



顺丰科技自从2024年1月采用Apache Gluten + Velox用于加速Spark查询以来,取得了较好的效果。目前上线1.6万多的Gluten任务,节省了超过10000 cpu cores资源,Gluten性能相比于原生的Spark提高了50%以上,算子回退率下降到了20%左右。Intel团队在Gluten编译,上线,优化过程中提供了大力帮助,支持了columnar shuffle,whole stage fallback,动态内存调整功能的上线和应用。目前Gluten任务主要跑在部署Intel芯片的机器上,并在此环境下观察到了显著的性能提升。本文重点介绍Gluten的原理,Gluten在顺丰的应用,Gluten的最佳实践,还有未来工作计划。
一、Apache Gluten原理介绍
Apache Spark是一款非常成熟稳定的计算引擎,在大数据行业被应用了数十年,处理PB级别数据,可扩展性,伸缩性好。然而随着时间的推移,Spark这款以Scala语言开发的引擎,不断面临性能瓶颈。Spark 2.0 采用Whole Stage Code Generation代替火山模型,在Query Plan层面实现了2倍多的性能提升。然而单个算子的性能提升几乎停滞。
这些年来随着native engine,例如Clickhouse/Arrow/Velox引擎的推出,给Spark性能提升带来了曙光。这类native engine,可以实现本地执行,列式数据格式,向量化能力,远胜于Spark基于JVM执行的性能。
Gluten就是在这种情况下诞生的。Gluten设计目标就是将Spark单个算子的执行卸载到native engine上面,即保持了Spark本身的高扩展性,同时享受native engine带来的性能提升。
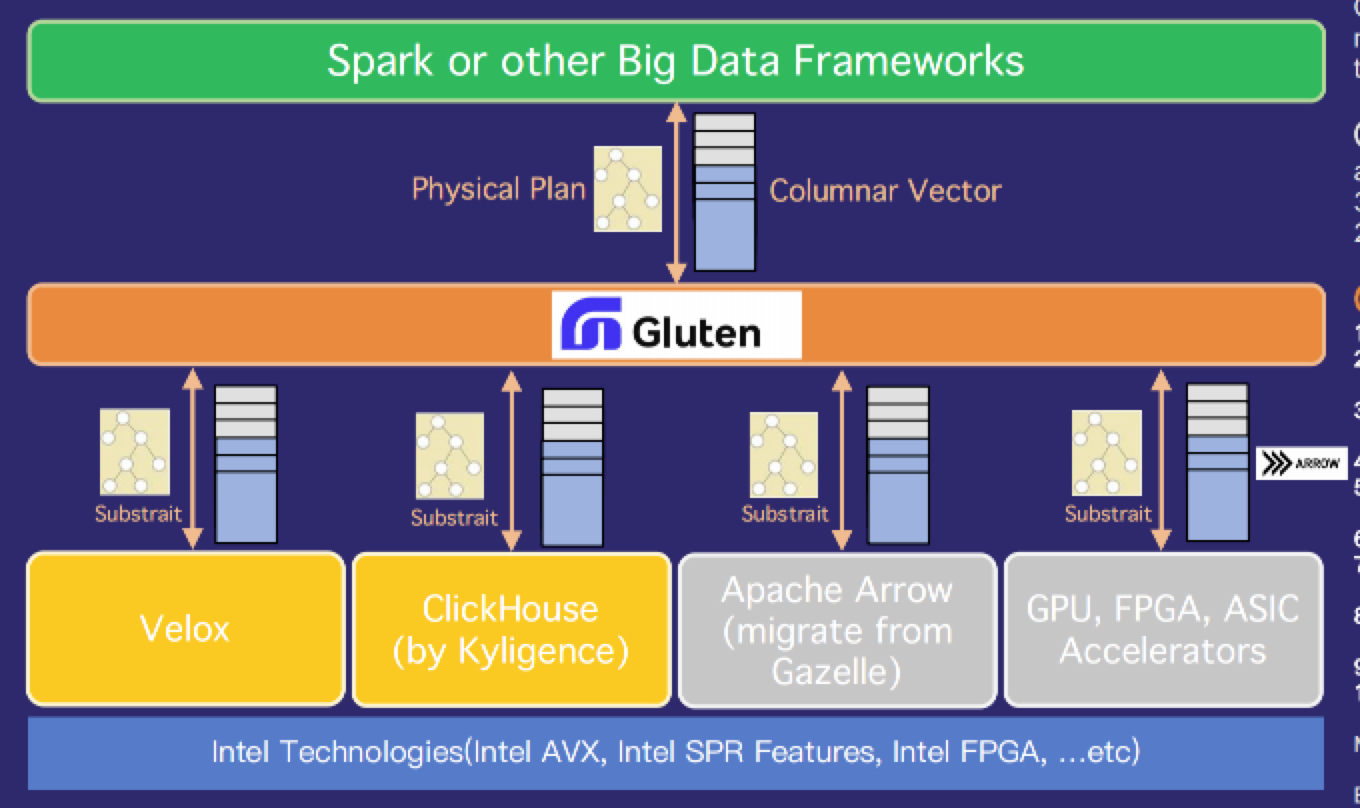
