 AWS EC2到RDS数据库迁移教程
AWS EC2到RDS数据库迁移教程




本次教程是AWS的EC2迁移到同一个VPC的RDS数据库上,EC2采用的是Ubuntu系统,mysql8.0.24版本。
然后使用DMS进行全量迁移和增量迁移
目录
介绍
AWS Database Migration Service(AWSDMS)
1.支持多种数据库引擎之间的迁移,包括关系型数据库和非关系型数据库。
2.支持单个数据库或整个数据库实例的迁移,并且可以进行增量迁移,确保在迁移期间对
源数据库的操作和更改都能同步到目标数据库中。
3.以处理大规模的数据迁移,支持并行迁移和分布式数据复制,以满足各种规模和需求的
迁移任务。
客户需求
1.生产环境数据库主库不能停机或者重启
2.生产环境数据库主库不能停机或者重启
3.需要用到第三方迁移工具
目标
验证DMS迁移成功性
验证目标库增量数据对源库的同步功能,数据库双向同步实现
指导第三方工具进行全量迁移
前期环境准备:
创建一个自己的VPC或者使用默认的VPC
有本地上云机器环境
如有环境请点击跳转到使用DMS进行全量和增量迁移上
创建EC2
首先,先创建了一个EC2实例,可以参考:
AWS 如何创建EC2以及连接EC2实例_aws中ec2创建新实例教程-优快云博客
进入终端之后
先输入执行
apt-get update然后再执行
apt-get install mysql-server -y来安装MySQL server服务器,
安装成功之后连接数据库
mysql -u root -p回车
一般来说是空密码
然后创建admin用户,加数据的时候要用
CREATE USER 'admin'@'%' IDENTIFIED BY 'your_password';授予 admin 用户所有权限:
GRANT ALL PRIVILEGES ON *.* TO 'admin'@'%' WITH GRANT OPTION;刷新权限,使更改生效:
FLUSH PRIVILEGES;创建mydb数据库
