







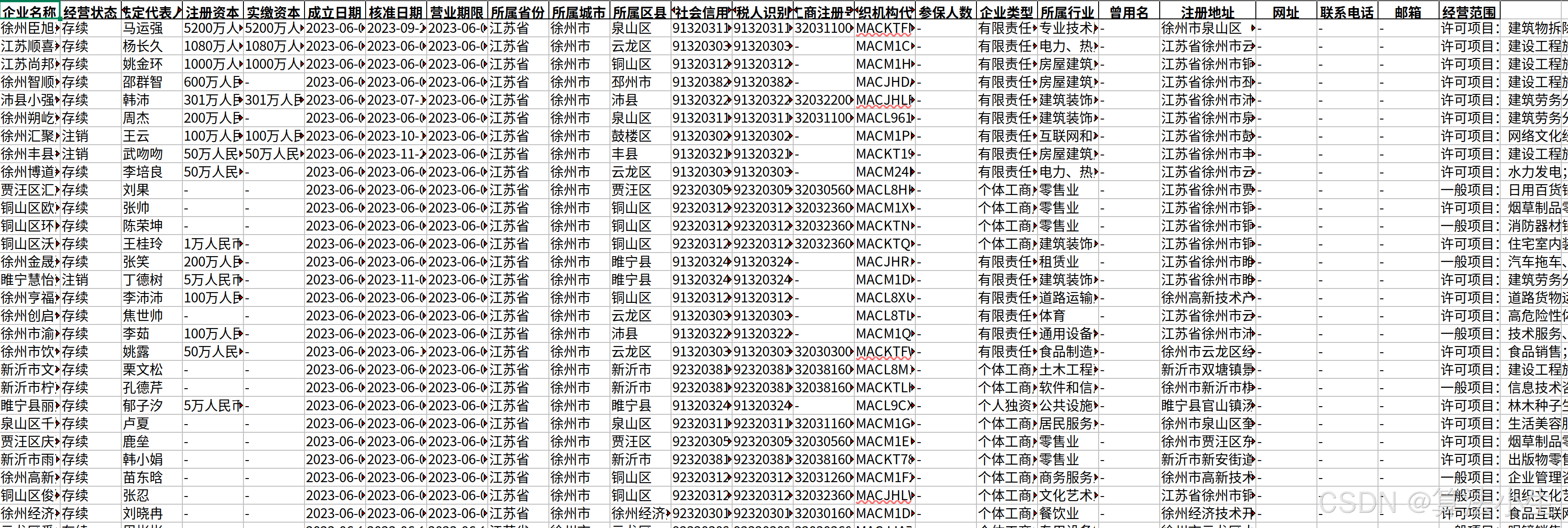
1. 原始数据格式
2. ES索引创建
PUT enterprise_info
{
"mappings": {
"properties": {
"company_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"business_status": {
"type": "keyword"
},
"legal_representative": {
"type": "keyword"
},
"registered_capital": {
"type": "text"
},
"paid_in_capital": {
"type": "text"
},
"establishment_date": {
"type": "date",
"format": "yyyy-MM-dd"
},
"approval_date": {
"type": "date",
"format": "yyyy-MM-dd"
},
"business_term": {
"type": "text"
},
"province": {
"type": "keyword"
},
"city": {
"type": "keyword"
},
"district": {
"type": "keyword"
},
"unified_social_credit_code": {
"type": "keyword"
},
"taxpayer_identification_number": {
"type": "keyword"
},
"business_registration_number": {
"type": "keyword"
},
"organization_code": {
"type": "keyword"
},
"insured_employees": {
"type": "integer"
},
"company_type": {
"type": "keyword"
},
"industry": {
"type": "keyword"
},
"former_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"registered_address": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"website": {
"type": "keyword"
},
"contact_phone": {
"type": "keyword"
},
"email": {
"type": "keyword"
},
"business_scope": {
"type": "text"
},
"english_name": {
"type": "text"
},
"company_size": {
"type": "keyword"
},
"source": {
"type": "keyword"
},
"taxpayer_qualification": {
"type": "keyword"
},
"website": {
"type": "keyword"
},
"primary_industry": {
"type": "keyword"
},
"secondary_industry": {
"type": "keyword"
},
"tertiary_industry": {
"type": "keyword"
},
"registration_authority": {
"type": "keyword"
},
"location": {
"type": "geo_point"
}
}
}
3. 解析入库代码
import pandas as pd
from elasticsearch import helpers
import hashlib
from utils.esutils import es_client
import os
import shutil
import ast
import datetime
# 字段映射字典:中文字段名 -> 英文字段名
FIELD_MAPPING = {
"企业名称": "company_name",
"英文名称": "english_name",
"统一社会信用代码": "unified_social_credit_code",
"企业类型": "company_type",
"经营状态": "business_status",
"成立日期": "establishment_date",
"核准日期": "approval_date",
"法定代表人": "legal_representative",
"注册资本": "registered_capital",
"实缴资本": "paid_in_capital",
"参保人数": "insured_employees",
"公司规模": "company_size",
"经营范围": "business_scope",
"注册地址": "registered_address",
"营业期限": "business_term",
"来源": "source",
"纳税人识别号": "taxpayer_identification_number",
"工商注册号": "business_registration_number",
"组织机构代码": "organization_code",
"联系电话": "contact_phone",
"邮箱": "email",
"纳税人资质": "taxpayer_qualification",
"曾用名": "former_name",
"所属省份": "province",
"所属城市": "city",
"所属区县": "district",
"网站链接": "website",
"网址": "website", # 兼容旧字段名
"所属行业": "industry",
"一级行业分类": "primary_industry",
"二级行业分类": "secondary_industry",
"三级行业分类": "tertiary_industry",
"登记机关": "registration_authority",
"经度": "longitude", # 临时字段,用于生成 location
"纬度": "latitude" # 临时字段,用于生成 location
}
def get_unique_id(province, city, district, address, company_name):
"""
生成唯一 ID,基于省份、城市、区域、注册地址和公司名。
Args:
province (str): 省份。
city (str): 城市。
district (str): 区域。
address (str): 注册地址。