图1Gluten的架构,Gluten以插件的方式将多个规则注入到Spark中。将Spark的物理计划转成Substrait表示的计划,Substrait是一款跨语言的计算表达式。然后通过JNI调用将Substrait Plan传递给native engine。native engine收到Substrait Plan后,执行并返回Columnar Batch给Spark。目前支持的native engine主要有Velox和ClickHouse,顺丰科技目前采用Velox作为native engine。除了查询计划的转换之外,Gluten还负责内存管理,fallback管理,Spark多版本的支持等。从TPC-H测试来看,相比于原生的Spark,性能提升2-14倍。
二、Apache Gluten在顺丰的应用
Apache Gluten于2024年01月份被引入顺丰,已经从1.1.1版本升级到1.2.0版本。结合目前的离线架构情况,我们针对Gluten发展了一套专门的系统,包括挑选任务,模拟,上线,下线等。
1、Gluten任务在顺丰的生命周期
针对Gluten任务的特点,我们设计了一套高效自动化的任务管理流程,让Gluten上线下线快捷发方便。首先介绍下Gluten任务在顺丰的生命周期。在一开始,我们会从70多万离线任务中(包括Hive/Spark)挑选符合标准的任务,作为转成Gluten任务的潜在候选者。挑选的标准为最近7天平均执行时间vcore-seconds超过10000,之所以这么选择是因为我们认为只有耗时比较长的任务才有转成Gluten的价值。对于耗时较短的小任务,由于Gluten本身存在算子转换的开销,可能造成性能损失超过了native engine带来的性能提升。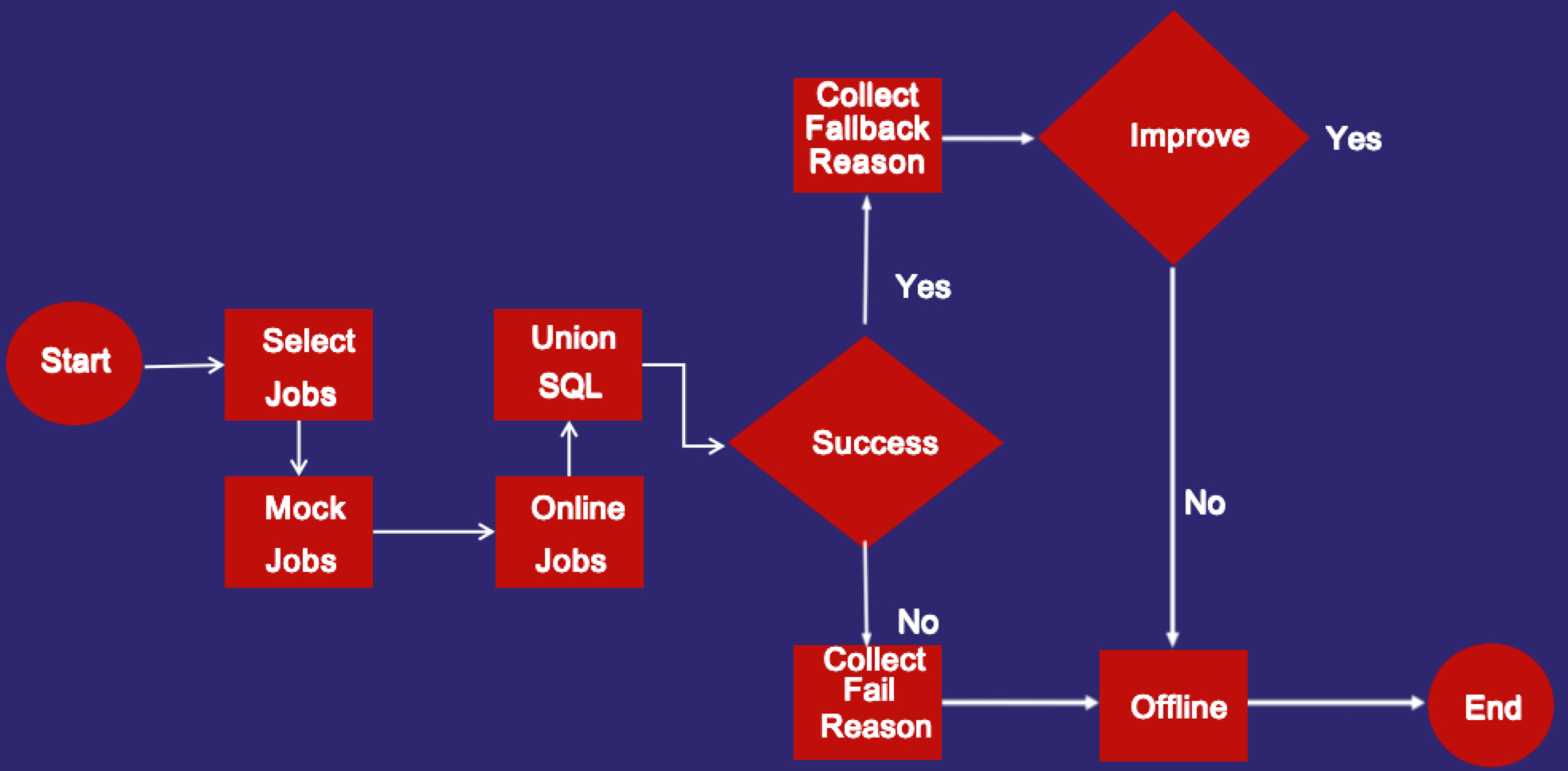
图2 Gluten任务生命周期
任务挑选出来后,再通过统一SQL对SQL进行兼容性处理。由于Gluten基于Spark引擎开发,从Hive任务转Gluten任务,部分任务存在语法差异。统一SQL模块负责对这种语法进行处理,让用户透明无感知。接着进行模拟。模拟就是针对这个任务,进行双跑实验。一个跑原生的Hive/Spark引擎,另外一个跑Gluten引擎。实验跑完后,对比结果,只有数据正确并且数据一致才达到上线标准。然后对模拟成功的任务进行上线,上线会走灰度系统。灰度系统根据配置决定一个任务应该以什么样的方式运行,运行在哪个引擎上。由于内部的离线引擎较多,Hive/Spark/Presto/Gluten等。需要通过灰度系统管理起来。之后以Gluten任务运行起来,任务跑完后,如果成功会收集算子回退原因以供后续进一步分析,如果运行失败,分析失败原因并及时下线,后续再考虑上线。