CREATE DATABASE mydb;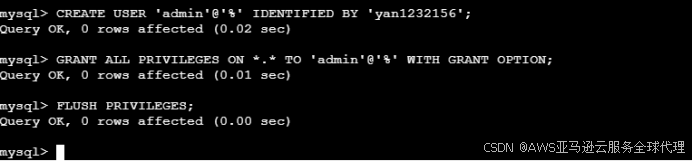
然后Ctrl +d退出
然后我们编辑配置文件使mysql能够公网连接Mysql
vim /etc/mysql/mysql.conf.d/mysqld.cnf将 bind-address的值改成0.0.0.0

然后我们重启mysql服务
systemctl daemon-reload
systemctl restart mysql
然后我们让我们自建的MYSQL数据库增加数据
数据库自增数据python代码:
运行代码的前置依赖:
apt install python3-pip -y
pip3 install pymysql
pip3 install faker
强制安装(风险较高,不推荐)
你可以使用 --break-system-packages 选项强制安装,但这可能会破坏系统环境:
pip3 install --break-system-packages pymysql faker创建一个py文件加进去然后执行下面代码插入1G的数据
vim codde.py然后我们把以下代码加上去:
import pymysql
from faker import Faker
import os
# 连接到MySQL数据库
conn = pymysql.connect(
host="localhost",
user="admin",
password="password",
database="mydb"
)
# 获取游标对象
cursor = conn.cursor()
# 准备要插入的数据
fake = Faker('zh_CN') # 使用中文本地化
data_size = 1 * 1024 * 1024 # 10MB
batch_size = 1024 # 1KB
num_tables = 10 # 生成10个表
# 批量生成表并插入数据
for table_num in range(num_tables):
table_name = f"mytable_{table_num}"
