是否符合Citus相关命名规则:
- 如果复制槽名称符合Citus相关命名规则,并且插件名称也匹配,则返回
True,表示不应该移除该复制槽。
- 如果复制槽名称符合Citus相关命名规则,并且插件名称也匹配,则返回
通过这种方式,ignore_replication_slot方法确保了:
- 只有在满足特定条件下,复制槽才会被保留下来,以避免误删MPP数据库为自身用途创建的复制槽。
- 保证了逻辑复制相关的复制槽不会被意外删除,从而保持了数据迁移等功能的正常运作。
2.2 patroni中的citus配置
Citus(环境配置设置)
启用Patroni与Citus的集成。如果已配置,Patroni将负责在协调器上注册Citus工作节点。您可以在这里找到有关Citus支持的更多信息。
- PATRONI_CITUS_GROUP:Citus组ID,整数。使用
0作为协调员,使用1、2等作为工作者 - PATRONI_CITUS_DATABASE:应创建
citus扩展的数据库。协调员和所有工作人员必须相同。目前只支持一个数据库。
Citus(yaml配置设置)
- 启用Patroni与Citus的集成。如果已配置,Patroni将负责在协调器上注册Citus工作节点。您可以在这里找到有关Citus支持的更多信息。
- group:Citus组ID,整数。使用
0作为协调员,使用1、2等作为工作者 - 数据库:应该创建
citus扩展的数据库。协调员和所有工作人员必须相同。目前只支持一个数据库。
- group:Citus组ID,整数。使用
2.3 patroni中对citus的支持
你只需要遵循几个简单的规则:
- Citus数据库扩展到 PostgreSQL必须在所有节点上可用。 绝对最低支持Citus 版本是10.0,但是,为了从透明切换中获得所有好处, 我们建议至少使用Citus 11.2。
- 所有Citus节点的群集名称(
scope)必须相同! - 协调程序和所有工作程序上的超级用户凭据必须相同 节点,而
pg_hba.conf应该允许所有节点之间的超级用户访问。 - 应允许从工作进程访问REST API 节点到协调器。例如,在一个示例中,凭证应该相同,如果 配置,工作节点的客户端证书必须由 协调员很
- 将以下部分添加到
patroni.yaml:
citus:
group: X # 0 for coordinator and 1, 2, 3, etc for workers
database: citus # must be the same on all nodes
在此之后,您只需启动Patroni,它将处理其余部分:
- Patroni将
bootstrap.dcs.synchronous_mode设置为法定人数 如果它没有被显式地设置为任何其他值, citus扩展将自动添加到shared_preload_libraries。- 如果没有在全局中显式设置
max_prepared_transactions, 动态配置Patroni将 自动将其设置为2*max_connections。 citus.local_hostnameGUC值将从localhost调整到 Patroni用来连接到本地PostgreSQL的值 instance.该值有时应不同于localhost因为PostgreSQL可能不会监听它。citus.database将自动创建,然后是CREATE EXTENSION citus。- 当前超级用户凭据将添加到
pg_dist_authinfo表以允许跨节点通信。不要忘记更新它们,如果 后来你决定改变超级用户的用户名/密码/sslcert/sslkey! - 协调器主节点将自动发现工作者主节点 节点,并使用
pg_dist_node函数。
ol(m and {‘move’: ‘pgoutput’, ‘split’: ‘citus’}.get(m.group(1)) == slot[‘plugin’])
return False
**作用:**
这个`ignore_replication_slot`方法的作用是判断一个复制槽是否应该被保留而不是被移除。具体来说:
1. 检查当前节点是否为主节点:
- 如果不是主节点,则直接返回`False`,表示可以移除复制槽。
2. 检查复制槽类型是否为逻辑类型:
- 如果复制槽类型不是逻辑类型,则直接返回`False`。
3. 检查复制槽所在的数据库是否为目标数据库:
- 如果复制槽不在目标数据库中,则直接返回`False`。
4. 检查复制槽名称是否符合Citus相关命名规则:
- 如果复制槽名称符合Citus相关命名规则,并且插件名称也匹配,则返回`True`,表示不应该移除该复制槽。
通过这种方式,`ignore_replication_slot`方法确保了:
- 只有在满足特定条件下,复制槽才会被保留下来,以避免误删MPP数据库为自身用途创建的复制槽。
- 保证了逻辑复制相关的复制槽不会被意外删除,从而保持了数据迁移等功能的正常运作。
### 2.2 patroni中的citus配置
[Citus](https://patroni.readthedocs.io/en/latest/ENVIRONMENT.html#citus)(环境配置设置)