2、Gluten任务管理架构
从Gluten任务等生命周期可以看出来,我们设计的Gluten任务管理框架如图3,包含4个主要模块。模拟系统,负责Gluten任务的模拟,确保Gluten任务上线后数据正确性和一致性。统一SQL,负责各大引擎的语法兼容,确保这些任务转到Gluten之后能够透明无感知。Fallback管理,负责Gluten任务一旦失败,能够快速地切换到其他引擎执行,确保最终能够跑成功,作为兜底机制,用户无感知。灰度系统负责通过配置等方式决定任务以什么参数运行,以及运行在哪个引擎上。下面章节详解介绍每个模块的功能。
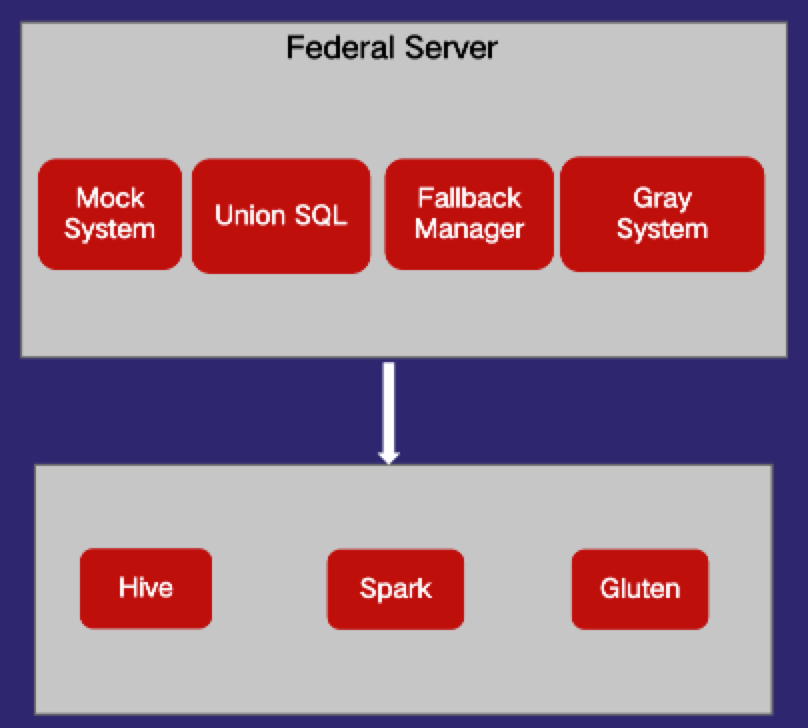
图3 Gluten任务管理框架
3、模拟系统
为了保障任务从Hive/Spark平滑转换到Gluten,并且数据正确和一致,我们设计了模拟系统模拟系统负责在上线Gluten前进行模拟,确保任务跑完后等数据正确性和一致性。首先从调度系统拿到任务的原始SQL语句,然后对这些SQL进行改写,主要是为了隔离生产环境和测试环境。以占大部分的ETL任务为例,SQL主要是insert into xxx select xxx from xxx的形式。这里的改写主要是隔离生产环境和测试环境的catalog,将模拟执行的结果写入到测试环境中。SQL改写完成后,分别运行在Gluten引擎和其他原生引擎上面。双跑结束后,再执行结果对比,主要求两张结果表的差集,检验数据行数是否一致,每一行数据是否一致。接下来生成报告,报告展示哪些任务跑失败了,哪些出现数据不一致,哪些跑成功了,方便后续进一步分析。只要那些跑成功并且数据一致的任务才达到上线标准。
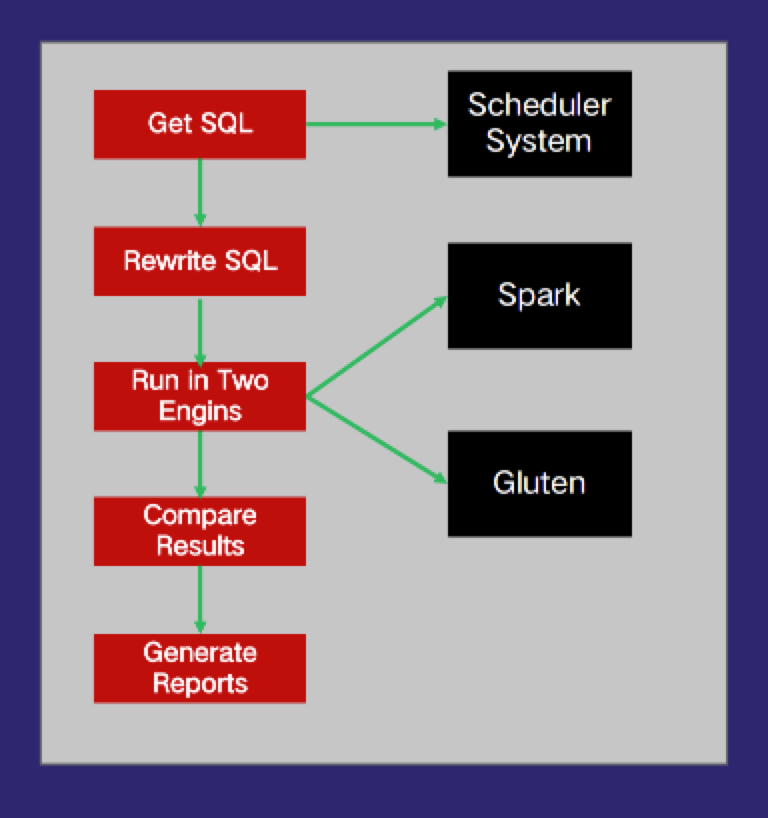
图4 模拟系统
4、统一SQL