# 创建表
cursor.execute(f"DROP TABLE IF EXISTS {table_name}")
cursor.execute(f"CREATE TABLE {table_name} (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255), address VARCHAR(255), phone VARCHAR(20))")
# 分批插入数据
for i in range(0, data_size, batch_size):
batch_data = []
for _ in range(batch_size):
name = fake.name()
address = fake.address()
phone = fake.phone_number()
batch_data.append((name, address, phone))
sql = f"INSERT INTO {table_name} (name, address, phone) VALUES (%s, %s, %s)"
cursor.executemany(sql, batch_data)
conn.commit()
print(f"Inserted {i+batch_size}/{data_size} bytes into {table_name}")
# 关闭连接
cursor.close()
conn.close()
:wq保存
执行python文件等待代码执行完毕
python3 code.py &然后我们连接mysql数据库
mysql -uroot -p然后回车
查询所有表的行数
SELECT TABLE_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'mydb';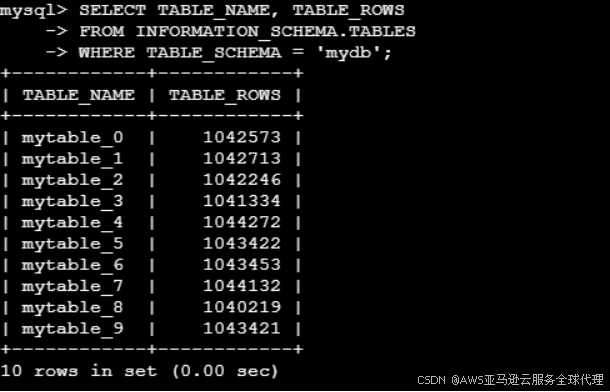
然后我们EC2实例的数据就插入完了
然后我们创建RDS数据库单实例
然后在AWS 控制台导航栏上搜索RDS
创建RDS
先创建一个参数组
