






 文章讲述了在Ubuntu20.04系统中,PyTorch运行时遇到CUDA初始化错误的问题,解决方法包括检查系统休眠设置、使用`sudomodprobenvidia_uvm`和禁用系统休眠。
文章讲述了在Ubuntu20.04系统中,PyTorch运行时遇到CUDA初始化错误的问题,解决方法包括检查系统休眠设置、使用`sudomodprobenvidia_uvm`和禁用系统休眠。
layout: post # 使用的布局(不需要改)
title: torch.cuda.is_available()报错 # 标题
subtitle: ubuntu系统进入休眠后cuda初始化报错 #副标题
date: 2023-11-29 # 时间
author: BY ThreeStones1029 # 作者
header-img: img/about_bg.jpg #这篇文章标题背景图片
catalog: true # 是否归档
tags: pytorch #标签
一、前言
ubuntu20.04,跑代码,系统自动休眠后,程序被异常终止,再次运行后报错
/home/***/anaconda3/envs/nnunet/lib/python3.9/site-packages/torch/cuda/__init__.py:107: UserWarning: CUDA initialization: CUDA unknown error - this may be due to an incorrectly set up environment, e.g. changing env variable CUDA_VISIBLE_DEVICES after program start. Setting the available devices to be zero. (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:109.)
二、解决方法
想来想去,明明下午还能正常运行,晚上回来看发现系统自动进入休眠了,代码被终止了,尝试重新运行发现报错,但理论上应该没问题的,除了系统休眠了一次。经过搜索在torch官网找到解决方法。
sudo rmmod nvidia_uvm
sudo modprobe nvidia_uvm
运行完成后就能正常使用cuda了。
三、设置系统不进入休眠
3.1.查看当前系统休眠状态
systemctl status sleep.target
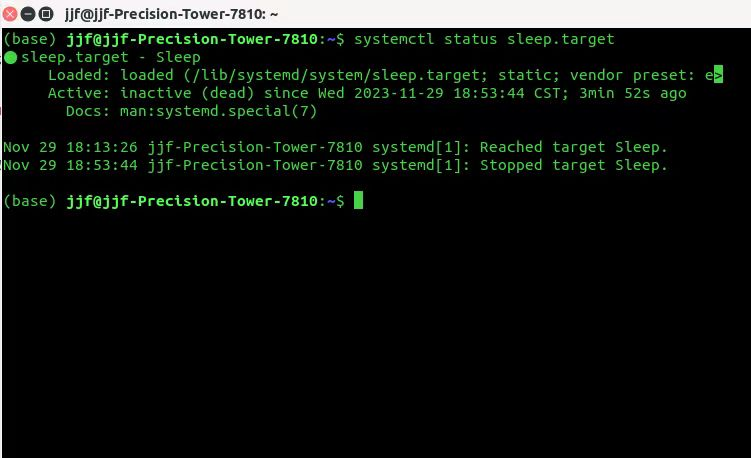
可以看到系统是设置了会自动进入休眠的,状态为loaded
3.2.设置不休眠
重新设置让它不进入休眠
sudo systemctl mask sleep.target supend.target hibernate.target hybrid-sleep.target

3.3.再次查看休眠状态
systemctl status sleep.target

变成masked即可


















 5541
5541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