由于顺丰内部离线引擎较多,例如Hive,Spark,Presto,Doris,Clickhouse,Gluten等,各个引擎的语法又不完全一致。对于用户来说,学习成本很高,使用难度大。针对这类问题我们设计了统一SQL系统解决此类问题,一条SQL可以透明跑在多种引擎上,用户只需掌握标准的SQL语法即可,由统一SQL负责屏蔽各大引擎的语法差异。在这里主要将Hive任务透明地转到Spark,再转到Gluten,用户全程无感知,而性能不断提升。统一SQL通过Calcite实现,在语法解析,语义校验,逻辑计划,物理计划阶段添加定制规则,实现不同引擎的语法兼容,然后生成对应引擎的代码,最后提交到对应的引擎上执行。
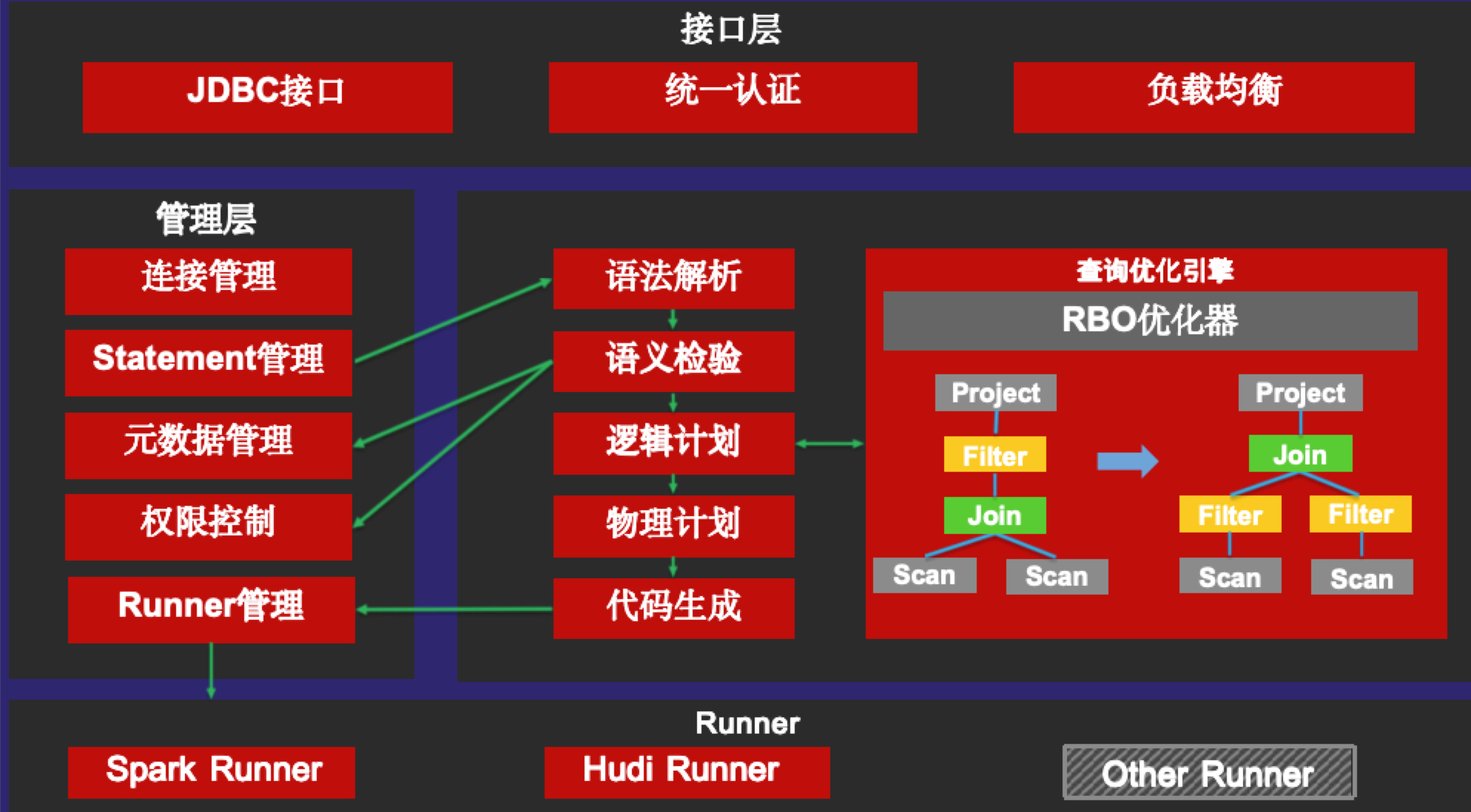
图5 统一SQL架构图
5、Fallback管理
这里的Fallback机制不同于Gluten自带的Fallback策略。这里的Fallback机制是一种兜底机制。由于Gluten上线后,遇到不可抗力因素导致运行失败,需要快速容错措施,确保最终能跑成功任务,用户无感知,为此我们设计了Fallback任务回退机制。Fallback管理在发现Gluten任务跑失败后,如果该任务原生是Hive任务,立即切换到Hive引擎上执行;如果原生是Spark任务,就切换到Spark引擎上执行,如图6所示。这种做法假设前提是这些任务从Hive或者Spark转换而来,那么之前他们都是能跑成功的,所以退回到原生的引擎也是能够跑成功的。Gluten在顺丰内部的定位是Spark加速器,那么这个加速器跑失败也不应该影响最终结果的成功。Fallback管理正是基于这一理念而设置。
图6 Fallback管理
6、灰度系统
由于顺丰内部有很多离线引擎,例如Hive,Spark,Presto,Clickhouse,Doris,同时一个任务在不同时间可能处于不同的状态,比如一开始他是Hive任务,后面变成了Spark任务,后面又变成了Gluten任务。任务还是那个任务,但是可能在不同时间段,需要用不同的引擎执行。为此我们设计了灰度系统就是负责通过配置的方式,决定任务用什么参数运行,跑在哪种引擎上。