







 该论文提出了一种新的CNN压缩方法,通过基于熵的评估标准来确定滤波器的重要性,并进行剪枝。这种方法能加速模型并减少中间激活的大小,实现在VGG-16和ResNet-50上压缩和加速模型的同时,仅轻微影响精度。
该论文提出了一种新的CNN压缩方法,通过基于熵的评估标准来确定滤波器的重要性,并进行剪枝。这种方法能加速模型并减少中间激活的大小,实现在VGG-16和ResNet-50上压缩和加速模型的同时,仅轻微影响精度。
论文地址:http://export.arxiv.org/pdf/1706.05791
一、精读论文
论文题目
An Entropy-based Pruning Method for CNN Compression
论文作者
Jian-Hao Luo Jianxin Wu
刊物名称
cvpr
出版日期
2017.6.17
摘要
本文的目标是通过滤波剪枝策略同时加速和压缩现成的cnn模型。首先利用所提出的基于熵的方法对各滤波器的重要性进行评估。然后丢弃几个不重要的过滤器以得到一个更小的CNN模型。最后,采用微调的方法恢复滤波器在剪枝过程中被破坏的泛化能力。我们的方法可以减少中间激活的大小,这将在模型训练阶段占据大部分内存占用,但在以前的压缩方法中较少关注。在ILSVRC-12基准上的实验验证了该方法的有效性。与以往的滤波器重要性评价准则相比,基于熵的方法获得了更好的性能。我们在VGG-16上实现了3.3×加速和16.64×压缩,在ResNet-50上实现了1.54×加速和1.47×压缩,两者的精度都下降了约1%。
关键词
剪枝、熵、深度学习
总结
文章也是网络剪枝的早期文章,其算法是filter级别的裁剪。文章认为weights的大小不能决定一个filter的重要性,应该用熵来决定
二、研读总结(分三段总结,500字左右)
1、 针对问题与解决方法
本文对中间激活剪枝方法进行了全面的描述。首先,给出了总体框架。本文的主要想法是放弃几个不重要的过滤器,并通过微调恢复其性能。这些实施细节将在随后公布。最后,我们介绍了一个有效的学习计划策略,这是我们方法的关键元素之一。
