




SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS ICLR2016
首先介绍下session-based 的概念:session是服务器端用来记录识别用户的一种机制. 典型的场景比如购物车,服务端为特定的对象创建了特定的Session,用于标识这个对象,并且跟踪用户的浏览点击行为。我们这里可以将其理解为具有时序关系的一些记录序列。
一、写作动机
传统的两类推荐方法——基于内容的推荐算法和协同过滤推荐算法(model-based、memory-based)在刻画序列数据中存在缺陷:每个item相互独立,不能建模session中item的连续偏好信息。
二、传统的解决方法
- item-to-item recommendation approach (Sarwar et al.,2001; Linden et al., 2003) : 采用session中item间的相似性预测下一个item。缺点:只考虑了最后一次的click 的item相似性, 忽视了前面的的clicks, 没有考虑整个序列信息。
- Markov decision Processes (MDPs)(Shani et al., 2002):马尔科夫决策过程,用四元组<S,A, P, R>(S: 状态, A: 动作, P: 转移概率, R: 奖励函数)刻画序列信息,通过状态转移概率的计算点击下一个动作:即点击item的概率。缺点:状态的数量巨大,会随问题维度指数增加。
三、Deep Neural Network的方法
本文的贡献在于首次将RNN运用于Session-based Recommendation,针对该任务设计了RNN的训练、评估方法及ranking loss。
Motivation(Why): 第一篇提出将RNN 应用到session-based recommendation 的论文。
Main Idea(What): 一个session 中点击 item 的行为看做一个序列,用GRU来刻画。
How:
1.系统架构
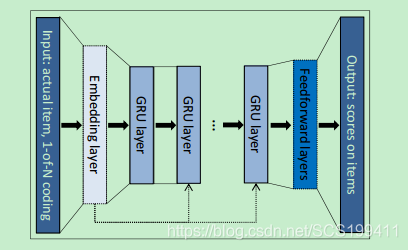
GRU:
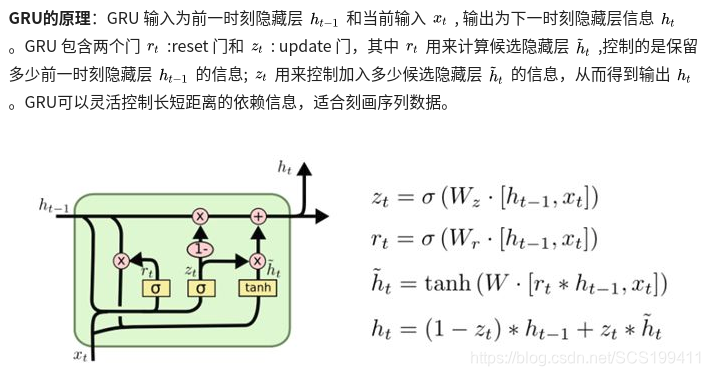
2. 训练策略
为了提高训练的效率,文章采用两种策略来加快简化训练代价,分别为:
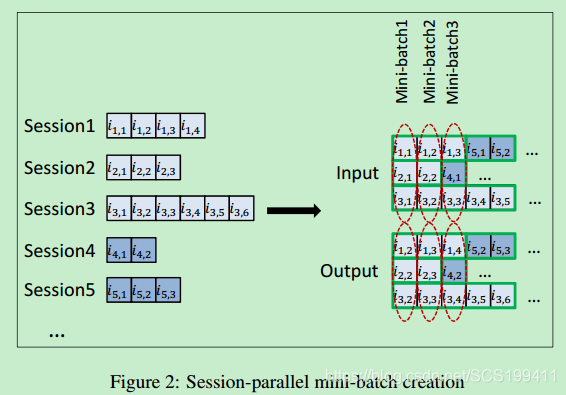
Training strategy: 为了更好的并行计算,论文采用了mini-batch的处理,即把不同的session拼接起来,同一个sequence遇到下一个Session时,要注意将GRU 中的一些向量重新初化。
Training data sample:因为item的维度非常高,item数量过大的概率会导致计算量庞大,所以只选取当前的正样本(即下一个点击的item)加上随机抽取的负样本。论文采用了取巧的方法来减少采样需要的计算量,即选取了同一个mini-batch 中其他sequence下一个点击的item作为负样本,用这些正负样本来训练整个神经网络。
3. 损失函数
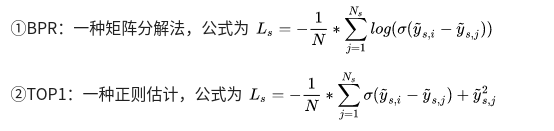
4. 数据集
RecSys Challenge 2015:网站点击流
Youtube-like OTT video service platform Collection
5. 评价指标
recall@20 :即在所有测试案例中前20个物品中具有所需物品的案例比例。
MRR :期望物品的评分的平均值
6. baseline
POP:推荐训练集中最受欢迎的item;
S-POP:推荐当前session中最受欢迎的item;
Item-KNN:推荐与实际item相似的item,相似度被定义为session向量之间的余弦相似度
BPR-MF:一种矩阵分解法,新会话的特征向量为其内的item的特征向量的平均,把它作为用户特征向量。
7. 实验结果
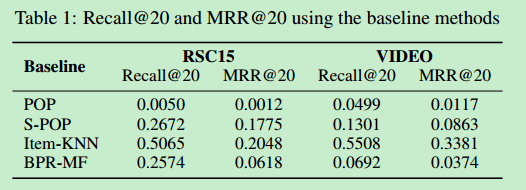
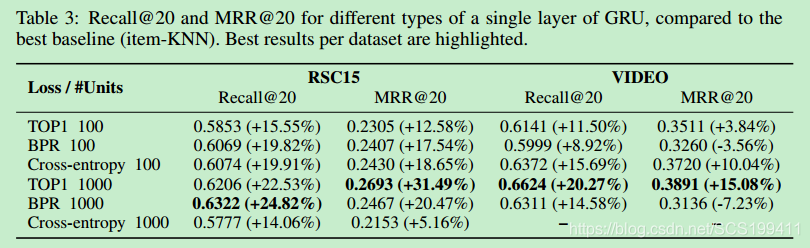
结果表明:
- 使用item embeding没什么用,因此还是用one-hot encoding
- 在GRU层后面使用全连接层对于结果帮助不大,不过增加GRU层的数量会提高模型的表现
- GRU比RNN和LSTM效果更好
- adagrad优化器以及隐层节点数量100

















 1367
1367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









