




缓存了一些视频m4s文件,只能用指定的软件打开,网上查了一下,需要去掉m4s文件开头的9个0,还要用FFmpeg将两个文件合并成一个文件。 经仔细研究缓存目录和其中文件,发现以下特点:
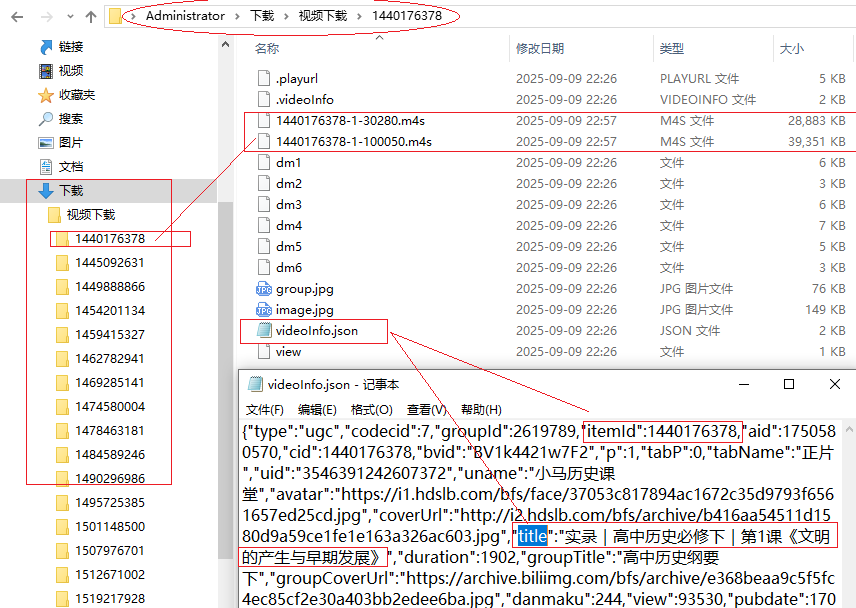
“缓存目录”中有很多“数字文件夹”,里面有两个m4s文件也是同样的数字开头,用记事本打开videoInfo.json文件,可以提取文件信息:
#分组号 "groupId":2619789
#组名 "groupTitle":"高中历史纲要下"
#文件ID "itemId":1440176378
#文件名 "title":"实录|高中历史必修下|第1课《文明的产生与早期发展》"
手工去掉m4s文件前面9个0,将两个同名文件通过FFmpeg合并后生成对应的mp4,就能脱机播放了。最后还要参考videoInfo.json改成对应的汉字文件名。
制定处理方案如下:
作为python除学者,需要在win7环境(方便向下兼容)处理m4s文件。
1、指定缓存目录的路径,指定FFmpeg工具所在目录的路径,指定存放“处理结果”的路径。
如果没有找到FFmpeg,请提示下载地址。
2、遍历所有包含m4s文件的目录,以二进制的方式处理m4s文件:
如果“前9个字节是0x30”则移除(0x30 是字符 '0' 的 ASCII 值),保留原文件名和后缀名。
否则,可以直接进入下一步处理。
3、进入找到的目录,提取videoInfo.json文件中的信息。
4、从中提取"itemId"作为“文件ID”、"title"作为“文件名”、"groupId"作为“分组号”
显示处理进度:已处理“文件ID”、“分组号”、“文件名”。
5、在当前目录利用FFmpeg合并两个以“文件ID”开头的m4s文件,生成的mp4文件改名成“文件名”.mp4,
放在“处理结果”之“分组号”目录里面。
显示处理进度:已合并处理完成 “文件名”.mp4
FFmpeg 的命令行为 ffmpeg.exe -i 找到的第一个.m4s -i 找到的第二个.m4s -codec copy“文件名”.mp4
6、完成后返回到第3步,直到处理完所有目录。
最后利用“AI豆包”生成脚本,源码和可执行文件如下:
(资源)利用FFmpeg自动批量处理m4s文件v2.1.py
(资源)视频处理(m4s)v2.1.exe
(资源)视频处理(示例).txt
如果对这个脚本有兴趣可以联系我QQ7355157(关键词:批量处理m4s文件)
【最终优化版特点说明】
一、详细的操作步骤说明:
1、为每个处理步骤添加了清晰的标题和说明文字
2、使用不同类型的信息提示([信息]、[成功]、[警告]、[错误])区分状态
3、操作流程完全按照你的要求分步展示
二、初学者友好的交互:
1、运行时会提示用户输入三个关键路径(可直接按 Enter 使用默认值)
2、清晰显示当前正在执行的操作和进度
3、提供详细的错误信息和解决建议
三、关键功能调整:
1、改用 "groupId" 作为分组号(根据最新需求,以此生成目录区分资源。)
2、找不到 FFmpeg 时显示官方下载地址和安装建议
3、增强了文件路径和命名的容错处理
四、完善的用户体验:
1、处理完成后显示总结报告,包括处理的目录数量和结果存放位置
2、每个目录处理完成后有明确的分隔标识
3、显示 FFmpeg 实际执行的命令,方便调试
使用方法非常简单:运行脚本后,根据提示输入或确认三个路径(缓存目录、
FFmpeg 目录、结果存放目录),然后脚本会自动按步骤处理所有文件,并实时显示进
度和结果。
如果遇到任何问题,脚本会显示详细的错误信息和解决建议,特别适合 Python
初学者使用。

















 1295
1295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