任务提交到调度系统后,会向灰度系统询问是否需要灰度,然后拉取对应的配置,配置包含了用什么引擎,以及运行的参数,然后通过统一SQL做语法的兼容,最后提交到对应的引擎上去执行,最后返回结果。灰度系统的最大作用,可以通过配置的方式,将一个任务透明地从Hive转到Spark再转到Gluten。除此之外,上线Gluten,下线Gluten,加入黑名单都是通过这个系统实现的。
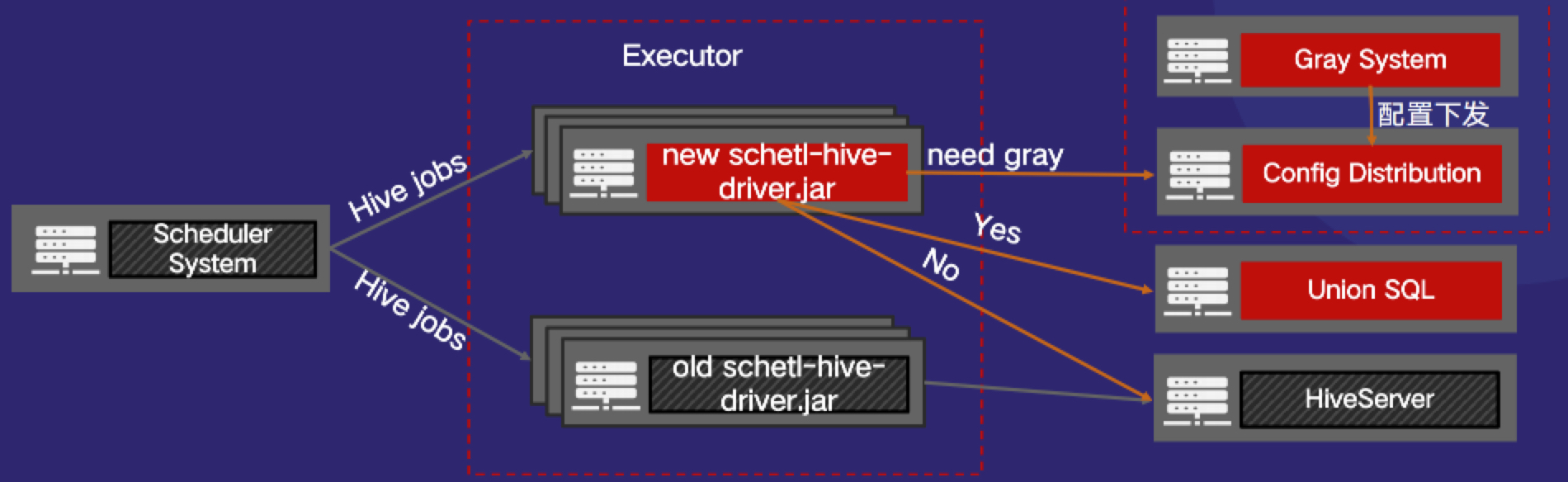
图7 灰度系统
三、Apache Gluten最佳实践
1、Gluten在顺丰科技的性能
自从2025年3月上线以来,随着Whole Stage Fallback策略,动态内存调整功能,Columnar ShuffleGluten的应用,性能不断取得突破,从节省3000多cu到节省10000多cu。CPU ratio(Gluten vcore-seconds / 原生spark vcore-seconds)达到50%。目前每天运行的Gluten任务大概有16000个。
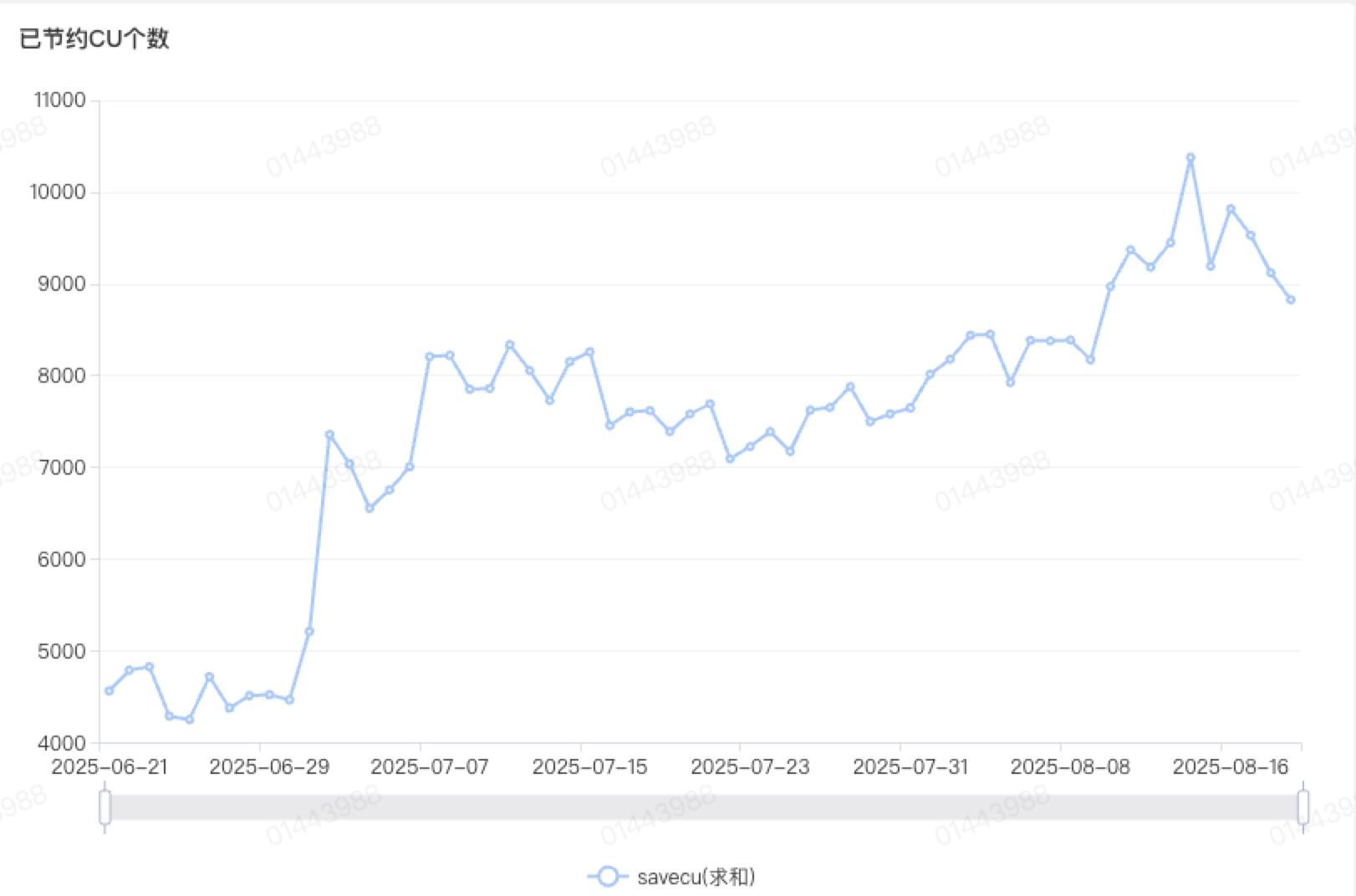
图8 Gluten节省CU数量
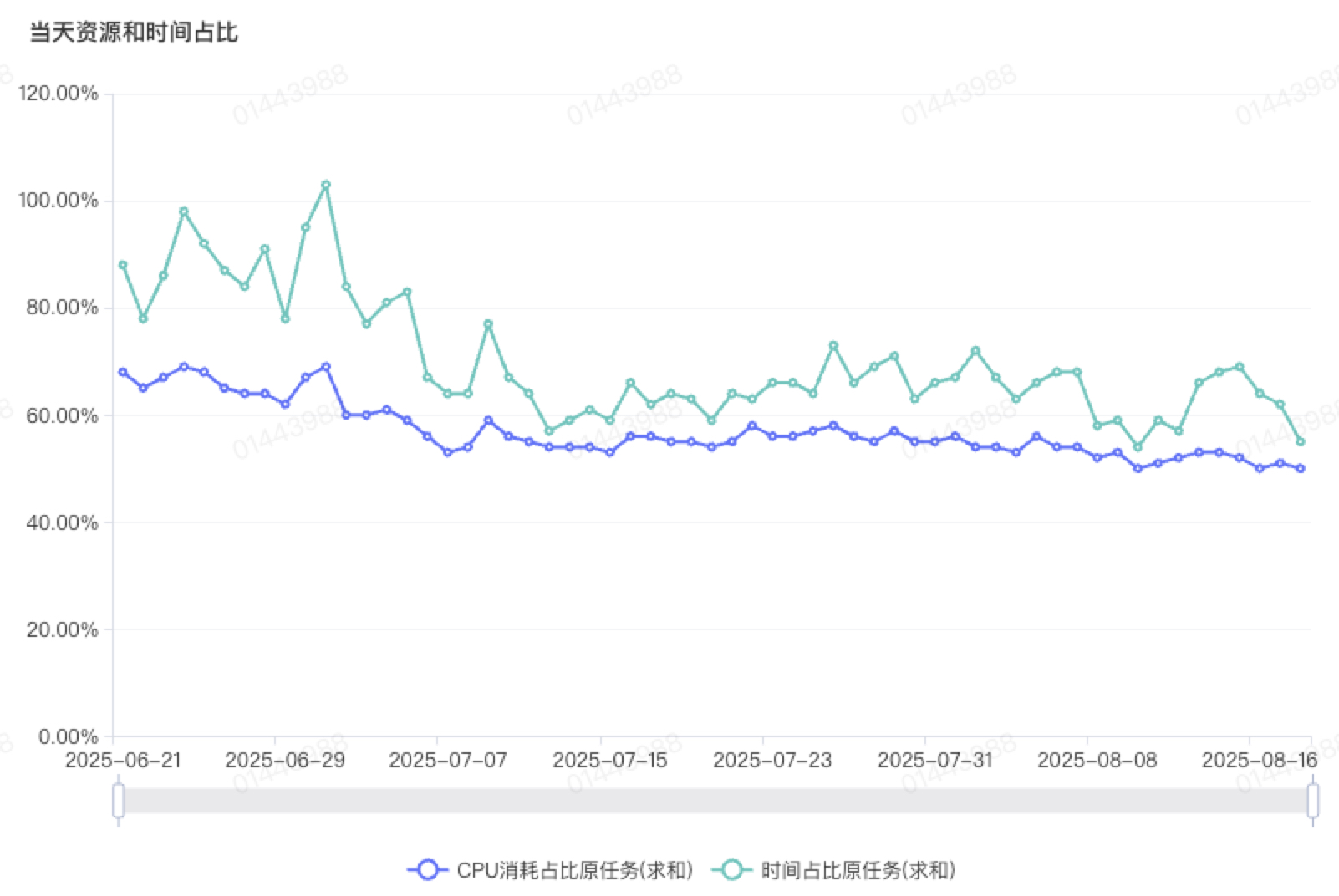
图9 Gluten耗时占原生Spark耗时比例
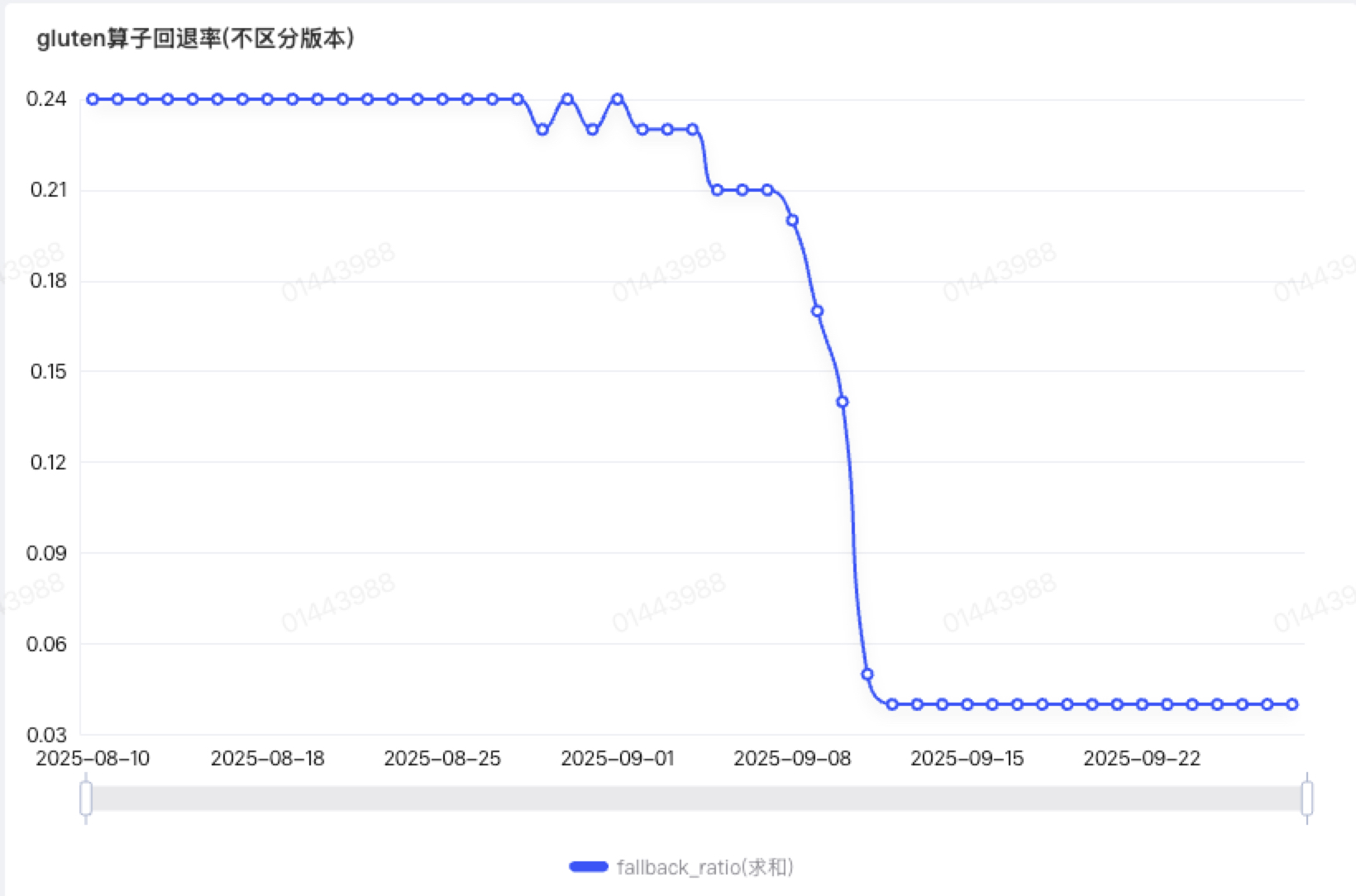
图10 gluten算子回退率
2、Whole Stage Fallback 策略
Gluten优先尝试将算子从Spark转化到native engine,如果某个算子不支持,就会回退到原生的spark算子上去,如图10所示。同时Gluten也会将多个算子组合到一起形成WholeStageTransformer,作为一整个Substarit plan交给native engine执行。由于目前Gluten对部分Spark算子不支持,一个Query plan中会同时存在Gluten算子和Spark算子,两种算子之间通过增加C2R或者R2C算子进行数据行列转换。这会导致一个问题,如果一个Stage里面回退算子较多,就会存在多个C2R和R2C算子,意味着数据在行列之间进行多次转换,这样就会导致性能下降。所以一个朴素的想法是,如果一个Stage里面有太多的算子回退,不如将整个stage都回退了,这样起码性能可以跟原生Spark保持一致,不会下滑。