有关RDS创建请参考创建AWS RDS数据库及参数组并连接-优快云博客
然后创建一个RDS单实例,引擎类型和引擎版本与ec2对应
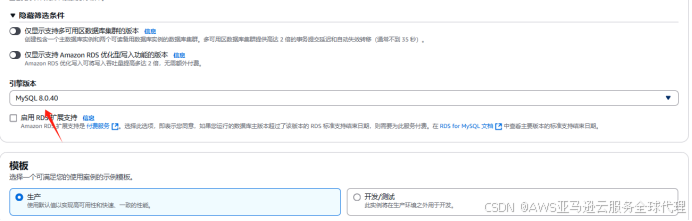
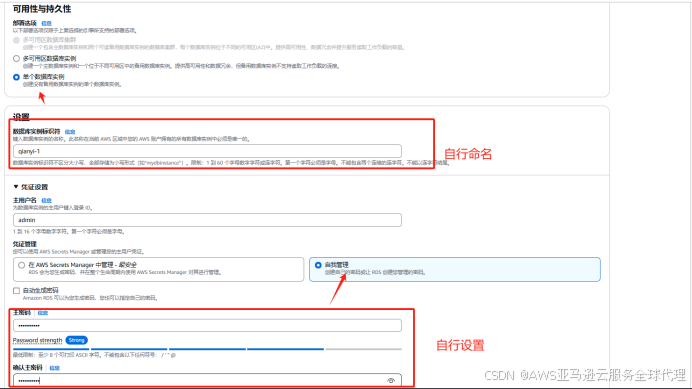
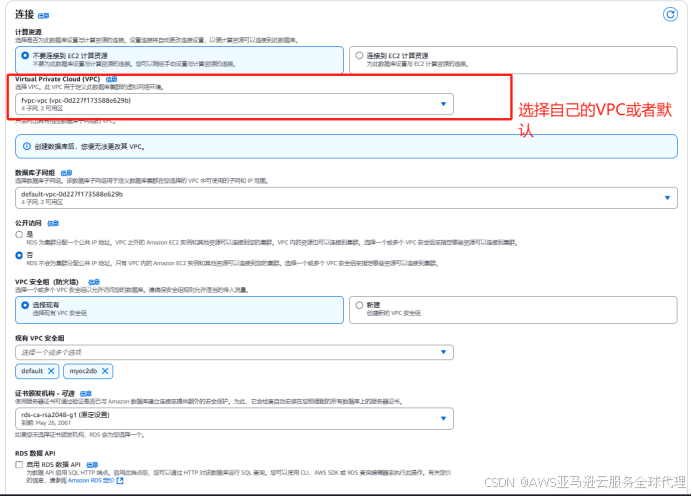
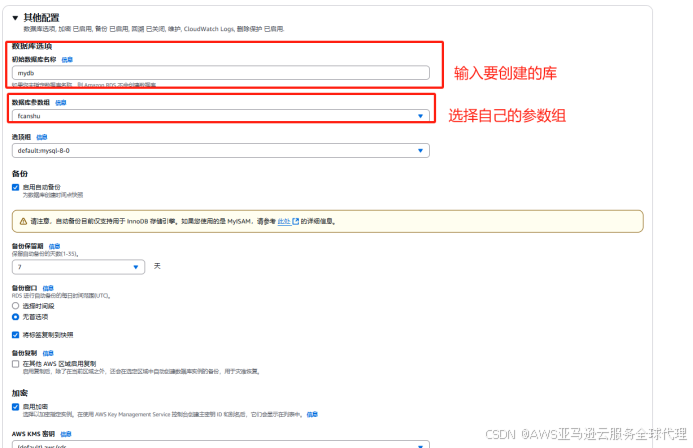
其他保持默认然后选择创建,等待创建成功

使用DMS进行全量和增量迁移
1、在AWS控制台上搜索DMS并选择
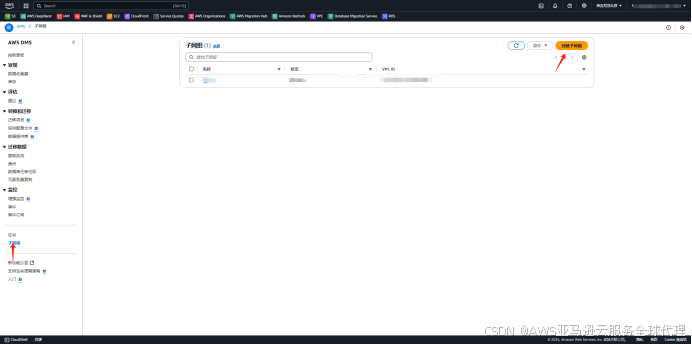
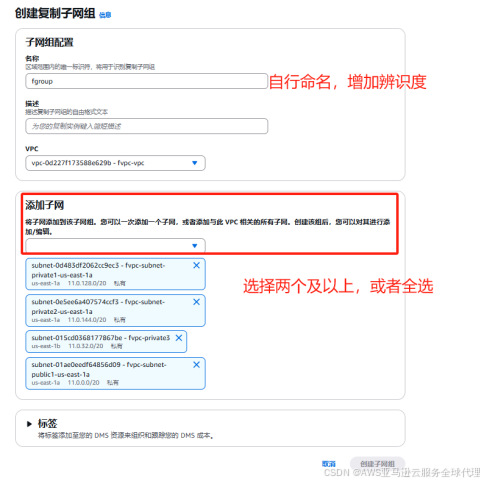
2、在左侧导航栏找到子网组,点击创建子网组
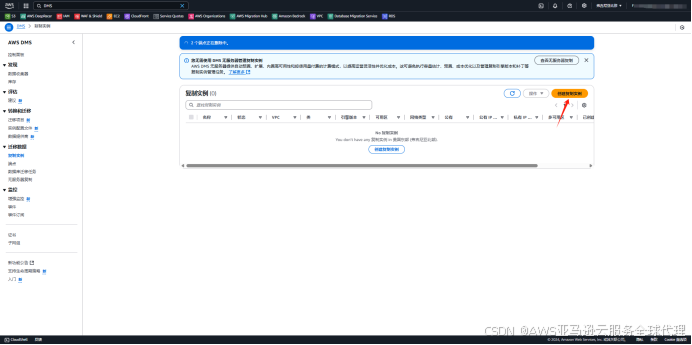
3、在左侧导航栏找到复制实例,点击复制实例
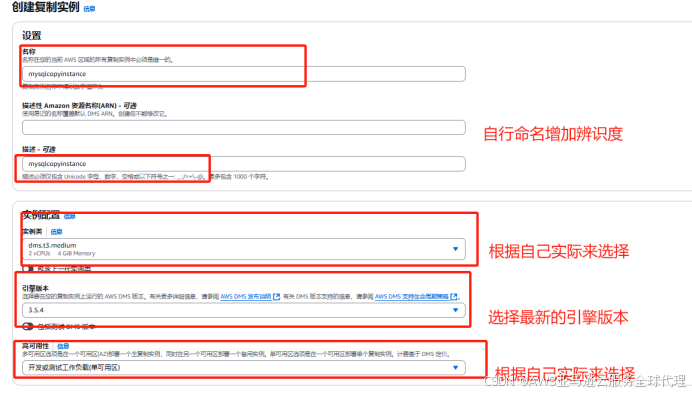
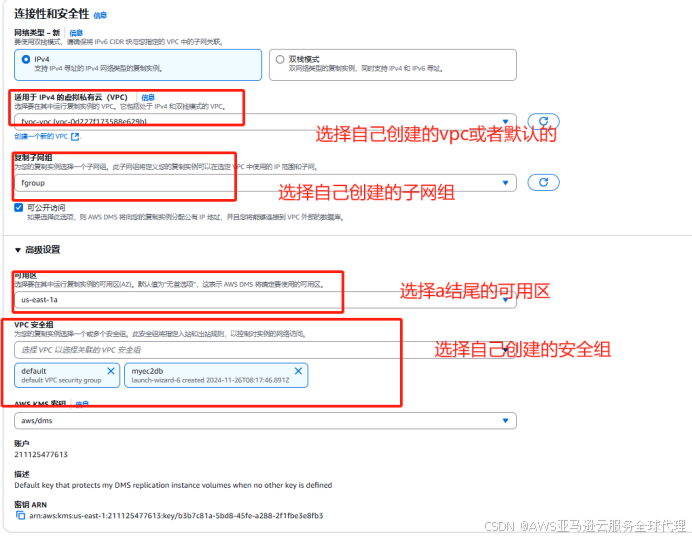
其他保持默认点击创建
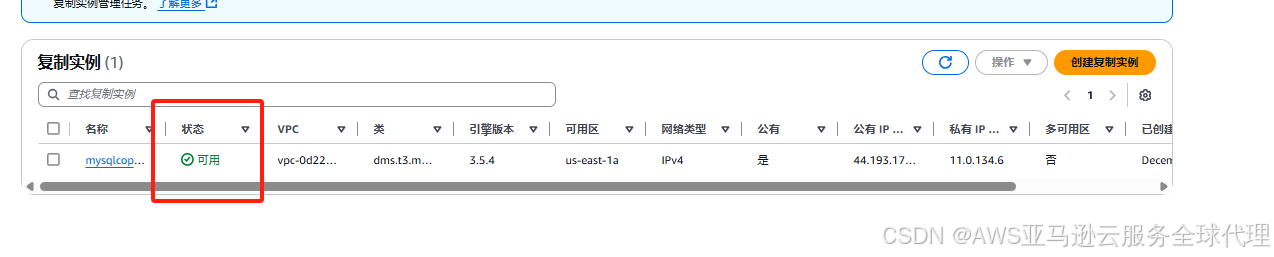
4、等待复制实例创建完成
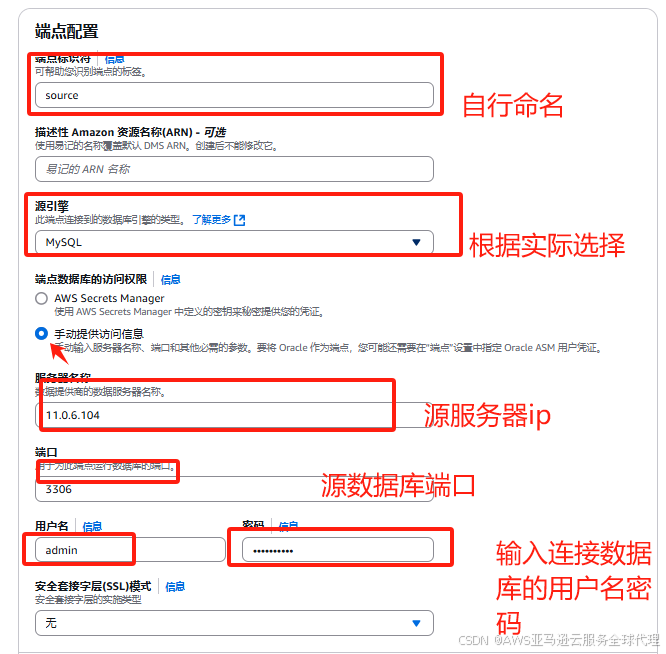
5、创建源端点
在左侧导航栏找到端点,点击创建断点
然后点击运行测试
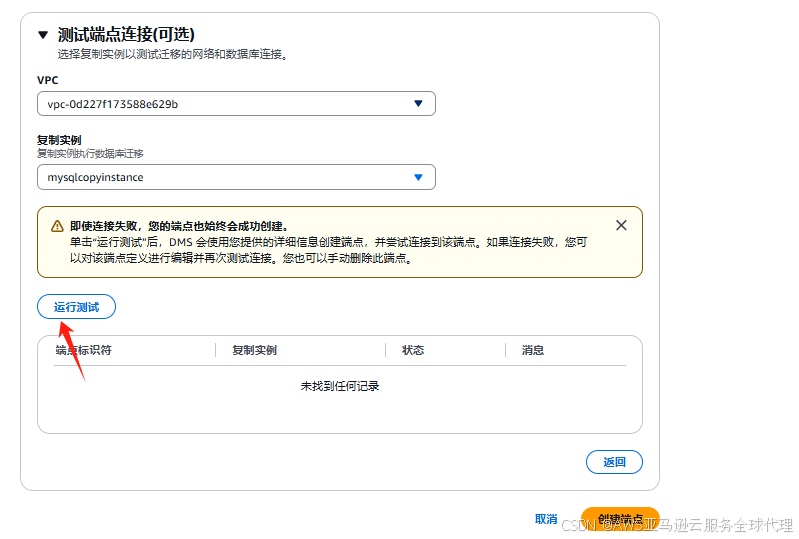
等待这个状态是successful的我们就点击创建端点

6、创建目标端点
在左侧导航栏找到端点,点击创建端点
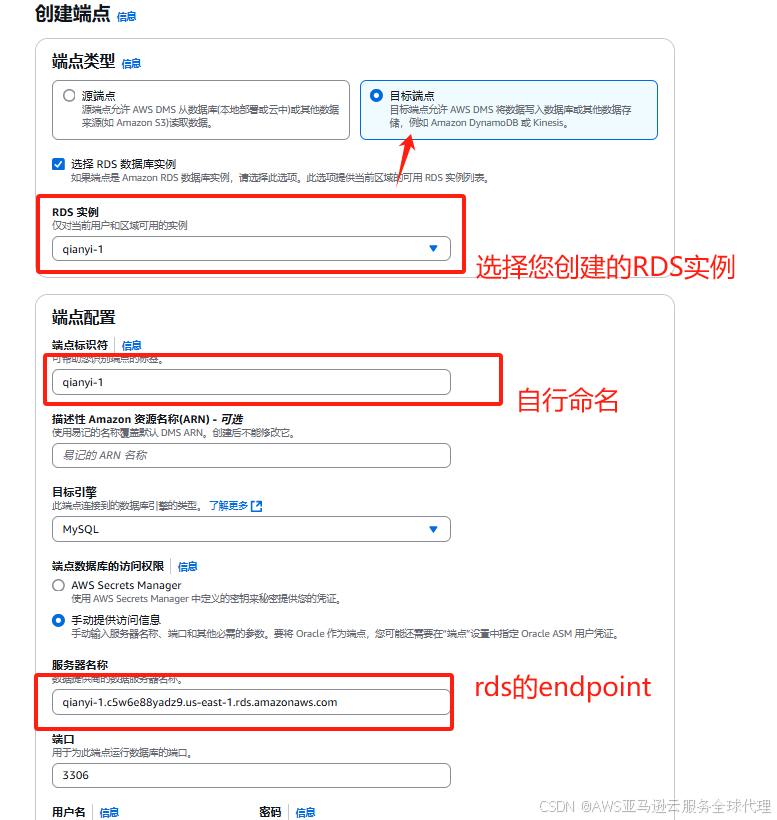
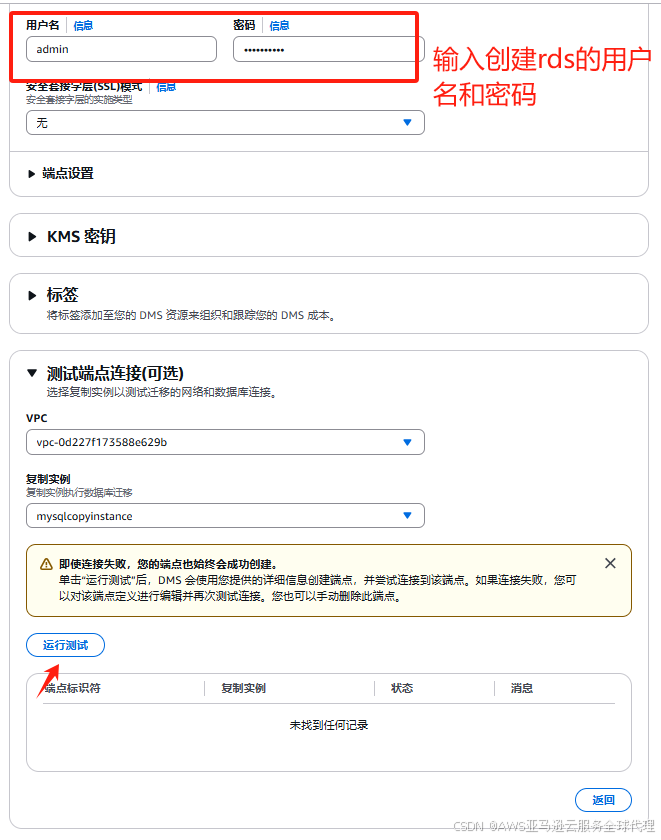
然后点击运行测试
等待这个状态是successful的我们就点击创建端点