company_name (str): 公司名。
Returns:
str: 唯一 ID。
"""
# 处理空值和值为 "-"
province = province if province and province != "-" else "unknown_province"
city = city if city and city != "-" else "unknown_city"
district = district if district and district != "-" else "unknown_district"
address = address if address and address != "-" else "unknown_address"
company_name = company_name if company_name and company_name != "-" else "unknown_company"
# 拼接字段值
combined = f"{province}{city}{district}{address}{company_name}"
# 使用 MD5 生成唯一 ID
return hashlib.md5(combined.encode('utf-8')).hexdigest()
def bulk_with_retry(es_client, actions, retries=3):
"""
带重试机制的批量写入。
Args:
es_client: Elasticsearch 客户端。
actions (list): 批量操作列表。
retries (int): 重试次数。
Returns:
bool: 是否成功。
"""
for attempt in range(retries):
try:
helpers.bulk(es_client, actions)
return True
except Exception as e:
print(f"批量写入失败,尝试 {attempt + 1}/{retries}: {e}")
if attempt == retries - 1:
raise e
return False
def import_to_es(df, index_name="enterprise_info", batch_size=5000, retries=1):
"""
将 DataFrame 数据批量写入 Elasticsearch。
如果字段值为 "-",则不写入该字段。
将经度和纬度合并为 location 字段(geo_point 类型)。
Args:
df (pandas.DataFrame): 包含企业信息的 DataFrame,字段名为中文。
index_name (str): 目标索引名。
batch_size (int): 批量写入的大小。
retries (int): 批量写入失败时的重试次数。
"""
actions = []
processed_count = 0
total_rows = len(df)
# 遍历 DataFrame 的每一行
for _, row in df.iterrows():
# 构建文档内容,将中文字段名映射为英文
info = {}
longitude = None
latitude = None
for cn_field, en_field in FIELD_MAPPING.items():
value = row.get(cn_field)
# 跳过 NaN 和值为 "-" 的字段
if pd.isna(value) or value == "-":
continue
# 临时存储 longitude 和 latitude
if en_field == "longitude":
longitude = value
continue
if en_field == "latitude":
latitude = value
continue
if en_field == "establishment_date" or en_field == "approval_date":
value = value.split(" ")[0]
try:
datetime.datetime.strptime(value, "%Y-%m-%d")
except ValueError:
value = None
info[en_field] = value
# 如果 longitude 和 latitude 都存在,生成 location 字段
if longitude is not None and latitude is not None:
try:
info["location"] = {
"lat": float(latitude),
"lon": float(longitude)
}
except (ValueError, TypeError):
print(f"无法转换经纬度为 location 字段: longitude={longitude}, latitude={latitude}")
# 生成唯一 ID
unique_id = get_unique_id(
info.get("province"),
info.get("city"),
info.get("district"),
info.get("registered_address"),
info.get("company_name")
)
# 构建 action
action = {
"_op_type": "index",
"_index": index_name,
"_id": unique_id,
"_source": info
}
actions.append(action)
processed_count += 1
# 批量写入
if len(actions) >= batch_size:
try:
bulk_with_retry(es_client, actions, retries)
actions.clear()
print(f"已处理 {processed_count}/{total_rows} 条数据")
except Exception as e:
print(f"批量写入失败: {e}")
print(actions)
pd.DataFrame(actions).to_csv('写入失败数据.csv', index=False)
raise e
# 处理剩余的数据
if actions:
try:
bulk_with_retry(es_client, actions, retries)
print(f"已处理 {processed_count}/{total_rows} 条数据(最后一批)")
except Exception as e:
print(f"批量写入失败(最后一批): {e}")
raise e
print(f"总共处理 {processed_count}/{total_rows} 条数据,写入完成!")