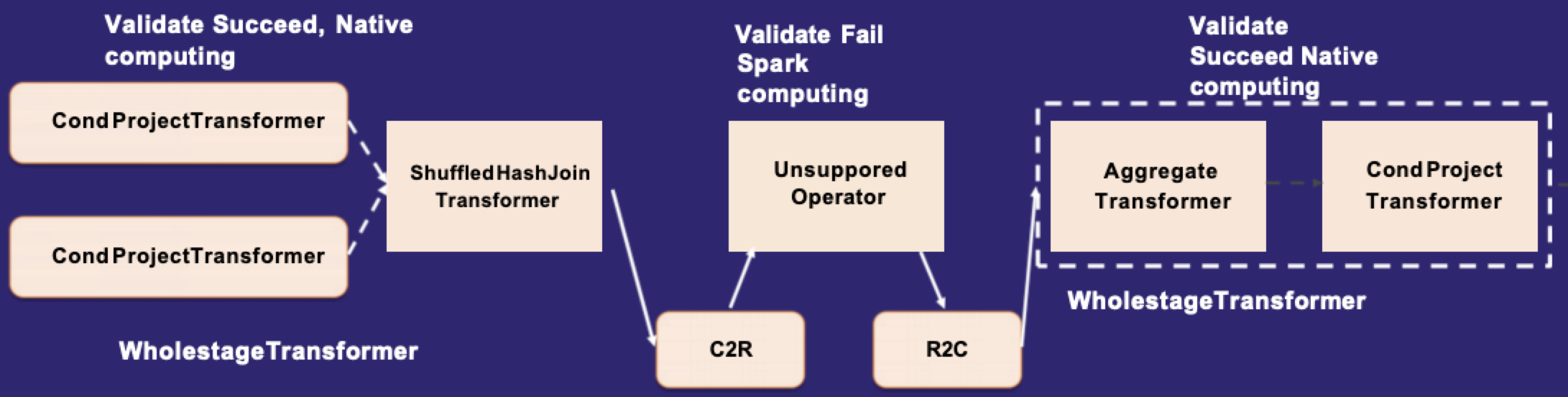
图11 Gluten Fallback机制
这就是Whole Stage Fallback策略诞生的背景。Whole Stage Fallback策略可以指定当一个Stage里面出现超过多少个回退的算子就将整个stage回退到原生Spark中执行。最开始我们应用这个策略设置阈值为1,却取得了比较差的效果。算子回退率从20%上升到了50%,性能下降了1倍。后面分析原因,发现这个策略虽然很好,但是内存如果配置不恰当,可能引起性能下降。在顺丰内部,on-heap配置1G内存,off-heap配置7G内存,还有1G配置overhead memory。这就导致算子回退到原生spark算子,可用的内存只有1G,导致频繁的GC甚至失败,性能由此下降。综合考虑后,我们决定内存配置维持不变,Whole Stage Fallback阈值设置为-1,也就是用最多的内存支持Gluten算子的计算,同时让更多算子尽量往Gluten上面转。这样配置后,性能提升了1倍,算子回退率下降到了20%左右。对于那种一个stage里面有多个算子回退的场景,我们设置Whole Stage Fallback阈值为1,并结合下面讲的动态内存调整来解决。
除此之外,Gluten还有一个Query level fallback策略。当整个query回退的算子超过阈值时,整个query的所有算子都会退到原生的Spark算子,也是为了确保整个查询的性能不比原生的Spark低。
3、动态内存调整
一个Gluten查询计划可能包含多个Spark算子和native engine算子,Spark算子执行使用的JVM管理的on-heap内存,native engine算子则使用off-heap内存,如图11所示。为了统一管理这些内存,Gluten创建了一个memory pool,用来管理native engine内存,如果memory pool内存不够,则向Spark task memory申请。