




 本文介绍如何使用torchtext 0.12版本进行数据加载,包括词表构建、数据集准备及使用DataLoader进行数据装载的过程。
本文介绍如何使用torchtext 0.12版本进行数据加载,包括词表构建、数据集准备及使用DataLoader进行数据装载的过程。
前言
蛮久前写过一篇torchtext加载数据,不过官方不久前升级了torchtext,移除了蛮多东西。数据加载也和之前不一样了。
看官方文档,似乎更推荐用torchdata装载数据,不过本文还是先用dataset做。
由于现在网上都没什么新版本教程,一个人看文档摸索的,有错请谅解
……
数据集准备
数据集随意,选用了自己常用的数据集作为例子。基本就如图所示:
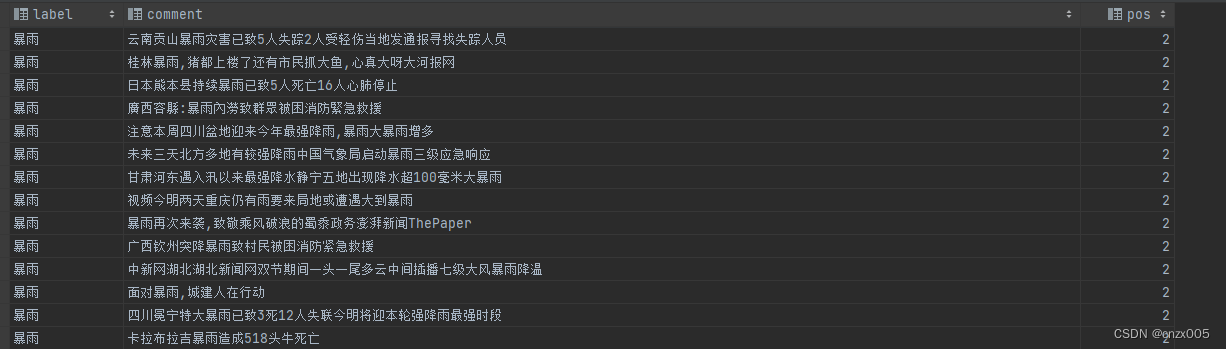
torchtext流程
新版本将之前的Field, TabularDataset,BucketIterator都删去了,流程略有不同。
词表装载
build_vocab_from_iterator 在 torchtext 中建立词表序列
主要参数如下
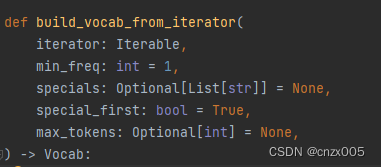
iterator 接受组成词表的迭代器
min_freq 是构成词表的最小频率
specials 是特殊词表符号
import pandas as pd
import pkuseg
from torchtext.vocab import build_vocab_from_iterator
seg = pkuseg.pkuseg()
def tokenizer(text):
return seg.cut(text)
def yield_tokens(data_iter):
for _, text in data_iter.iterrows():
yield tokenizer(text['comment' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8545
8545




 到【灌水乐园】发言
到【灌水乐园】发言







