







挺有趣,挺好玩的,边玩边记录
数据清理终极指南
The Ultimate Guide to Data Cleaning
这篇文章提供了一个全面的指南,强调了数据清洗的重要性,并详细介绍了如何提高数据质量。以下是文章的总结:
数据清洗的必要性:脏数据会导致错误的分析结果和决策,因此清洗数据对于获得可靠的洞察至关重要。
数据质量维度:包括有效性、准确性、完整性、一致性和统一性,这些是衡量数据质量的关键标准。
数据清洗工作流程:包括检查、清洗、验证和报告四个步骤,这是一个迭代的过程,需要不断地检查和修正数据。
数据清洗技术:涉及去除无关数据、处理重复数据、类型转换、修正语法错误、标准化、缩放/转换、归一化、处理缺失值和异常值等。
验证和报告:清洗后的数据需要重新检查以确保符合规则和约束,并且需要记录所做的更改和数据的质量。
持续改进:数据清洗是一个持续的过程,需要不断地评估和改进数据收集和清洗的方法。
文章强调,无论数据清洗过程多么强大,都需要培养一种对数据质量的持续关注和投资,以确保数据分析的准确性和可靠性。
专家系统

文章:Artificial Intelligence - Expert Systems
视频:Expert System Components
决策树

文章:Decision tree
视频:Decision Tree Classifier Explained
关于决策树(Decision tree)的总结:
定义:决策树是一种监督学习算法,用于分类和回归任务。它通过学习简单的决策规则从数据特征中推断出目标值。
结构:决策树由节点(代表属性或决策点)和边(代表决策结果)组成,形成树状结构。