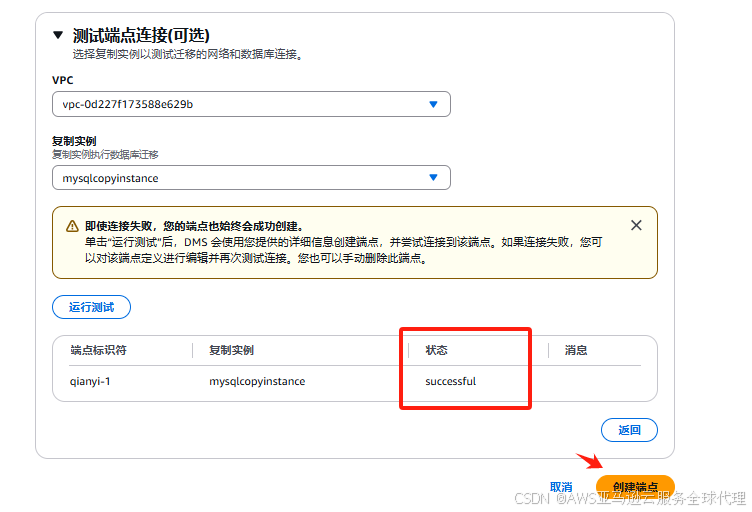
7、然后就是创建迁移任务
创建迁移任务。AWS Database Migration Service (AWS DMS) 任务是执行所有工作的地方。您可以指定要用于迁移和任何特殊处理的表 (或视图) 和架构,例如日志记录要求、控制表数据和错误处理。
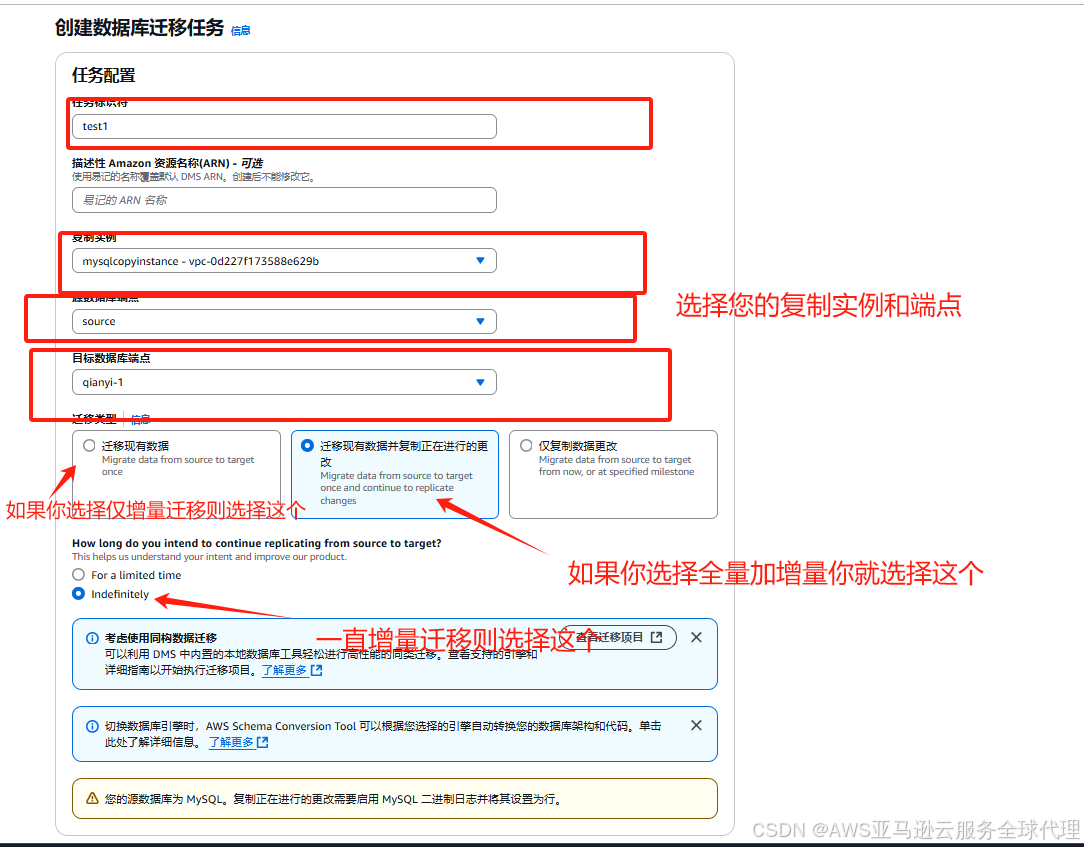
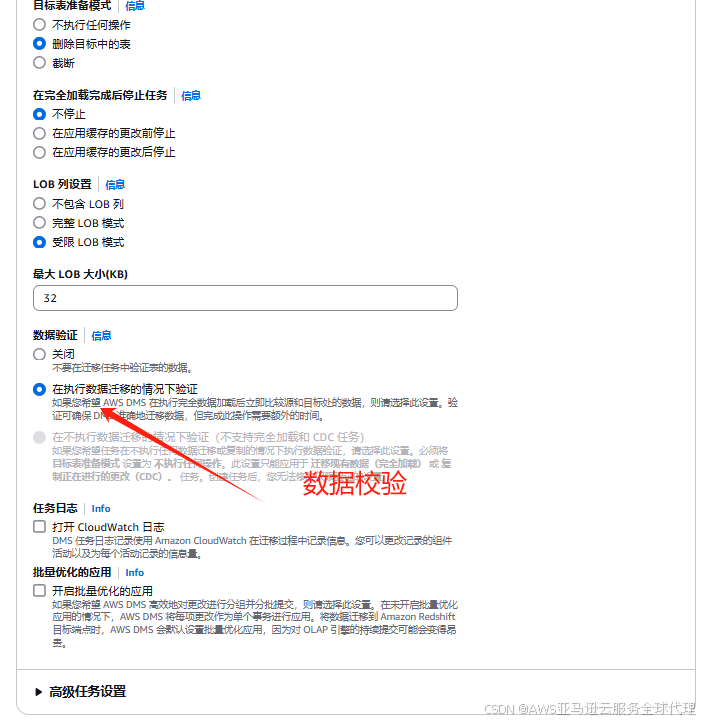
然后我们把数据校验开了
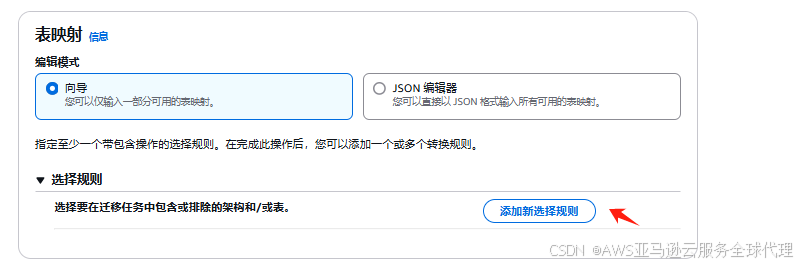
滑倒表映射我们点击添加新选择规则
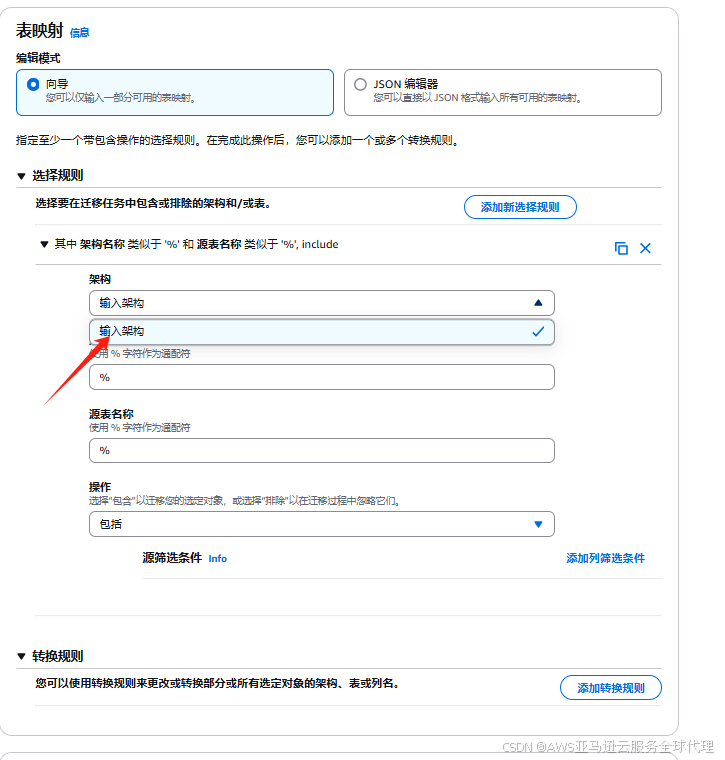
架构那里选择输入架构
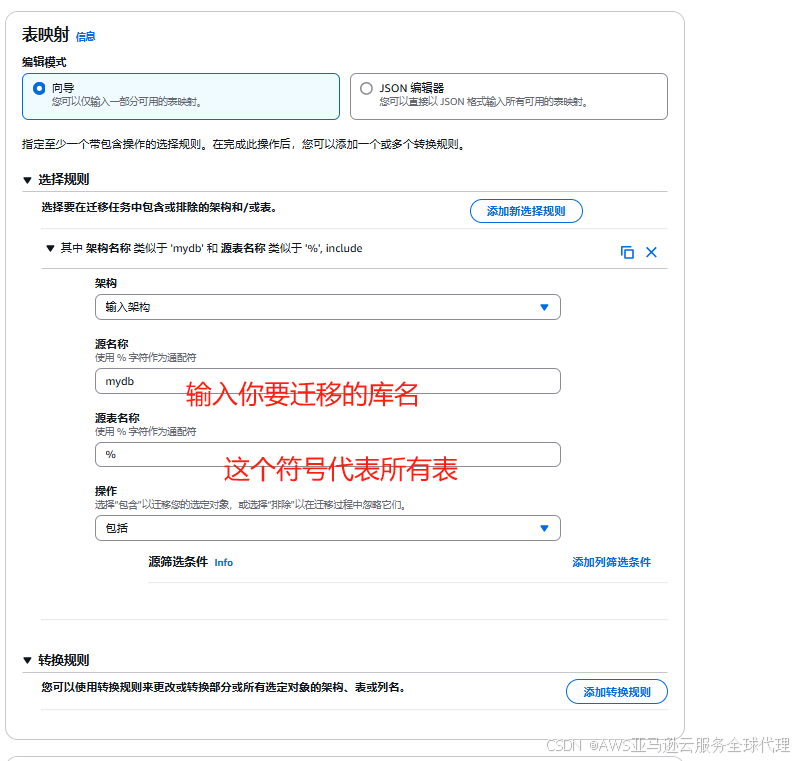
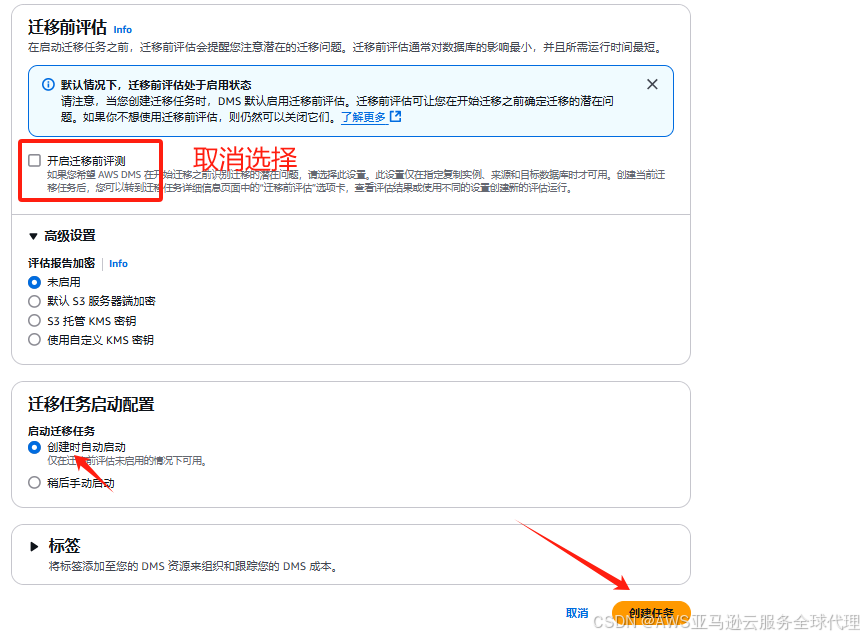
取消选择开启迁移前评测,点击创建任务
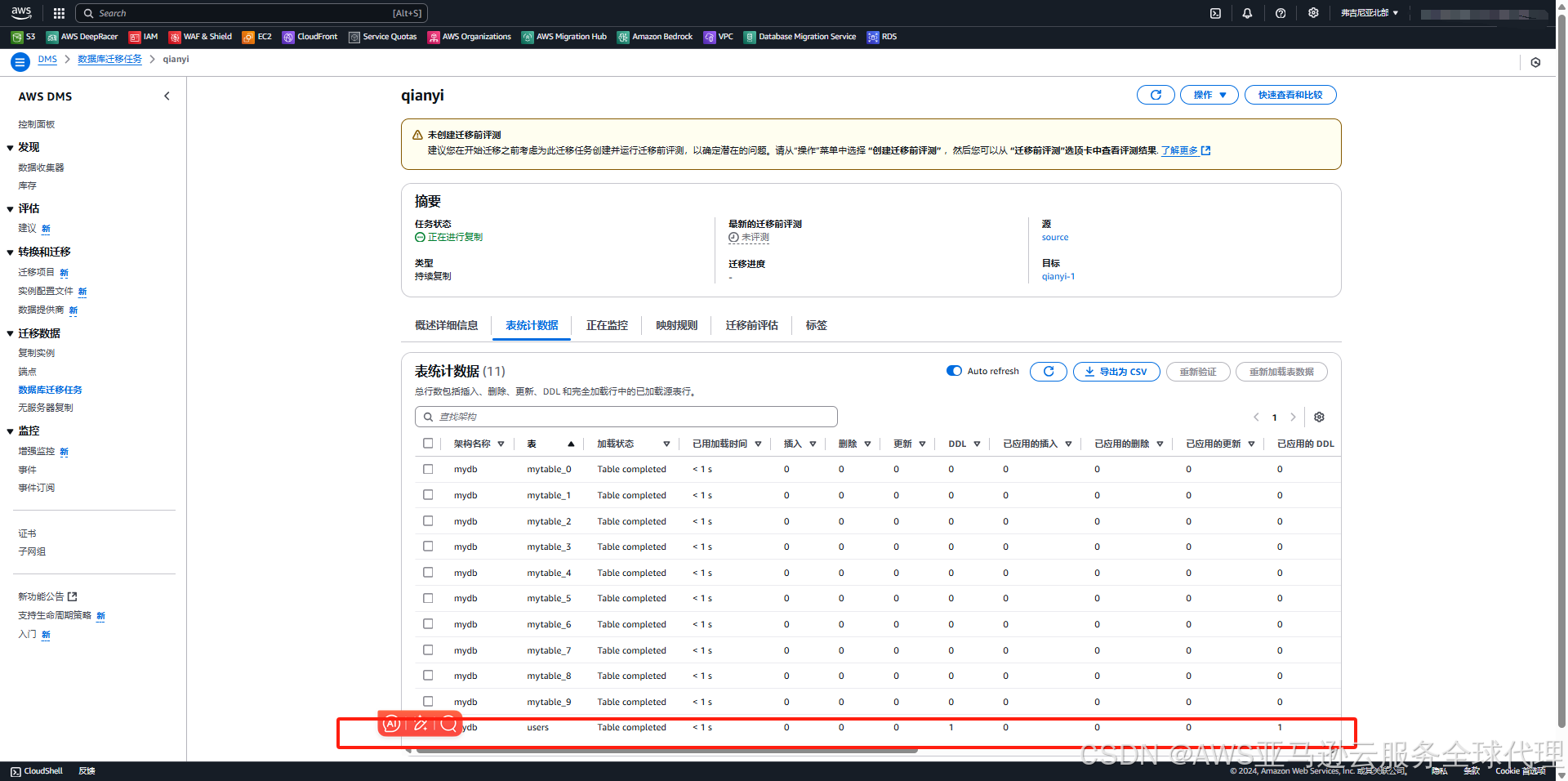
点击这个任务,点击表统计数据
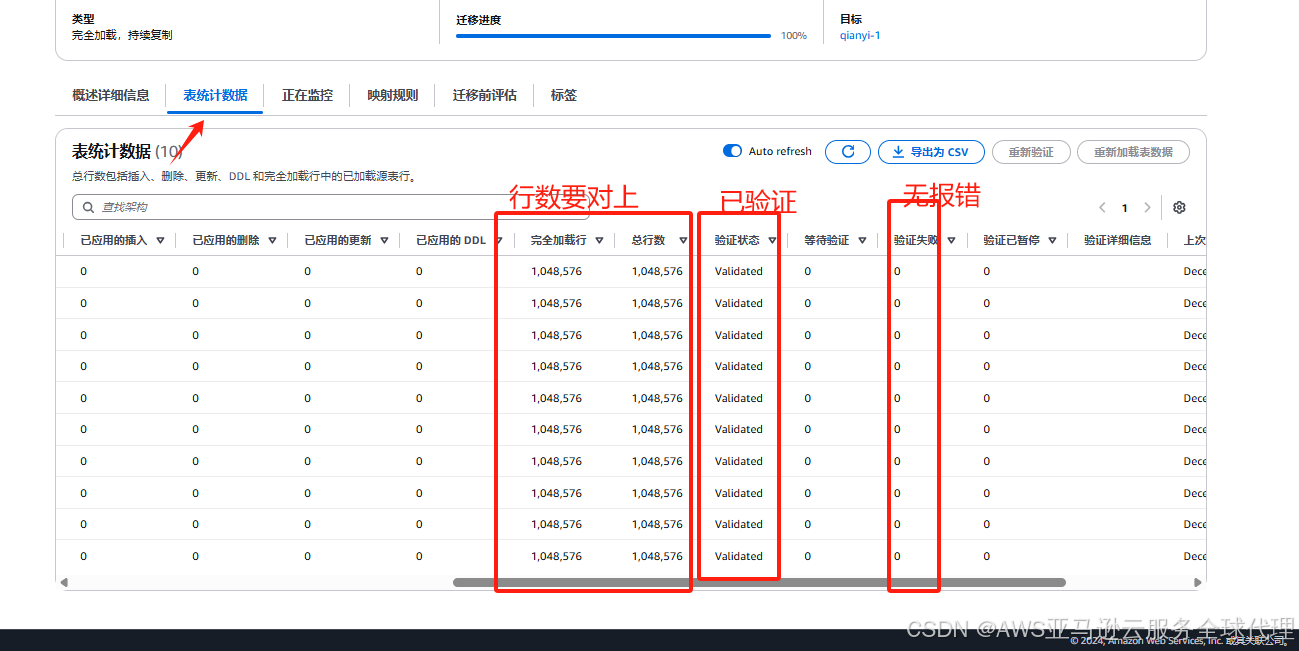
使用SQL语句进行数据核对,源和数据库两边值一致就没问题
SELECT COUNT(*) FROM mytable_1;
测试表前后两行的数据,源和数据库两边一致就没有问题
查询表的前2行数据
SELECT * FROM mytable_0 LIMIT 2;查询表的后2行数据
SELECT *
FROM mytable_0
ORDER BY id DESC
LIMIT 2;
其他工具全量迁移然后使用AWS DMS服务进行增量
做迁移前准备事项
首先我们先查看mysql的时区是是否一致,需要改成UTC时区进行重启
进入源数据库执行
SHOW VARIABLES LIKE '%time_zone%';
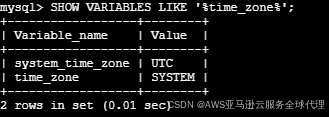