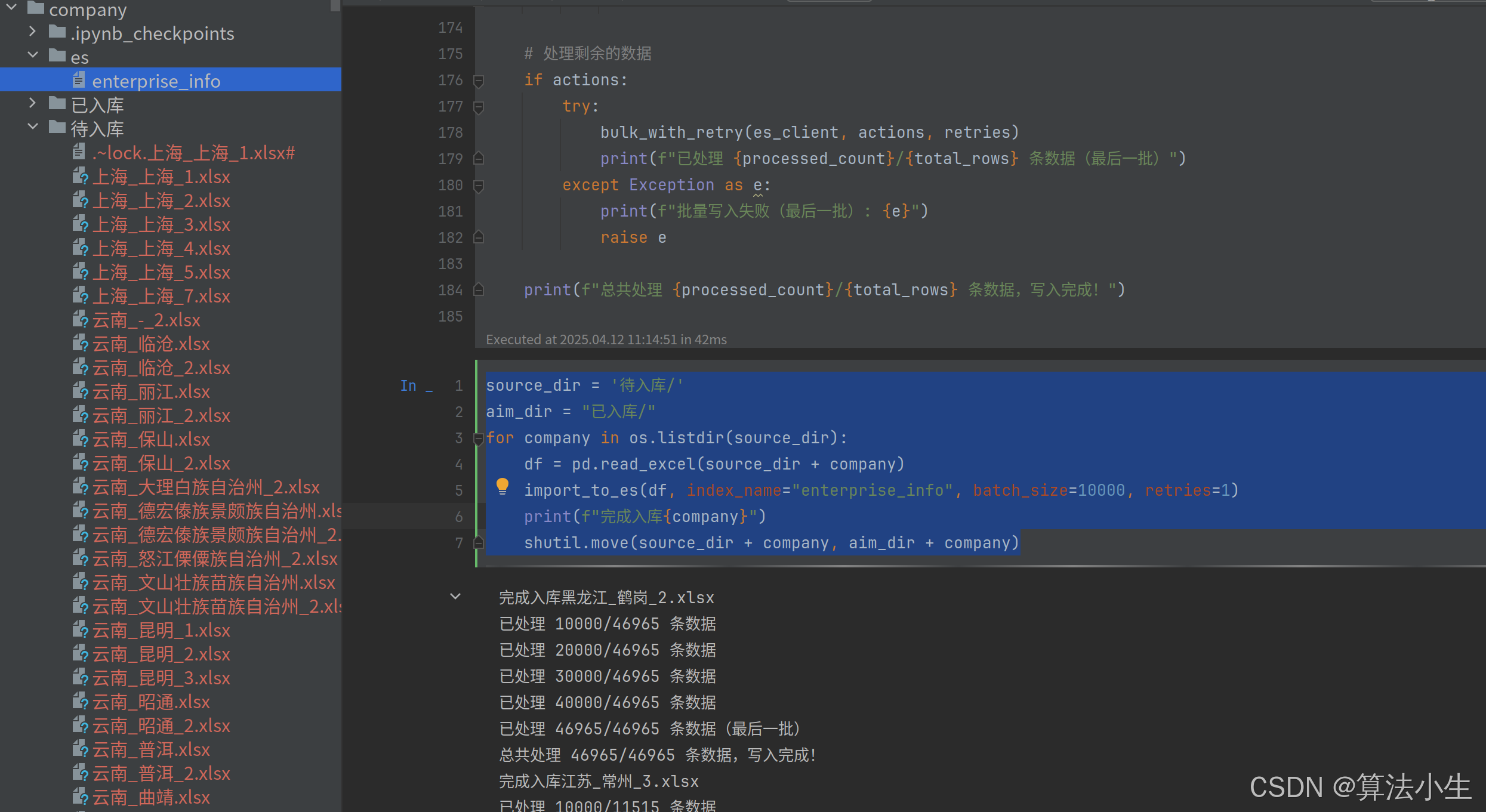
source_dir = '待入库/'
aim_dir = "已入库/"
for company in os.listdir(source_dir):
df = pd.read_excel(source_dir + company)
import_to_es(df, index_name="enterprise_info", batch_size=10000, retries=1)
print(f"完成入库{company}")