根节点:树的起始点,代表整个数据集。
内部节点:代表一个属性上的测试,用于进一步划分数据集。
叶节点:树的末端节点,代表最终的决策结果或分类。
分支:从节点延伸出来的线,代表测试的不同可能结果。
属性选择:在每个节点,算法需要选择一个属性来分割数据。这个选择通常基于信息增益、基尼不纯度或其他标准。
分割:根据所选属性的不同值,数据被分割成不同的子集。
递归:这个过程递归地在每个子集上重复,直到满足停止条件,如达到最大深度、所有实例属于同一类别,或子集中的实例数太少。
剪枝:为了防止过拟合,决策树可能会进行剪枝,即移除树的某些部分以简化模型。
应用:决策树在许多领域都有应用,包括医疗诊断、金融风险评估、市场研究等。
优点:决策树易于理解和解释,可以处理数值和类别数据,不需要数据标准化。
缺点:容易过拟合,可能对噪声和异常值敏感。
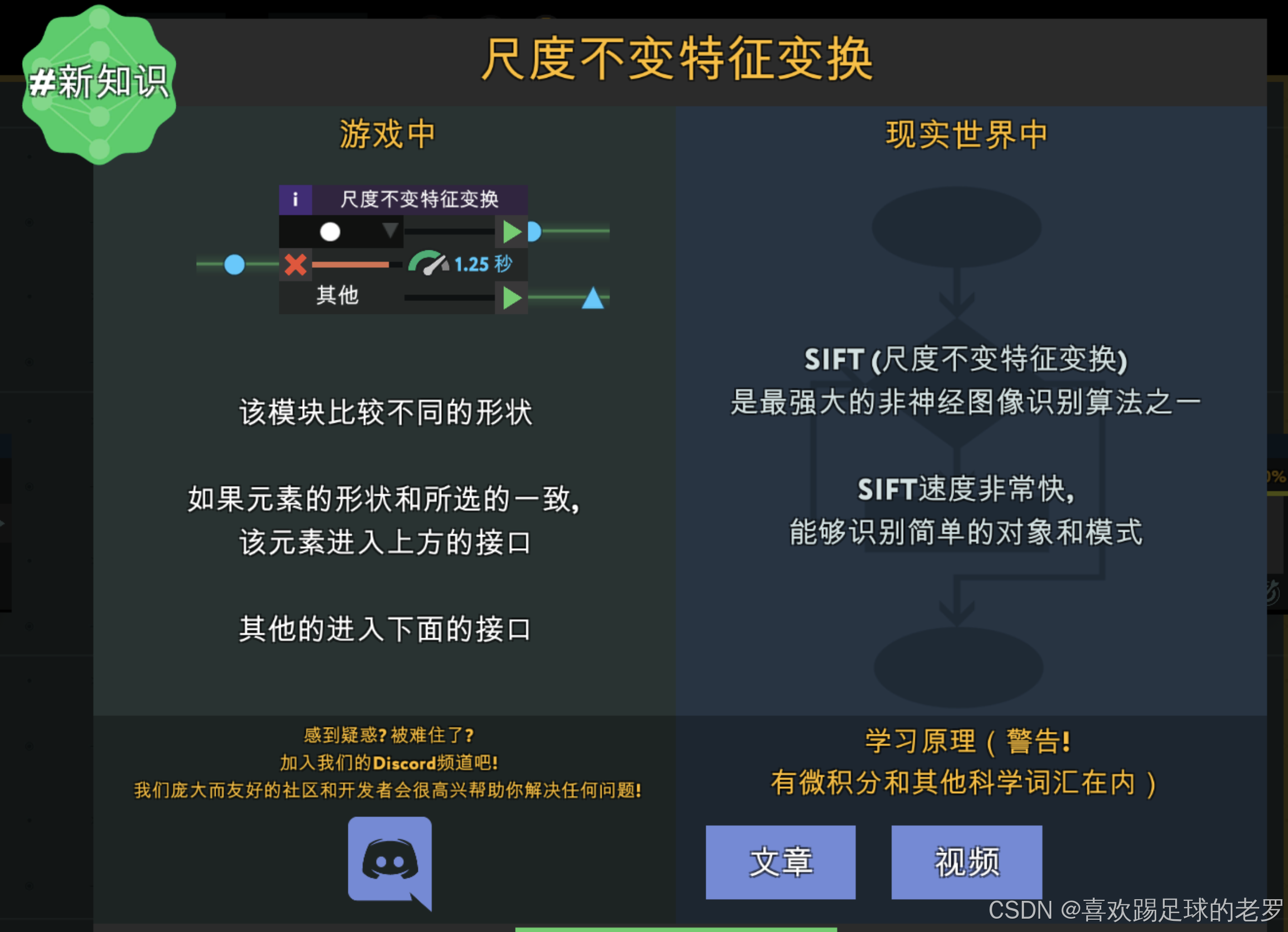
尺度不变特征变换
文章:Introduction to SIFT( Scale Invariant Feature Transform)
视频:SIFT
IFT(Scale-Invariant Feature Transform,尺度不变特征变换)是一种在计算机视觉领域广泛使用的特征提取算法,由David Lowe在1999年提出,并在2004年进行了完善
。以下是SIFT算法的简要介绍:
SIFT算法简介
SIFT算法用于侦测和描述图像中的局部特征,这些特征对于图像的缩放、旋转以及亮度变化具有不变性。这意味着即使图像的大小、方向或亮度发生变化,SIFT特征仍然能够被识别和匹配