不是UTC则需要更改时区,更改完进行重启进行导出进行重启
mysqldump
全量备份
使用mysql官方提供了mysqldump(简单,备份时间长,如果是简单的备份 / 恢复,使用它就足够了)
全量备份:可以使用mysqldump直接备份整个库或者是备份其中某一个库或者一个库中的某个表。
#1.登录选项:
-u user:指定用户
-h host:指定主机
-p:表示要使用密码
#2.备份选项:
--all-databases:备份所有数据库
--databases db1 db2:备份指定的数据库
--single-transaction:对事务引擎执行热备
--flush-logs:更新二进制日志文件
--master-data=2
1:每备份一个库就生成一个新的二进制文件(默认)
2:只生成一个新的二进制文件
--quick:在备份大表时指定该选项
1.备份指定数据库。(全量备份mysql某个数据库)
mysqldump -uroot -p --databases testdb --single-transaction --flush-logs --master-data=2 > databases.sql
回车输入密码
2.备份多个数据库。
mysqldump -uroot -p --databases testdb testdemo --single-transaction --flush-logs --master-data=2 > databases.sql
回车输入密码
3.备份所有数据库。
mysqldump -uroot -p --all-databases --single-transaction --flush-logs --master-data=2 > all_databases.sql
回车输入密码
恢复数据
1.mysql命令恢复至指定数据库
-- 恢复至指定数据库(Test)
mysql -u root -h 127.0.0.1 -p Test < c:\demo.sql
如果已经登录mysql,则可以使用这种方式恢复至指定数据库,但只能在cmd界面下执行source命令,不能在mysql工具里面执行source命令。