当task memory不够时,则会触发spill机制。但是目前on-heap内存和off-heap内存都是通过配置固定设置,不能在运行时改变。每个任务的算子回退率不一样,无法一套配置满足所有的任务。对于顺丰内部on-heap : off-heap = 1 : 7的配置,在算子回退较多的场景,会导致Spark算子没有足够的内存使用。
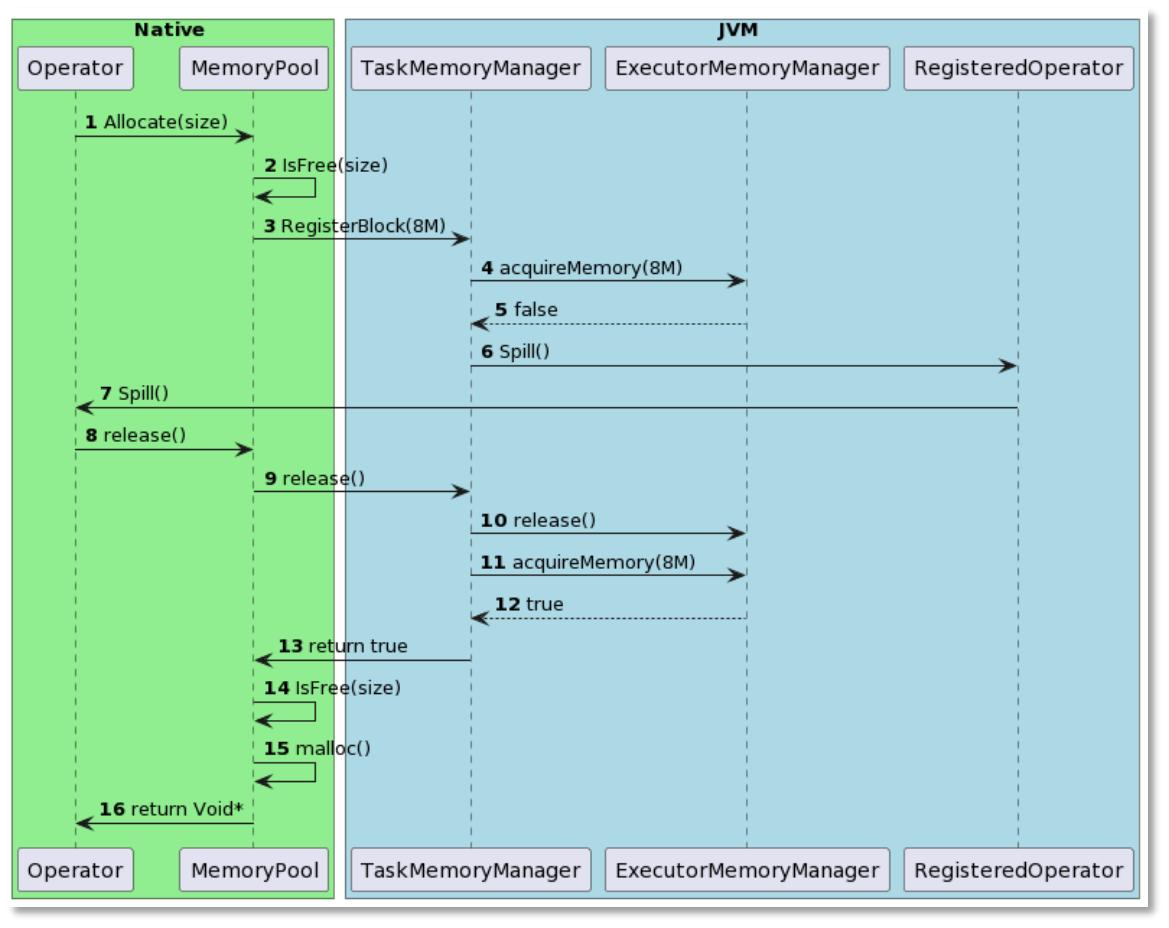
图12 Gluten内存管理机制
我们巧妙的运用动态内存调整这个功能解决此类问题。动态内存调整会在生成query时,计算一个stage内部算子回退的情况,如果回退较多,就会把off-heap内存减少,on-heap内存增多,总内存保持不变。如果算子100%会退了,那么就会把大部分off-heap内存挪给on-heap用。这样根据算子回退率,平衡on-heap/off-heap内存,可以有效解决算子回退时的内存分配问题,保障一个最佳的性能。如图12动态内存调整功能利用ApplyResourceProfile来实现对stage资源的调整。
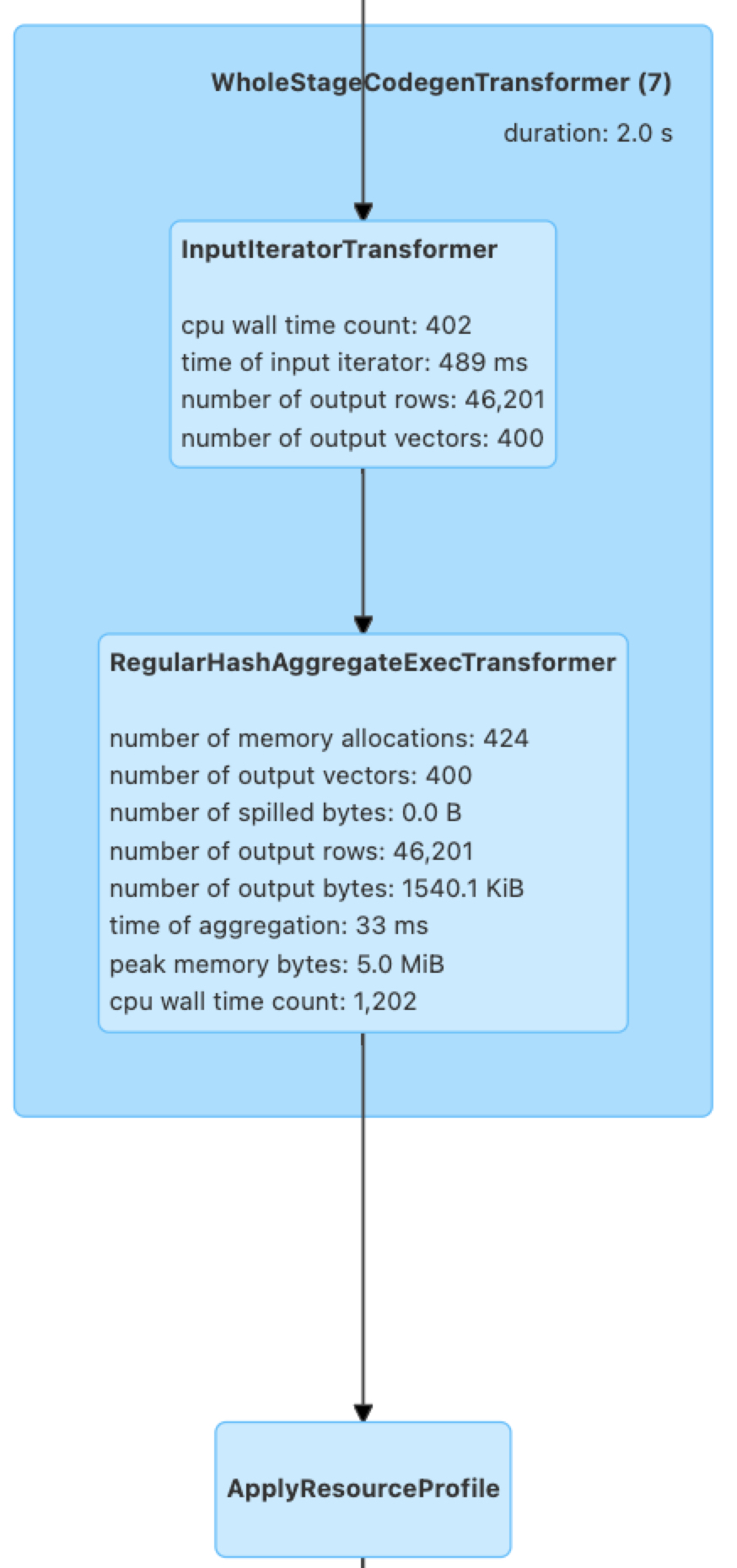
图13 动态内存调整生成的Query Plan
4、Columnar Shuffle功能
Gluten背后的native engine Velox和Clickhouse都是基于列式的引擎,数据读出来天然是列式的,然而Spark的shuffle都是基于行式的,这就需要一个C2R算子进行转换。除此之外,列式在数据压缩,减少IO读放大,向量化执行具备很大优势,所以基于列式的shuffle更适合Gluten的计算场景。Gluten复用了Gazelle的Columnar Shuffle实现,支持split, spill,compress,serialization,merge files等特性,同时还支持结合RSS(Uniffle和Celeborn)使用,性能远超过Spark的行式Shuffle,如图13所示。图15是基于行式的Shuffle,会多一个C2R算子,图16是基于列式的Shuffle。