shutil.move(source_dir + company, aim_dir + company)
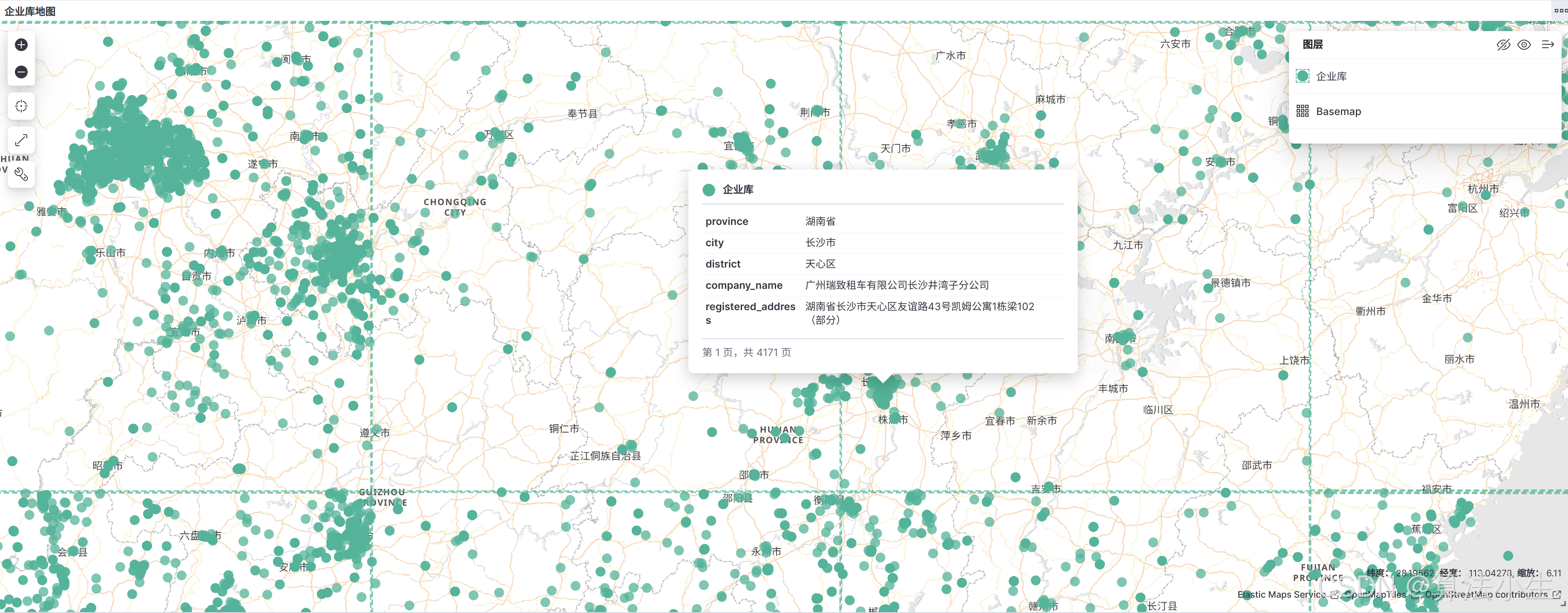
4. 入库结果
5. 下一步规划
上次我们训练了简单的中文分词模型,效果不是太好,后面转向Bert+CRF中文分词研究,有了这么多真实地址进行测试验证,相信很快就会有结果,第一时间开源给大家




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