-- 如果已经登录mysql,则可以使用这种方式恢复至指定数据库
-- 只能在cmd界面下执行source命令,不能在mysql工具里面执行source命令
use Test;
source c:\demo.sql
2.从所有备份的数据库文件中恢复某一个数据库
mysql -u root -p song --one-database< /demo.sql 使用DMS进行增量迁移
使用mysqldump全量迁移完导入之后,我们使用DMS增量迁移
我们在源数据库上
我们查看最新的binlog日志
我们进入mysql的binlog路径查看binlog的文件
mysqlbinlog <最新的binlog文件路径> | grep -i "^#"

然后我们创建AWS的DMS的子网组、复制实例、源端点、目的端点请参考上面在AWS控制台上搜索DMS并选择
我们创建迁移任务
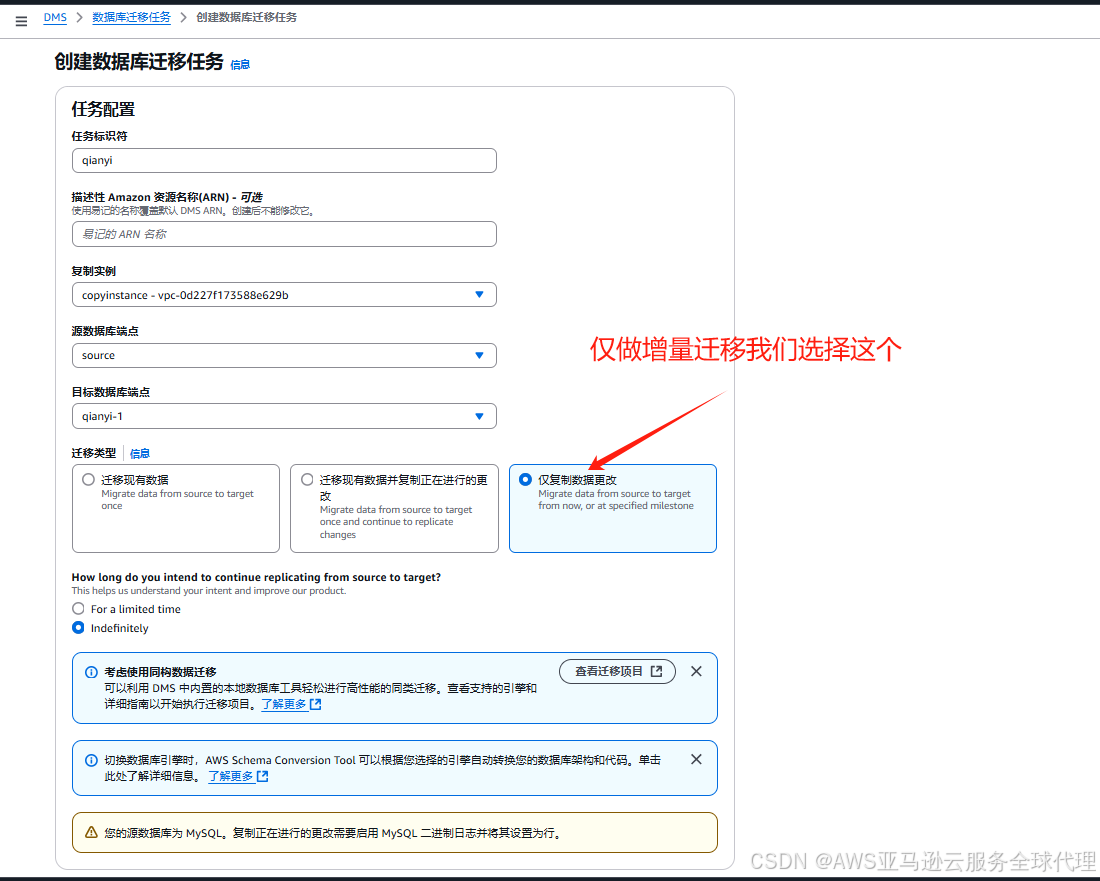
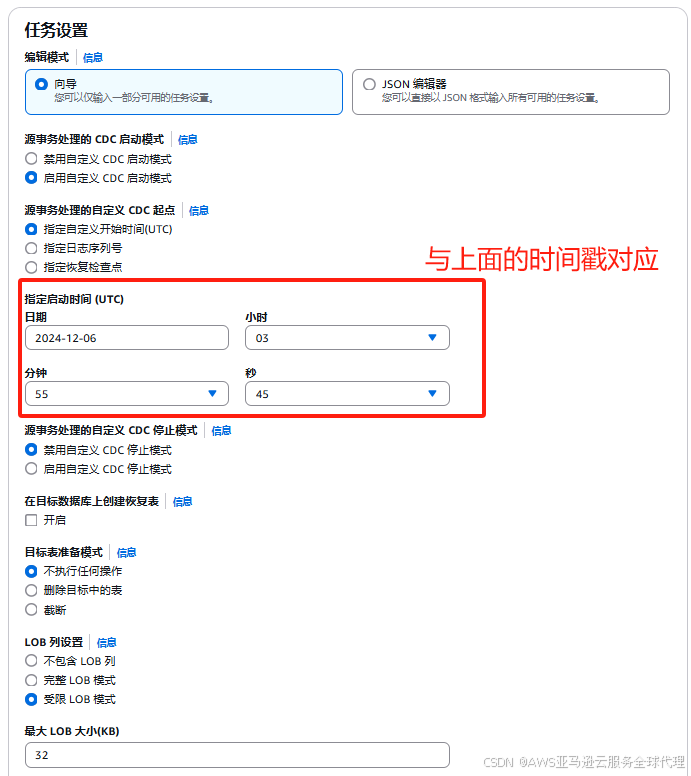
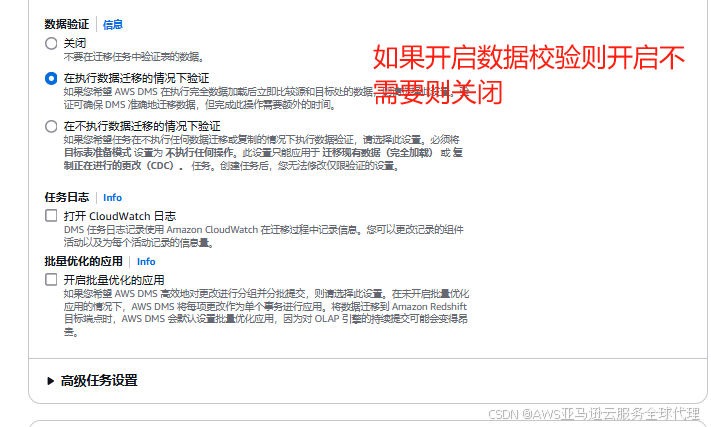
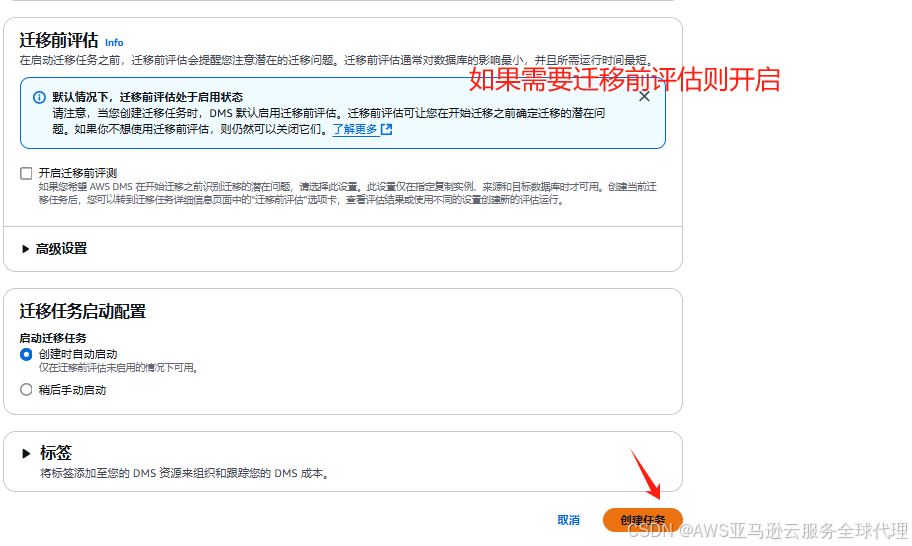

然后我们就开启了无限期的增量迁移任务
我在源数据库插入数据
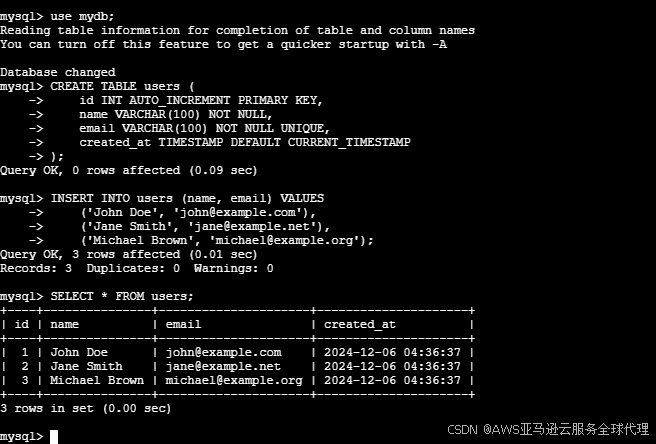
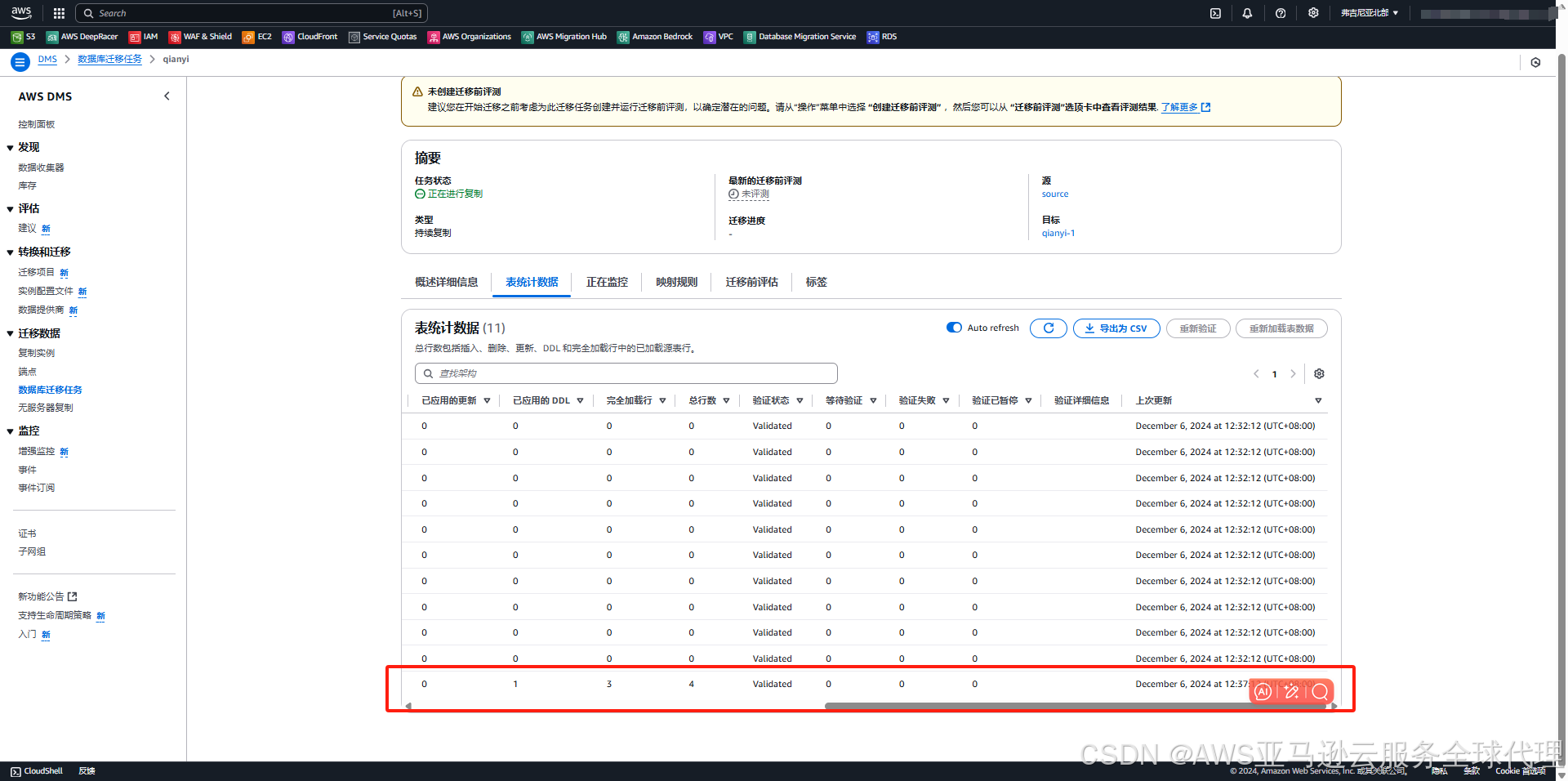
然后我们就完成了增量迁移
mydump er导出 & myloader导入
在开始之前,需要确保已经安装了 mydumper 和 myloader 工具,并且可以连接到源 MySQL 数据库和目标 OceanBase 数据库。
mydumper导出
mydumper 是一款开源的 MySQL 逻辑备份工具,主要由 C 语言编写。与 MySQL 自带的 mysqldump 类似,但是 mydumper 更快更高效。
