




 在Spark SQL处理数据时,小文件问题常见,可通过设置`spark.sql.shuffle.partitions`、使用`coalesce(num)`或应用Spark Sql Adaptive Execution解决。`spark.sql.shuffle.partitions`参数用于控制shuffle操作的分区数,`coalesce(num)`用于再分区,而Adaptive Execution是2.3.0版本后引入的,能动态调整reduce个数,优化joins和数据倾斜问题。
在Spark SQL处理数据时,小文件问题常见,可通过设置`spark.sql.shuffle.partitions`、使用`coalesce(num)`或应用Spark Sql Adaptive Execution解决。`spark.sql.shuffle.partitions`参数用于控制shuffle操作的分区数,`coalesce(num)`用于再分区,而Adaptive Execution是2.3.0版本后引入的,能动态调整reduce个数,优化joins和数据倾斜问题。
参考:
https://github.com/Intel-bigdata/spark-adaptive
http://spark.apache.org/docs/latest/configuration.html
使用Spark Sql APIs 处理数据容易产生生成大量小文件,小文件问题也是在分布式计算中常见的问题。一般有三种方法来处理这类问题:
- 设置spark.sql.shuffle.partitions
- 采用coalesce(num)对数据集repartition
- 使用Spark Sql Adaptive Execution
- spark.sql.shuffle.partitions 参数通过在处理joins 或 aggregations 等shuffle操作来控制输出的分区数。
可以在spark-submit 提交任务时通过 --conf 来指定
- coalesce(num) 通过对数据集再分区控制输出分区数
- Spark Sql Adaptive Execution 是spark 2.3.0 版本后添加的
spark sql自适应框架可以通过设置spark shuffle partition的上限和下限对不同作业不同阶段的 reduce 个数进行动态调整;同时也可以通过参数对 joins 和 数据倾斜问题进行优化
Spark Sql Adaptive Execution参数:
控制并发度
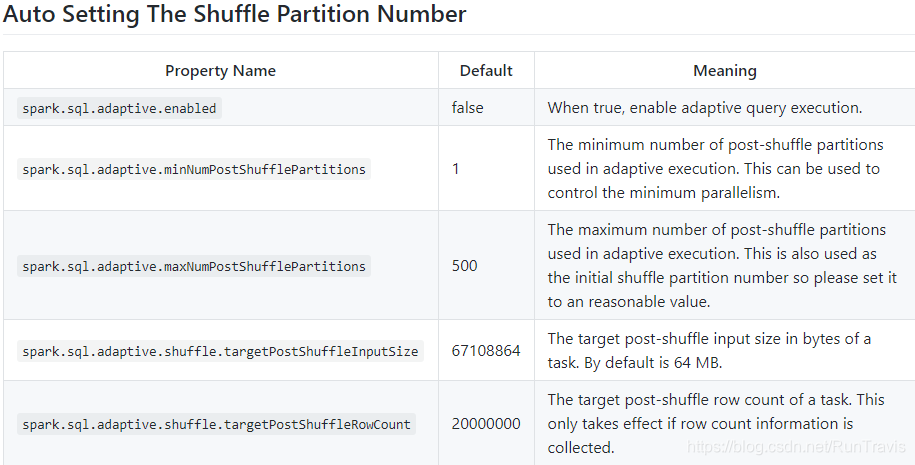
Joins 优化策略:

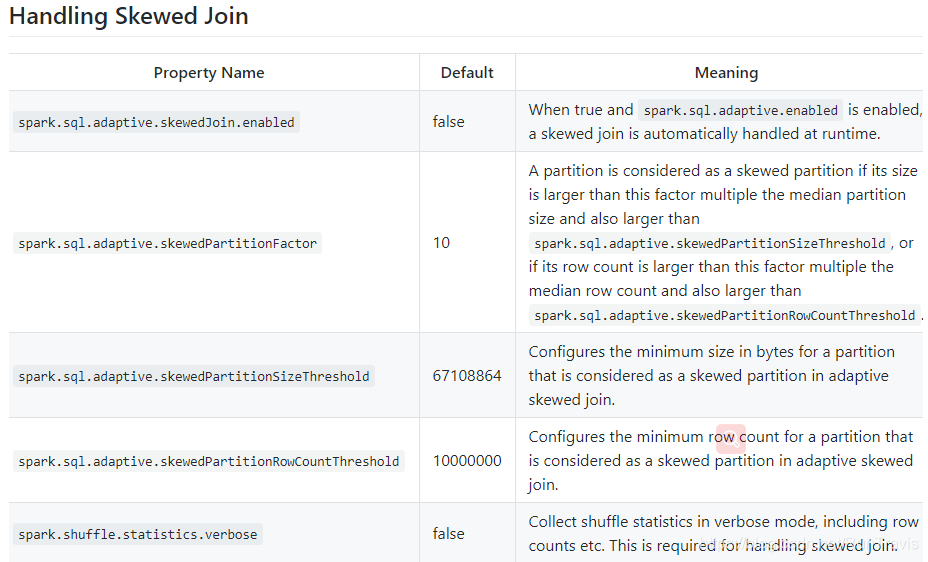
数据倾斜:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3771
3771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