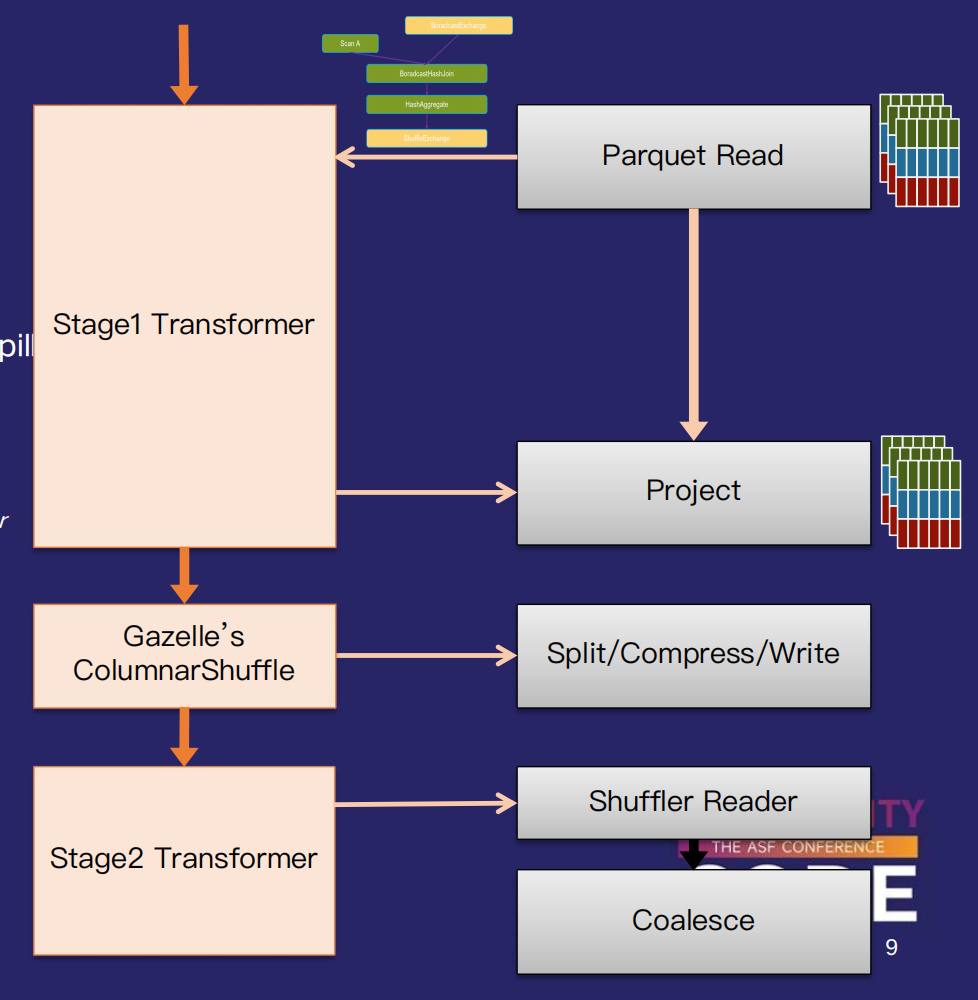
图14 Columnar Shuffle

图16 基于列式Shuffle的Query Plan
四、Apache Gluten未来工作
1、Gluten支持Flink任务
目前Gluten主要支持Spark算子的native,而Flink在流式计算领域具有广泛的影响。Flink也面临着性能瓶颈,算子性能受限于Java语言,无法进一步提升。Gluten从2025年开始探索支持Flink,将Flink算子卸载到Velox/ClickHouse等引擎上。预计到2025年年底会发布第一个版本。Flink在顺丰内部也得到广泛的运用,我们目前也在积极参与Gluten支持Flink的研发工作,期待未来将Flink的性能提升2倍以上,带来更多资源的节省。
2、回退率进一步下降
在顺丰内部,目前Gluten还有20%左右的回退率,主要原因是部分算子还不支持,部分函数不支持,还有复杂数据类型不支持,例如array/map/struct。这些导致Gluten算子回退到Spark算子,性能没有得到提升。未来Gluten进一步支持这些算子和函数,提升性能。并且在支持算子和函数的同时,确保性能得到提升。
3、支持TextFile表
Gluten目前支持的主要是parquet/ORC/AVRO等列式的表,方便Velox/ClickHouse引擎的向量化计算。但是顺丰内部也有不少TextFile表,Gluten在读出TextFile表后需要一个R2C算子转成列式数据,再交给Velox/ClickHouse进一步计算。这个过程C2R带来了数据转换的开销,以及行式存储不利于谓词下推和读放大等问题,都会带来性能下降。Gluten目前遇到TextFile表都是直接回退到Spark算子。一种解决办法是推动用户将TextFile表转成Parquet表,另外一种方法是Gluten直接支持TextFile表的读写。

















 1172
1172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