。
SIFT算法步骤
尺度空间极值检测:SIFT算法首先在多尺度空间中检测极值点,这些极值点将作为后续特征点的候选
。
关键点定位:通过比较候选点在不同尺度下的极值变化,确定最终的关键点
。
关键点方向分配:根据关键点周围的梯度方向,为每个关键点分配一个方向
。
关键点描述符生成:利用关键点周围的图像梯度信息,生成关键点描述符
。
特征点匹配:利用关键点描述符进行特征点匹配
。
SIFT算法特点
尺度不变性:SIFT算法能够检测出在不同尺度下的关键点
。
旋转不变性:SIFT算法能够检测出在不同旋转角度下的关键点
。
位置不变性:SIFT算法能够检测出在不同位置下的关键点
。
唯一性:SIFT算法能够生成具有唯一性的关键点描述符
。
SIFT算法应用领域
SIFT算法的应用范围广泛,包括物体辨识、机器人地图感知与导航、影像缝合、3D模型建立、手势辨识、影像追踪和动作比对等
。
SIFT算法因其在图像处理和目标识别中的稳健性和准确性而受到重视,尽管它在实时性、特征点数量以及对边缘光滑目标的特征提取方面存在一些限制
。SIFT特征的信息量大,适合在大量数据库中快速准确匹配
。
感知器
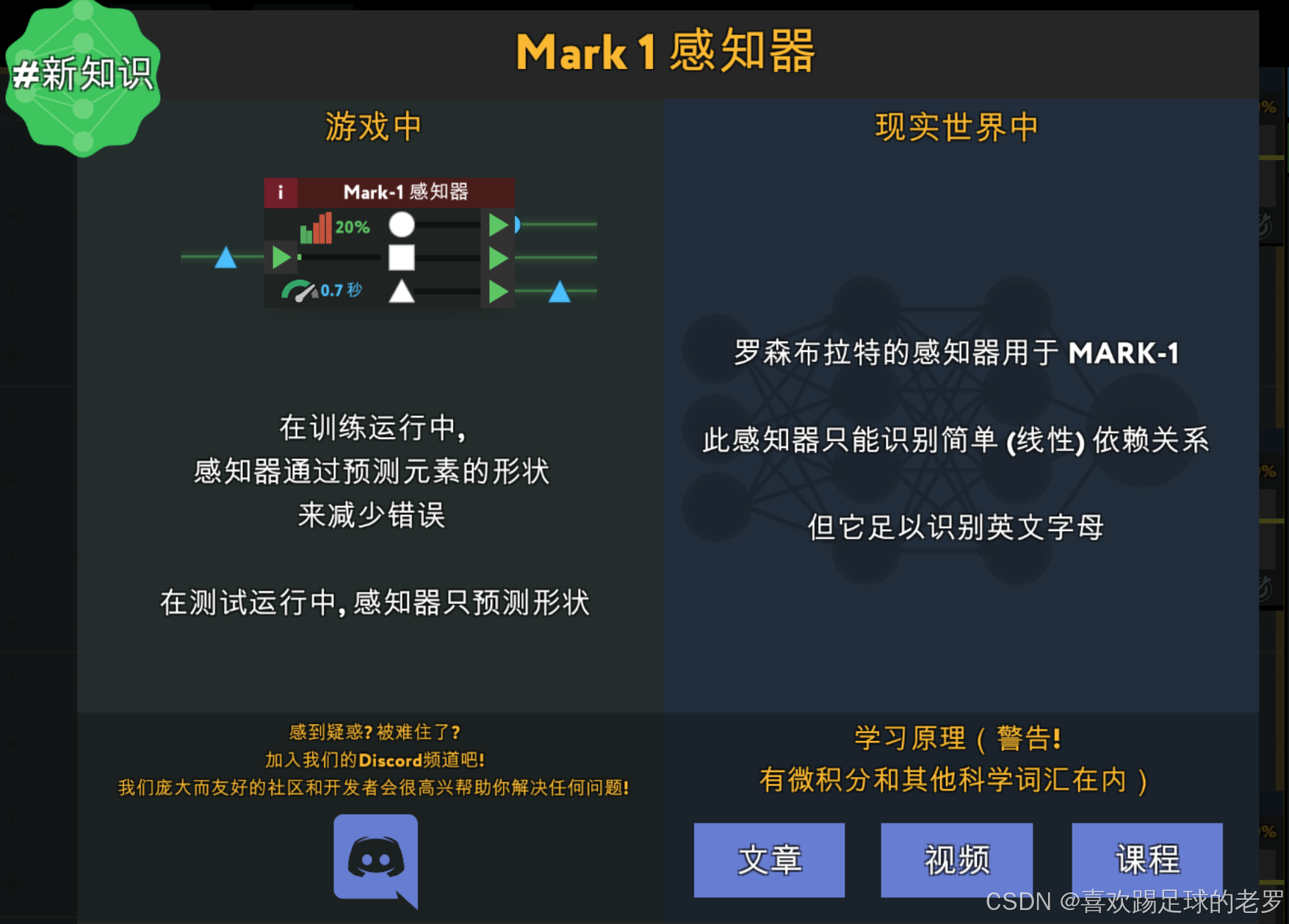
文章:https://en.wikipedia.org/wiki/Perceptron
视频:But How Does The Perceptron Actually Work?
课程:感知器:最简单的神经网络




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