下图说明了我们提出的中间激活剪枝方法的总体框架。对于我们想要删除的特定层(即第i层),我们首先关注它的激活张量。如果它的激活张量的几个通道足够弱(例如,所有的元素都有相同的值),我们就有足够的信心相信相应的滤波器也不那么重要,可以对其进行修剪。我们提出了一个基于熵的度量来评估每个信道的弱点。如图1所示,这些弱通道用黄色突出显示。然后,这些弱滤波器都被从原始模型中删除,导致一个更紧凑的网络结构。下一层中相应的滤波器通道也被删除。与原模型相比,该剪枝模型具有更少的参数,从而减少了运行时间和内存消耗。更重要的是,激活的大小也减少了,这在以前的压缩方法中不太受关注。最后,根据稀疏表示和分布式表示的性质(即每个概念由多个神经元表示,每个神经元参与多个概念的表示[14,2]),这些滤波器虽然较弱,但也存储了一些知识。因此,修剪后的模型的泛化能力会受到影响。为了恢复其性能,对整个网络进行了微调。我们采用不同的学习计划来训练修剪后的模型,不仅减少了整体的训练时间,而且防止了模型被吸引到坏的局部极小值。
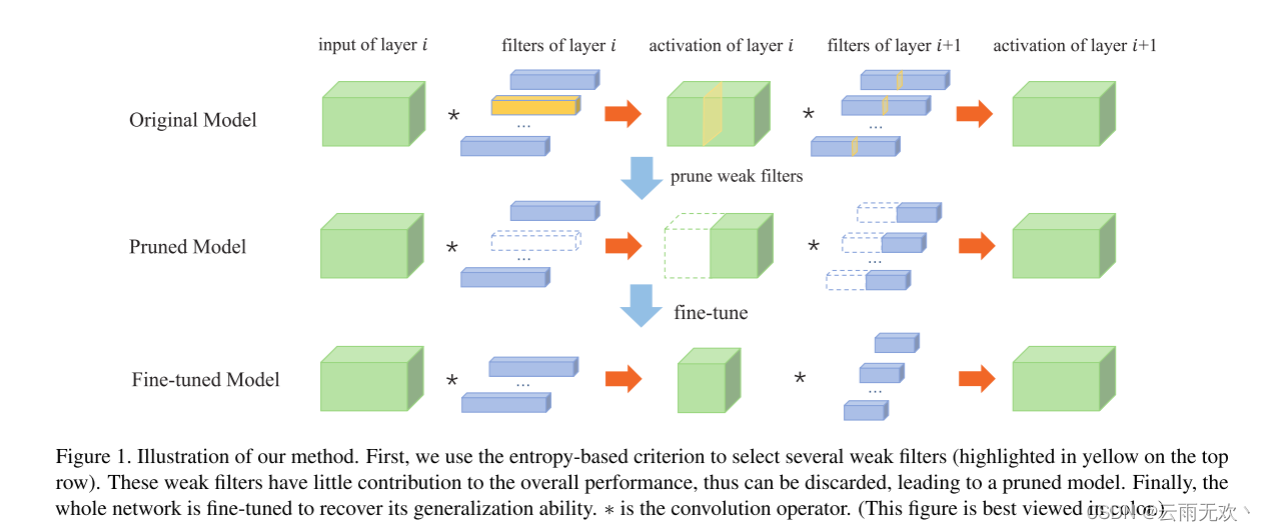
2、 数据实验与结论分析
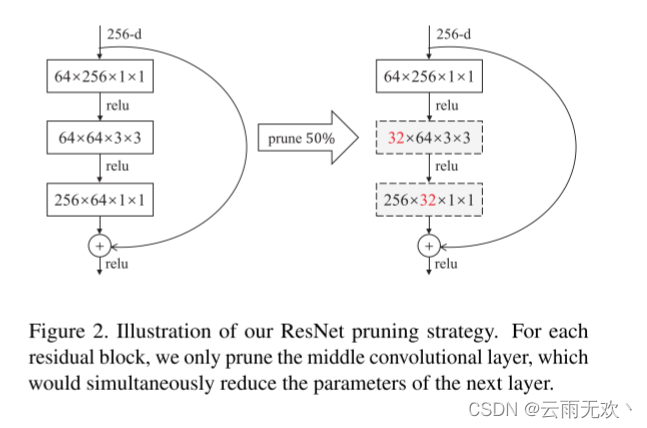
我们使用两种不同的策略来修剪这两种类型的网络。对于VGG-16,我们注意到超过90%的FLOPs存在于前10层(Conv1-1到Conv4-3),全连接层贡献了所有模型参数的将近89.36%。为了减少运行时间,我们采用基于熵的方法对前10个卷积层进行修剪。对于全连接层,我们的方法也是有效的,但我们认为用全局平均池化层代替它们更有效,因为我们的目标是尽可能地减少参数大小。ResNet由于其特殊的结构,存在许多限制。例如,同一组中每个块的输出通道号需要一致,否则需要一个特殊的投影快捷方式来完成求和操作(详见[13])。因此,很难直接对每个残差块的最后一层卷积进行裁剪。由于大多数参数位于最后两层,我们认为对中间层进行剪枝是一个更好的选择,这样也可以减少下一层的参数大小。该策略如图2所示。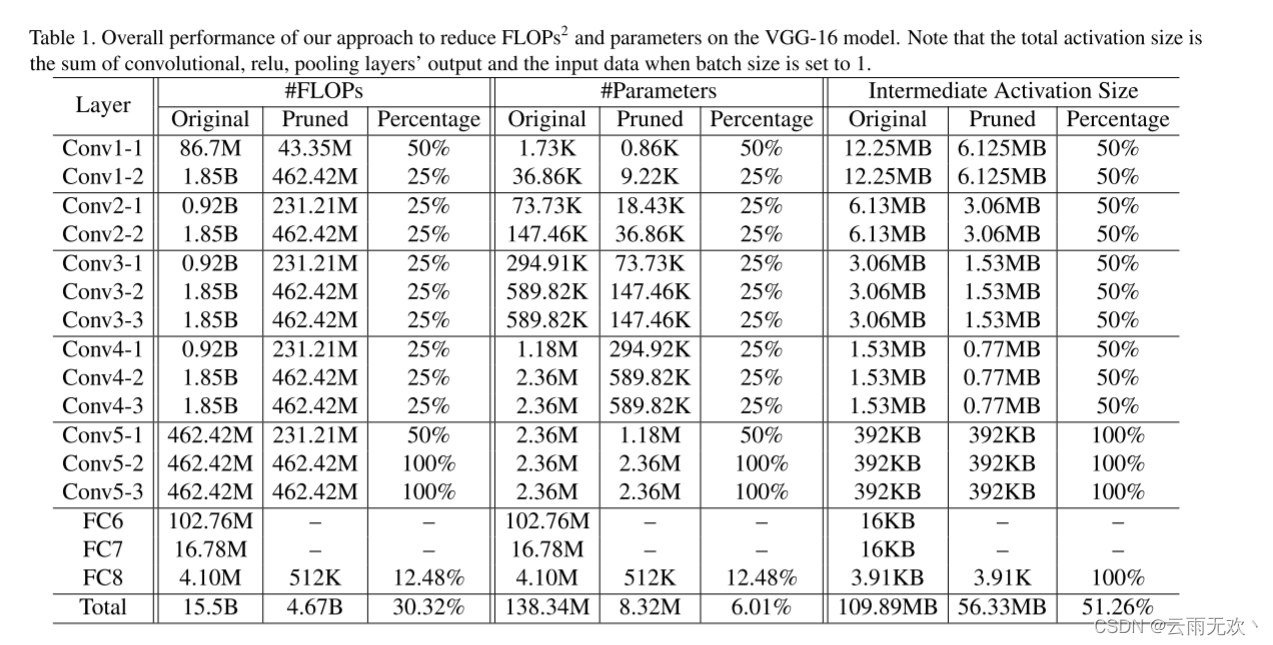
3、 科研启发与积累工作
( 针对自己的研究方向,总结自己的收获和所受的启发。
精度论文的积累工作:是否复现了论文模型或积累了数据集等 )




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











