






2025.3.4
再跑cic网站的爬虫Index of /,想把所有目录的文件统计一下大小但遇到几个问题,可见下面的prompt
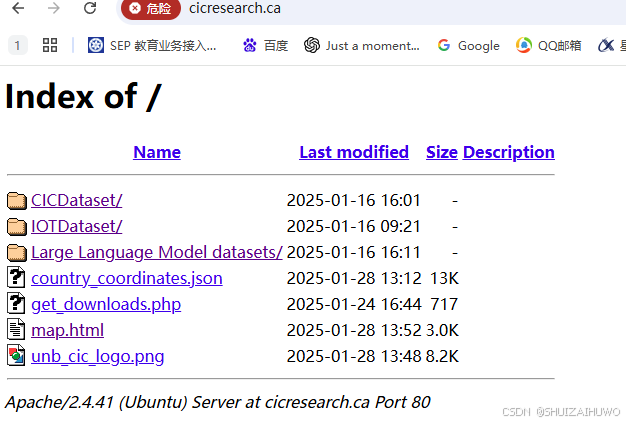
我现在想把这个网站上的所有文件夹里的数据都统计一遍大小,但是手动操作比较慢,http://cicresearch.ca/,请注意:1.这个网站的http://cicresearch.ca/CICDataset/和http://cicresearch.ca/IOTDataset/两个二级目录,由二级目录到三级目录时要填写表单,但可以通过在三级目录后加上/Dataset,跳过表单,直接进入三级目录(由于三级目录后已加上/Dataset,故每个三级目录对应一个四级目录)2.这个网站在进入http://cicresearch.ca/Large%20Language%20Model%20datasets/这个二级目录时,也需要同样的操作,如http://cicresearch.ca/Large%20Language%20Model%20datasets/Dataset才可正常访问这个目录,请你写一个爬虫脚本,把每个文件的大小和地址、上传时间等元素,通过json格式给我,并统计总大小
把claude的代码经过修改后确实可以了。下面开始读代码,记录一些python用法:
1.quote用来将字符串转换为适合在 URL 中使用的格式 ,比如把%20替换成空格,来自url.parser库,这里的.replace(" ", "%20")可以去掉,是多余的
def should_add_dataset_suffix(self, url):
"""判断是否需要添加Dataset后缀"""
for special_dir in self.special_dirs:
if special_dir in url:
# 如果是二级目录,直接添加Dataset
if url.rstrip('/') == self.base_url + quote(special_dir).replace(" ", "%20"):
return True
# 如果是三级目录,也添加Dataset
parts = url.rstrip('/').split('/')
if len(parts) > 4 and special_dir in parts[3]:
# 确保不是已经有Dataset的URL
if not url.endswith('/Dataset/') and 'Dataset' not in url.split('/')[-8:]:
return True
return False2.判断三级子目录时,为什么len(parts)>4就说是三级目录呢:若len(parts)为5,那么此时对应的目录就成为:http://cicresearch.ca/part1/part2/,正好是三级目录。这里要注意,两个相邻的/会被切出一个空字符串,但也占一个长度。
url="http://cicresearch.ca/part1/part2/part3"
parts=url.rstrip('/').split('/')
print(parts)
输出:
['http:', '', 'cicresearch.ca', 'part1', 'part2', 'part3']3.
if not url.endswith('/Dataset/') and 'Dataset' not in url.split('/')这段代码有点意思 ,首先,not的优先级比and高,所以先判断两个条件
其次,not的位置可变,上面代码等价于下面的代码
if not url.endswith('/Dataset/') and not 'Dataset' in url.split('/')2025.3.5
def parse_apache_directory(self, url, html):
"""解析Apache目录列表"""
soup = BeautifulSoup(html, 'html.parser')
items = []
# 查找表格 - Apache目录列表通常使用表格布局
table = soup.find('table')
if table:
rows = table.find_all('tr')
print(f"发现table,有 {len(rows) - 3} 个项目")
# 跳过标题行
for row in rows[1:]:
cells = row.find_all(['td', 'th'])
if len(cells) < 3:
continue
# 获取名称、最后修改时间和大小
name_cell = cells[1]
date_cell = cells[2]
size_cell = cells[3]
link = name_cell.find('a')
if not link:
continue
name = link.text.strip()
if name == "Parent Directory" or name == "..":
continue
href = link.get('href')
full_url = urljoin(url, href)
is_dir = href.endswith('/')
last_modified = date_cell.text.strip()
size_text = size_cell.text.strip()
size_bytes = 0 if is_dir else self.parse_size(size_text)
item = {
"name": name,
"url": full_url,
"is_directory": is_dir,
"last_modified": last_modified,
"size_text": size_text if not is_dir else "-",
"size_bytes": size_bytes
}
items.append(item)
return items1.这里进入了解析html的部分,先解析apache的 表格布局,用soup.find()先找出table,再找出每行元素rows,标识符为'tr',项目应该有tr数量减三个,因为table上下各有一条横线,占2个tr,上面还有标题栏,占一个tr。
ps:刚才发现无论怎么算,代码运行出来都多一个tr,后来刷新了网页,发现网页更新了,网站多加了一个html文件...