启用Patroni与[Citus的](https://docs.citusdata.com/)集成。如果已配置,Patroni将负责在协调器上注册Citus工作节点。您可以[在这里](https://patroni.readthedocs.io/en/latest/citus.html#citus)找到有关Citus支持的更多信息。
- PATRONI_CITUS_GROUP:Citus组ID,整数。使用`0`作为协调员,使用`1`、`2`等作为工作者
- PATRONI_CITUS_DATABASE:应创建`citus`扩展的数据库。协调员和所有工作人员必须相同。目前只支持一个数据库。
[Citus](https://patroni.readthedocs.io/en/latest/yaml_configuration.html#citus)(yaml配置设置)
- 启用Patroni与[Citus的](https://docs.citusdata.com/)集成。如果已配置,Patroni将负责在协调器上注册Citus工作节点。您可以[在这里](https://patroni.readthedocs.io/en/latest/citus.html#citus)找到有关Citus支持的更多信息。
- group:Citus组ID,整数。使用`0`作为协调员,使用`1`、`2`等作为工作者
- 数据库:应该创建`citus`扩展的数据库。协调员和所有工作人员必须相同。目前只支持一个数据库。
### 2.3 patroni中对citus的支持
你只需要遵循几个简单的规则:
1. [Citus](https://github.com/citusdata/citus)数据库扩展到 PostgreSQL必须在所有节点上可用。 绝对最低支持Citus 版本是10.0,但是,为了从透明切换中获得所有好处, 我们建议至少使用Citus 11.2。
2. 所有Citus节点的群集名称(`scope`)必须相同!
3. 协调程序和所有工作程序上的超级用户凭据必须相同 节点,而`pg_hba.conf`应该允许所有节点之间的超级用户访问。
4. [应允许从工作进程访问REST API](https://patroni.readthedocs.io/en/latest/yaml_configuration.html#restapi-settings) 节点到协调器。例如,在一个示例中,凭证应该相同,如果 配置,工作节点的客户端证书必须由 协调员很
5. 将以下部分添加到`patroni.yaml`:
citus:
group: X # 0 for coordinator and 1, 2, 3, etc for workers
database: citus # must be the same on all nodes
在此之后,您只需启动Patroni,它将处理其余部分:
1. Patroni将`bootstrap.dcs.synchronous_mode`设置为[法定人数](https://patroni.readthedocs.io/en/latest/replication_modes.html#quorum-mode) 如果它没有被显式地设置为任何其他值,
2. `citus`扩展将自动添加到`shared_preload_libraries`。
3. 如果没有在全局中显式设置`max_prepared_transactions`, [动态配置](https://patroni.readthedocs.io/en/latest/dynamic_configuration.html#dynamic-configuration)Patroni将 自动将其设置为`2*max_connections`。
4. `citus.local_hostname` GUC值将从`localhost`调整到 Patroni用来连接到本地PostgreSQL的值 instance.该值有时应不同于`localhost` 因为PostgreSQL可能不会监听它。
5. `citus.database`将自动创建,然后是`CREATE EXTENSION citus`。
6. 当前超级用户[凭据](https://patroni.readthedocs.io/en/latest/yaml_configuration.html#postgresql-settings)将添加到`pg_dist_authinfo` 表以允许跨节点通信。不要忘记更新它们,如果 后来你决定改变超级用户的用户名/密码/sslcert/sslkey!
7. 协调器主节点将自动发现工作者主节点 节点,并使用 `pg_dist_node`函数。
8. Patroni还将维护`pg_dist_node`,以备故障转移/恢复时使用 在协调器或工作器集群上发生。

















 1281
1281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