mydumper 的一些优点特性:
轻量级C语言开发
支持多线程备份数据,备份后按表生成多个备份文件
支持事务性和非事务性表一致性备份
支持将导出的文件压缩,节约空间
支持多线程恢复
支持已守护进程模式工作,定时快照和连续二进制日志
支持按指定大小将备份文件切割
数据与建表语句分离
下载安装:
ubuntu自带myloader
apt-get install mydumper -y常用案例:
# 备份全部数据库
mydumper -u root -p 123456 -o /home/mydumper/data/all/# 备份全部数据库,排除系统库,
mydumper -u root -p 123456 --regex '^(?!(mysql|sys|performance_schema|information_schema))' -o /home/mydumper/data/all/使用mydumper进行全量备份时,可以通过查看mydumper生成的元数据文件来获取最新的binlog位置和时间戳信息。具体步骤如下:
mydumper -h hostname -u username -p'password' -B databasename -o /path/to/output
在备份输出目录下,会生成一个metadata文件,例如:
/path/to/output/metadata
打开这个metadata文件,查找"SHOW MASTER STATUS"部分,内容类似如下:
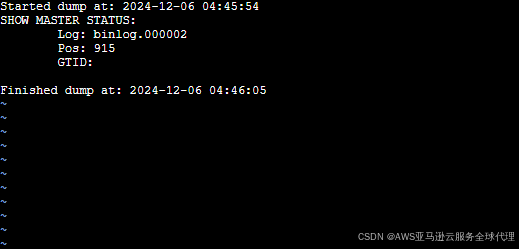
记住Finished后面的时间戳即可,增量需要用到
myloader导入
# 从备份中恢复指定库
myloader -u root -p 123456 -s db1 -o -d /home/mydumper/data/all/0/之后增量参考使用DMS进行增量迁移


















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