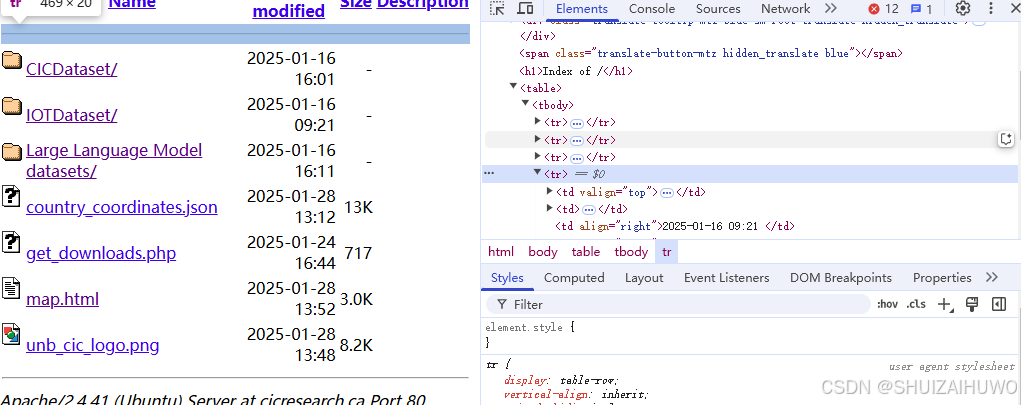
2.开始找td、th标签,
td代表 "table data"(表格数据)。th代表 "table header"(表格头部)。
过滤掉那些单元格数量少于 3 个的行,通常这些行不包含有效数据
cell[0]是图标,cell[1]是名称,cell[2]是日期,cell[3]是大小
有'a'标签代表是一个超链接,可点击跳转。若不是超链接,就退出循环
# 获取名称、最后修改时间和大小
name_cell = cells[1]
date_cell = cells[2]
size_cell = cells[3]
link = name_cell.find('a')
if not link:
continue
name = link.text.strip()
if name == "Parent Directory" or name == "..":
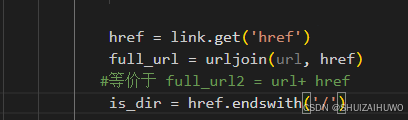
continuelink.text会去掉a标签的内容,只保留文本部分
link.get('href)获取下一级的链接,拼上就是完整的连接了
判断是不是文件夹,只需要看末尾有没有/
3.response是获取get方法的响应
try:
# 添加随机延迟避免请求过快
time.sleep(random.uniform(0.1, 0.3))
response = requests.get(url, headers=self.headers, timeout=30)
if response.status_code == 404:
print(f"页面不存在: {url}")
return
response.raise_for_status()#来判断请求是否成功,如果成功则继续执行,否则抛出异常
# 检查是否是Apache目录列表
if "Index of" in response.text and "Apache" in response.text:
items = self.parse_apache_directory(url, response.text)
for item in items:
if item["is_directory"]:
# 递归爬取子目录
self.crawl_directory(item["url"])
else:
# 添加文件到结果
self.results["files"].append(item)
self.results["total_size_bytes"] += item["size_bytes"]
print(f"发现文件: {item['name']} - {item['size_text']}")
else:
# 不是Apache目录列表,尝试从HTML中提取链接
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.find_all('a')对于每个item,如果是目录的话,就用当前item的url继续递归,深度优先遍历

















 1177
1177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









